原文链接:https://blog.csdn.net/c20081052/article/details/89358658
论文链接:Objects as Points
代码链接:https://github.com/xingyizhou/CenterNet
Abstract
目标检测识别往往在图像上将目标用矩形框形式框出,该框的水平和垂直轴与图像的水平和垂直向平行。大多成功的目标检测器都先穷举出潜在目标位置,然后对该位置进行分类,这种做法浪费时间,低效,还需要额外的后处理。**本文中,我们采用不同的方法,构建模型时将目标作为一个点——即目标BBox的中心点。我们的检测器采用关键点估计来找到中心点,并回归到其他目标属性,例如尺寸,3D位置,方向,甚至姿态。**我们基于中心点的方法,称为:CenterNet,相比较于基于BBox的检测器,我们的模型是端到端可微的,更简单,更快,更精确。我们的模型实现了速度和精确的最好权衡,以下是其性能:
MS COCO dataset, with 28:1% AP at 142 FPS, 37:4% AP at 52 FPS, and 45:1% AP with multi-scale testing at 1.4 FPS.
用同个模型在KITTI benchmark 做3D bbox,在COCO keypoint dataset做人体姿态检测。同复杂的多阶段方法比较,我们的取得了有竞争力的结果,而且做到了实时的。
Introduction
目标检测 驱动了 很多基于视觉的任务,如 实例分割,姿态估计,跟踪,动作识别。且应用在下游业务中,如 监控,自动驾驶,视觉问答。当前检测器都以bbox轴对称框的形式紧紧贴合着目标。对于每个目标框,分类器来确定每个框中是否是特定类别目标还是背景。
One stage detectors 在图像上滑动复杂排列的可能bbox(即锚点),然后直接对框进行分类,而不会指定框中内容。
Two-stage detectors 对每个潜在框重新计算图像特征,然后将那些特征进行分类。
后处理,即 NMS(非极大值抑制),通过计算Bbox间的IOU来删除同个目标的重复检测框。这种后处理很难区分和训练,因此现有大多检测器都不是端到端可训练的。
本文通过目标中心点来呈现目标(见图2),然后在中心点位置回归出目标的一些属性,例如:size, dimension, 3D extent, orientation, pose。 而目标检测问题变成了一个标准的关键点估计问题。我们仅仅将图像传入全卷积网络,得到一个热力图,热力图峰值点即中心点,每个特征图的峰值点位置预测了目标的宽高信息。
模型训练采用标准的监督学习,推理仅仅是单个前向传播网络,不存在NMS这类后处理。

对我们的模型做一些拓展(见图4),可在每个中心点输出3D目标框,多人姿态估计所需的结果。
对于3D BBox检测,我们直接回归得到目标的深度信息,3D框的尺寸,目标朝向;
对于人姿态估计,我们将关节点(2D joint)位置作为中心点的偏移量,直接在中心点位置回归出这些偏移量的值。

由于模型设计简化,因此运行速度较高(见图1)

Related work
我们的方法与基于锚点的one-stage方法相近。中心点可看成形状未知的锚点(见图3)。但存在几个重要差别(本文创新点):
第一,我们分配的锚点仅仅是放在位置上,没有尺寸框。没有手动设置的阈值做前后景分类。(像Faster RCNN会将与GT IOU >0.7的作为前景,<0.3的作为背景,其他不管);
第二,每个目标仅仅有一个正的锚点,因此不会用到NMS,我们提取关键点特征图上局部峰值点(local peaks);
第三,CenterNet 相比较传统目标检测而言(缩放16倍尺度),使用更大分辨率的输出特征图(缩放了4倍),因此无需用到多重特征图锚点;

