一、explain分析工具
explain是mysql的执行计划查看工具,用于分析一个查询语句的性能。
其三种格式如下:
explain select ...
explain extended select ... # 该命令将执行计划反编译成select语句,运行 show warnings 可以得到被mysql优化后的查询语句
explain partitions select... # 该命令用于分区表的explain命令explain 命令的输出有以下字段:
id| select_type | table | type | possible_keys | key | key_len | ref | rows | Extra 下面详细叙述explain输出的各项内容。
1、id
表示查询中执行select子句或操作表的顺序,id为几就代表是第几个select。
如果id相同,则执行的循序由上到下,例如:
mysql> explain select t.id,t.name,count(*) as arts_count from arts a join type t on a.tid=t.id where is_send=0 group by t.id\G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: t
partitions: NULL
type: ALL
possible_keys: PRIMARY
key: NULL
key_len: NULL
ref: NULL
rows: 9
filtered: 100.00
Extra: Using temporary; Using filesort
*************************** 2. row ***************************
id: 1
select_type: SIMPLE
table: a
partitions: NULL
type: ref
possible_keys: tid
key: tid
key_len: 5
ref: art.t.id
rows: 978
filtered: 10.00
Extra: Using where
2 rows in set, 1 warning (0.00 sec)他们的id相同,所以执行顺序是第一行中的表再是第二行中的表。
如果id不同,id大的优先级高,先被执行。
2、select_type
表示每个查询的类型,有一下几种类型:
simple,primary,subquery,derived,union unoim result- SIMPLE:简单的 SELECT 查询,查询中不包含子查询或者 UNION;
- PRIMARY:查询中若包含任何复杂的子查询,最外层查询标记为该标识;
- SUBQUERY:在 SELECT 或 WHERE 中包含子查询,该子查询被标记为:SUBQUERY;
- DEPENDENT SUBQUERY:在 SUBQUERY 基础上,子查询中的第一个SELECT,取决于外部的查询;
- DERIVED:在 FROM 列表中包含的子查询,被标记为 DERIVED(衍生),MysqL会递归执行这些子查询,把结果放在临时表中;
- UNION:UNION 中的第二个或后面的 SELECT 语句,则标记为UNION ; 若 UNION 包含在 FROM 子句的子查询中,外层 SELECT 将被标记为:DERIVED;
- DEPENDENT UNION:UNION 中的第二个或后面的SELECT语句,取决于外面的查询;
- UNION RESULT:UNION 的结果,UNION 语句中第二个 SELECT 开始后面所有 SELECT;
从 union 表中获取结果的select标记为union result。第二个select出现在union之后被标记为union,也就是union之后的select是Union类型,但union之前的那个select不是union而是primary,整个union语句是一个union result。
如 :
select * from a union select * from b #这也是最常规的 union 联合查询若union包含在from子句的子查询中,则外层select被标记为derived。
例如:
explain select id,title from arts where id<1500 union select id,title from arts where id>70000 \G;
*************************** 1. row ***************************
id: 1
select_type: PRIMARY
table: arts
partitions: NULL
type: range
possible_keys: PRIMARY
key: PRIMARY
key_len: 4
ref: NULL
rows: 394
filtered: 100.00
Extra: Using index condition
*************************** 2. row ***************************
id: 2
select_type: UNION
table: arts
partitions: NULL
type: range
possible_keys: PRIMARY
key: PRIMARY
key_len: 4
ref: NULL
rows: 2612
filtered: 100.00
Extra: Using index condition
*************************** 3. row ***************************
id: NULL
select_type: UNION RESULT
table: <union1,2>
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: NULL
