正确答案: C 你的答案: C (正确)
程序计数器是一个比较小的内存区域,用于指示当前线程所执行的字节码执行到了第几行,是线程隔离的
虚拟机栈描述的是Java方法执行的内存模型,用于存储局部变量,操作数栈,动态链接,方法出口等信息,是线程隔离的
方法区用于存储JVM加载的类信息、常量、静态变量、以及编译器编译后的代码等数据,是线程隔离的
原则上讲,所有的对象都在堆区上分配内存,是线程之间共享的
正确答案: C 你的答案: C (正确)
JDBC提供了Statement、PreparedStatement 和 CallableStatement三种方式来执行查询语句,其中 Statement 用于通用查询, PreparedStatement 用于执行参数化查询,而 CallableStatement则是用于存储过程
对于PreparedStatement来说,数据库可以使用已经编译过及定义好的执行计划,由于 PreparedStatement 对象已预编译过,所以其执行速度要快于 Statement 对象”
PreparedStatement中,“?” 叫做占位符,一个占位符可以有一个或者多个值
PreparedStatement可以阻止常见的SQL注入式攻击
1.Statement、PreparedStatement和CallableStatement都是接口(interface)。
2.Statement继承自Wrapper、PreparedStatement继承自Statement、CallableStatement继承自PreparedStatement。
3.
Statement接口提供了执行语句和获取结果的基本方法;
PreparedStatement接口添加了处理 IN 参数的方法;
CallableStatement接口添加了处理 OUT 参数的方法。
4.
a.Statement:
普通的不带参的查询SQL;支持批量更新,批量删除;
b.PreparedStatement:
可变参数的SQL,编译一次,执行多次,效率高;
安全性好,有效防止Sql注入等问题;
支持批量更新,批量删除;
c.CallableStatement:
继承自PreparedStatement,支持带参数的SQL操作;
支持调用存储过程,提供了对输出和输入/输出参数(INOUT)的支持;
Statement每次执行sql语句,数据库都要执行sql语句的编译 ,
最好用于仅执行一次查询并返回结果的情形,效率高于PreparedStatement。
PreparedStatement是预编译的,使用PreparedStatement有几个好处
1. 在执行可变参数的一条SQL时,PreparedStatement比Statement的效率高,因为DBMS预编译一条SQL当然会比多次编译一条SQL的效率要高。
2. 安全性好,有效防止Sql注入等问题。
3. 对于多次重复执行的语句,使用PreparedStament效率会更高一点,并且在这种情况下也比较适合使用batch;
4. 代码的可读性和可维护性。
下面有关SPRING的事务传播特性,说法错误的是?
正确答案: B 你的答案: B (正确)
PROPAGATION_SUPPORTS:支持当前事务,如果当前没有事务,就以非事务方式执行
PROPAGATION_REQUIRED:支持当前事务,如果当前没有事务,就抛出异常
PROPAGATION_REQUIRES_NEW:新建事务,如果当前存在事务,把当前事务挂起
PROPAGATION_NESTED:支持当前事务,新增Savepoint点,与当前事务同步提交或回滚
事务属性的种类: 传播行为、隔离级别、只读和事务超时
a) 传播行为定义了被调用方法的事务边界。
传播行为 |
意义 |
PROPERGATION_MANDATORY |
表示方法必须运行在一个事务中,如果当前事务不存在,就抛出异常 |
PROPAGATION_NESTED |
表示如果当前事务存在,则方法应该运行在一个嵌套事务中。否则,它看起来和PROPAGATION_REQUIRED 看起来没什么俩样 |
PROPAGATION_NEVER |
表示方法不能运行在一个事务中,否则抛出异常 |
PROPAGATION_NOT_SUPPORTED |
表示方法不能运行在一个事务中,如果当前存在一个事务,则该方法将被挂起 |
