
论文链接:https://openaccess.thecvf.com/content/CVPR2022/papers/Long_Stand-Alone_Inter-Frame_Attention_in_Video_Models_CVPR_2022_paper.pdf
代码:https://github.com/FuchenUSTC/SIFA
1. 动机
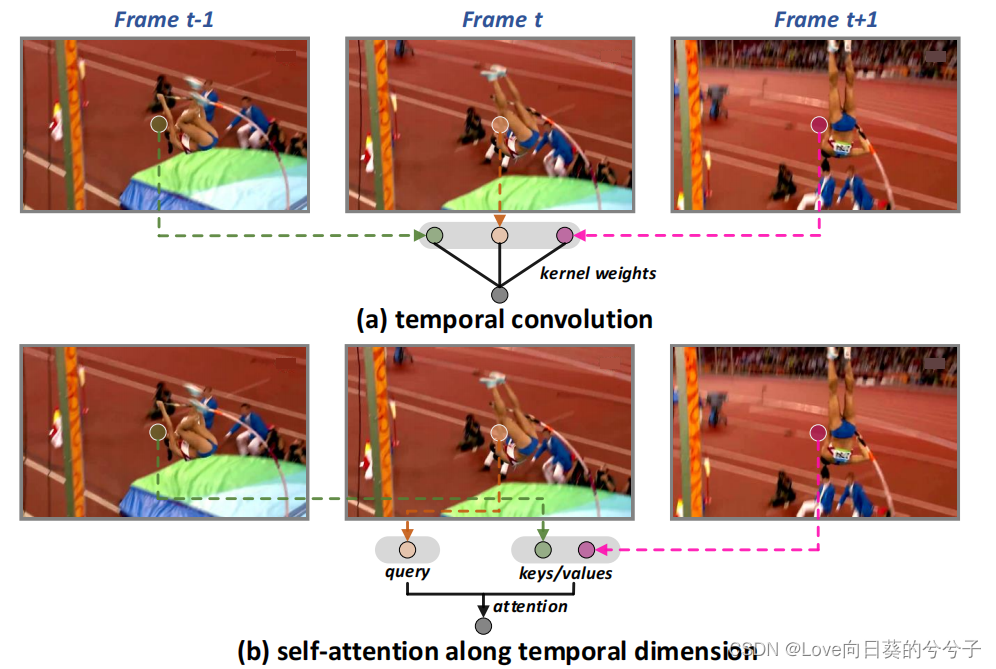
视频是对移动的视觉图像的电子表示,它自然地形成了运动,它表示物体或人的位置随着时间的不断变化。建模这样的时间动态是必不可少的。现代深度学习模型通过执行时空3D卷积、分别将3D卷积分解为空间和时间卷积,或者沿着时间维度计算自我注意力来利用运动(如下图所示)。这些成功背后的隐含假设是跨连续帧的特征映射可以很好地对齐的基础。然而,这一假设可能并不总是成立,特别是对于大变形的区域。
如下,由于撑杆跳运动员的运动,圆圈中突出显示的跨帧相同位置对应不同的物体(在例中是人和轨道)。因此,在这些位置上执行时间卷积或计算注意力可能是时间特征聚集的次优选择。
2. 贡献
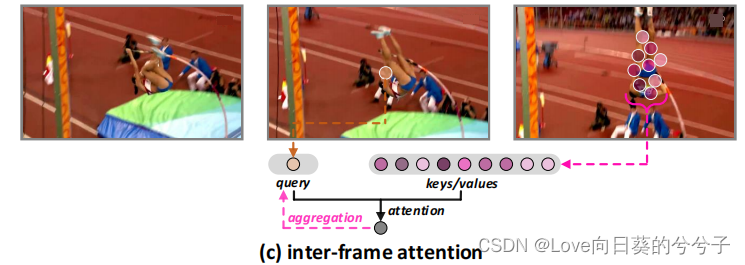
本文提出一个 Stand-alone Inter-Frame Attention (SIFA)块,通过深入研究帧间的变形来推断局部变形区域内的时间注意力,以进行时间建模。
3. 方法
本文主要引入了一种新的 Stand-alone Inter-Frame Attention (SIFA)用于时间建模。通过深入研究帧间的变形来推断局部变形区域内的时间注意力,以进行时间建模SIFA利用连续帧间局部区域内的时间相关性,通过注意力将其局部邻居聚集到相邻帧中,从而增强每帧的特征。接着,在视频模型中设计了一种新颖的独立块,即SIFA块,用于跨帧在低变形区域上执行帧间注意。
3.1 Stand-alone Inter-Frame Attention (SIFA)
在视频表示学习中,时间建模的一种自然方法是使用跨帧进行像素级特征聚合的1D时间卷积。通过深入研究帧间的变形来推断局部变形区域内的时间注意力,以进行时间建模然而,该方法仅在时间维度上捕获同一空间位置之间的运动线索,而忽略了不同空间位置的帧间相关性进行时间建模。受注意力(Transformer, Non-Local)对远程依赖建模的启发,作者设计了一种适合于时间建模的新的注意力机制,即Stand-alone Inter-Frame Attention (SIFA),该机制利用局部区域内的帧间相关性进行有效的注意力学习。对相邻帧局部区域内的所有时间邻居进行聚合,增强帧间特征。
