一、前言
LiDAR 滤波的现有方法包括:数学形态学滤波法、基于地形坡度滤波、最小二乘内插法滤波等滤波方法。最小二乘内插法能够较好的获取地形趋势面,但是算法中无法根据地形自适应设置参数;在地形起伏较大的地区提取结果精度低;无法剔除大型建筑物和大面积且穿透率较低的植被;可能接收负粗差点;计算时间长。
利用最小二乘内插法滤波方法难以获取较高精度的结果,因此,博客提出了一种基于移动窗口加权迭代最小二乘拟合的区域生长滤波,即移动窗口下的区域生长滤波,对LiDAR 数据进行滤波。首先使用移动窗口加权迭代最小二乘拟合的方法对原始点云数据进行滤波,由于每一个格网中的地物分布情况存在差异,一个连续的地形被分在两个格网之中,其保留下来的结果也会存在差异;经过若干次迭代之后,将原始数据与对应位置的拟合数据做差值,在一定阈值范围内的点保留为地面点,超过阈值范围的点当作非地面点剔除掉。该方法的提取结果为部分地面点,但其“腐蚀”效果较强,导致地面点结果缺失严重,因此将上述过程得到的部分地面的作为种子点采用区域生长方法进行点集重建,以得到完整的地面点点集。
二、算法构建
1、 基于移动窗口加权迭代最小二乘拟合的种子点选取
为了有效去除大面积的植被和大型建筑物,本次提出移动窗口加权迭代最小二乘拟合法。如图1 所示,其中加权迭代最小二乘拟合中的格网划分如图1 中的第一次格网划分(黑色网格)。在第一次格网划分的基础上,水平方向和竖直方向分别偏移0.5 倍的格网宽度,进行第二次格网划分,在第二次格网划分中,第一次划分的格网边缘位于第二次划分格网的中间位置。在格网划分之后,对每一个格网进行二次曲面拟合。比较格网中原始点云与之相对应位置的拟合曲面值的差值 ,判断其是否为地面点。若为地面点则保留其原始的高程值,反之,则用对应位置拟合曲面的值来替换其原始的高程值。
,判断其是否为地面点。若为地面点则保留其原始的高程值,反之,则用对应位置拟合曲面的值来替换其原始的高程值。

图1 移动格网划分示意图
将两次保留的高程值取平均值如图 2 所示 。 用此平均值与原始值进行比较再次判断该点是否为地面点 。在 此过程中 可以得出 ,加权迭代最小二乘拟合的方法是从整体到局部,分而治之;移动窗口加权迭代最小二乘拟合的方法是从整体到局部,再到整体,先分而治之,再进行整体的考虑。
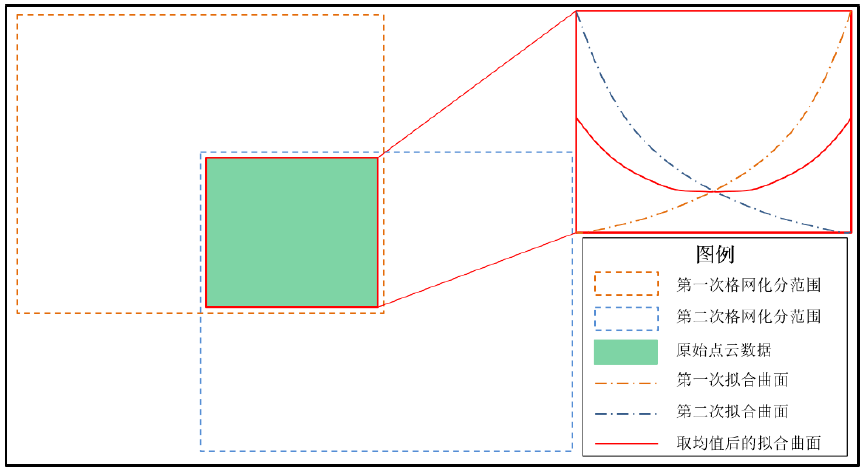
图 2 移动格网划分后拟合曲面示意图
该算法是在迭代线性最小二乘内插法上做的改进,其 不足之处有:地形起伏较大的区域 的 特征较难保留 这些特征边界变得平滑 本次 方法继承了迭代线性最小二乘内插法计算时间比较长的缺点,计算量翻倍,计算的时间也翻倍。 优点在于能够 较 好的获得地形趋势面 ;对于大型的建筑物,通过移动格网,能够通过若干个格网进行覆盖,从而达到剔除建筑物的目的;在进行拟合之前,先对数据进行预处理,剔除负粗差。但是该方法通常破坏了地形结构, 将其保留的点作为种子点,如图 3(b)所示 然后使用区域生长法对原始数据进行影像分割,这些种子点生长得到的区域即视为地面点所在的区域 。
2、基于区域生长的点集重建
移动窗口加权迭代最小二乘拟合法虽然获取了部分较为准确的地面点集,但通常破坏了原始数据的地形结构,使地面点严重缺失,因此将该步骤保留的点作为种子点 进行点集重建。因为深度影像数据邻域关系的表达比点云数据更方便,所以使用原始数据的深度影像进行操作。 使用区域生长法对深度影像数据 进行分割基于 这些种子点生长得到 的区域即视为重建后地面点所在的区域 。
(1)深度影像数据
在点云数据的处理过程中,会涉及到大量的邻域处理,数据的表达和结构直接影响到算法的可行性与效率。 深度影像( 距离图像)是一类特殊形式的图像,其与普通的灰度图像的不同之处在于二者的像素表示的内容不同:灰度图像的像素值表示的是该点感光的强度或灰度;深度图像的像素值表示了扫描点的距离信息。一般的转换过程为:将不规则的点云数据通过格网内插得到规则格网数字高程矩阵 ,再进行灰度量化得到距离灰度数字图像。 此过程需要进行内插,会带来内插误差;进行灰度量化的过程需要取整,会产生舍入误差。

