RWKV是一个结合了RNN与Transformer双重优点的模型架构。由香港大学物理系毕业的彭博首次提出。简单来说,RWKV是一个RNN架构的模型,但是可以像transformer一样高效训练。今天,HuggingFace官方宣布在transformers库中首次引入RNN这样的模型,足见RWKV模型的价值。

同时,在LM-Sys官方的匿名模型battle中,目前RWKV-4-Raven-14B排名第六,仅次于Koala-13B,好于Oasst-Pythia-12B,也能看到普通用户对其的认可。
本文将简要介绍一下RWKV模型以及如何使用。
-
RNNs与Transformers各自的特点
-
RWKV模型简介
-
基于RWKV思想的开源模型
-
RWKV-4系列模型的训练成本与速度
-
RWKV与transformers整合
-
文本生成案例
-
基于raven的chat模式
-
-
RWKV系列总结
RNNs与Transformers各自的特点
RNNs是一个经典的用于序列处理的深度学习模型,它有很多不同的架构。由于RNNs架构的模型在输入输出的序列中有很高的自由度,因此可以用来处理很多问题,经典的如翻译、时许预测等都可以使用。下图展示了不同的RNNs的架构。

RNNs架构的模型可以逐步地对输入序列进行处理,在实时数据建模时候非常有用。然而,按照序列的顺序处理要求导致它在处理长序列的时候会出现梯度消失的问题,限制了RNN模型的规模。
因此,Google在2017年提出了基于自注意力机制的transformer模型,它可以采用全局注意力机制,不需要按照序列顺序处理所有输入,极大地提高了数据并行处理的能力,因此可以产生更大规模的模型。但,transformers架构的模型也不是所有的方面都好于RNN模型。
在训练期间,Transformer模型相对于传统的RNN和CNN模型有几个优点。其中最显著的优点之一是其学习上下文表示的能力。与RNN和CNN模型逐个单词地处理输入序列不同,Transformer模型可以将输入序列作为整体进行处理。这使得它可以捕捉序列中单词之间的长距离依赖关系,这在语言翻译和问答等任务中特别有用。
在推断阶段,RNN模型在速度和内存效率方面具有一些优势。这些优势包括简单性,只需要矩阵-向量操作,以及内存效率,因为在推断期间内存要求不会增加。此外,由于计算只针对当前token和状态,因此计算速度随着上下文窗口长度的增加保持不变。
因此,如果我们能找到一个模型,它在训练期间可以像transformer一样高效,在推断期间可以像RNN那样使用较少的内存并可以隐式地处理“无限”长的上下文,那自然是完美的。
基于这个思想,彭博提出了RWKV模型。
RWKV模型简介
苹果在2021年发布了一篇论文《An Attention Free Transformer》,提出了一个不需要Attention机制的transformer模型。与标准的Transformer不同,Attention Free Transformer不使用注意力机制来计算序列中不同位置之间的相互作用。相反,它使用类似于卷积的局部操作来处理序列数据。具体来说,每个位置的输出由其周围的固定大小的局部邻域的加权和决定,其中权重由固定的可学习卷积内核计算。这种方法有效地捕获了序列中不同位置之间的依赖关系,同时减少了模型的计算复杂度和存储需求。