PROPAGATION_REQUIRED |
表示当前方法必须运行在一个事务中,如果当前存在一个事务,那么该方法运行在这个事务中,否则,将创建一个新的事务 |
PROPAGATION_REQUIRES_NEW |
表示当前方法必须运行在自己的事务中,如果当前存在一个事务,那么这个事务将在该方法运行期间被挂起 |
PROPAGATION_SUPPORTS |
表示当前方法不需要运行在一个是事务中,但如果有一个事务已经存在,该方法也可以运行在这个事务中 |
b) 隔离级别
在操作数据时可能带来 3 个副作用,分别是脏读、不可重复读、幻读。为了避免这 3 中副作用的发生,在标准的 SQL 语句中定义了 4 种隔离级别,分别是未提交读、已提交读、可重复读、可序列化。而在 spring 事务中提供了 5 种隔离级别来对应在SQL 中定义的 4 种隔离级别,如下:
隔离级别 |
意义 |
ISOLATION_DEFAULT |
使用后端数据库默认的隔离级别 |
ISOLATION_READ_UNCOMMITTED |
允许读取未提交的数据(对应未提交读),可能导致脏读、不可重复读、幻读 |
ISOLATION_READ_COMMITTED |
允许在一个事务中读取另一个已经提交的事务中的数据(对应已提交读)。可以避免脏读,但是无法避免不可重复读和幻读 |
ISOLATION_REPEATABLE_READ |
一个事务不可能更新由另一个事务修改但尚未提交(回滚)的数据(对应可重复读)。可以避免脏读和不可重复读,但无法避免幻读 |
ISOLATION_SERIALIZABLE |
这种隔离级别是所有的事务都在一个执行队列中,依次顺序执行,而不是并行(对应可序列化)。可以避免脏读、不可重复读、幻读。但是这种隔离级别效率很低,因此,除非必须,否则不建议使用。 |
c) 只读
如果在一个事务中所有关于数据库的操作都是只读的,也就是说,这些操作只读取数据库中的数据,而并不更新数据,那么应将事务设为只读模式( READ_ONLY_MARKER ) , 这样更有利于数据库进行优化 。
因为只读的优化措施是事务启动后由数据库实施的,因此,只有将那些具有可能启动新事务的传播行为(PROPAGATION_NESTED 、 PROPAGATION_REQUIRED 、 PROPAGATION_REQUIRED_NEW) 的方法的事务标记成只读才有意义。
如果使用 Hibernate 作为持久化机制,那么将事务标记为只读后,会将 Hibernate 的 flush 模式设置为FULSH_NEVER, 以告诉 Hibernate 避免和数据库之间进行不必要的同步,并将所有更新延迟到事务结束。
d) 事务超时
如果一个事务长时间运行,这时为了尽量避免浪费系统资源,应为这个事务设置一个有效时间,使其等待数秒后自动回滚。与设
置“只读”属性一样,事务有效属性也需要给那些具有可能启动新事物的传播行为的方法的事务标记成只读才有意义。
下面有关servlet和cgi的描述,说法错误的是?
正确答案: D 你的答案: D (正确)
servlet处于服务器进程中,它通过多线程方式运行其service方法
CGI对每个请求都产生新的进程,服务完成后就销毁
servlet在易用性上强于cgi,它提供了大量的实用工具例程,例如自动地解析和解码HTML表单数据、读取和设置HTTP头、处理Cookie、跟踪会话状态等
cgi在移植性上高于servlet,几乎所有的主流服务器都直接或通过插件支持cgi
选择D,servlet处于服务器进程中,它通过多线程方式运行其service方法,一个实例可以服务于多个请求,并且其实例一般不会销毁,而CGI对每个请求都产生新的进程,服务完成后就销毁,所以效率上低于servlet。
下面有关servlet service描述错误的是?
正确答案: B 你的答案: B (正确)
不管是post还是get方法提交过来的连接,都会在service中处理
doGet/doPost 则是在 javax.servlet.GenericServlet 中实现的
service()是在javax.servlet.Servlet接口中定义的
service判断请求类型,决定是调用doGet还是doPost方法
doGet/doPost 则是在 javax.servlet.http.HttpServlet 中实现的
下列有关Servlet的生命周期,说法不正确的是?
