Prometheus是一个简单而有效的开源监控系统。在我们发表《用Prometheus监控微服务》一文后的几年里,该系统已经从云原生计算基金会(CNCF)毕业,成为分布式系统的首选监控工具。正如我们在之前的文章中提到的,其中一个原因是其直观的简单性。它并不试图做任何花哨的事情。它提供了一个数据存储、数据搜刮器、警报机制和一个非常简单的用户界面。
部署Prometheus和相关的Alertmanger工具可能是一项复杂的任务,但有一些工具可以简化和自动化这一过程,比如Prometheus Operator项目。
在这篇博文中,我们将解释一般情况下什么是操作员,Prometheus操作员如何工作,以及如何配置它以最佳方式使用Prometheus和Alertmanager。
操作员
正如我们的文章《Kubernetes运营商解释》中所说,运营商是Kubernetes的一种软件扩展。它们提供了一种一致的方法来自动处理所有应用程序的操作过程,而不需要任何人工干预,它们通过与Kubernetes API密切合作来实现。
操作员是建立在Kubernetes的两个关键原则之上。自定义资源(CR),在这里通过自定义资源定义(CRD)和自定义控制器的方式实现。CR是Kubernetes API的一个扩展,它提供了一个可以存储和检索结构化数据的地方--应用程序的理想状态。自定义控制器用于观察这个CR,并利用收到的信息采取行动,将Kubernetes集群调整到所需状态。
普罗米修斯操作员
这个操作员的主要目的是简化和自动配置和管理运行在Kubernetes集群上的Prometheus监控栈。从本质上讲,它是一个自定义的控制器,可以监控通过以下CRD引入的新对象类型。
- Prometheus:将所需的Prometheus部署定义为一个StatefulSet
- Alertmanager:定义了一个所需的Alertmanager部署
- ServiceMonitor:声明性地指定应如何监控Kubernetes服务组。
- PodMonitor:声明性地指定应如何监控pod群组
- Probe:声明性地指定应如何监控入口或静态目标组。
- PrometheusRule:定义了一套所需的Prometheus警报和/或记录规则
- AlertmanagerConfig:声明性地指定Alertmanager配置的子段
为什么使用普罗米修斯操作符
如前所述,使用操作员可以大大减少配置、实施和管理普罗米修斯监控堆栈的所有组件的工作量。它还可以提供资源的动态更新,如警报和/或普罗米修斯规则,而不需要停机。
使用引入的CRD是相对直接的,是采用该堆栈的操作最佳实践的交钥匙解决方案。此外,这种方法使运行多个实例成为可能,甚至可以使用不同版本的普罗米修斯。
使用普罗米修斯操作员
先决条件
要遵循本文章中的例子,必须满足以下要求。
- Kubernetes集群。出于测试目的,我们建议使用Kind来运行一个使用Docker容器的本地集群,Minikube也可以作为一种选择
kubectl命令行工具:安装并配置好,以便连接到集群上- 一个暴露普罗米修斯指标的网络应用。我们使用的是microservices-demo,它模拟了一个电子商务网站面向用户的部分,并为每个服务暴露了一个
/metrics端点。按照文档的要求,在集群上部署它
部署运营商
我们首先将普罗米修斯操作员部署到集群中。我们必须创建所有 CRD,定义用于配置监控栈的 Prometheus、Alertmanager 和 ServiceMonitor 抽象,以及 Prometheus Operator 控制器和服务。
这可以使用 Prometheus Operator GitHub 仓库中的bundle.yaml文件完成。
kubectl apply -f https://raw.githubusercontent.com/prometheus-operator/prometheus-operator/master/bundle.yaml首先我们验证所有的 CRD 是否已经创建。
kubectl get crds输出结果应该与此类似。
