图解NLP模型发展:从RNN到Transformer
自然语言处理 (NLP) 是深度学习中一个颇具挑战的问题,与图像识别和计算机视觉问题不同,自然语言本身没有良好的向量或矩阵结构,且原始单词的含义也不像像素值那么确定和容易表示。一般我们需要用词嵌入技术将单词转换为向量,然后再输入计算机进行计算。
词嵌入可用于多种任务,例如情感分类、文本生成、名称实体识别或机器翻译等。它以一种巧妙的处理方式,让模型在某些任务上的性能与人类能力相当。
那么,接下来的问题是:如何处理词嵌入? 如何为此类数据建立模型?这是本文接下来重点介绍的内容。

文章目录
循环神经网络(RNN)
人类的阅读习惯不会从头开始思考每个出现单词的含义,而是透过前面单词的信息来理解当前单词的含义。基于这种行为,循环神经网络 (RNN) 应运而生。
本节我们将重点关注 RNN 单元及其改进。 稍后,我们会将RNN单元组合在一起看整体架构。
普通RNN
Vanilla RNN 由若干重复单元组成,每个单元按顺序接收输入嵌入 x t x_t xt,并通过隐藏状态 h t − 1 h_{t-1} ht−1 记忆过去的序列。隐藏状态更新为 h t h_t ht 并发送到下一个单元,或者输出预测结果。下图展示了 RNN 单元的内部工作原理。
 h t = tanh ( W ⋅ [ h t − 1 , x t ] + b ) h_t = \tanh(W \sdot [h_{t-1}, x_t]+b) ht=tanh(W⋅[ht−1,xt]+b)
h t = tanh ( W ⋅ [ h t − 1 , x t ] + b ) h_t = \tanh(W \sdot [h_{t-1}, x_t]+b) ht=tanh(W⋅[ht−1,xt]+b)
优点
- 以一种自然好理解的方式处理顺序和先前输入
缺点
- 每一步的操作都依赖前一步的输出,因此很难并行化 RNN 操作。
- 处理长序列可能出现梯度爆炸或消失。
长短期记忆网络(LSTM)
解决梯度爆炸或消失问题的一种方法是使用门控 RNN,门控 RNN可以有选择地保留信息并能够学习长期依赖性。门控 RNN 有两种流行变体:长短期记忆 (LSTM) 和门控循环单元 (GRU)。

f t = σ ( W f ⋅ [ h t − 1 , x t ] + b f ) i t = σ ( W i ⋅ [ h t − 1 , x t ] + b i ) C ~ t = tanh ( W c ⋅ [ h t − 1 , x t ] + b c ) o t = σ ( W o ⋅ [ h t − 1 , x t ] + b o ) C t = f t ∘ C t − 1 + i t ∘ C ~ t h t = o t ∘ tanh ( C t ) \begin{align} f_t&=\sigma(W_f \sdot [h_{t-1}, x_t]+b_f)\notag\\ i_t&=\sigma(W_i \sdot [h_{t-1}, x_t]+b_i)\notag\\ \tilde{C}_t &= \tanh(W_c \sdot [h_{t-1}, x_t]+b_c)\notag\\ o_t&=\sigma(W_o \sdot [h_{t-1}, x_t]+b_o)\notag\\ C_t&=f_t \circ C_{t-1}+i_t \circ \tilde{C}_t\notag\\ h_t &= o_t \circ \tanh(C_t)\notag \end{align} ftitC~totCtht=σ(Wf⋅[ht−1,xt]+bf)=σ(Wi⋅[ht−1,xt]+bi)=tanh(Wc⋅[ht−1,xt]+bc)=σ(Wo⋅[ht−1,xt]+bo)=ft∘Ct−1+it∘C~t=ot∘tanh(Ct)
为了避免长期依赖问题,LSTM 配备了一个类似于高速公路的单元状态 C t C_t Ct,因此信息可以很容易地流过而不会发生变化。
为了有选择地保留信息,LSTM 也有三个门:
- 遗忘门 → \rarr → 查看 h t − 1 h_{t-1} ht−1 和 x t x_t xt,并输出一个由 0 到 1 之间的数字组成的向量 f t f_t ft,它告诉我们要从单元状态 C t − 1 C_{t-1} Ct−1 中丢弃哪些信息。
- 输入门 → \rarr → 相似遗忘门,但这次输出的 i t i_t it 用于根据虚拟单元状态 c ˊ t \acute{c}_t cˊt 来决定我们要将哪些新信息存储在单元状态中。
- 输出门 → \rarr → 相似遗忘门,但是输出 o t o_t ot用于过滤更新后的单元状态 C t C_t Ct 得到新的隐藏状态 h t h_t ht。
门控循环单元(GRU)
LSTM 非常复杂。GRU 提供与 LSTM 相似的性能,但复杂性更低(权重更少)。它合并了单元状态和隐藏状态。 还将遗忘门和输入门组合成一个“更新门”。