正确答案: A 你的答案: A (正确)
在创建自己的Servlet时候,应该在初始化方法init()方法中创建Servlet实例
在Servlet生命周期的服务阶段,执行service()方法,根据用户请求的方法,执行相应的doGet()或是doPost()方法
在销毁阶段,执行destroy()方法后会释放Servlet 占用的资源
destroy()方法仅执行一次,即在服务器停止且卸载Servlet时执行该方法
创建Servlet的实例是由Servlet容器来完成的,且创建Servlet实例是在初始化方法init()之前
Servlet的生命周期分为5个阶段:加载、创建、初始化、处理客户请求、卸载。
(1)加载:容器通过类加载器使用servlet类对应的文件加载servlet
(2)创建:通过调用servlet构造函数创建一个servlet对象
(3)初始化:调用init方法初始化
(4)处理客户请求:每当有一个客户请求,容器会创建一个线程来处理客户请求
(5)卸载:调用destroy方法让servlet自己释放其占用的资源
下面有关servlet中init,service,destroy方法描述错误的是?
正确答案: D 你的答案: D (正确)
init()方法是servlet生命的起点。一旦加载了某个servlet,服务器将立即调用它的init()方法
service()方法处理客户机发出的所有请求
destroy()方法标志servlet生命周期的结束
servlet在多线程下使用了同步机制,因此,在并发编程下servlet是线程安全的
servlet在多线程下其本身并不是线程安全的。
如果在类中定义成员变量,而在service中根据不同的线程对该成员变量进行更改,那么在并发的时候就会引起错误。最好是在方法中,定义局部变量,而不是类变量或者对象的成员变量。由于方法中的局部变量是在栈中,彼此各自都拥有独立的运行空间而不会互相干扰,因此才做到线程安全。
下面有关struts1和struts2的区别,描述错误的是?
正确答案: B 你的答案: 空 (错误)
Struts1要求Action类继承一个抽象基类。Struts 2 Action类可以实现一个Action接口
Struts1 Action对象为每一个请求产生一个实例。Struts2 Action是单例模式并且必须是线程安全的
Struts1 Action 依赖于Servlet API,Struts 2 Action不依赖于容器,允许Action脱离容器单独被测试
Struts1 整合了JSTL,Struts2可以使用JSTL,但是也支持OGNL
从action类上分析:
1.Struts1要求Action类继承一个抽象基类。Struts1的一个普遍问题是使用抽象类编程而不是接口。
2. Struts 2 Action类可以实现一个Action接口,也可实现其他接口,使可选和定制的服务成为可能。Struts2提供一个ActionSupport基类去实现常用的接口。Action接口不是必须的,任何有execute标识的POJO对象都可以用作Struts2的Action对象。
从Servlet 依赖分析:
3. Struts1 Action 依赖于Servlet API ,因为当一个Action被调用时HttpServletRequest 和 HttpServletResponse 被传递给execute方法。
4. Struts 2 Action不依赖于容器,允许Action脱离容器单独被测试。如果需要,Struts2 Action仍然可以访问初始的request和response。但是,其他的元素减少或者消除了直接访问HttpServetRequest 和 HttpServletResponse的必要性。
从action线程模式分析:
5. Struts1 Action是单例模式并且必须是线程安全的,因为仅有Action的一个实例来处理所有的请求。单例策略限制了Struts1 Action能作的事,并且要在开发时特别小心。Action资源必须是线程安全的或同步的。
6. Struts2 Action对象为每一个请求产生一个实例,因此没有线程安全问题。(实际上,servlet容器给每个请求产生许多可丢弃的对象,并且不会导致性能和垃圾回收问题)
关于AWT和Swing说法正确的是?