NAME CREATED AT alertmanagerconfigs.monitoring.coreos.com 2021-04-20T19:34:44Z alertmanagers.monitoring.coreos.com 2021-04-20T19:34:57Z podmonitors.monitor.coreos.com 2021-04-20T19:35:00Z probes.monitoring.coreos.2021-04-20T19:35:01Z prometheuses.monitoring.coreos.com 2021-04-20T19:35:06Z prometheusrules.monitoring.coreos.com 2021-04-20T19:35:11Z serviceicemonitors.monitoring.coreos.com 2021-04-20T19:35:12Z thanosrulers.monitoring.coreos.com 2021-04-20T19:35:14Z然后我们检查操作员是否在当前命名空间(默认)中创建,并且pod处于运行状态。
kubectl get deploy NAME READY UP-TO-DATE AVAILABLE AGE prometheus-operator 1/1 1 1 5m59skubectl get podsNAME READY STATUS RESTARTS AGE prometheus-operator-5b5887c64b-w7gqj 1/1 Running 0 6m1s最后,我们确认操作员服务也已创建。
kubectl get serviceNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE prometheus-operator ClusterIP None <none> 880/TCP 8m25s RBAC权限
Prometheus服务器需要访问Kubernetes的API,以搜刮目标并到达Alertmanager集群。因此,需要一个ServiceAccount来提供对这些资源的访问,它必须被创建并相应地绑定到一个ClusterRole。
apiVersion: v1 kind: ServiceAccount metadata: name: prometheus --- apiVersion: rbac.authorization.k8s.io/v1 kind:ClusterRole 元数据: name: prometheus rules: - apiGroups: [""] resources: - nodes - nodes/metrics - services - endpoints - pods verbs:["get", "list", "watch"] - apiGroups: ["" ] 资源: - configmaps verbs:["get"] - apiGroups: - networking.k8s.io resources: - ingresses verbs:["get", "list", "watch"] - nonResourceURLs:["/metrics"] 动词。["get"] --- apiVersion: rbac.authorization.k8s.io/v1 kind:ClusterRoleBinding 元数据: name: prometheus roleRef: apiGroup: rbac.authorization.k8s.io kind:ClusterRole name: prometheus subjects: - kind: ServiceAccount name: prometheus namespace: default将上述内容添加到清单文件rbac.yaml中,然后应用。
kubectl apply -f rbac.yaml检查角色是否被创建并绑定到ServiceAccount上。
kubectl describe clusterrolebinding prometheusName: prometheus Labels: <none> Annotations: <none> Role: Kind: ClusterRole Name: prometheus Subjects: Kind Name Namespace ---- --------- ServiceAccount prometheus default部署和配置
普罗米修斯
在创建PrometheusServiceAccount并赋予其对Kubernetes API的访问权后,我们可以部署Prometheus实例。
创建一个文件prometheus.yaml,内容如下。
