目录
2.1 参数的硬共享机制(hard parameter sharing)
2.2 参数的软共享机制(soft parameter sharing)
一、前言及定义
多任务学习(Multi-task learning)是和单任务学习(single-task learning)相对的一种机器学习方法。在机器学习领域,标准的算法理论是一次学习一个任务,也就是系统的输出为实数的情况。复杂的学习问题先被分解成理论上独立的子问题,然后分别对每个子问题进行学习,最后通过对子问题学习结果的组合建立复杂问题的数学模型。多任务学习是一种联合学习,多个任务并行学习,结果相互影响。
用大家经常使用的school data做个简单的对比,school data是用来预测学生成绩的回归问题的数据集,总共有139个中学的15362个学生,其中每一个中学都可以看作是一个预测任务。单任务学习就是忽略任务之间可能存在的关系分别学习139个回归函数进行分数的预测,或者直接将139个学校的所有数据放到一起学习一个回归函数进行预测。而多任务学习则看重 任务之间的联系,通过联合学习,同时对139个任务学习不同的回归函数,既考虑到了任务之间的差别,又考虑到任务之间的联系,这也是多任务学习最重要的思想之一。
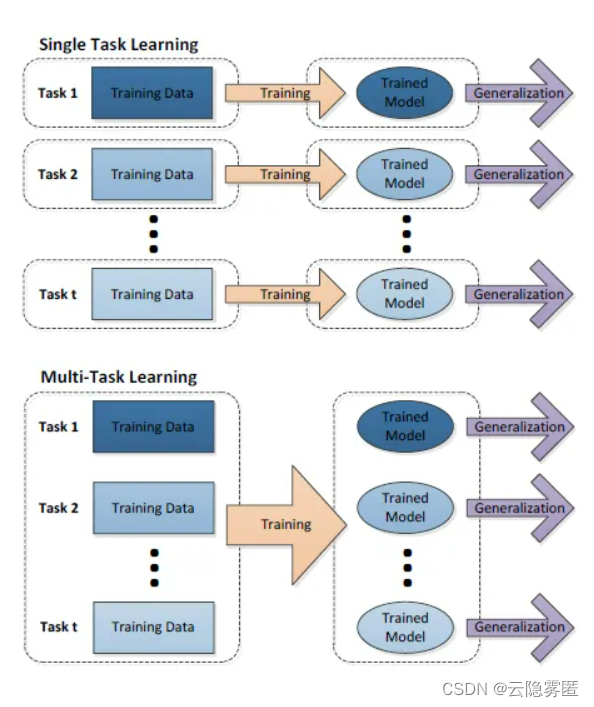
如果用含一个隐含层的神经网络来表示学习一个任务,单任务学习和多任务学习可以表示成下图所示:

二、多任务学习(MTL)的两种方法
2.1 参数的硬共享机制(hard parameter sharing)

2.2 参数的软共享机制(soft parameter sharing)

在这种方法下,每个任务都有自己的模型,有自己的参数,但是对不同模型之间的参数是有限制的,不同模型的参数之间必须相似,由此会有个distance描述参数之间的相似度,会作为额外的任务加入到模型的学习中,类似正则化项。
三、多任务学习模型
3.1 MT-DNN

3.2 ERNIE 2.0

- ERNIE模型原有的单词、实体、短语掩码模型;
- 单词的大写(Capitalization)预测;
- 单词--文档关系预测(预测输入文本块中的词是否出现在同一文档的其他文本块)。
- 句子重排序:对于随机打乱的文本块,恢复其原始顺序;
- 句子距离预测:判断输入的两个句子是来自同一文档的两个相邻句子,或是同一文档的两个不相邻句子,或来自不同文档。因此是一个多分类问题。
- 篇章关系(Discourse relation)预测:对句对间的修辞关系分类。这里用到了由无监督方法构建的篇章关系数据集;
- 信息检索相关性(IR Relevance)。这里需要用到搜索引擎的查询日志:取搜索引擎的查询与文档的标题作为模型的输入句对,如果该文档没有出现在搜索结果中,则认为两者不相关。否则,根据用户是否点击进一步分为强相关与弱相关。
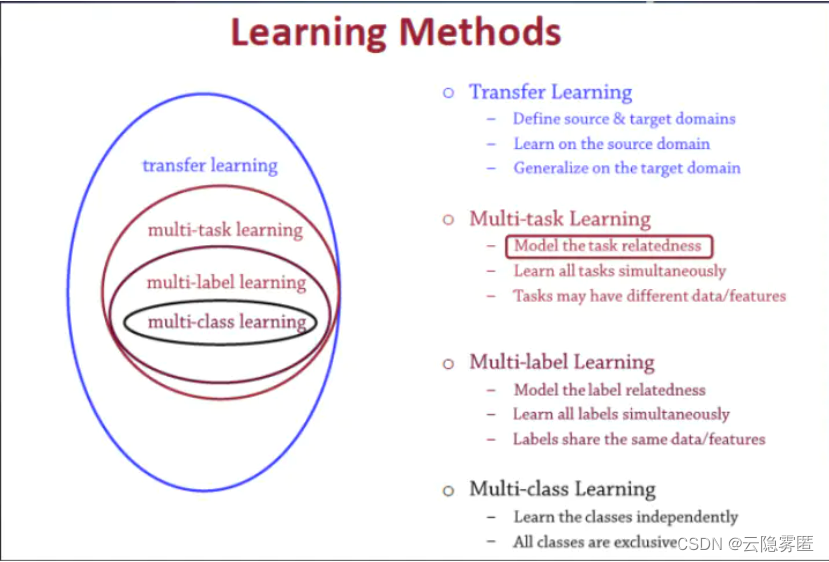
四、多任务学习与其他学习算法的关系
-
transfer learning:定义一个源域一个目标域,从源域学习,然后把学习的知识信息迁移到目标域中,从而提升目标域的泛化效果。迁移学习一个非常经典的案例就是图像处理中的风格迁移
-
multi-task:训练模型的时候目标是多个相关目标共享一个表征,比如人的特征学习,一个人,既可以从年轻人和老人这方面分类,也可以从男人女人这方面分类,这两个目标联合起来学习人的特征模型,可以学习出来一个共同特征,适用于这两种分类结果,这就是多任务学习
-
multi-label:打多个标签,或者说进行多种分类,还是拿人举例啊,一个人,他可以被打上标签{青年,男性,画家}这些标签。如果还有一个人他也是青年男性,但不是画家,那就只能打上标签{青年,男性}。它和多任务学习不一样,它的目标不是学习出一个共同的表示,而是多标签
-
multi-class:多分类问题,可选类别有多个但是结果只能分到一类中,比如一个人他是孩子、少年、中年人还是老人