正确答案: D 你的答案: 空 (错误)
Swing是AWT的子类
AWT在不同操作系统中显示相同的风格
AWT不支持事件类型,Swing支持事件模型
Swing在不同的操作系统中显示相同的风格
AWT :是通过调用操作系统的native方法实现的,所以在Windows系统上的AWT窗口就是Windows的风格,而在Unix系统上的则是XWindow风格。 AWT 中的图形函数与 操作系统 所提供的图形函数之间有着一一对应的关系,我们把它称为peers。 也就是说,当我们利用 AWT 来构件图形用户界面的时候,我们实际上是在利用 操作系统 所提供的图形库。由于不同 操作系统 的图形库所提供的功能是不一样的,在一个平台上存在的功能在另外一个平台上则可能不存在。为了实现Java语言所宣称的"一次编译,到处运行"的概念,AWT 不得不通过牺牲功能来实现其平台无关性,也就是说,AWT 所提供的图形功能是各种通用型操作系统所提供的图形功能的交集。由于AWT 是依靠本地方法来实现其功能的,我们通常把AWT控件称为重量级控件。
Swing :是所谓的Lightweight组件,不是通过native方法来实现的,所以Swing的窗口风格更多样化。但是,Swing里面也有heaveyweight组件。比如JWindow,Dialog,JFrame
Swing是所谓的Lightweight组件,不是通过native方法来实现的,所以Swing的窗口风格更多样化。但是,Swing里面也有heaveyweight组件。比如JWindow,Dialog,JFrame
Swing由纯Java写成,可移植性好,外观在不同平台上相同。所以Swing部件称为轻量级组件( Swing是由纯JAVA CODE所写的,因此SWING解决了JAVA因窗口类而无法跨平台的问题,使窗口功能也具有跨平台与延展性的特性,而且SWING不需占有太多系统资源,因此称为轻量级组件!!!)
看以下代码:
文件名称:forward.jsp
<html>
<head><title> 跳转 </title> </head>
<body>
<jsp:forward page="index.htm"/>
</body>
</html>
如果运行以上jsp文件,地址栏的内容为
正确答案: A 你的答案: A (正确)
http://127.0.0.1:8080/myjsp/forward.jsp
http://127.0.0.1:8080/myjsp/index.jsp
http://127.0.0.1:8080/myjsp/index.htm
http://127.0.0.1:8080/myjsp/forward.htm
forward和redirect是最常问的两个问题
forward,服务器获取跳转页面内容传给用户,用户地址栏不变
redirect,是服务器向用户发送转向的地址,redirect后地址栏变成新的地址
因此这个题是A
下面哪一项不是加载驱动程序的方法?
正确答案: A 你的答案: B (错误)
通过DriverManager.getConnection方法加载
调用方法 Class.forName
通过添加系统的jdbc.drivers属性
通过registerDriver方法注册
DriverManager.getConnection方法返回一个Connection对象,这是加载驱动之后才能进行的
关于sleep()和wait(),以下描述错误的一项是( )
正确答案: D 你的答案: D (正确)
sleep是线程类(Thread)的方法,wait是Object类的方法;
sleep不释放对象锁,wait放弃对象锁
sleep暂停线程、但监控状态仍然保持,结束后会自动恢复
wait后进入等待锁定池,只有针对此对象发出notify方法后获得对象锁进入运行状态
D错是因为进入的是就绪状态而不是运行状态
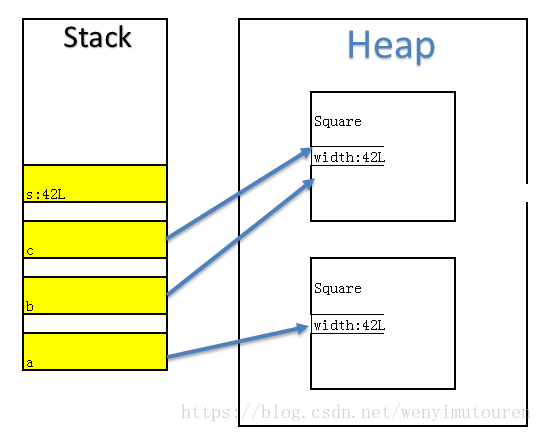
根据下面的程序代码,哪些选项的值返回true?