apiVersion: monitoring.coreos.com/v1 kind:Prometheus元数据: name: prometheus spec: serviceAccountName: prometheus serviceMonitorNamespaceSelector:{} serviceMonitorSelector:{} podMonitorSelector:{}资源:请求:内存。400Mi此清单定义了serviceMonitorNamespaceSelector、serviceMonitorSelector和podMonitorSelector字段,以指定要包括哪些 CR。在这个例子中,{}值被用来匹配所有现有的CR。例如,如果我们想只匹配sock-shop命名空间中的serviceMonitors,我们可以使用下面的matchLabels值。
serviceMonitorNamespaceSelector: matchLabels: name: sock-shop应用该文件。
kubectl apply -f prometheus.yaml检查实例是否处于运行状态。
kubectl get prometheusNAME VERSION REPLICAS AGE prometheus 10skubectl get pods
NAME READY STATUS RESTARTS AGE prometheus-prometheus-0 2/2 Running 5 10s一个由Prometheus操作的服务也应该已经被创建。
kubectl get services
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE prometheus-operated ClusterIP None <none> 9090/TCP 17s通过转发本地端口来访问服务器的服务。
kubectl port-forward svc/prometheus-operated 9090:9090
服务监控器
操作员使用ServiceMonitors来定义一组要被Prometheus监控的目标。它使用标签选择器来定义要监控的服务,寻找的命名空间,以及暴露度量的端口。
创建一个service-monitor.yaml文件,内容如下,添加一个ServiceMonitor,以便Prometheus服务器只刮取自己的度量衡端点。
apiVersion: monitoring.coreos.com/v1 kind: ServiceMonitor metadata: name: prometheus labels: name: prometheus spec: selector: matchLabels: operated-prometheus:"true" namespaceSelector: any: true endpoints: - port: webServiceMonitor只匹配含有operated-prometheus:"true "的标签,该标签被自动添加到所有Prometheus实例中,并在所有底层端点上刮取名为web的端口。由于namespaceSelector被设置为any:true,因此任何与所选标签相匹配的命名空间中的所有服务都被包括在内。
应用清单后,作为搜刮目标的Prometheus端点应该显示在Prometheus UI目标页面上。
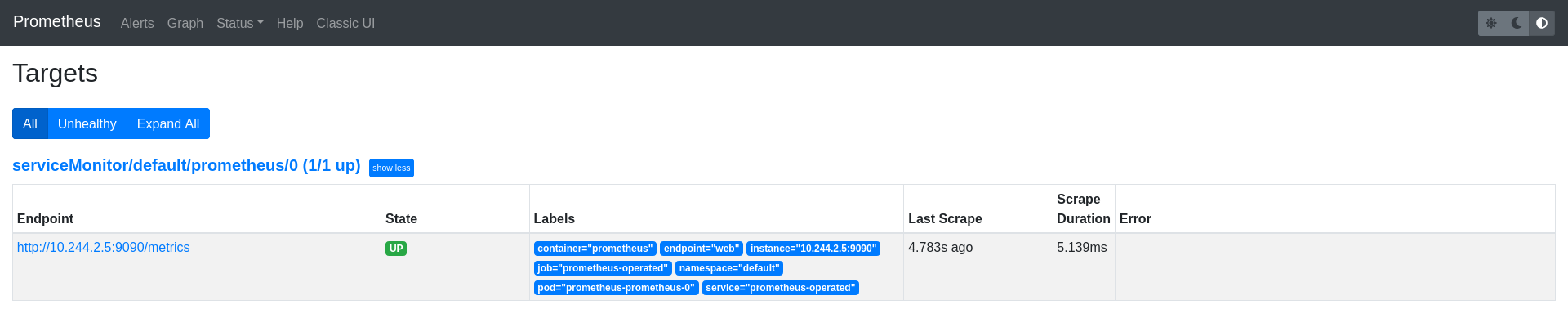
PodMonitor
可能有一些用例需要直接刮取Pod,而不需要与服务直接关联(例如刮取侧边设备)。操作员还包括一个PodMonitorCR,用于声明性地指定应被监控的Pod组。
作为一个例子,我们使用微服务-演示项目中的前端应用程序,正如我们之前提到的,它模拟了一个电子商务网站的面向用户的部分,暴露了一个/metrics端点。
在清单文件podmonitor.yaml中定义一个PodMonitor,只从sock-shop命名空间选择这个部署pod。尽管它可以使用ServiceMonitor来选择,但我们使用了targetPort字段来代替。这是因为pod在8079端口上暴露指标,并且不包括端口名称。
apiVersion: monitoring.coreos.com/v1 kind:PodMonitor元数据:名称:前端标签:名称:前端规格:namespaceSelector:匹配名称:- sock-shop选择器:匹配标签:名称:前端podMetricsEndpoints:- 目标端口:8079前端端点应该已经被添加为Prometheus目标。
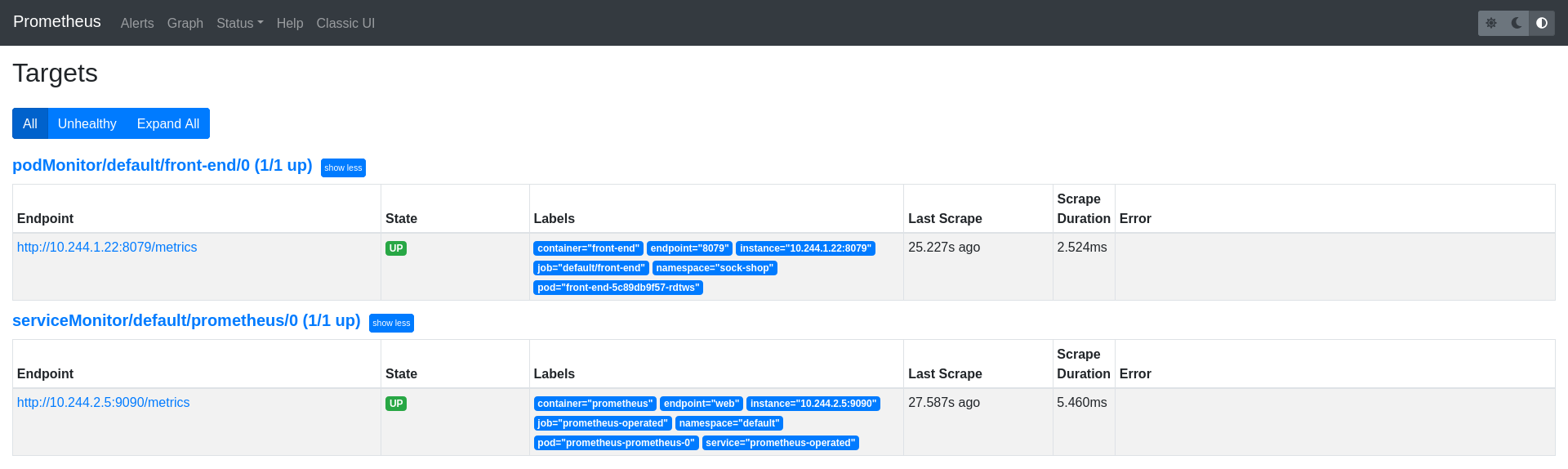
额外的搜刮配置