通过关键点估计做目标检测:
我们并非第一个通过关键点估计做目标检测的。CornerNet将bbox的两个角作为关键点;ExtremeNet 检测所有目标的 最上,最下,最左,最右,中心点;所有这些网络和我们的一样都建立在鲁棒的关键点估计网络之上。但是它们都需要经过一个关键点grouping阶段,这会降低算法整体速度;而我们的算法仅仅提取每个目标的中心点,无需对关键点进行grouping 或者是后处理;
单目3D 目标检测:
3D BBox检测为自动驾驶赋能。Deep3Dbox使用一个 slow-RCNN 风格的框架,该网络先检测2D目标,然后将目标送到3D 估计网络;3D RCNN在Faster-RCNN上添加了额外的head来做3D projection;Deep Manta 使用一个 coarse-to-fine的Faster-RCNN ,在多任务中训练。而我们的模型同one-stage版本的Deep3Dbox 或3D RCNN相似,同样,CenterNet比它们都更简洁,更快。
Preliminary
令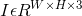 为输入图像,其宽W,高H。我们目标是生成关键点热力图
为输入图像,其宽W,高H。我们目标是生成关键点热力图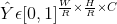 ,其中R 是输出stride(即尺寸缩放比例),C是关键点类型数(即输出特征图通道数);关键点类型有: C = 17 的人关节点,用于人姿态估计; C = 80 的目标类别,用于目标检测。我们默认采用下采用数为R=4 ;
,其中R 是输出stride(即尺寸缩放比例),C是关键点类型数(即输出特征图通道数);关键点类型有: C = 17 的人关节点,用于人姿态估计; C = 80 的目标类别,用于目标检测。我们默认采用下采用数为R=4 ;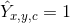 表示检测到的关键点;
表示检测到的关键点;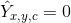 表示背景;我们采用了几个不同的全卷积编码-解码网络来预测图像 I 得到的\hat{Y}:stacked hourglass network , upconvolutional residual networks (ResNet), deep layer aggregation (DLA) 。
表示背景;我们采用了几个不同的全卷积编码-解码网络来预测图像 I 得到的\hat{Y}:stacked hourglass network , upconvolutional residual networks (ResNet), deep layer aggregation (DLA) 。
我们训练关键点预测网络时参照了Law和Deng (H. Law and J. Deng. Cornernet: Detecting objects as
paired keypoints. In ECCV, 2018.) 对于 Ground Truth(即GT)的关键点 c ,其位置为 p 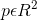 ,计算得到低分辨率(经过下采样)上对应的关键点
,计算得到低分辨率(经过下采样)上对应的关键点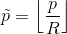 我们将 GT 关键点 通过高斯核
我们将 GT 关键点 通过高斯核 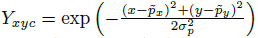 分散到热力图
分散到热力图 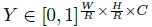 上,其中
上,其中 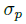 是目标尺度-自适应 的标准方差。如果对于同个类 c (同个关键点或是目标类别)有两个高斯函数发生重叠,我们选择元素级最大的。训练目标函数如下,像素级逻辑回归的focal loss:
是目标尺度-自适应 的标准方差。如果对于同个类 c (同个关键点或是目标类别)有两个高斯函数发生重叠,我们选择元素级最大的。训练目标函数如下,像素级逻辑回归的focal loss:
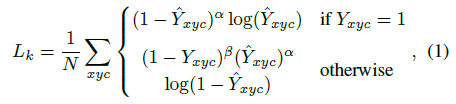
其中 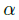 和
和 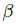 是focal loss的超参数,实验中两个数分别设置为2和4, N是图像 I 中的关键点个数,除以N主要为了将所有focal loss归一化。
是focal loss的超参数,实验中两个数分别设置为2和4, N是图像 I 中的关键点个数,除以N主要为了将所有focal loss归一化。
由于图像下采样时,GT的关键点会因数据是离散的而产生偏差,我们对每个中心点附加预测了个局部偏移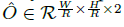 所有类别 c 共享同个偏移预测,这个偏移同个 L1 loss来训练:
所有类别 c 共享同个偏移预测,这个偏移同个 L1 loss来训练:
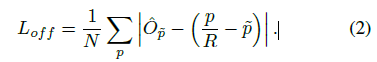
只会在关键点位置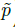 做监督操作,其他位置无视。下面章节介绍如何将关键点估计用于目标检测。
做监督操作,其他位置无视。下面章节介绍如何将关键点估计用于目标检测。
Objects as Points
令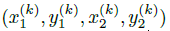 是目标 k (其类别为
是目标 k (其类别为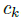 )的bbox. 其中心位置为
)的bbox. 其中心位置为 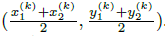 ,我们用 关键点估计
,我们用 关键点估计 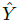 来得到所有的中心点,此外,为每个目标 k 回归出目标的尺寸
来得到所有的中心点,此外,为每个目标 k 回归出目标的尺寸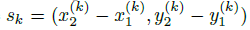 。为了减少计算负担,我们为每个目标种类使用单一的尺寸预测
。为了减少计算负担,我们为每个目标种类使用单一的尺寸预测 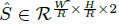 ,我们在中心点位置添加了 L1 loss:
,我们在中心点位置添加了 L1 loss:
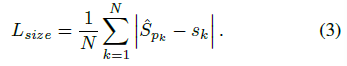
我们不将scale进行归一化,直接使用原始像素坐标。为了调节该loss的影响,将其乘了个系数,整个训练的目标loss函数为:
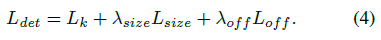
实验中, 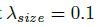 ,整个网络预测会在每个位置输出 C+4个值(即关键点类别C, 偏移量的x,y,尺寸的w,h),所有输出共享一个全卷积的backbone;
,整个网络预测会在每个位置输出 C+4个值(即关键点类别C, 偏移量的x,y,尺寸的w,h),所有输出共享一个全卷积的backbone;
从点到Bbox
在推理的时候,我们分别提取热力图上每个类别的峰值点。如何得到这些峰值点呢?做法是将热力图上的所有响应点与其连接的8个临近点进行比较,如果该点响应值大于或等于其八个临近点值则保留,最后我们保留所有满足之前要求的前100个峰值点。令 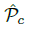 是检测到的 c 类别的 n 个中心点的集合。
是检测到的 c 类别的 n 个中心点的集合。 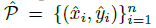 每个关键点以整型坐标
每个关键点以整型坐标 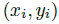 的形式给出。作为测量得到的检测置信度, 产生如下的bbox:
的形式给出。作为测量得到的检测置信度, 产生如下的bbox:
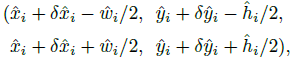
其中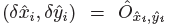 是偏移预测结果;
是偏移预测结果;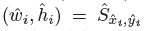 是尺度预测结果;所有的输出都直接从关键点估计得到,无需基于IOU的NMS或者其他后处理。
是尺度预测结果;所有的输出都直接从关键点估计得到,无需基于IOU的NMS或者其他后处理。
附飞桨课件