public class Square {
long width;
public Square(long l) {
width = l;
}
public static void main(String arg[]) {
Square a, b, c;
a = new Square(42L);
b = new Square(42L);
c = b;
long s = 42L;
}
}
正确答案: C 你的答案: C (正确)
a == b
s == a
b == c
a.equals(s)
在jdk1.5的环境下,有如下4条语句:
Integer i01 = 59;
int i02 = 59;
Integer i03 =Integer.valueOf(59);
Integer i04 = new Integer(59)。
以下输出结果为false的是:
正确答案: C 你的答案: C (正确)
System.out.println(i01== i02);
System.out.println(i01== i03);
System.out.println(i03== i04);
System.out.println(i02== i04);
C选项i03和i04是两个不同的对象,返回false
D选项i02是基本数据类型,比较的时候比较的是数值,返回true
下面哪个不对?
正确答案: C 你的答案: B (错误)
RuntimeException is the superclass of those exceptions that can be thrown during the normal operation of the Java Virtual Machine.
A method is not required to declare in its throws clause any subclasses of RuntimeExeption that might be thrown during the execution of the method but not caught
An RuntimeException is a subclass of Throwable that indicates serious problems that a reasonable application should not try to catch.
NullPointerException is one kind of RuntimeException
Error是 indicates serious problems

运行时异常的特点是Java编译器不会检查它,也就是说,当程序中可能出现这类异常,即使没有用try-catch语句捕获它,也没有用throws子句声明抛出它,也会编译通过。
非运行时异常 (编译异常): 是RuntimeException以外的异常,类型上都属于Exception类及其子类。从程序语法角度讲是必须进行处理的异常,如果不处理,程序就不能编译通过。如IOException、SQLException等以及用户自定义的Exception异常,一般情况下不自定义检查异常。
1. public class HasStatic{
2. private static int x=100;
3. public static void main(String args[]){
4. HasStatic hs1=new HasStatic();
5. hs1.x++;
6. HasStatic hs2=new HasStatic();
7. hs2.x++;
8. hs1=new HasStatic();
9. hs1.x++;
10. HasStatic.x--;
11. System.out.println("x="+x);
12. }
13. }
正确答案: D 你的答案: D (正确)
程序通过编译,输出结果为:x=103
10行不能通过编译,因为x是私有静态变量
5行不能通过编译,因为引用了私有静态变量
程序通过编译,输出结果为:x=102
关于struts项目中的类与MVC模式的对应关系,说法错误的是
正确答案: C D 你的答案: D (错误)
Jsp文件实现视图View的功能
ActionServlet这一个类是整个struts项目的控制器
ActionForm、Action都属于Model部分
一个struts项目只能有一个Servlet

下面有关jsp中静态include和动态include的区别,说法错误的是?
正确答案: D 你的答案: D (正确)
动态INCLUDE:用jsp:include动作实现
静态INCLUDE:用include伪码实现,定不会检查所含文件的变化,适用于包含静态页面<%@ include file="included.htm" %>
静态include的结果是把其他jsp引入当前jsp,两者合为一体;动态include的结构是两者独立,直到输出时才合并
静态include和动态include都可以允许变量同名的冲突.页面设置也可以借用主文件的
动态 INCLUDE 用 jsp:include 动作实现 <jsp:include page="included.jsp" flush="true" /> 它总是会检查所含文件中的变化 , 适合用于包含动态页面 , 并且可以带参数。各个文件分别先编译,然后组合成一个文件。
静态 INCLUDE 用 include 伪码实现 , 定不会检查所含文件的变化 , 适用于包含静态页面 <%@ include file="included.htm" %> 。先将文件的代码被原封不动地加入到了主页面从而合成一个文件,然后再进行翻译,此时不允许有相同的变量。
以下是对 include 两种用法的区别 , 主要有两个方面的不同 ;
一 : 执行时间上 :
<%@ include file="relativeURI"%> 是在翻译阶段执行
<jsp:include page="relativeURI" flush="true" /> 在请求处理阶段执行 .
