在DevOps席卷软件工程领域之前,一旦他们的应用程序启动并开始运行,应用程序便如黑盒一般,开发人员无从知晓。工程师往往等到客户或者相关使用者抱怨“网站访问缓慢”或者503页面过多时,才会发现系统何时发生了中断。
不幸的是,这导致相同的错误反复发生,因为开发人员缺乏对应用程序性能的洞察力,并且一旦出现故障,不知道从哪里开始调试他们的代码。
那解决方案呢?现在广泛采用的DevOps概念是一种新方法,它要求在软件部署和开发过程中开发人员 (Dev) 和运维团队 (Ops)之间进行协作和持续迭代。
到了2015年左右,Netflix、Uber 和 Airbnb等大型数据导向的公司已经采用持续集成/持续部署 (CI/CD) 原则,甚至构建开源工具来促进数据团队的成长,于是DataOps诞生了。事实上,如果不管数据工程师有没有意识到这一点,他都可能已经将DataOps流程和技术应用到堆栈中了。在过去的几年里, DataOps作为一个框架在各种规模的数据团队中越来越受欢迎,它支持快速部署数据流水线,同时仍然提供可靠的、值得信赖的、随时可用的数据。
什么是DataOps?
DataOps是一门融合数据工程和数据科学团队以满足企业在数据方面的需求的方法论,类似于DevOps帮助扩展软件工程的方式。与 DevOps将 CI/CD 应用于软件开发和运维的方式类似,DataOps需要一种类似于CI/CD、自动化优先的方法来构建和扩展数据产品。同时, DataOps使数据工程团队更容易为分析师和其他下游使用人员提供可靠的数据来驱动决策。
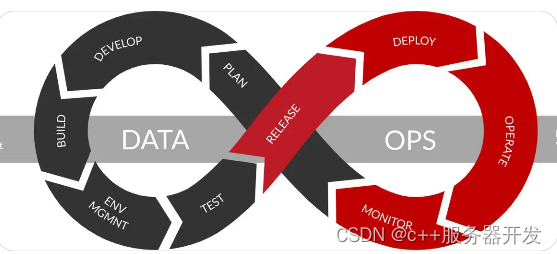
DataOps与DevOps
虽然DataOps与DevOps有许多相似之处,但两者之间也有重要区别。
其中关键区别是DevOps是一种将开发和运维团队聚集在一起,以提高软件开发和交付效率的方法,而DataOps专注于打破数据生产者和数据消费者之间的孤岛,使数据更加可靠和更有价值。
多年来,DevOps团队已成为大多数科技企业不可或缺的一部分,消除了软件开发人员和IT人员之间的隔阂,促进了软件无缝且可靠地发布到产品中。随着DevOps在企业中越来越受欢迎,支持它们的技术栈开始变得越来越复杂。为了保持系统整体处于健康状况,DevOps工程师利用可观察性来监控、跟踪和分类事件,以防止应用程序停机。
软件可观察性包括三个支柱
日志:记录给定时间戳发生的事件,同时为发生的特定事件提供上下文。
指标:用数字表示一段时间内测量的数据。
跟踪:表示分布式环境中相互关联的事件。
总之,可观察性的三个支柱使DevOps团队能够预测未来的行为并信任他们的应用程序。
类似地,DataOps原则可帮助团队消除隔阂并更有效地工作,从而在整个企业内交付高质量的数据产品。随着公司开始从各种来源获取大量数据,DataOps专业人员还利用可观察性来减少停机时间。数据可观察性是企业充分了解其系统中数据健康状况的能力。它通过对在数天、数周甚至数月内未被检测到的事件进行监控和告警,从而降低数据停机时间的频率和影响(数据不完整、错误、丢失或其他不准确的时间段)。与软件可观察性一样,数据可观察性包括自己的一组支柱。
新鲜度:数据是最新的吗?最后一次更新是什么时候?
分布:数据是否在可接受的范围内?是否符合预期的格式吗?
卷:所有数据都到了吗?表中是否有重复或删除的数据?
架构:架构是什么,它有变化吗?对架构的更改是主动进行的吗?
沿袭:哪些上游和下游的相关性连接到给定的数据资产?谁依赖这些数据进行决策,这些数据在哪些表中?