filtered: NULL
Extra: Using temporary
3 rows in set, 1 warning (0.00 sec)又例如:
explain select d1.name,(select id from t3) d2 from (select id,name from t1 where other_column="") d1 union (select name,id from t2);
得到结果如下
id select_type table
1 primary <derived3>
3 derived t1
2 subquery t3
4 union t2
null union result <union1,4>第一行:id为1,表示它是第一个select,select_type为primary表示该查询是一个外层查询,table列是<drived3>表示查询结果来自于一个衍生表。其中3代表这个该查询衍生来自第3个select,即id为3的select。
第二行:id为3,是第三个select,因为查询语句是在from之中,所以是derived。
第三行:id为2,第二个select是作为子查询。
第四行:id为4,查看第四个select,在union关键字后面,它是union类型且它是最先执行的。
第五行:id为null表示它是一个临时表,没有select,它代表的是整个语句,table列的<union1,4>表示它是对第一个和第四个select的结果的union操作。
3、type
在表中找到所需行的方式,又叫访问方式。
有如下类型:
all/index/range/ref/eq_ref/const,system/null - ALL:全表扫描,性能最差。
- index:表示基于索引的全表扫描,先扫描索引再扫描全表数据。
- range:表示使用索引范围查询。使用>、>=、<、<=、in等等。
- ref:表示采用了非唯一索引,或者是唯一索引的非唯一性前缀。
- eq_ref:一般情况下出现在多表join查询,表示前面表的每一个记录,都只能匹配后面表的一 行结果。
- const:表最多有一个匹配行,因为只有一行,所以这一行中列的值可以被优化器视为常量。
- system:system 类型一般用于 MyISAM 或 Memory 表,属于 const 类型的特例。
上面的这些type字段值,执行效率从上至下依次增强。效率从低到高依次为 all < index < range < index_merge < ref < eq_ref < const/system。
下面对type字段常用的类型做详细的说明:
all是最坏的情况,因为采用了全表扫描的方式。
index 和 all 差不多,只不过 index 对索引表进行全扫描,这样做的好处是不再需要对数据进行排序,但是开销依然很大。如果我们在 extra 列中看到 Using index,说明采用了索引覆盖,也就是索引可以覆盖所需的 SELECT 字段,就不需要进行回表,这样就减少了数据查找的开销。
range表示采用了索引范围扫描。比如下面这条SQL语句:
select * from tb_user where id>=1 and id<=5;从range这一级别开始,索引的作用会越来越明显,因此我们需要尽量让 SQL 查询可以使用到 range 这一级别及以上的 type 访问方式。
ref类型表示采用了非唯一索引,或者是唯一索引的非唯一性前缀。
比如我们对tb_order表user_id字段创建索引:
CREATE INDEX user_id_index on tb_order(user_id)然后查询user_id等于1的订单信息,EXPLAIN 执行计划如下:
EXPLAIN SELECT title,order_datetime FROM tb_order WHERE user_id=1还有in、between and,如果搜索条件不是索引为条件,就会变成全表扫描ref非唯一性索引扫描,即使用普通索引或者唯一索引的非唯一前缀作为where条件搜索。
例如:
# 我设置了一个文章表的tid字段(分类id)为普通索引
explain select * from arts where tid=6;
+----+-------------+-------+------------+------+---------------+------+---------
+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len
| ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------
+-------+------+----------+-------+
| 1 | SIMPLE | arts | NULL | ref | tid | tid | 5
| const | 2189 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+------+---------
+-------+------+----------+-------+
explain select * from arts where title="新闻标题"; #此时的 type 是 all 全表扫描
explain select t.name,arts.* from arts join type t on arts.tid=t.id; #对文章表和分类表进行多表联查
+----+-------------+-------+------------+------+---------------+------+---------
+----------+-------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len
| ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------
+----------+-------+----------+-------+