r t = σ ( W r ⋅ [ h t − 1 , x t ] + b r ) z t = σ ( W z ⋅ [ h t − 1 , x t ] + b z ) h ~ t = tanh ( W h ⋅ [ r t ∘ h t − 1 , x t ] + b h ) h t = ( 1 − z t ) ∘ h t − 1 + z t ∘ h ~ t \begin{align} r_t&=\sigma(W_r \sdot [h_{t-1}, x_t]+b_r)\notag\\ z_t&=\sigma(W_z \sdot [h_{t-1}, x_t]+b_z)\notag\\ \tilde{h}_t &= \tanh(W_h \sdot [r_t \circ h_{t-1}, x_t]+b_h)\notag\\ h_t &= (1-z_t) \circ h_{t-1} + z_t \circ \tilde{h}_t\notag \end{align} rtzth~tht=σ(Wr⋅[ht−1,xt]+br)=σ(Wz⋅[ht−1,xt]+bz)=tanh(Wh⋅[rt∘ht−1,xt]+bh)=(1−zt)∘ht−1+zt∘h~t
GRU中有两个门:
- 重置门 → \rarr → 查看 h t − 1 h_{t-1} ht−1和 x t x_t xt,并输出一个由 0 到 1 之间的数字组成的向量 r t r_t rt,它决定需要忽略多少过去的信息 h t − 1 h_{t-1} ht−1。
- 更新门 → \rarr → 确定我们要在新的隐藏状态 h t h_t ht中保存的信息或基于 r t r_t rt丢弃的信息。
RNN架构
当我们了解了 RNN 单元的工作原理后,就可以按一定顺序将它们连接起来。 这里,预测的输出概率 y t y_t yt 可以表示为:
y t = g ( W h t + b ) y_t = g(Wh_t+b) yt=g(Wht+b)
其中 W W W是权重, b b b是偏差, g g g是激活函数。具体选择哪个激活函数以及RNN单元如何连接取决于具体任务。

其中,上图最后一个结构(机器翻译)就是我们所谓的seq2seq模型。其中输入序列 x 1 , x 2 , … , x t x_1,x_2,\dots,x_t x1,x2,…,xt 被翻译成输出序列 y 1 , y 2 , … , y m y_1,y_2,\dots,y_m y1,y2,…,ym。前 t t t 个 RNN 单元组成编码器,后 m m m 个 RNN 单元组成解码器。
另外,RNN 单元也可以如下图一样翻转或堆叠。 此类架构通常仅由两层或三层组成。这样做可以以增加计算量为代价提高模型性能。

注意力
seq2seq 只能使用编码器最末端的输出,输入给解码器解释。解码器只能看到来自最后一个编码器 RNN 单元的输入序列。但是,输入序列的不同部分在输出序列的每个生成步骤中可能更有用。 这就是注意力的概念。
优点
- 无论输入标记的位置如何,都会考虑适当的编码表示。
缺点
- 另一个计算步骤涉及学习权重。
带注意力的seq2seq
每个解码器token会查看每个编码器token,并通过其隐藏状态来决定哪些token需要更多关注。