DataOps框架
为了更快、更可靠地洞察数据, DataOps团队应用了一个持续的反馈循环,也称为DataOps生命周期。DataOps生命周期是从DevOps生命周期中汲取灵感,但考虑到数据不断变化的特性,它融合了不同的技术和流程。DataOps生命周期允许数据团队和业务团队协同工作,为企业提供更可靠的数据和分析。以下是实际的DataOps生命周期。
规划:与产品、工程和业务团队合作,为数据的质量和可用性设置KPI、SLA和SLI。
开发:构建数据产品和机器学习模型,为数据应用程序提供生产力。
集成:将代码和数据产品(或其中之一)集成到现有的技术和数据栈中(或其中之一),例如,将DBT模型与Airflow集成,以便DBT模块可以自动运行。
测试:测试数据以确保其符合业务逻辑并满足基本操作阈值(例如数据的唯一性或无空值)。
发布:将数据发布到测试环境中。
部署:将数据合并到生产环境中。
操作:将数据运行到应用程序中,例如为机器学习模型提供数据的Looker或Tableau仪表板和数据加载器。
监控:持续监控数据中的任何异常并发出警报。
这个循环会不断重复。通过将DevOps的类似原则应用于数据流水线,数据团队可以更好地协作,从而一开始就识别、解决甚至防止数据质量问题的发生。
DataOps的五个最佳实践
与我们在软件开发领域的朋友类似,数据团队也开始效仿,将数据视为产品。
数据是企业决策过程的关键部分,将产品管理思维应用到如何构建、监控和测量数据产品,有助于确保这些决策能基于准确、可靠的信息。在过去几年与数百个数据团队交谈后,我们总结了五个关键的DataOps最佳实践,可以帮助您更好地适应这种“数据即产品”的方法。
1、尽早让有关人员在KPI上达成一致,并定期重新审视它们
既然企业将数据视为产品,那么内部有关人员就是企业的客户。因此,尽早与数据的关键有关人员保持一致,并就谁使用数据、他们如何使用数据以及用于什么目的达成一致是至关重要的。为关键数据集制订服务水平协议(SLA)也很重要。与有关人员就“什么样的数据质量标准才是对的”达成一致,有助于企业避免在哪些是KPI,哪些是无关紧要的指标,以及类似的问题反复讨论。
在和有关人员达成一致看法后,企业应该定期与他们核对以确保优先级仍然一致。Red Ventures的高级数据科学家Brandon Beidel每周与公司的每个业务团队会面,讨论团队在 SLA方面的进展。
“我总是用简单的商业术语来企业对话,并专注于谁、什么、何时、何地以及为什么”,布兰登告诉我们。“我特别想问一些关于数据新鲜度限制的问题,我发现这对业务有关人员特别重要。”
2、尽可能多的任务自动化
DataOps的主要关注点之一是数据工程自动化。数据团队可以将通常需要数小时才能完成的机械任务自动化,例如单元测试、硬编码获取管道和工作流编排。通过使用自动化解决方案,团队可以减少人为错误进入数据流水线的可能性并提高可靠性,同时帮助企业做出更好、更快的基于数据的决策。
3、拥抱“交付和迭代”文化
对于大多数数据驱动的企业而言,速度至关重要。而且,数据产品并不需要百分百完美才能增加价值。我的建议就是构建一个基本的MVP,对其进行测试,评估学习成果,并根据需要进行修改。我的第一手经验表明,通过在生产中使用实时数据进行测试和迭代,可以更快地构建成功的数据产品。团队可以与相关人员协作,监控、测试和分析模式,以解决任何问题并改善结果。如果经常这样做,将会有更少的错误并降低错误进入数据流水线的可能性。
4、引进自助服务工具
DataOps的一个重要好处是消除了数据在业务人员和数据工程师之间的隔阂。为了做到这一点,业务用户需要能够通过自助工具满足自己的数据需求。业务人员可以在需要时访问他们需要的数据,而不是让数据团队来满足业务用户的临时请求(这最终会减缓决策制定的速度)。Intuit的前工程副总裁Mammad Zadeh认为,自助服务工具在跨企业启用DataOps方面发挥至关重要的作用。“数据中心团队应确保数据的生产者和使用者都可以使用正确的自助式基础设施和工具,以便他们能够轻松完成工作,”Mammad告诉我们,“为他们配备正确的工具,让他们直接互动,不要设置任何障碍。”
5、优先考虑数据质量,然后才是扩展规模
在扩展的同时保持高数据质量并非易事。因此,从最重要的数据资产开始——没错,就是有关人员在做出重要决策时所依赖的信息。
如果数据资产中不准确的数据可能意味着时间、资源和收入的损失,请注意这些数据以及通过数据质量功能(如测试、监控和警报)支持这些决策的实施。然后,继续构建企业的能力以涵盖更多数据生命周期。