| 1 | SIMPLE | t | NULL | ALL | PRIMARY | NULL | NULL
| NULL | 9 | 100.00 | NULL |
| 1 | SIMPLE | arts | NULL | ref | tid | tid | 5
| art.t.id | 24064 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+------+---------
+----------+-------+----------+-------+
# 结果对分类表是全表扫描,对文章表是索引扫描
explain select * from arts where tid>6; # 此时的type就变为range了eq_ref:唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配。常用于主键和唯一索引扫描。
const、system:当mysql对查询进行优化并转化为一个常量的时候type就是const类型,例如使用主键或者唯一键作为where的条件查询,此时mysql会将这个查询结果转化为一个常量。
system是const的一个特例,当查询的表只有一行数据的时候,type就是system类型。
例如:
explain select * from arts where id=1300; #type 为constnull: Mysql 在优化过程中分解语句,查询时甚至不用访问表或者索引。
例如:
explain select max(id) from arts;
explain select count(*) from arts;4、possible_keys
指出 MysqL 能使用哪个索引在表中找到记录,查询涉及到的字段上若存在索引,则该索引将被列出,但不一定被查询使用。
如果该列是 NULL,则没有相关的索引。
5、key
显示在查询中实际使用到的索引,若没有使用索引,显示为 NULL。
如:
explain select title from arts where id=750000;如果要查询的字段就是这个索引,则 key 为该索引字段名,但possible_keys为null。
select id from arts查询中若使用了覆盖索引,则该索引可能出现在 key 列表,不出现在 possible_keys。
6、key_len
表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度。
key_len 显示的值为索引字段的最大可能长度,并非实际使用长度,即 key_len 是根据表定义计算而得,不是通过表内检索出的。
key_len的计算规则如下:
字符串类型:
- 字符串长度跟字符集有关,常见编码长度:gbk=2、utf8=3、utf8mb4=4;
- char(n):n*字符集长度;
- varchar(n):n * 字符集长度 + 2字节;
数值类型
- TINYINT:1个字节;
- SMALLINT:2个字节;
- MEDIUMINT:3个字节;
- INT、FLOAT:4个字节;
- BIGINT、DOUBLE:8个字节;
时间类型:
- DATE:3个字节;
- TIMESTAMP:4个字节;
- DATETIME:8个字节;
在不损失精确性的前提下,长度越短越好。
7、ref
多表联查时的连接匹配条件。
8、rows
是估算执行这条语句需要扫描的记录数,例如我的arts表有60多万条数据,我的tid字段有建立索引的。
explain select * from arts where tid=6;结果 rows为325186,要扫描三十多万条。
当我删除tid索引的时候再执行:
explain select * from arts where tid=6;rows614436,变成扫描60多万跳,变成了全表扫描。所以,查看性能 rows是很重要的一个指标,而建立索引和使用where的范围查询可以减少扫描的行数,如果用主键来查,发现rows只有1而已。
但其实,不一定扫描的行数越少就查的越快,例如我这个表有60万+的数据。
select title from arts where tid=6 and id>500000
select title from arts where id>500000 and tid=6;
select title from arts where id in (select id from arts where id>500000) and tid=6;这前两条显示的rows都是311430,第三条显示的是203329和1,但是第一个用了40s,第二个用了16s,第三个只用了1.3秒,他们的结果是一样的。
这是因为子查询查的字段是主键id,又是根据主键范围为条件查的,所以会非常快,只花了0.1秒。而外层查询又是根据主键id和索引tid查的,所以也是飞快。
这里说一下:
select title from arts where id>500000
select id from arts where id>500000这两句的条件都是用主键进行范围查询,扫描的条数也相同,但前者花了3.5秒,后者花了0.1秒而已,只因为查询的字段后者是主键。
同样说明不一定扫描行数不一定是越少就越快。
9、Extra
其他的额外的执行计划信息,在该列展示:
- Using index:该值表示相应的 SELECT 操作中使用了覆盖索引(Covering Index);
-
Using index condition:第一种情况是搜索条件中虽然出现了索引列,但是有部分条件无法使用索引,会根据能用索引的条件先搜索一遍再匹配无法使用索引的条件,回表查询数据;第二种是使用了索引下推;
- Using where:表示存储引擎收到记录后进行后过滤(Post-filter),如果查询操作未能使用索引,Using where 的作用是提醒我们 MysqL 将用 where 子句来过滤结果集,即需要回表查询;
- Using temporary:表示 MysqL 需要使用临时表来存储结果集,常见于排序和分组查询;