可以通过秘密文件向Prometheus实例追加额外的搜刮配置。这些文件必须遵循 Prometheus的配置方案,用户有责任确保它们是有效的。
下面是一个例子,你可以看到,在Prometheus中添加了一个额外的作业,以刮取目录服务端点。首先生成prometheus-additional-job.yaml文件,声明这个工作要刮取目录服务。
\- job/name: "catalogue"
static_configs:
- 目标。\["catalogue.sock-shop"\] 。然后用prometheus-additional-job.yaml内容创建extra-scrape-configs.yaml秘密文件。
kubectl create secret generic additional-scrape-configs --from-file=prometheus-additional-job.yaml --dry-run=client -oyaml > additional-scrape-configs.yaml检查additional-scrape-configs.yaml的内容并应用。
apiVersion: v1 data: prometheus-additional-job.yaml:LSBqb2JfbmFtZTogImNhdGFsb2d1ZSIKICBzdGF0aWNfY29uZmlnczoKICAgIC0gdGFyZ2V0czogWyJjYXRhbG9ndWUuc29jay1zaG9wIl0K kind: Secret metadata: creationTimestamp: null name: additional-scrap-configs kubectl apply -f additional-scrape-configs.yaml 最后,必须对Prometheus实例进行编辑,以使用extraScrapeConfigs字段引用额外的配置。
apiVersion: monitoring.coreos.com/v1 kind:普罗米修斯元数据: name: prometheus spec: serviceAccountName: prometheus serviceMonitorNamespaceSelector:{} serviceMonitorSelector:{} podMonitorSelector:{} additionalScrapeConfigs: name: additional-scrape-configs key: prometheus-additional-job.yaml resources: requests: memory:400Mi enableAdminAPI: falsekubectl apply -f prometheus.yaml现在目录端点也应该被列为Prometheus目标。
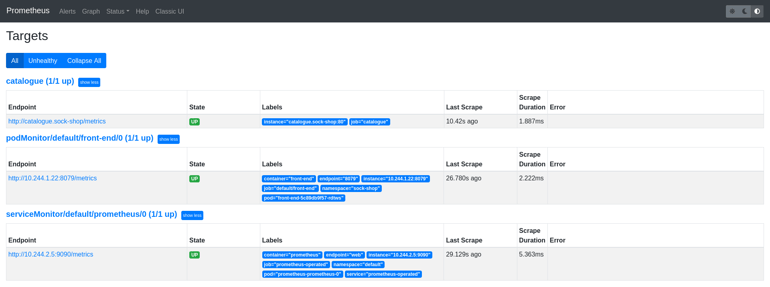
Alertmanager
普罗米修斯运营商还引入了Alertmanager资源,允许用户声明性地描述一个Alertmanager集群。它还增加了一个AlertmanagerConfigCR,允许用户声明性地描述Alertmanager的配置。
首先,创建一个alertmanager-config.yaml文件,定义一个AlertmanagerConfig资源,将通知发送到一个不存在的wechat接收器和其对应的Secret文件。
apiVersion: monitoring.coreos.com/v1alpha1 kind:AlertmanagerConfig元数据: name: config-alertmanager labels: alertmanagerConfig: socks-shop spec: route: groupBy:['job'] groupWait: 30s groupInterval:5m repeatInterval: 12h receiver: 'wechat-socks-shop' receivers: - name: 'wechat-socks-shop' wechatConfigs: - apiURL:'http://wechatserver:8080/' corpID: 'wechat-corpid' apiSecret: name: 'wechat-config' key: 'apiSecret' --apiVersion: v1 kind: Secret type:Opaque metadata: name: wechat-config data: apiSecret: cGFzc3dvcmQK应用上述清单。