H = [ h 1 , h 2 , … , h t ] T Attention ( s i , H ) = softmax ( s i H T d h ) ⋅ H \begin{align} H&=[h_1, h_2, \dots, h_t]^T\notag\\ \text{Attention}(s_i, H)&=\text{softmax}(\frac{s_iH^T}{\sqrt{d_h}})\sdot H\notag \end{align} HAttention(si,H)=[h1,h2,…,ht]T=softmax(dhsiHT)⋅H
在 seq2seq 中合并注意力分为三个步骤:
- 标量注意力分数是根据一对解码器和编码器隐藏状态 ( s i , h j ) (s_i, h_j) (si,hj) 计算的,它表示编码器token j j j 与解码器token i i i 的“相关性”。
- 所有注意力分数都通过 softmax 传递以产生注意力权重,这些注意力权重形成解码器和编码器token对相关性的概率分布。
- 计算具有注意力权重的编码器隐藏状态的加权和,并将其送入到下一个解码器单元。
在上面的案例中,分数函数为
score ( s i , h j ) = s i T h j d h \text{score}(s_i, h_j) = \frac{s_i^Th_j}{\sqrt{d_h}} score(si,hj)=dhsiThj
其中 d h d_h dh 是 h j h_j hj(和 s i s_i si)的维度。
自注意力
接下来我们完全抛弃 seq2seq,只关注注意力。 一种流行的注意力机制是自注意力。自注意力不去寻找解码器token与编码器token的相关性,而是寻找一组token中的每个token与同一组中所有其他token的相关性。

X = [ x 1 , x 2 , … , x t ] T Q = [ q 1 , q 2 , … , q t ] T = X W Q K = [ k 1 , k 2 , … , k t ] T = X W K V = [ v 1 , v 2 , … , v t ] T = X W V Attension ( Q , K , V ) = softmax ( Q K T d k ) ⋅ V \begin{align} X=[x_1, x_2, \dots, x_t]^T\notag\\ Q=[q_1, q_2, \dots, q_t]^T &= XW_Q\notag\\ K=[k_1, k_2, \dots, k_t]^T &= XW_K\notag\\ V=[v_1, v_2, \dots, v_t]^T &= XW_V\notag\\ \text{Attension}(Q, K, V) &= \text{softmax}(\frac{QK^T}{\sqrt{d_k}})\sdot V\notag \end{align} X=[x1,x2,…,xt]TQ=[q1,q2,…,qt]TK=[k1,k2,…,kt]TV=[v1,v2,…,vt]TAttension(Q,K,V)=XWQ=XWK=XWV=softmax(dkQKT)⋅V
自注意力使用注意力函数创建基于输入token对之间相似性的加权表示,它提供了输入序列的丰富表示,这些表示关注其元素之间的关系。
自注意力与普通注意力之间存在三个主要区别:
- 由于自注意力中没有解码器token,取而代之的是“查询”向量 q i q_i qi,它与输入嵌入 x i x_i xi 线性相关。
- 注意分数是根据 ( q i , k j ) (q_i, k_j) (qi,kj)对计算得到的,其中 k j k_j kj 是与 q i q_i qi 具有相同维度的“关键”向量,并且也与 x j x_j xj 线性相关。
- 与普通注意力中的 k j k_j kj 再次乘以注意力权重不同,自注意力将新的“值”向量 v j v_j vj 与注意力权重相乘。 请注意, v j v_j vj 可能具有与 k j k_j kj 不同的维度,并且也与 x j x_j xj 线性相关。
多头注意力
注意力可以并行运行多次,以产生所谓的多头注意力。 然后将独立的注意力输出连接起来并线性转换为预期维度。
多头注意力允许以不同方式关注输入序列的各个部分(例如,长期依赖与短期依赖),因此它可以提高单一注意力的性能。