- Using filesort:对数据使用外部排序算法,将取得的数据在内存中进行排序,这种无法利用索引完成的排序操作称为文件排序;
- Using join buffer:说明在获取连接条件时没有使用索引,并且需要连接缓冲区来存储中间结果;
- Impossible where:说明 where 语句会导致没有符合条件的行,通过收集统计信息不可能存在结果;
- Select tables optimized away:说明仅通过使用索引,优化器可能仅从聚合函数结果中返回一行;
- No tables used:Query 语句中使用 from dual 或不含任何 from 子句;
包含不适合在其他列显示但非常重要的信息,有以下4中:
Using Index:表示相应的select查询使用了覆盖索引;覆盖索引就是包含满足查询需要的所有数据的索引
Using where:表示mysql在存储引擎收到记录后进行"后过滤",并不是说查询语句中使用了where就会有Using where:
explain select id from arts where id>500000; # 显示了Using where
explain select * from arts where id>500000; # 没有显示Using where Using temporary:表示使用了临时表来存储结果集,常用于排序和分组查询。如果同时出现了Using temporary和Using filesort 则性能是不佳的,这种情况出现在使用非索引字段分组的情况。
explain select title from arts where id>600000 group by is_send desc;
+------+-------------+-------+-------+---------------+---------+---------+------+--------+--------------------------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+-------+-------+---------------+---------+---------+------+--------+--------------------------------------------------------+
| 1 | SIMPLE | arts | range | PRIMARY | PRIMARY | 4 | NULL | 122818 | Using index condition; Using temporary; Using filesort |
+------+-------------+-------+-------+---------------+---------+---------+------+--------+--------------------------------------------------------+
explain select title from arts group by id desc;
+------+-------------+-------+------+---------------+------+---------+------+--------+----------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+-------+------+---------------+------+---------+------+--------+----------------+
| 1 | SIMPLE | arts | ALL | NULL | NULL | NULL | NULL | 614436 | Using filesort |
+------+-------------+-------+------+---------------+------+---------+------+--------+----------------+Using filesort:文件排序,mysql将无法利用到索引的排序操作成为文件排序,所以出现Using filesort 比不出现Using filesort的性能差。
select sql_no_cache title from arts where id>500000 order by create_time desc; # Using index condition; Using filesort 用了3秒多
explain select sql_no_cache title from arts where id>700000 order by id desc; # Using where; 用了1秒多所以尽可能使用索引排序。
Explain不会告诉你关于触发器,存储过程的信息或者用户自定义函数对查询的性能影响情况。
Explain不会考虑缓存因素,并且Explain不会显示mysql在查询中所做的优化,部分统计信息是估算的,不准确。
如果有子查询或者使用了临时表的视图,使用explain的开销会很大。
总结:
EXPLAIN 命令输出字段:
- id:select查询的序列号,表示查询中执行select子句或操作表的顺序;
- select_type:表示 SELECT 的类型;
- table:输出结果集的表,显示这一步所访问数据库中表名称,有时不是真实的表名字,可能是简称;
- type:表示表的连接类型;
- possible_keys:表示查询时,可能使用的索引;
- key:表示实际使用的索引;
- key_len:索引字段的长度;
- ref:列与索引的比较,表示表的连接匹配条件,即哪些列或常量被用于查找索引列上的值;
- rows:扫描出的行数,表示 MysqL 根据表统计信息及索引选用情况,估算的找到所需的记录扫描的行数;
- filtered:按表条件过滤的行百分比;