二 : 引入内容的不同 :
<%@ include file="relativeURI"%>
引入静态文本 (html,jsp), 在 JSP 页面被转化成 servlet 之前和它融和到一起 .
<jsp:include page="relativeURI" flush="true" /> 引入执行页面或 servlet 所生成的应答文本 .
给定以下JAVA代码,这段代码运行后输出的结果是()
public class Test
{
public static int aMethod(int i)throws Exception
{
try{
return i / 10;
}
catch (Exception ex)
{
throw new Exception("exception in a Method");
} finally{
System.out.printf("finally");
}
}
public static void main(String [] args)
{
try
{
aMethod(0);
}
catch (Exception ex)
{
System.out.printf("exception in main");
}
System.out.printf("finished");
}
}
正确答案: B 你的答案: B (正确)
exception in main finished
finally finished
exception in main finally
finally exception in main finished
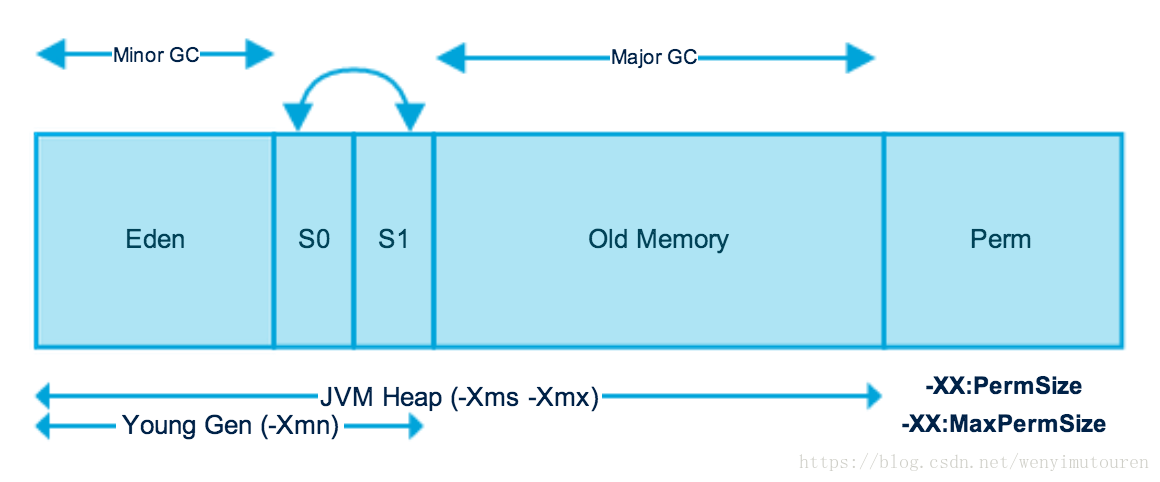
对于JVM内存配置参数:
-Xmx10240m -Xms10240m -Xmn5120m -XXSurvivorRatio=3
,其最小内存值和Survivor区总大小分别是()
正确答案: D 你的答案: C (错误)
5120m,1024m
5120m,2048m
10240m,1024m
10240m,2048m
-Xmx:最大堆大小
-Xms:初始堆大小
-Xmn:年轻代大小
-XXSurvivorRatio:年轻代中Eden区与Survivor区的大小比值
年轻代5120m, Eden:Survivor=3,Survivor区大小=1024m(Survivor区有两个,即将年轻代分为5份,每个Survivor区占一份),总大小为2048m。
-Xms初始堆大小即最小内存值为10240m