
在上一篇博客《注意力机制原理概述》中,我们介绍了注意力机制的基本原理以及一些技术细节。基于注意力机制的深度学习模型在起初设计时,针对的是NLP问题。包括词元分析,翻译等语言处理任务,注意力机制能够训练超大规模数据,并建立学习模型,获得显著的性能提升。鉴于注意力机制在NLP任务中的空前成功,视觉领域也尝试引入注意力机制,著名工作包括VIT [1] 和Swin Transformer [2]。对于点云数据处理,一些基于Transformer模型 [3][4] 的工作也被提出。本文以文献 [3] 为基础,概述在点云数据处理任务中引入Point Transformer的具体思路。
1. 概述
Point Transformer基于自注意力网络实现网络模型的构建。通过设计针对点云的自注意力层,结合位置编码构建Transformer block,利用自注意力机制,实现包括语义分割,部件分割以及识别任务。该项工作的最大贡献即提出面向点云的自注意力层。自注意力层是序列无关的,天然适合处理无序点云数据。为了方便理解自注意力层,这里回顾一些基础知识。设存在一个特征向量{xi},标准的标量点积注意力层能够被表示为:

yi是输出特征, φ, ψ, 和 α是逐点特征变换,类似线性变换或MLP,δ是位置编码函数,ρ是标准化操作,例如softmax。标量注意力层计算由φ和ψ变换来的特征的标量点积,使用输出作为注意力分数,对α变换的汇聚特征赋权。注:这个公式的写法存在一些误导,在一些相关介绍中,一般使用α来表示权重或分数,这里是反的,需要注意。
在向量注意力中,注意力权重的计算是不同的,其为向量表示,可以独立调节特征通道。

这里的β为关系函数,γ为映射函数,如MLP,用来产生注意力向量用于特征汇聚。结合前文对注意力机制的介绍,不管ρ的内部多么复杂,其只用来衡量查询xi与xj的差异,并指导对xj的加权输出,建立xi与{xj}的关系。包括标量和向量自注意力都是集合算符,集合本身能够被视为表示任意信号的特征向量。自然,其能够对应一组点云局部的patch,或邻域结构。
2. Point Transformer层
基于自注意力机制的基本原理,文献 [3] 提出Point transformer层(Pt层),结构如下:
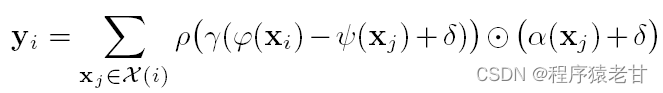
![]() 是xi点的一个局部邻域,可基于KNN定义。由于我们有了局部邻域,就可以使用最近的基于图像patch的自注意力网络,来分析点在其邻域内的自注意力。这里的映射函数γ是一个包含两层线性层的MLP和一个Relu层的组合。Pt层层如下图所示:
是xi点的一个局部邻域,可基于KNN定义。由于我们有了局部邻域,就可以使用最近的基于图像patch的自注意力网络,来分析点在其邻域内的自注意力。这里的映射函数γ是一个包含两层线性层的MLP和一个Relu层的组合。Pt层层如下图所示:
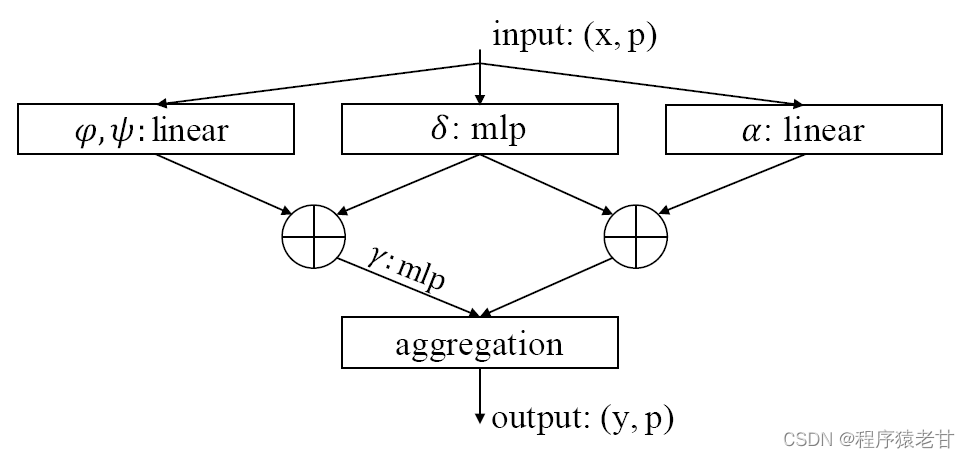
图1. Point transformer层结构图。
3. 位置编码与块构建
位置编码在自注意力机制中是非常重要的,相关介绍已经在上篇博客中提及。在点云处理中,三维点坐标天然表达位置信息,可以被直接用来做位置编码。这里给出位置编码函数δ的表示:
![]()
pi和pj即点的坐标,编码函数θ与之前提到的映射函数γ的结构一样。
构建包含Pt层在内的残差Point Transformer 块(Pt块)作为网络设计的核心,结果如下图(a)所示:
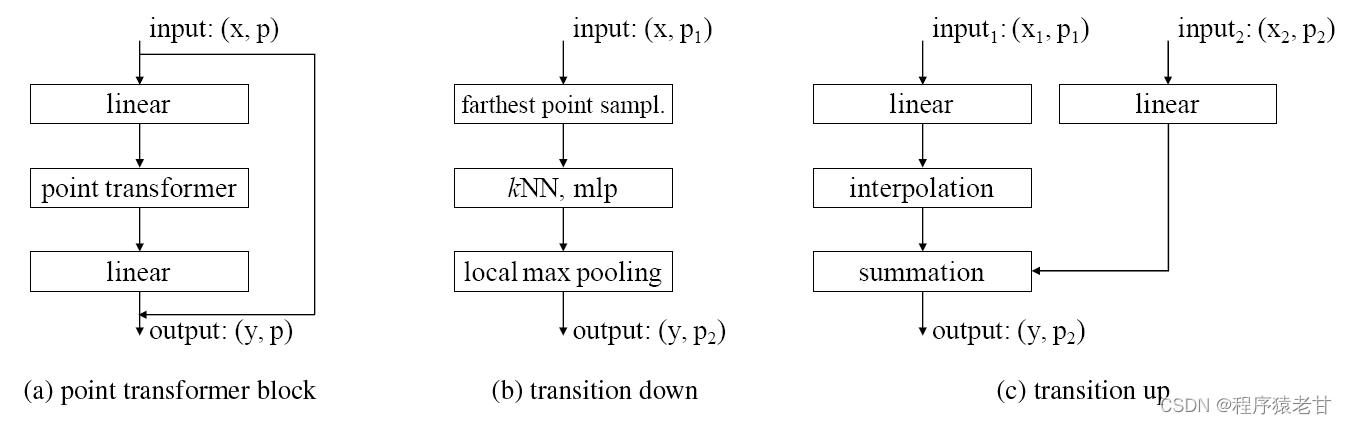
图2. 各模块结构示意图。
transformer块汇聚了自注意力层,线性映射降低了维度,提高计算效率。输入是一组特征向量x伴随三维坐标p。Pt块促进了局部特征向量的信息交互,产生新的特征向量作为输出。信息汇聚既适应特征向量的内容,也适应特征向量的三维布局。
4. 模型架构
基于Pt块,一个完整的点云Transformer网络模型被构建。Pt层是网络中最主要的特征聚合算子,不需要卷积或其他辅助模块。整个结构仅需要Pt层,点变换和池化操作。网络结构如下图:

图3. Point transformer结构图。
整个架构包含五个阶段,每个阶段都会逐次进行下采样,下采样率分别为1,4,4,4,4,对应的点数为N,N/4,N/16,N/64,N/256。各个阶段的过度由转接模块实现,向下转接用于特征编码,向上转接用于特征解码。
向下转接主要的功能是减少点集维度,例如从第一阶段到第二阶段,点数N变到N/4。这里使用最远点采样,实现向下转接。为了池化转接后的特征向量,这里使用KNN(k=16)在输入端。每个输入特征经过一个线性变换,随之进行归一化和ReLU,然后进行最大池化。转接前点集的,按照K近邻汇聚到转接后采样点中。向下转接模块结构如图2(b)所示。
对于稠密预测任务,类似于语义分割,我们适配一个U-net的设计,其结构与向下转接形成对偶关系。每一阶段通过上采样模块连接,实现对电云的上采样。最后,每一个输入点的特征被一个线性层处理,紧跟着一个归一化层和重采样层,使得特征通过三线形差值,被映射到高分辨率点集。这些从之前的解码器生成的特征正好对应对称位置编码阶段的特征,通过跨越连接实现(见图3,对应位置的编解码器均有一条跨越连接的数据通路)。向上转接模块如图2(c)所示。