X = [ x 1 , x 2 , … , x t ] T Q = X W Q K = X W K V = X W V head i = Attension ( Q W Q ( i ) , K W k ( i ) , V W V ( i ) ) MultiHead ( Q , K , V ) = Concat ( head 1 , … , head n ) W 0 \begin{align} X&=[x_1, x_2, \dots, x_t]^T\notag\\ Q&=XW_Q\notag\\ K&=XW_K\notag\\ V&=XW_V\notag\\ \text{head}_i&=\text{Attension}(QW_Q^{(i)},KW_k^{(i)},VW_V^{(i)})\notag\\ \text{MultiHead}(Q,K,V) &= \text{Concat}(\text{head}_1, \dots,\text{head}_n)W_0\notag \end{align} XQKVheadiMultiHead(Q,K,V)=[x1,x2,…,xt]T=XWQ=XWK=XWV=Attension(QWQ(i),KWk(i),VWV(i))=Concat(head1,…,headn)W0
上图中的自注意力可以换成任何类型的注意力或其他实现,只要其变量的维度匹配即可。
Transformer
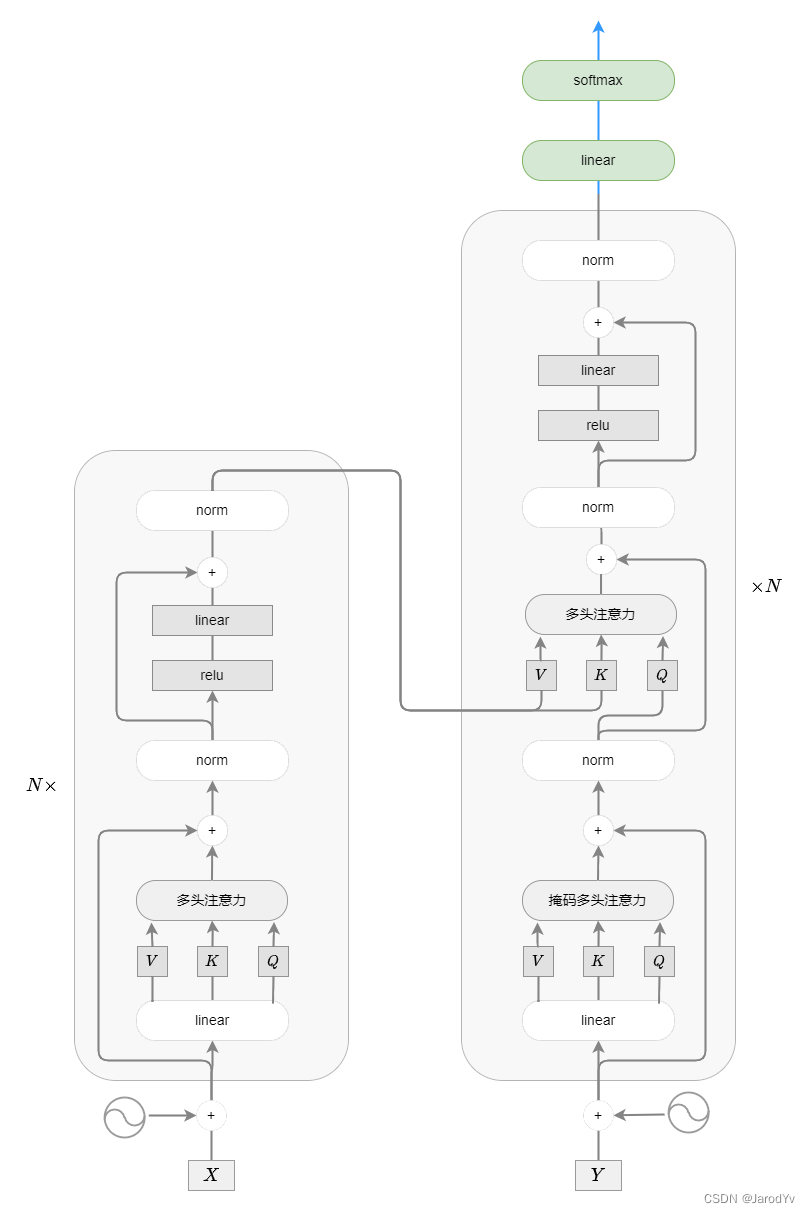
给定输入嵌入 X X X 和输出嵌入 Y Y Y,一般来说,Transformer有 N N N 个编码器堆叠而成,连接到 N N N 个解码器也堆叠在一起。 没有递归或卷积,每个编码器和解码器只需要注意力(attention is all you need)。