为了减少此过程中的误差,首先根据点云数据的范围来确定深度影像的范围,再利用上面的公式将点云数据映射到深度影像中,最后用最邻近插值方法填补无效值区域;用实际的高程值取代灰度量化的值,消除取整过程中的舍入误差。由点云数据转换得到的深度影像数据如图 3 所示。

图 3 原始点云数据与深度影像数据
(2)区域生长
Zucke于 1976 年提出区域生长的概念,其基本思想是将具有相似性质的像素集合起来构成区域。首先找到一个种子点作为生长的起点,然后在种子像素的周围邻域中的找出像素相同或者性质相似的点,合并到种子点所在区域内;将新加入区域的像素点作为新的种子点,继续上述过程,直到没有满足条件的像素时停止迭代。

图4 地面点的提取过程
将1 的种子点作为生长的起点,对深度影像数据进行区域生长法分割。经分割后的影像可分为目标和背景:种子点所在的区域为目标,反之为背景。再将原始数据按照公式(1)进行转换 如果转换后 的点位于目标区域则为地面点提取的结果如图4(c)所示。
三、实例数据分析
1、实验数据
选取的实验数据 为 国际摄影测量与遥感学会 ISPRS 提供的滤波测试数据,包括 samp12 、 samp23 、 samp 24 、 samp31 、 samp41 和 samp53 等 六 组实验数据 。 samp 12数据 含有植被和建筑物 samp23 和 samp24 数据 含有 大型建筑物、不规则形状的建筑物和道路; samp 31 数据含有被植被环绕的建筑物 、 空旷地区上有很多高低混合的特征地物 samp41 数据含有 火车站与火车(低密度的地形点)、空隙;samp 53 数据含有 陡峭的山坡、植被、和空隙。本次博客结果主要展示samp 12与samp 53的结果。
2、实验结果
本方法中,移动窗口的大小设置为 24(m);格网偏移为 12(m);比较格网中原始点云与之相对应位置的拟合曲面值的差值 为 0.2 (m)和 0.5 (m)分别剔除非地面点和高程值较低的粗差点;迭代的次数设置为 2 次及以上(根据实验,迭代 2 次效果就比较好);区域生长法的阈值设置为 0.2(m)。滤波结果如图所示:

图5 samp12 结果比对图

图6 samp53 结果比对图
3、精度分析
根据 ISPRS 定义的 I 类误差、 II 类误差和总体误差作为 LiDAR 数据滤波的评价指标, I 类误差是指将地面点误分到非地面点的比率, II 类误差是指将非地面点误分到地面点的比率,总误差是指所有点云数据被误判的比率,用于评价滤波效果整体质量的指标。对六组实验数据的滤波结果进行误差统计,并与TerraScan 软件滤波误差统计进行比较,如表 1 所示;六组实验数据滤波产生误差的空间分布如图 7 所示。
表 1 TerraScan 软件滤波和 本次方法滤波的误差比较