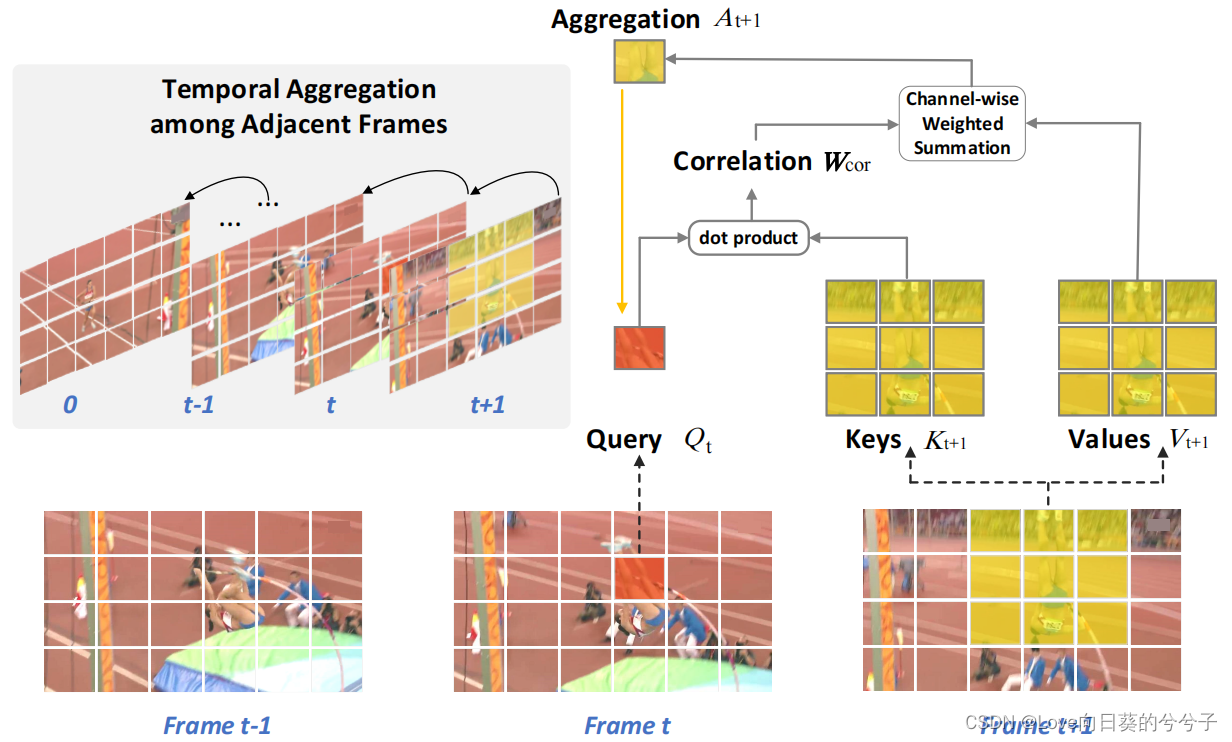
如上引入SIFA的细节图所示。具体地,输入 F ∈ R C × L × H × W F\in \mathbb{R}^{C \times L \times H \times W} F∈RC×L×H×W,其中 C C C, H × W H\times W H×W,和 L L L分别表示channel大小,spatial大小和时间长。这里将 F F F转成2D特征序列,记为 { f t } t = 0 L − 1 \{ f_t \}^{L-1}_{t=0} {
ft}t=0L−1。对于第 t t t帧,将其在空间位置 ( x , y ) (x, y) (x,y)的特征作为查询 Q t ∈ R C Q_t \in \mathbb{R}^C Qt∈RC,通过深入研究帧间的变形来推断局部变形区域内的时间注意力,以进行时间建模。同时,将第 ( t + 1 ) (t+1) (t+1)帧在以 ( x , y ) (x, y) (x,y)为中心的局部区域(大小: k × k k \times k k×k网格)内的特征设为键 K t + 1 ∈ R C × { k × k } K_{t+1} \in \mathbb{R}^{C \times \{k \times k \}} Kt+1∈RC×{
k×k}和值 V t + 1 ∈ R C × { k × k } V_{t+1} \in \mathbb{R}^{C \times \{k \times k \}} Vt+1∈RC×{
k×k}。然后,通过dot production计算查询 Q t Q_t Qt和键 K t + 1 K_{t+1} Kt+1之间的相关矩阵 W c o r W_{cor} Wcor:
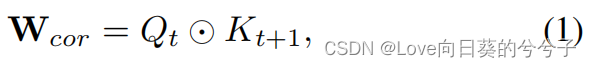
其中⊙表示矩阵乘法,用于测量查询与其局部 k × k k × k k×k网格中的时间邻居(即键)之间的成对时间相关性。
现有工作一般将学习到的相关矩阵 W c o r ∈ R 1 × { k × k } W_{cor} \in \mathbb{R}^{1 \times \{k \times k\}} Wcor∈R1×{
k×k}作为像素级位移信息,直接用它来扩充主特征图,辅助流量估计、几何匹配和运动建模任务。通过深入研究帧间的变形来推断局部变形区域内的时间注意力,以进行时间建模作为一种替代方法,我们利用相关矩阵作为注意力权重,动态聚集附近帧局部区域内的相应值,以增强查询特性。其中,以相关矩阵 W c o r W_{cor} Wcor作为注意权值,对局部区域内的 V t + 1 V_{t+1} Vt+1进行通道聚合:
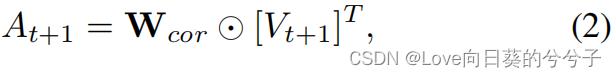
其中 A t + 1 A_{t+1} At+1是由查询的时态邻居派生的聚合特征, [ ⋅ ] T [·]^T [⋅]T表示矩阵转置。通过深入研究帧间的变形来推断局部变形区域内的时间注意力,以进行时间建模。在此基础上,将查询与聚合特征进行集成,得到时态特征聚合后的增强查询特征 Y t Y_t Yt:

因此,SIFA对第 t t t帧中的每个空间位置进行帧间注意,以挖掘其在第 ( t + 1 ) (t+1) (t+1)帧局部区域内的时间相关性。通过深入研究帧间的变形来推断局部变形区域内的时间注意力,以进行时间建模。因此,每一帧的特征图通过注意来聚集下一帧的局部邻居的特征来加强。通过这种方式,我们在输入序列中的每对相邻帧之间操作SIFA。注意,对于序列中的最后一帧,我们在该帧与自身之间进行帧间注意,并通过特征聚合来增强其自身的特征映射,从而保持输出帧序列的时间长度为 L L L。
3.2 Connections with Previous Spatio-temporal Attention

SIFA与以往时空注意机制的详细联系和区别,通过深入研究帧间的变形来推断局部变形区域内的时间注意力,以进行时间建模引入了两种时空注意(即联合时空自注意或分割时空自注意),利用时空自注意进行视频表示学习。其中,联合时空自注意(上图(a)中的ST)整体地对所有帧的输入特征/补丁进行自注意。分割的时空自注意(上图 (b)中的 T + S T+S T+S)分别将当前帧内的空间注意和对相邻帧相同空间位置的时间邻居的时间注意应用。
- SIFA针对视频建模沿着时间维度探索自我注意力。通过深入研究帧间的变形来推断局部变形区域内的时间注意力,以进行时间建模与ST中对整体特征/斑块的全局时间关注不同,SIFA在帧间进行局部区域内的局部时间关注,计算效率更高。此外,与 T + S T+S T+S只挖掘连续帧的同一空间位置的时间演化相比,SIFA捕获局部区域内更丰富的帧间相关性进行注意力学习,从而便于时间建模。
3.3 SIFA Block
设计SIFA机制是为了模拟连续帧内局部区域内目标的时间演化。通过深入研究帧间的变形来推断局部变形区域内的时间注意力,以进行时间建模。然而,简单地在等大小的局部区域( k × k k \times k k×k网格)上使用帧间注意不可避免地忽略了每帧对象的不规则几何变换,导致次优解。为了缓解这一问题,我们设计了一个SIFA块,将帧间注意力应用于附近帧的局部变形区域,其中包括在自由形式空间变形中采样的时间邻居。