p i , 2 j = sin ( 1 / 1000 0 2 j / d x ) p i , 2 j + 1 = cos ( 1 / 1000 0 2 j / d x ) X = [ x 1 , x 2 , … , x t ] T + [ P i j ] Y = [ <bos> , x 1 , … , y m ] T + [ P i j ] For r = 1 , 2 , … , N X : = LayerNorm ( X + MultiHead ( X W Q , X W K , X W V ) ) X : = LayerNorm ( X + max { 0 , X W 1 ( r ) + b 1 ( r ) } W 2 ( r ) + b 2 ( r ) ) For r = 1 , 2 , … , N Y : = LayerNorm ( Y + MaskMultiHead ( Y W Q , Y W K , Y W V ) ) Y : = LayerNorm ( Y + MultiHead ( Y W Q , X W K , X W V ) ) Y : = LayerNorm ( Y + max { 0 , Y W 3 ( r ) + b 3 ( r ) } W 4 ( r ) + b 4 ( r ) ) proba = softmax ( Y W 0 ) \begin{align} p_{i, 2j}&=\sin(1/10000^{2j/d_x})\notag\\ p_{i, 2j+1}&=\cos(1/10000^{2j/d_x})\notag\\ X&=[x_1, x_2, \dots, x_t]^T+[P_{ij}]\notag\\ Y&=[\text{<bos>},x_1, \dots, y_m]^T+[P_{ij}]\notag\\ \notag\\ \text{For }r &= 1,2,\dots,N\notag\\ \quad X&:=\text{LayerNorm}(X+\text{MultiHead}(XW_Q, XW_K,XW_V))\notag\\ \quad X&:=\text{LayerNorm}(X+\max\{0,XW_1^{(r)}+b_1^{(r)}\}W_2^{(r)}+b_2^{(r)})\notag\\ \notag\\ \text{For }r &= 1,2,\dots,N\notag\\ \quad Y&:=\text{LayerNorm}(Y+\text{MaskMultiHead}(YW_Q, YW_K,YW_V))\notag\\ \quad Y&:=\text{LayerNorm}(Y+\text{MultiHead}(YW_Q, XW_K,XW_V))\notag\\ \quad Y&:=\text{LayerNorm}(Y+\max\{0,YW_3^{(r)}+b_3^{(r)}\}W_4^{(r)}+b_4^{(r)})\notag\\ \notag\\ \text{proba} &= \text{softmax}(YW_0)\notag \end{align} pi,2jpi,2j+1XYFor rXXFor rYYYproba=sin(1/100002j/dx)=cos(1/100002j/dx)=[x1,x2,…,xt]T+[Pij]=[<bos>,x1,…,ym]T+[Pij]=1,2,…,N:=LayerNorm(X+MultiHead(XWQ,XWK,XWV)):=LayerNorm(X+max{ 0,XW1(r)+b1(r)}W2(r)+b2(r))=1,2,…,N:=LayerNorm(Y+MaskMultiHead(YWQ,YWK,YWV)):=LayerNorm(Y+MultiHead(YWQ,XWK,XWV)):=LayerNorm(Y+max{ 0,YW3(r)+b3(r)}W4(r)+b4(r))=softmax(YW0)
优点
- 更好地表示输入token,其中token表示基于使用自注意力的特定相邻token。
- (并行)使用所有输入token,不受顺序处理(RNN)的内存限制。
缺点
- 计算量大。
- 需要大量数据(可以使用预训练模型缓解)。
接下来,让我们深入理解Transformer的工作原理!
第一步. 将位置编码加入词嵌入