最后,对于分割任务,最后一层解码后,每一点均会对应生成一个特征向量。最后应用一个MLP层映射这个特征到最终结果。对于分类任务,我们逐点对特征执行全局平均池化,以获得一个对于整个点云的全局特征向量。将这个全局特征通过一个MLP层以输出分类结果。
5. 实验结果
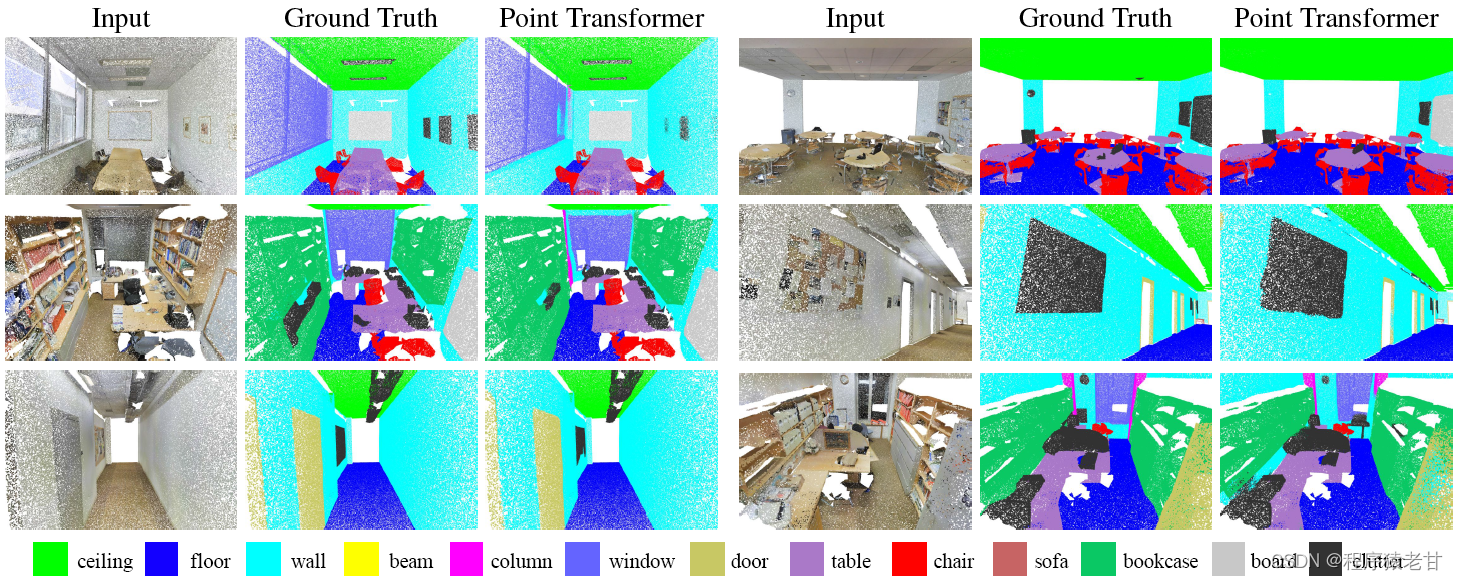
图4. S3DIS场景分割结果。

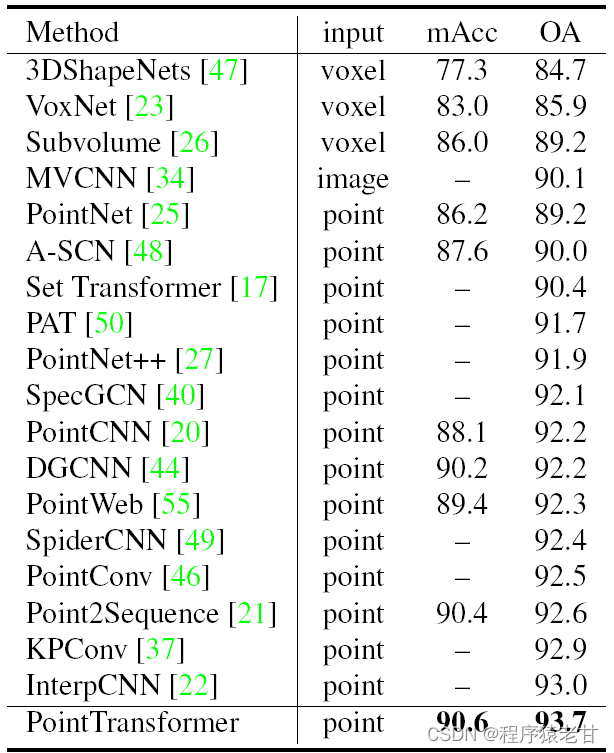
图5. S3DIS场景分割精度与ModelNet40识别精度对比数据。
总结
整体来说,基于自注意力机制设计的Point Transformer利用了点在局部邻域的对应关系,建立查询、键、值在点云局部邻域的表示,并建立以点对为注意力单位的特征学习模型。这取代了PointNet++中在局部建立特征卷机的做法,使得向下采样点特征聚集的过程更加高效,降低了邻域中,不相关点对对于训练的影响。不过,没有使用多头注意力,仍被称为Transformer,感觉是有点奇怪的。我认为对于之后对于该结构的改进,可以从此处入手。
Reference
[1] A. Dosovitskiy, L. Beyer, A. Kolesnikov, et al. An image is worth 16x16 words: Transformers for image recognition at scale[J]. arXiv preprint arXiv:2010.11929, 2020.
[2] Z. Liu, Y. Lin, Y. Cao, et al. Swin transformer: Hierarchical vision transformer using shifted windows [C]. International conference on computer vision. 2021: 10012-10022.
[3] H. Zhao, L. Jiang, J. Jia J, et al. Point transformer [C]. Proceedings of the IEEE/CVF international conference on computer vision. 2021: 16259-16268.
[4] MH. Guo, JX. Cai, ZN. Liu, et al. Pct: Point cloud transformer[J]. Computational Visual Media, 2021, 7: 187-199.