论文:https://arxiv.org/abs/1904.07850
目录
1. CenterNet网络结构
除了检测任务外,CenterNet还可以用于肢体识别或者3D目标检测等,因此CenterNet论文中提出了三种backbone的网络结构,分别是Resnet-18, DLA-34和Hourglass-104, 三种backbone准确度和速度如下:
- Resnet-18 with up-convolutional layers : 28.1% coco and 142 FPS
- DLA-34 : 37.4% COCOAP and 52 FPS
- Hourglass-104 : 45.1% COCOAP and 1.4 FPS
实际工作中我主要用CenterNet进行目标检测,常用Resnet50作为backbone,这里主要介绍resnet50_center_net,其网络结构如下:

可以发现CenterNet网络比较简单,主要包括resnet50提取图片特征,然后是反卷积模块Deconv(三个反卷积)对特征图进行上采样,最后三个分支卷积网络用来预测heatmap, 目标的宽高和目标的中心点坐标。值得注意的是反卷积模块,其包括三个反卷积组,每个组都包括一个3*3的卷积和一个反卷积,每次反卷积都会将特征图尺寸放大一倍,有很多代码中会将反卷积前的3x3的卷积替换为DCNv2(Deformable ConvetNets V2)来提高模型拟合能力。
关于DCN(Deformable ConvetNets)参见:目标检测论文阅读:Deformable Convolutional Networks - 知乎, 目标检测论文阅读:DCN v2 - 知乎
CenterNet的模型计算流程如下:
-
图片缩放到512x512尺寸(长边缩放到512,短边补0),随后将缩放后1x3x512x512的图片输入网络
-
图片经过resnet50提取特征得到feature1尺寸为1x2048x16x16
-
feature1经过反卷积模块Deconv,三次上采样得到feature2尺寸为1x64x128x128
-
将feature2分别送入三个分支进行预测,预测heatmap尺寸为1x80x128x128(表示80个类别),预测长宽尺寸为1x2x128x128(2表示长和宽),预测中心点偏移量尺寸为1x2x128x128(2表示x, y)
-
测试的过程中,由于只需要从热图中提取目标,这样就不需要使用NMS,降低了计算量
关于另外两种backbone参见:
- DLA-34网络即Deep Layer Aggregation, 其理解参见:CenterNet的骨干网络之DLASeg - 云+社区 - 腾讯云
- Hourglass网络主要用于人体姿态估计,其理解参见:论文笔记Stacked Hourglass Networks - 知乎
2. heatmap(热力图)理解和生成
2.1 heatmap生成
CenterNet将目标当成一个点来检测,即用目标box的中心点来表示这个目标,预测目标的中心点偏移量(offset),宽高(size)来得到物体实际box,而heatmap则是表示分类信息。每一个类别都有一张heatmap,每一张heatmap上,若某个坐标处有物体目标的中心点,即在该坐标处产生一个keypoint(用高斯圆表示),如下图所示:

产生heatmap的步骤解释如下:
如下图左边是缩放后送入网络的图片,尺寸为512x512,右边是生成的heatmap图,尺寸为128x128(网络最后预测的heatmap尺度为128x128。其步骤如下:
- 将目标的box缩放到128x128的尺度上,然后求box的中心点坐标并取整,设为point
- 根据目标box大小计算高斯圆的半径,设为R
- 在heatmap图上,以point为圆心,半径为R填充高斯函数计算值。(point点处为最大值,沿着半径向外按高斯函数递减)
(注意:由于两个目标都是猫,属于同一类别,所以在同一张heatmap上。若还有一只狗,则狗的keypoint在另外一张heatmap上)

2.2 heatmap高斯函数半径的确定
参考:说点Cornernet/Centernet代码里面GT heatmap里面如何应用高斯散射核 - 知乎
heatmap上的关键点之所以采用二维高斯核来表示,是由于对于在目标中心点附近的一些点,其预测出来的box和gt_box的IOU可能会大于0.7,不能直接对这些预测值进行惩罚,需要温和一点,所以采用高斯核。如下图所示:

Fig5.这段话的意思就是在设置GT box的heat map的时候,我们不能仅仅只在top-left/bottom-right的位置设置标签(置为1),因为fig5中红色的bbox为GT框,但是绿色的框其实也能很好的包围目标。所以如果在检测中得到想绿色的这样的框的话,我们也给它保留下来。甚至说的更普遍一些,只要预测的corners在top-left/bottom-right点的某一个半径r内,并且其与GTbox的IOU大于一个阈值(一般设为0.7),我们将将这些点的标签不直接置为0,那置为多少呢?可以通过一个温和的方式来慢慢过渡,所以采用二维的高斯核未尝不可。
那问题现在就变成了如何确定半径r,使得IOU与GT box大于0.7的预测框不被直接阉割掉。
关于高斯圆的半径确定,主要还是依赖于目标box的宽高,其计算方法为下图所示。 实际情况中会取IOU=0.7,即下图中的overlap=0.7作为临界值,然后分别计算出三种情况的半径,取最小值作为高斯核的半径r

综合三种情况,可以得到r = min(r1, r2, r3)将这三个中的最小值设为半径。
然后根据这个半径设计一个高斯散射核,就是很简单的事了。高斯散射核长这样:

最中心的位置是标签值为1,周围的标签呈 规律递减。
规律递减。
3. 数据增强
关于CenterNet还有一点值得注意的是其数据增强部分,采用了仿射变换warpAffine,其实就是对原图中进行裁剪,然后缩放到512x512的大小(长边缩放,短边补0)。实际过程中先确定一个中心点,和一个裁剪的长宽,然后进行仿射变换,如下图所示,绿色框住的图片会被裁剪出来,然后缩放到512x512(实际效果见图二中六个子图中第一个)

下面是上图选择不同中心点和长度进行仿射变换得到的样本。除了中心点,裁剪长度,仿射变换还可以设置角度,CenterNet中没有设置角度(代码中为0),是由于加上旋转角度后,gt_box会变的不是很准确,如最右边两个旋转样本

4. loss函数理解
center_net的loss包括三部分,heatmap的loss,目标长宽预测loss,目标中心点偏移值loss。其中heatmap的Lk采用改进的focal loss,长宽预测的Lsize和目标中心点偏移Loff都采用L1Loss, 而且Lsize加上了0.1的权重。

heatmap loss
heatmap loss的计算公式如下,对focal loss进行了改写,α和β是超参数,用来均衡难易样本和正负样本。N是图像的关键点数量(正样本个数),用于将所有的positive focal loss标准化为1,求和符号的下标xyc表示所有heatmap上的所有坐标点(c表示目标类别,每个类别一张heatmap),为预测值,Yxyc为标注真实值。
Yxyc具体而言,设输入图片为![]() , W代表图片的宽,H代表高。CenterNet的输出是一个关键点热图heatmap。
, W代表图片的宽,H代表高。CenterNet的输出是一个关键点热图heatmap。

其中R代表输出的stride大小,C代表关键点的类型的个数。在COCO数据集目标检测中,R设置为4,C的值为80,代表80个类别。如果![]() 代表检测到一个物体,表示对类别c来说,(x,y)这个位置检测到了c类的目标。既然输出是热图,标签构建的ground truth也必须是热图的形式。标注的内容一般包含(x1,y1,x2,y2,c),目标框左上角坐标、右下角坐标和类别c,按照以下流程转为ground truth:
代表检测到一个物体,表示对类别c来说,(x,y)这个位置检测到了c类的目标。既然输出是热图,标签构建的ground truth也必须是热图的形式。标注的内容一般包含(x1,y1,x2,y2,c),目标框左上角坐标、右下角坐标和类别c,按照以下流程转为ground truth:
- 得到原图中对应的中心坐标

- 得到下采样后的feature map中对应的中心坐标
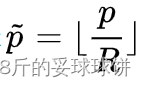 , R代表下采样倍数,CenterNet中R为4
, R代表下采样倍数,CenterNet中R为4 - 如果输入图片为512,那么输出的feature map的空间分辨率为[128x128], 将标注的目标框以高斯核的方式将关键点分布到特征图上:
 , 其中
, 其中是一个与目标大小相关的标准差(代码中设置的是)。对于特殊情况,相同类别的两个高斯分布发生了重叠,重叠元素间最大的值作为最终元素。
关于focal loss的理解参考:样本不均衡问题 - silence_cho - 博客园 , 扔掉anchor!真正的CenterNet——Objects as Points论文解读 - 知乎
相比focal loss,负样本的loss里面多了一个(1-Yxyc)β, 是为了抑制0<Yxyc<1的负样本的loss(heatmap高斯中心点附近那些点)

中心点偏移值损失
Loff损失函数公式如下, 其只对正样本的偏移值损失进行计算。其中 表示预测的偏移值,p为图片中目标中心点坐标,R为缩放尺度,
为缩放后中心点的近似整数坐标。
假设图片实际中心点p为(125, 63),由于图片的尺寸为512*512,缩放尺度R=4,因此缩放后的128x128尺寸下中心点坐标为p\R(31.25, 15.75), 相对于整数坐标(31, 15)的偏移值即为(0.25, 0.75), 即(p/R -
)。

长宽预测损失值
损失函数公式如下,也是只对正样本的损失值计算,Spk为预测尺寸,Sk为真实尺寸。

5.前向及输出
最终网络在每个位置预测c+4个输出,c是类别数,4则包含横向和纵向的offset以及宽高。
在前向阶段,对于每个类别的热度图,提取峰值点,若一个点的值大于等于其周围八个点的值,则认为是峰值点,选取top100个峰值点。使用该点的

作为该点的置信,代码中采用0.3作为阈值对这些峰值点进行筛选。
最终确定bbox的左上右下的位置为:

需要指出的是,网络最后的输出摆脱了基于IOU的NMS及其他的后处理,而仅仅需要一个3*3的max pooling选择峰值关键点即可。
总结:
centernet简洁有效,仅需要得到一个中心点,其余的目标大小、维度、方向、姿态等都直接由中心位置进行回归。前向过程也很快捷,不需要额外的后处理操作(如nms等)。
当然,该网络也有缺点,当两个同类物体中心点重叠时,centernet无能为力。
参考链接:
说点Cornernet/Centernet代码里面GT heatmap里面如何应用高斯散射核 - 知乎