p i , 2 j = sin ( 1 / 1000 0 2 j / d x ) p i , 2 j + 1 = cos ( 1 / 1000 0 2 j / d x ) X = [ x 1 , x 2 , … , x t ] T + [ P i j ] Y = [ <bos> , x 1 , … , y m ] T + [ P i j ] \begin{align} p_{i, 2j}&=\sin(1/10000^{2j/d_x})\notag\\ p_{i, 2j+1}&=\cos(1/10000^{2j/d_x})\notag\\ X&=[x_1, x_2, \dots, x_t]^T+[P_{ij}]\notag\\ Y&=[\text{<bos>},x_1, \dots, y_m]^T+[P_{ij}]\notag \end{align} pi,2jpi,2j+1XY=sin(1/100002j/dx)=cos(1/100002j/dx)=[x1,x2,…,xt]T+[Pij]=[<bos>,x1,…,ym]T+[Pij]
由于Transformer不包含递归和卷积,为了让模型可以利用序列的顺序,我们必须注入token在序列中相对或绝对位置的信息。
因此,我们必须通过“位置编码”的方式让模型明确地知道token的位置:
p i , 2 j = sin ( 1 / 1000 0 2 j / d x ) p i , 2 j + 1 = cos ( 1 / 1000 0 2 j / d x ) \begin{align} p_{i, 2j}&=\sin(1/10000^{2j/d_x})\notag\\ p_{i, 2j+1}&=\cos(1/10000^{2j/d_x})\notag \end{align} pi,2jpi,2j+1=sin(1/100002j/dx)=cos(1/100002j/dx)
其中 i i i 是token的位置(#0、#1 等), j j j 是编码的列号, d x dₓ dx 是编码的维度(与输入嵌入 X X X 的维度相同 )。
下图是对编码维度为 512 512 512 的前 2048 2048 2048 个token的位置编码矩阵 P P P 的可视化。
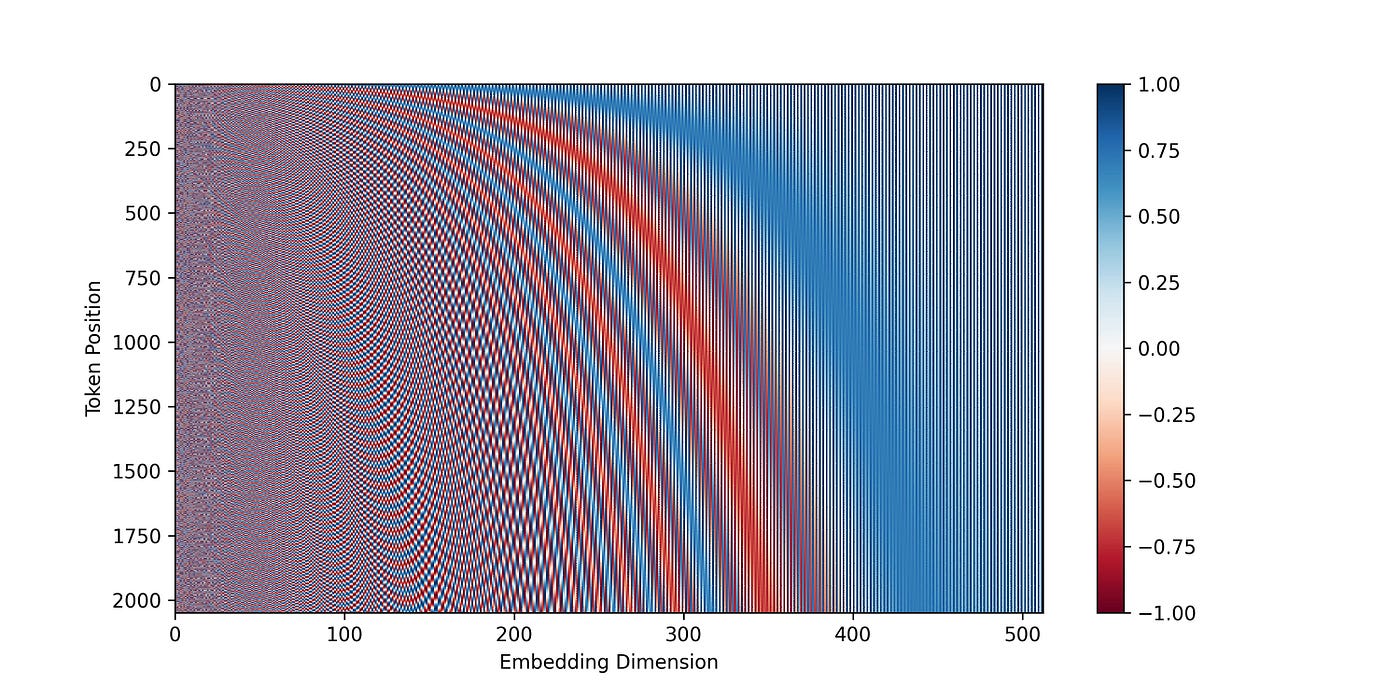
与 seq2seq 模型一样,输出嵌入 Y Y Y 向右移动,第一个token是“句子开始”标记<bos>。 接着将位置编码添加到 X X X 和 Y Y Y,然后分别发送到第一个编码器和解码器。
第二步. 编码器:多头注意力和前馈