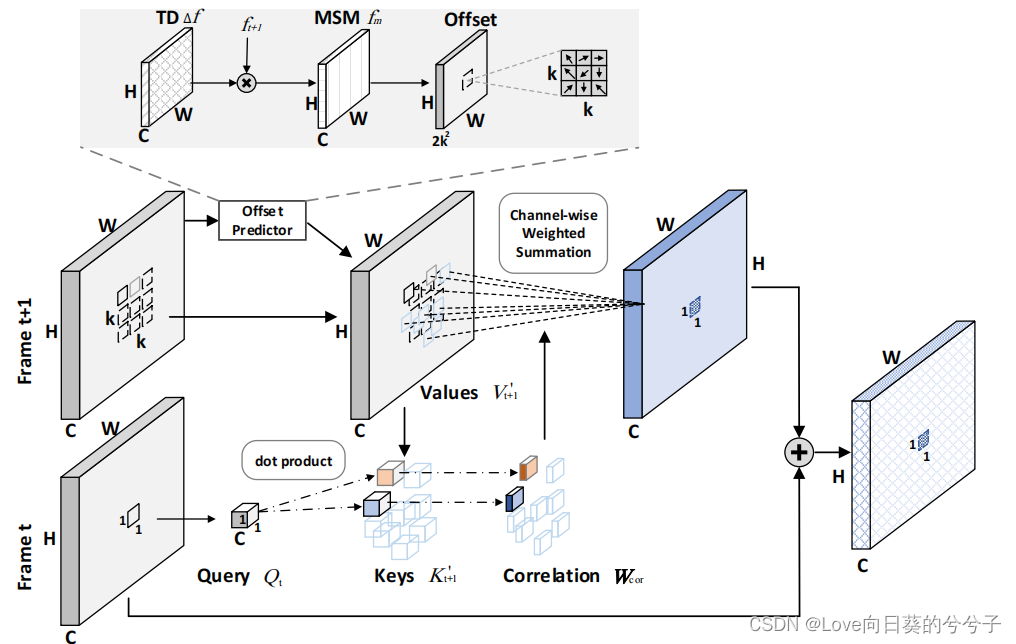
操作可变形特征重采样的最典型方法是用额外的偏移量来增加空间采样位置,这些偏移量是通过可变形ConvNets中的可学习偏移估计器来预测的。通过深入研究帧间的变形来推断局部变形区域内的时间注意力,以进行时间建模。尽管如此,这个偏移估计器学会仅根据输入特征映射本身推断每个空间位置的2D偏移,同时留下连续帧之间的固有运动线索。相反,我们提出在局部区域内估计每个空间位置的二维偏移量,基于其运动显著性图(MSM),作为运动监督来指导变形特征的重新采样,上图显示了SIFA块的详细结构。
形式上,给定每一对连续的帧(即第 t t t帧 f t f_t ft和第 ( t + 1 ) (t+1) (t+1)帧 f t + 1 f_{t+1} ft+1),我们首先计算它们之间的时间差(TD)通过深入研究帧间的变形来推断局部变形区域内的时间注意力,以进行时间建模:

接下来,我们对这种时间差异进行sigmoid操作,从而得到标准化的注意力图。通过深入研究帧间的变形来推断局部变形区域内的时间注意力,以进行时间建模该注意图动态地精确定位了第 ( t + 1 ) (t+1) (t+1)帧中包含高度突出的物体运动的空间位置。因此,将第 ( t + 1 ) (t+1) (t+1)帧 f t + 1 f_{t+1} ft+1的特征图与注意力图相乘,得到运动显著性图(MSM) f m f_m fm:
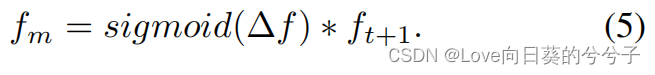
以运动显著图 f m f_m fm为条件,我们利用偏移估计器来预测第 ( t + 1 ) (t+1) (t+1)帧 f t + 1 f_{t+1} ft+1的局部区域( k × k k \times k k×k网格)内每个空间位置的二维偏移。通过深入研究帧间的变形来推断局部变形区域内的时间注意力,以进行时间建模注意,偏移估计器实现为一个2D卷积层,输出通道大小为 2 k 2 2k^2 2k2。更具体地说,设 ( Δ a , Δ b ) (\Delta a, \Delta b) (Δa,Δb)表示以查询位置 ( x , y ) (x, y) (x,y)为中心的 k × k k \times k k×k网格内每个空间位置 p = ( a , b ) p = (a, b) p=(a,b)的估计二维偏移量,相应的不规则空间位置表示为 p ′ = ( a + Δ a , b + Δ b ) p' = (a + \Delta a, b + \Delta b) p′=(a+Δa,b+Δb)。在Deformable Convolutional Networks之后,作者在每个不规则空间位置 p ′ p' p′上通过双线性插值对特征 K t + 1 ′ ( p ′ ) K'_{t+1}(p') Kt+1′(p′)进行采样,即:
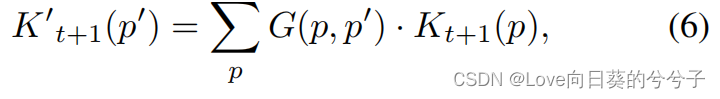
其中 p ′ p' p′为分数空间位置, p p p枚举局部区域内的所有积分空间位置。通过深入研究帧间的变形来推断局部变形区域内的时间注意力,以进行时间建模 K t + 1 ( p ) K_{t+1}(p) Kt+1(p)表示正则空间位置 p p p上的主特征, G G G为双线性插值核。对第 ( t + 1 ) (t+1) (t+1)帧 f t + 1 f_{t+1} ft+1中的所有 k 2 k^2 k2个可变形特征进行采样后,将其作为第 t t t帧 f t f_t ft中的查询 Q t ∈ R C Q_t \in \mathbb{R}^C Qt∈RC的键 K t + 1 ′ ∈ R C × { k × k } K'_{t+1} \in \mathbb{R}^{C \times \{k \times k \}} Kt+1′∈RC×{
k×k}和值 V t + 1 ′ ∈ R C × { k × k } V'_{t+1} \in \mathbb{R}^{C \times \{k \times k \}} Vt+1′∈RC×{
k×k}。这样,我们对附近帧的局部可变形区域执行SIFA机制,并通过注意力聚合这些可变形特征来进一步强化每帧特征通过深入研究帧间的变形来推断局部变形区域内的时间注意力,以进行时间建模。即
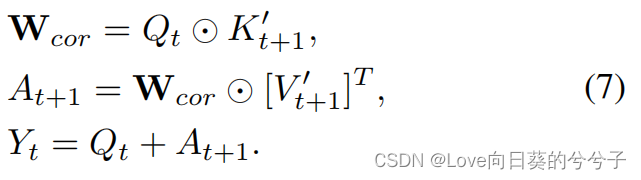
最后,将第 t t t帧的增强特征 Y t Y_t Yt作为SIFA块的输出。
3.4 应用: 2D CNN and Vision Transformer
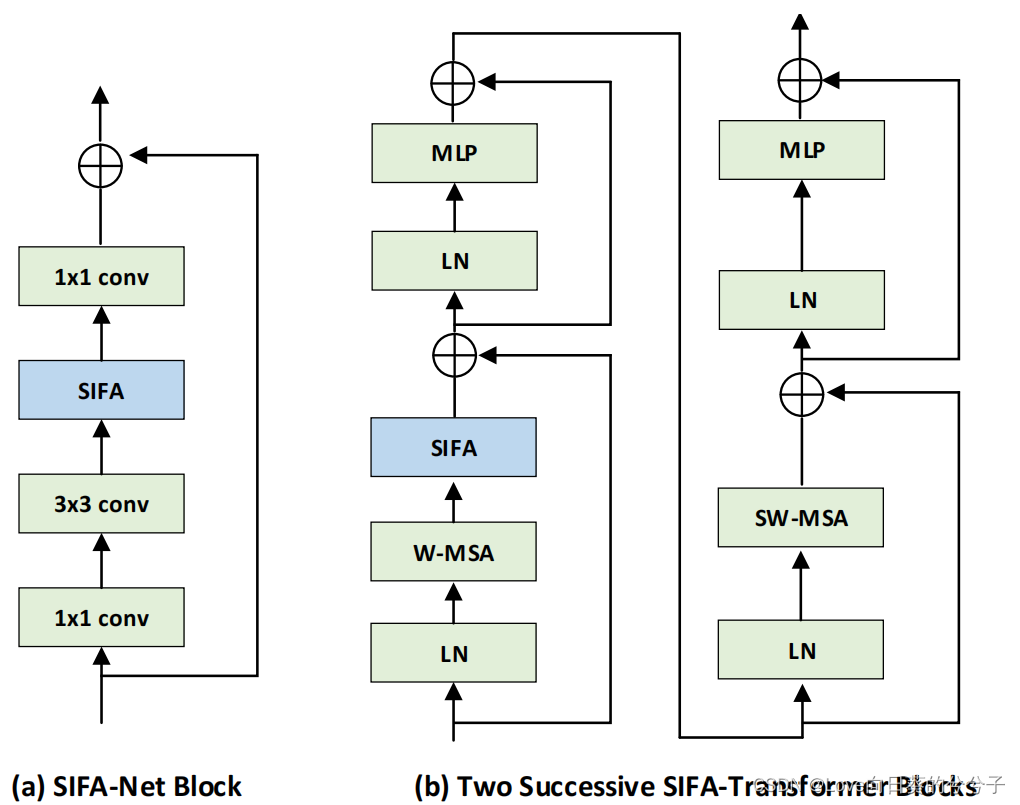
SIFA块作为时间建模的独立原语,可以插入到任何2D CNN或Vision Transformer架构。通过深入研究帧间的变形来推断局部变形区域内的时间注意力,以进行时间建模这样的设计自然升级了这些视觉主干,具有时间建模的能力,从而促进了视频表示的学习。在这里,介绍如何将SIFA块集成到现有的2D CNN(例如ResNet)和Vision Transformer(例如Swin Transformer)中。下图描述了用SIFA块在ResNet/Swin Transformer中配备基本构建块的两种不同结构,即SIFA-Net和SIFA-Transformer。更多细节见论文和代码!!