苹果发布的这篇论文的核心是改写了transformer里面的多头注意力公式(Multi-Head Attention,MHA),其它部分不变。而彭博发现该公式经过一些变换可以改写成RNN的形式(具体公式解析大家参考彭博在知乎上的一系列文章:https://zhuanlan.zhihu.com/p/514840332 ,本文不再赘述)。进而产生了RWKV系列模型,其中RWKV分别是公式中的4个参数。
自从彭博发现了这个公式之后,经过数次迭代目前已经发展到了RWKV-4(即第4个版本)。其核心代码如下图所示(来源彭博的知乎文章):
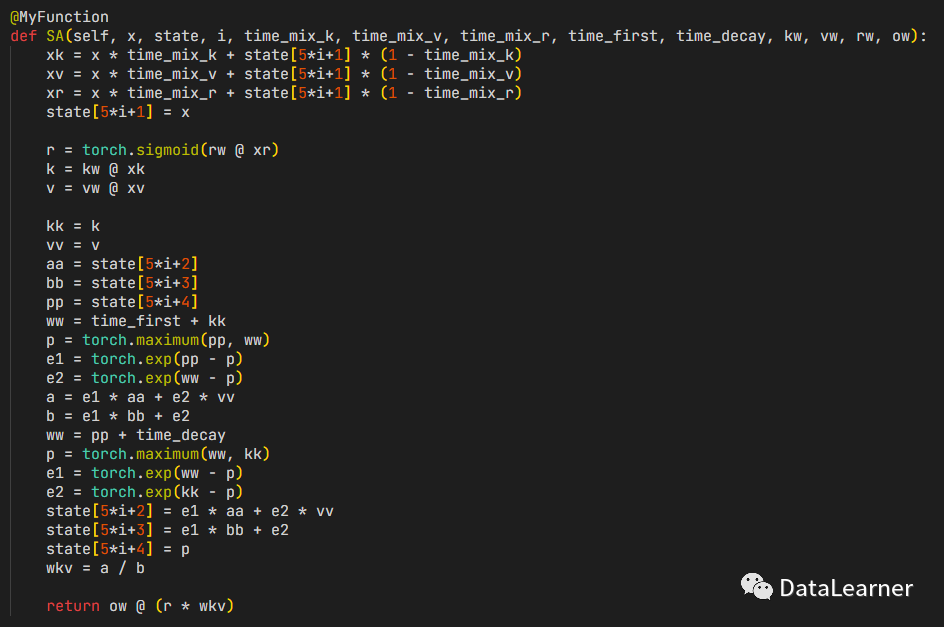
总结一下,RWKV的几个特点如下:
-
没有注意力机制
-
不需要embedding
-
可以以transformer的形式训练RNN架构的模型,训练效率高
-
由于是RNN的架构,推理速度很快
-
推理过程没有上下文长度的限制
基于RWKV思想的开源模型
目前官方已经就RWKV开源了多个模型。主要是Raven系列模型,Raven是基于RWKV-4架构在Pile数据集上训练和微调的大模型,做过指令微调或者chat微调版本。此外,也包括了非Raven版本的RWKV-4的模型。
HuggingFace上开源的RWKV-4系列模型总结如下:
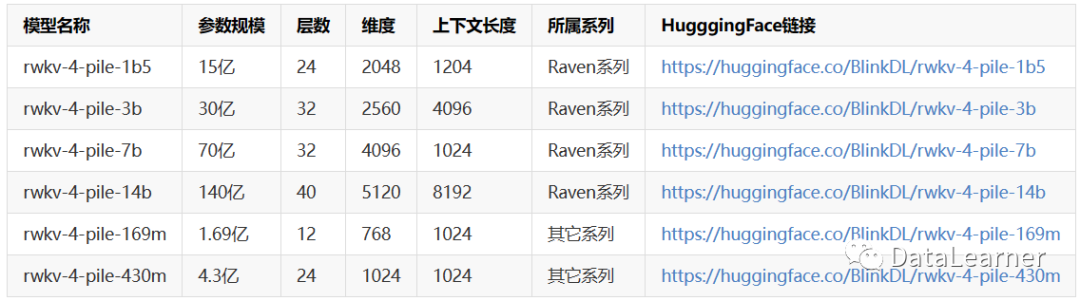
此外,官方目前还在训练针对小说、多语言等方面的模型。
官方也发布了RWKV-4模型与其它开源模型的效果对比:
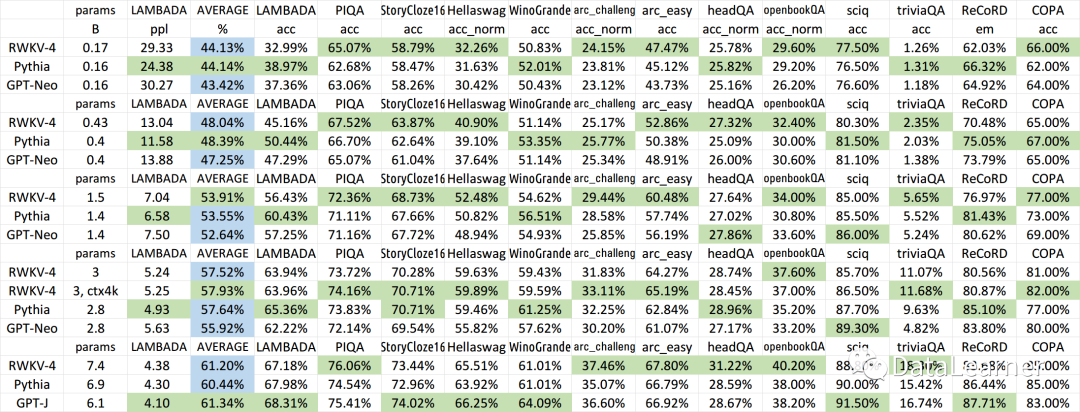
可以看到,在同等规模参数中,RWKV-4系列与Pythia和GPT-J比都是很有优势的。
注意,RWKV系列开源的最大的优点包括:
-
可以商用
-
基于1.7万亿tokens训练
-
未来将开源1000亿参数规模的预训练结果
RWKV-4系列模型的训练成本与速度
如前所属,RWKV模型强调的一个重要的特点是既可以像transformer那样高效训练,也可以像RNN那样有很好的推理能力。目前官方给的相关数据如下:
RWKV-4 14B(BF16精度)在64个A100-80G显卡上训练速度是每秒11.4万tokens!
官方宣称,推理阶段只有矩阵与向量的乘法,没有矩阵相乘,因此,即使在CPU上运行速度也很快(没有数据),甚至可以在手机上运行!
RWKV与transformers整合
今天,HuggingFace官方宣布transformers库整合了RWKV系列模型,这也是transformers库中引入的第一个RNN模型,使用很简单。
RWKV系列总结
HuggingFace官方宣布transformers库整合了RWKV系列模型证明了它的价值,这也是近期难得的国产项目被认可的表现。它在LM-Sys的匿名测评中也很棒,甚至超出了清华大学出品的在业内评价很高的ChatGLM-6B(清华大学有1300亿规模的版本,未开源)。RWKV模型思想很简单,但是比较难能可贵的是官方完全开源的态度,包括预训练结果可商用、训练代码的开源以及与transformers的整合。期待更加完整的结果测试~