从表1 中可以看出 ,六组实验数据中 samp12 、samp23 、samp 24 、samp31和 samp41 的总体误差都要小于 TerraScan 软件滤波的总体误差 samp 53 的总体误差大于误差大于TerraScanTerraScan软件滤波的总体误差软件滤波的总体误差。
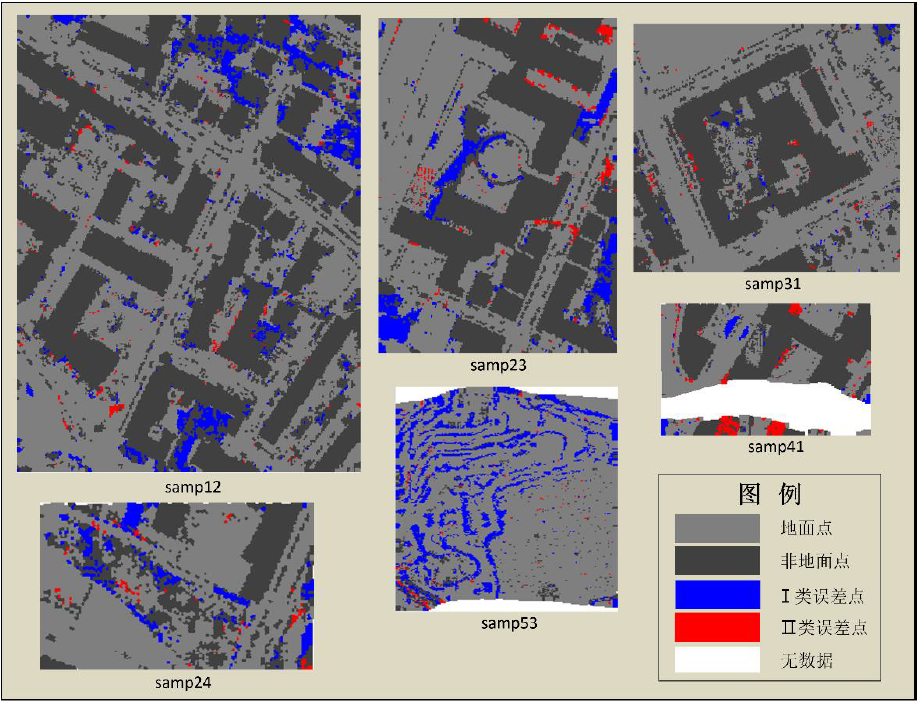
图 7 实验数据集滤波产生误差的空间分布
究其原因前五组数据基本结构由地面、道路和建筑物、植被组成,通过移动窗口加权迭代最小二乘拟合,能够剔除掉绝大多数的非地面点,再把保留下来的点作为种子点,通过区域生长法在剔除的点集中寻找被误分的地面点,由于地面点的组成比较单一,高程起伏变化不明显,使用区域生长法很能高效的提取地面点,从误差分布图中可以看出, I 类误差主要分布在建筑物旁边,或者是起伏比较小的地物,samp41 的 II 类误差较大 主要原因是在进行 移动窗口加权迭代最小二乘拟合时,移动窗口中都大部分是非地面点,导致非地面点剔除的不彻底,在经过区域生长法使误差点数目进行反弹。第六组数据主要由陡崖和植被组成,通过移动窗口加权迭代最小二乘拟合,能够有效地剔除植被的同时,对陡崖的结构破坏很大,加上复杂的地形,区域生长法在此条件下的作用不大,从误差分布图中可以看出,在陡崖的边缘存在大量的 I类误差。
四、结论
根据现有的滤波算法的优缺点和适用条件。在此基础上提出了基于移动窗口加权迭代最小二乘拟合的区域生长法滤波的方法。针对加权迭代最小二乘拟合法的缺点,即不适用于地形起伏较大的地区:在设置格网的大小上,由于一个格网很难覆盖大型的建筑物,文中采用移动窗口的方法进行处理,即一个格网难以覆盖的建筑物可以使用多个格网进行覆盖,该方法能够有效地剔除建筑物,缺点是破坏了陡崖等地形起伏较大的结构;为了尽可能少的破坏该结构,文中在前面的基础上对上述的结果进行区域生长法,找回部分被误分类到非地面点的地面点集。由于桥梁和地面在连接处的高程一致,通过区域生长法会把桥梁保留下来。
实验选取了六 组测试数据 结果显示 本次作业 方法能够有效地剔除建筑物及植被等地物 ,但是在保留陡崖等特征地形和去除桥梁地物上还需要做进一步的改进。