4. 实验
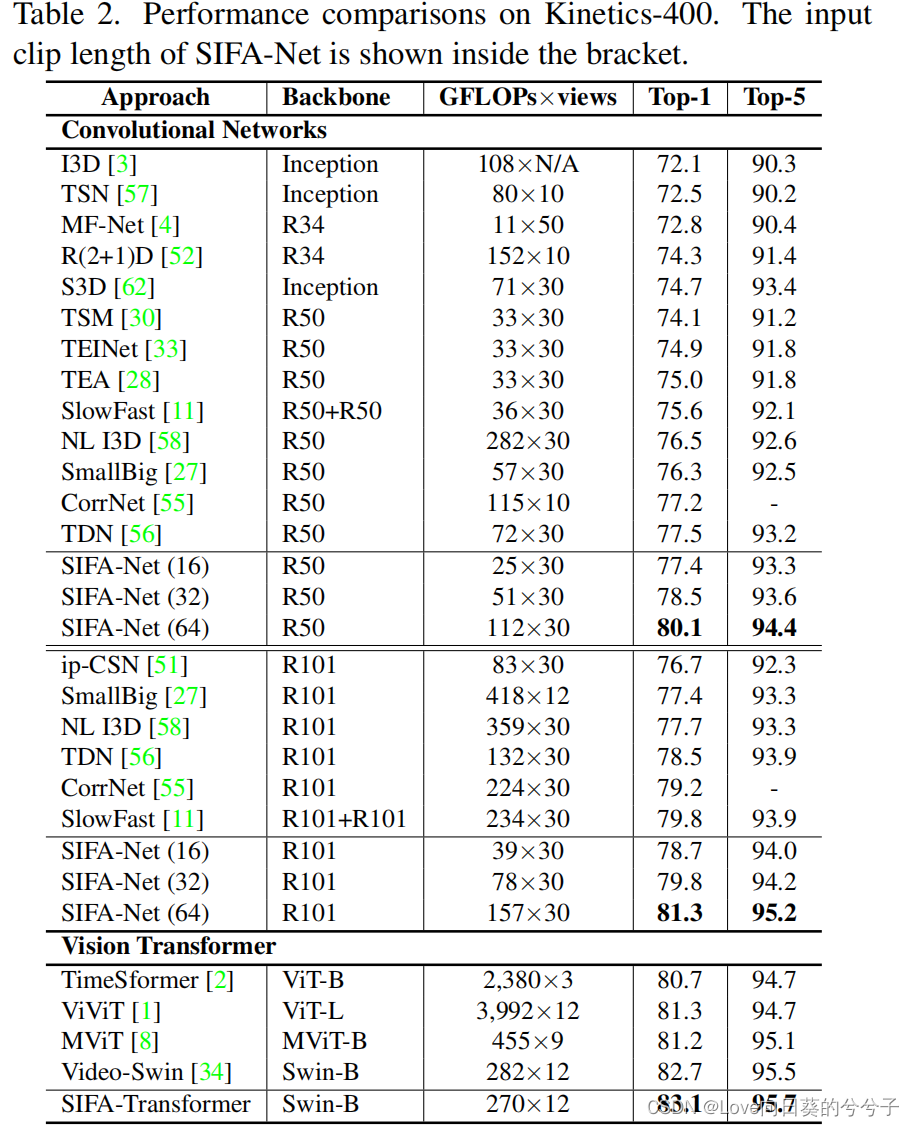
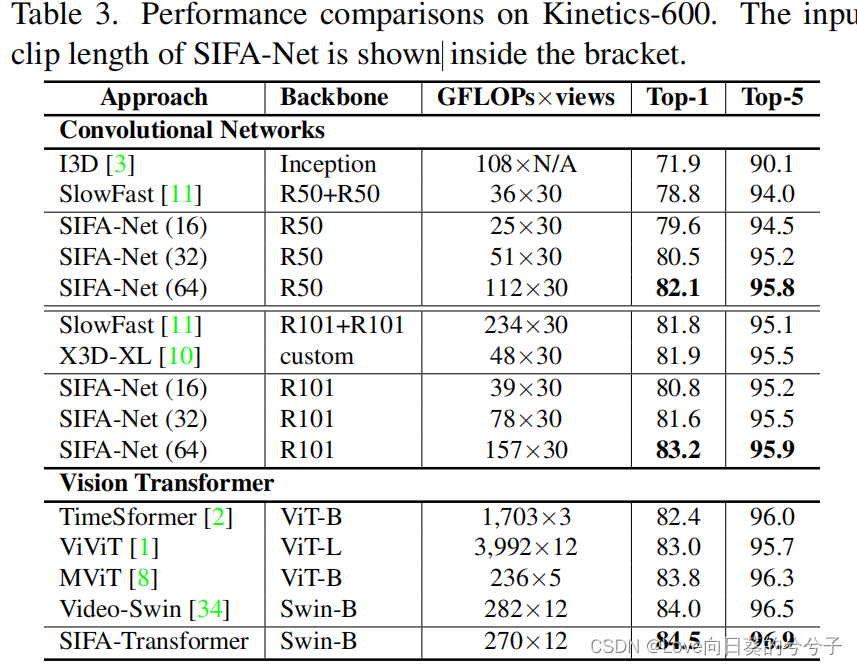
- SOTA方法对比
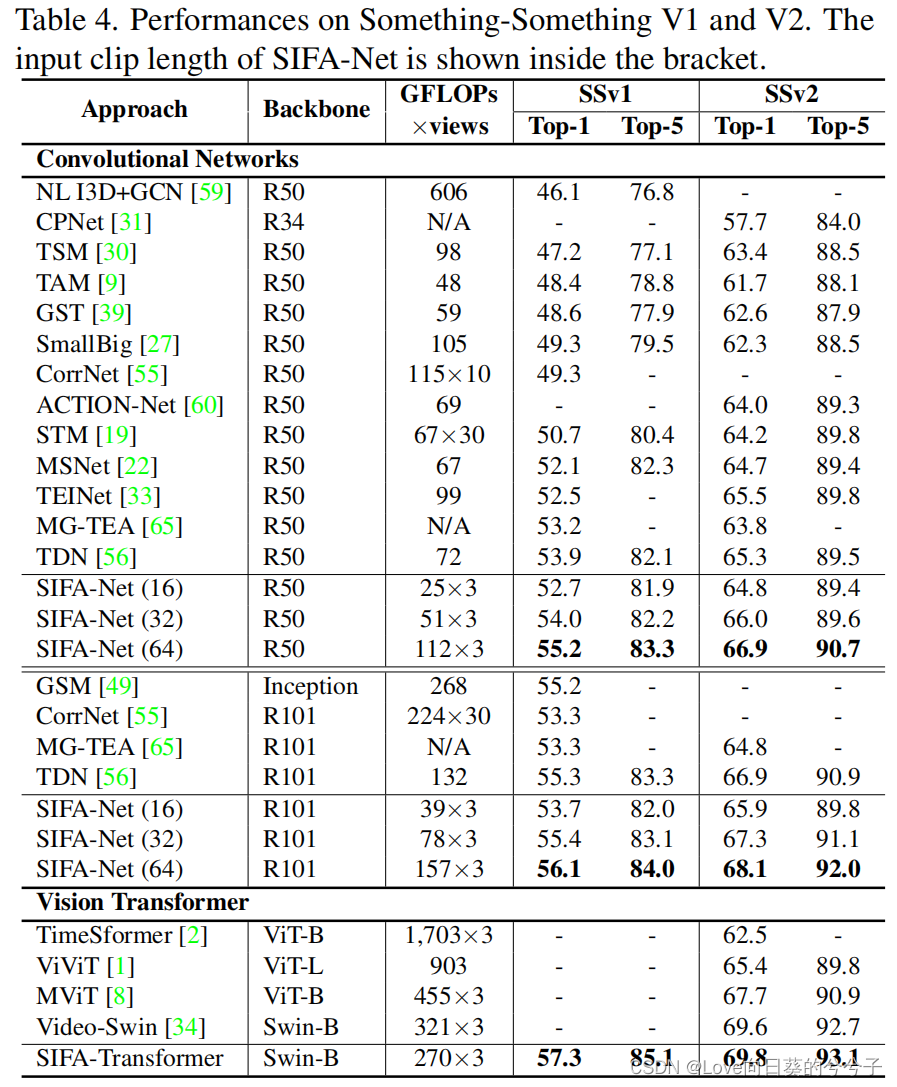
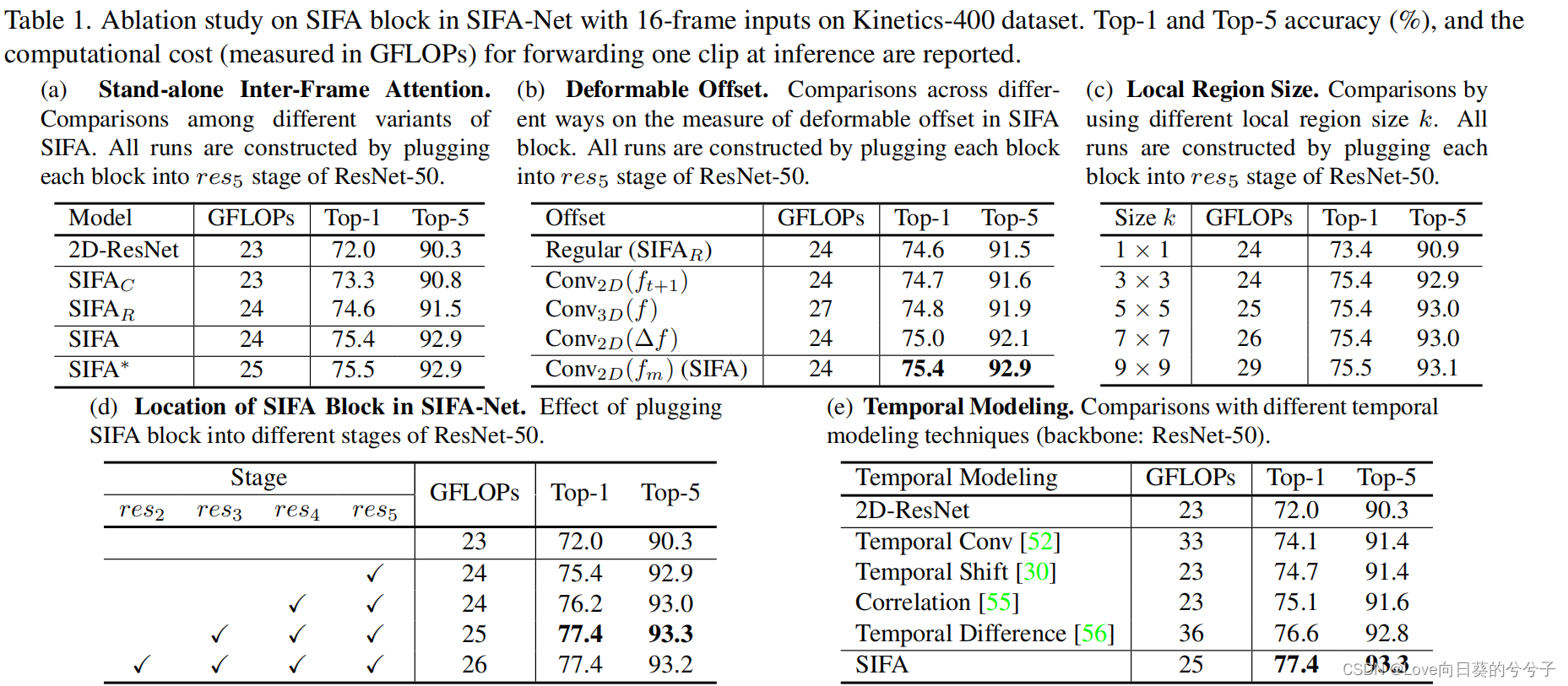
- 成分分析
- SIFA的可视化

5. Conclusion
本文提出了 Stand-alone Inter-Frame Attention(SIFA)块,它探索了跨帧的变形,用于局部自注意的时间建模。通过深入研究帧间的变形来推断局部变形区域内的时间注意力,以进行时间建模。具体来说,SIFA以当前帧的空间位置为查询对象,对下一帧局部邻近区域的键/值进行自注意。此外,针对下一帧目标的不规则变形,利用可变形设计来估计局部区域内各个空间位置的偏移量,从而得到在一次变形中重新采样的键/值。这种可变形的特征重采样被运动线索重新缩放,以促进帧间注意学习。最后,对所有可变形值进行聚合,增强帧内特征。通过将SIFA块插入ResNet和Swin Transformer中,构建了两个新的视频骨干(SIFANet和SIFA-Transformer),并在四个动作识别数据集上进行了实验验证。
仅供参考,有任何问题欢迎一起讨论O(∩_∩)O