For r = 1 , 2 , … , N X : = LayerNorm ( X + MultiHead ( X W Q , X W K , X W V ) ) X : = LayerNorm ( X + max { 0 , X W 1 ( r ) + b 1 ( r ) } W 2 ( r ) + b 2 ( r ) ) \begin{align} \text{For }r &= 1,2,\dots,N\notag\\ \quad X&:=\text{LayerNorm}(X+\text{MultiHead}(XW_Q, XW_K,XW_V))\notag\\ \quad X&:=\text{LayerNorm}(X+\max\{0,XW_1^{(r)}+b_1^{(r)}\}W_2^{(r)}+b_2^{(r)})\notag \end{align} For rXX=1,2,…,N:=LayerNorm(X+MultiHead(XWQ,XWK,XWV)):=LayerNorm(X+max{
0,XW1(r)+b1(r)}W2(r)+b2(r))
编码器由两部分组成:
- 输入嵌入 X X X ——在添加位置编码 P P P 之后——被送入多头注意力。多头注意力采用了残差连接,这意味着我们将词嵌入(或前一个编码器的输出)加到注意力的输出上。 然后将结果归一化。
- 归一化后,信息传入一个前馈神经网络,该网络由两层组成,分别具有 ReLU 和线性激活函数。同样,我们在此部分采用了残差连接和归一化。
编码器内部计算结束后,输出可以发送到另一个编码器,最后一个编码器将特定部分发送给每个解码器。

第三步. 解码器:(掩码)多头注意力和前馈

For r = 1 , 2 , … , N Y : = LayerNorm ( Y + MaskMultiHead ( Y W Q , Y W K , Y W V ) ) Y : = LayerNorm ( Y + MultiHead ( Y W Q , X W K , X W V ) ) Y : = LayerNorm ( Y + max { 0 , Y W 3 ( r ) + b 3 ( r ) } W 4 ( r ) + b 4 ( r ) ) \begin{align} \text{For }r &= 1,2,\dots,N\notag\\ \quad Y&:=\text{LayerNorm}(Y+\text{MaskMultiHead}(YW_Q, YW_K,YW_V))\notag\\ \quad Y&:=\text{LayerNorm}(Y+\text{MultiHead}(YW_Q, XW_K,XW_V))\notag\\ \quad Y&:=\text{LayerNorm}(Y+\max\{0,YW_3^{(r)}+b_3^{(r)}\}W_4^{(r)}+b_4^{(r)})\notag \end{align} For rYYY=1,2,…,N:=LayerNorm(Y+MaskMultiHead(YWQ,YWK,YWV)):=LayerNorm(Y+MultiHead(YWQ,XWK,XWV)):=LayerNorm(Y+max{
0,YW3(r)+b3(r)}W4(r)+b4(r))
解码器包含三部分:
- 输出嵌入 Y Y Y ——在右移并添加位置编码 P P P 之后——被输入到多头注意力中。 在注意力中,我们屏蔽掉(设置为 − ∞ -\infin −∞ )softmax 输入中对应于后续位置连接的所有值。
- 然后信息通过另一个多头注意力——没有掩码——作为查询向量传递。 键和值向量来自最后一个编码器的输出。 这允许解码器中的每个位置都关注输入序列中的所有位置。
- 跟编码器一样,结果会发送到具有激活函数的前馈神经网络。
解码器内部计算的结束后,输出可以发送到另一个解码器,最后一个解码器将输出发送给分类器。
第四步. 分类器
proba = softmax ( Y W 0 ) \text{proba} = \text{softmax}(YW_0) proba=softmax(YW0)
这是最后一步,非常简单。 我们使用习得的线性变换和 softmax 将解码器输出转换为预测的下一个token的概率。
∗ ∗ ∗ \ast\ast\ast ∗∗∗
Transformer 在 NLP 中取得了巨大的成功。它的出现是机器学习领域的一个里程碑。许多预训练模型(例如 GPT-2、GPT-3、BERT、XLNet 和 RoBERTa)等都是从Transformer发展而来。最近大火的ChatGPT也是以Transformer为基础,在各种 NLP 相关任务(例如机器翻译、文档摘要、文档生成、命名实体识别)和语义理解中展现了超出预期的经验表现。
总结
尽管NLP 相关任务很难,但依然有许多方法可以解决它们。最直观的是 RNN,虽然它很难并行化,且在处理长序列时会出现梯度爆炸或梯度消失。但我们还有 LSTM 和 GRU!
如何组织排列 RNN 单元有很多种方式,其中一种称为 seq2seq。 在 seq2seq 中,解码器只能看到来自最后一个编码器 RNN 单元的输入序列。这激发了注意力机制的诞生,在输出序列的每个生成步骤中,可以关注输入序列的不同部分。
随着自注意力的发展,RNN 单元被完全抛弃。被称为多头注意力的自注意力与前馈神经网络形成了Transformer ,Transformer 作为一个重要的里程碑,影响并创建了许多先进的 NLP 模型,如 GPT-3、BERT 等。