kubectl apply -f alertmanager-config.yaml然后创建alertmanager.yaml文件来定义Alertmanager集群。
apiVersion: monitoring.coreos.com/v1 kind:Alertmanager metadata: name: socks-shop spec: replicas:1 alertmanagerConfigSelector: matchLabels: alertmanagerConfig: examplealertmanagerConfigSelector字段被用来选择正确的AlertmanagerConfig。
应用并检查它是否被创建。
kubectl apply -f alertmanager.yamlalertmanager.monitoring.coreos.com/socks-shop已创建。一个由alertmanager操作的服务应该已经被自动创建了,用它来访问Alertmanager的web UI。
kubectl port-forward svc/alertmanager-operated 9093:9093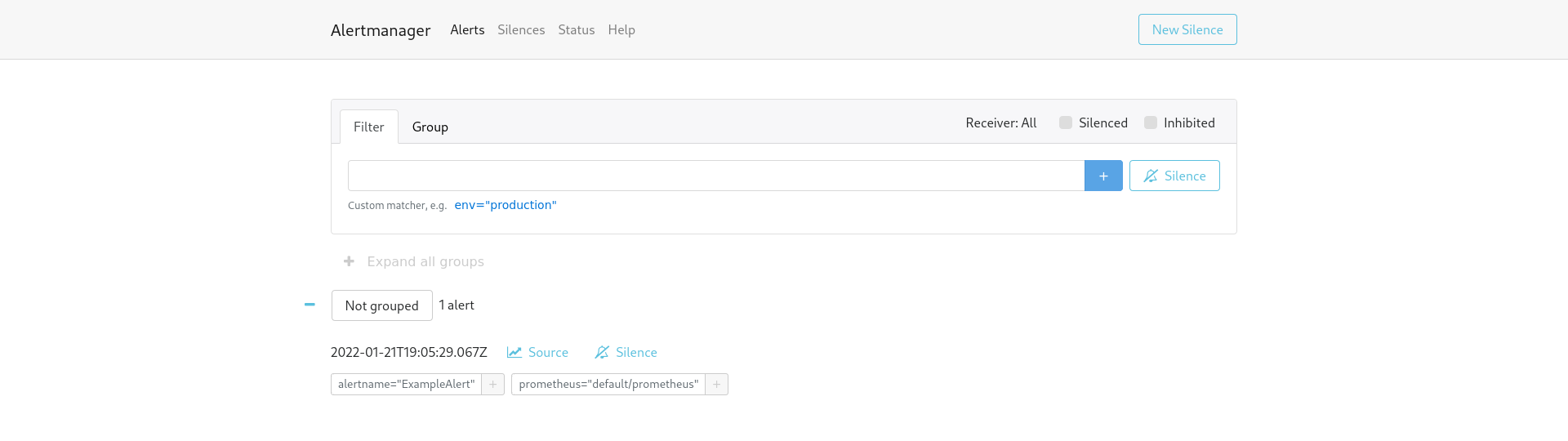
现在我们有了一个功能齐全的Alertmanager集群,但是没有任何针对它的警报。可以使用PrometheusRule自定义资源添加警报规则,以定义评估的规则。
普罗米修斯规则
PrometheusRuleCR支持定义一个或多个RuleGroups。这些组由一组规则对象组成,可以代表Prometheus支持的两类规则中的任何一类,即记录或警报。
作为一个例子,创建prometheus-rule.yaml文件,其中有以下PrometheusRule,它将总是触发一个警报。
apiVersion: monitoring.coreos.com/v1 kind:PrometheusRule metadata: creationTimestamp: null labels: prometheus: socks-shop role: alert-rules name: prometheus-example-rules spec: groups: - name: ./example.rules rules: - alert: ExampleAlert expr: vector(1)现在Alertmanager集群正在运行,并且创建了一个警报规则,我们需要把它连接到Prometheus。要做到这一点,编辑Prometheus实例,指定要使用的Alertmanager集群和要安装到其中的警报规则。
apiVersion: monitoring.coreos.com/v1 kind:普罗米修斯元数据: name: prometheus spec: serviceAccountName: prometheus serviceMonitorNamespaceSelector:{} serviceMonitorSelector:{} podMonitorSelector:{} additionalScrapeConfigs: name: additional-scrape-configs key: prometheus-additional-job.yaml resources: requests: memory:400Mi enableAdminAPI: false alerting: alertmanagers: - namespace: default name: alertmanager-operated port: web ruleSelector: matchLabels: role: alert-rules prometheus: socks-shop我们应该能够在Alertmanager用户界面中看到警报的触发,也能在Prometheus实例警报部分看到。

最后的想法
正如我们在这篇文章的开头提到的,以及在前面的例子中看到的,使用Prometheus操作员可以帮助减少以快速、自动和可靠的方式管理Prometheus和Alertmanager组件的开销。
尽管操作员提供了所有的优势,但我们必须记住,我们正在增加另一层抽象。随之而来的是复杂性的小幅增加,这可能会导致未被注意到的错误配置,可能比传统的静态配置更难调试。
最后的想法是,尽管操作者可能被视为引入了一个额外的复杂层,但我们认为这是一个合理的权衡,其好处远远超过了任何潜在的坏处。