- extra:执行情况的说明和描述;
MySQL执行计划的局限:
- 只是计划,不是执行 sql 语句,可以随着底层优化器输入的更改而更改;
- EXPLAIN 不会告诉显示关于触发器、存储过程的信息对查询的影响情况;
- EXPLAIN 不考虑各种 Cache;
- EXPLAIN 不能显示 MysqL 在执行查询时的动态,因为执行计划在执行查询之前生成;
- EXPALIN 部分统计信息是估算的,并非精确值;
- EXPALIN 只能解释 SELECT 操作,其他操作要重写为 SELECT 后查看执行计划;
- EXPLAIN PLAN 显示的是在解释语句时数据库将如何运行 sql 语句,由于执行环境和 EXPLAIN PLAN 环境的不同,此计划可能与 sql 语句实际的执行计划不同;
在使用EXPLAIN分析慢SQL的时候,我们主要关注type字段,最好可以使用到 range 这一级别及以上的 type 访问方式,如果只使用到了 all 或者 index 这一级别的访问方式,我们可以从 SQL 语句和索引设计的角度上进行改进。
其次关注rows字段,绝大部分rows小的语句执行一定很快,所以优化语句基本上都是在优化rows。
二、explain分析SQL语句案例
1、Type 访问类型
有8类,性能从好到坏依次是:
System > const > eq_ref > ref > range > index >all要保证查询至少达到range级别,最好能达到ref级别。
System:表只有一条记录(实际中基本不存在这个情况);
Const:当条件查询是对主键或者唯一键进行精确查询(=);例如 select * from t1 where id=1,mysql会将这条记录作为常量;
Eq_ref:唯一性索引扫描。当使用唯一键为条件查询时就是eq_ref;
例如:
select * from user where userName = ‘abc’Ref:相对应eq_ref,当使用普通索引作为条件进行精确查询时就是ref, 普通索引可以有重复的字段值。
例如:
select * from employee where name = ‘zbp’ 这条语句不是eq_ref而是ref,因为name不是唯一索引而是个普通索引,名字允许重名。
Eq_ref:只会返回一条记录,而ref可以返回多条记录。
Range:对添加了索引的字段进行范围查找。
如 in/bettween/</>。
Index:index表示使用了覆盖索引。Index和all相同点是都会对全部的叶子节点进行遍历。区别是index遍历的是不含行数据的叶子节点(只遍历索引值),all是遍历含有行数据的叶子节点,也就是说index遍历的次数和all一样,但是每次遍历(读取)的数据量比all小很多。所以index会比All快很多很多很多很多。
例如:
select id from t1;All:全表扫描。
例如:
select * from t1;2、执行select子句或操作表的顺序
3种情况:
1. id相同执行顺序由上到下
比如:
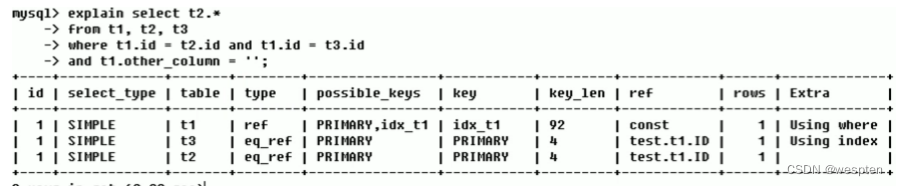
看第一列和第三列:Id都是1,所以执行的顺序是先加载t1 , 然后 t3,最后t2。
2. Id不同:如果是子查询,id的序号会递增,id值也大优先级越高,越先被执行
比如:

看第一列和第三列:先执行查t3表的子查询,再执行t1子查询,最后查t2查询。
3. Id相同不同都存在
比如:

看第一列和第三列:首先会执行id大的sql,然后id相同的则从上到下顺序执行。
derived是衍生表的意思,也就是mysql把 select t3.id from t3 where xxx 这句的执行结果处理成了一个虚拟的表,这种把一个查询的结果临时存为一个表就是衍生表。
derived2中的2是id,表示这张衍生表是id为2的语句生成的衍生表,也就是表s1。
所以上面的执行顺序是:
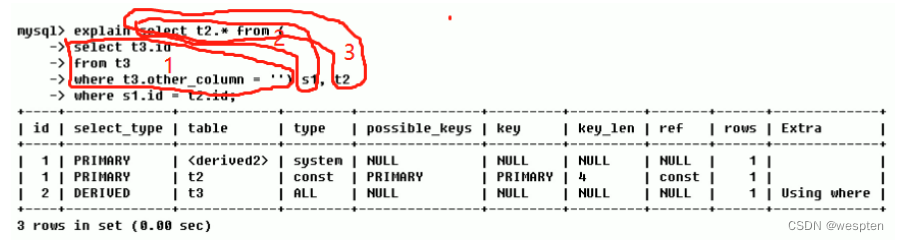
3、显示哪些列或者常量被作为被检索值去进行查找
例如:

只看ref字段这里表示,t2的col1以及常量 ‘ac’ 被作为要查找的值进行检索。
4、Using filesort 使用了文件排序
mysql中无法利用索引完成的排序,又叫做“文件排序”。出现这种情况很危险,性能不好。
文件排序不是在文件中进行排序而是在内存中进行排序,你用手指头想想怎么可能在文件中进行排序。
比如:联合索引 index(col1, col2, col3):

这条语句的where使用到了索引,但是order by排序的时候没有用到索引的排序,所以用了文件排序。意味着mysql要重新对结果集在内存中(sort_buffer 排序缓冲区)排序。
5、Using temporary 使用临时表保存中间结果
当mysql对查询的结果排序或分组时由于内存不足以存放要排序的内容,可能会内部创建临时表。出现了这个比using filesort 还惨,因为内部创建临时表意味着会产生额外的IO。
比如:

从 Using temporary 和 Using filesort 这个例子说明,即使where用到了索引,但如果排序没用到索引,性能也不好。
6、Using index 使用了覆盖索引
出现这个,性能会很好。
如果同时出现using where ,表明索引用来执行where条件查找。
如果没有出现using where,表明select查的是索引列,但是没有执行where查找。
例如:

这是同时出现 using index 和 using where。

只出现了 using index。
三、对SQL执行慢进行分析优化
SQL执行慢会有以下两种情况。
偶尔慢:
- DB 在刷新脏页;
- redo log 写满了;
- 内存不够用,要从 LRU 链表中淘汰;
- MySQL认为系统空闲的时候;
- MySQL关闭时;
一直慢的原因:
- 索引没有设计好、sql 语句没写好、MySQL选错了索引。
MySQL慢查询优化步骤:
- 开启MysqL慢查询日志,通过慢查询日志定位到执行较慢的sql语句。
- 利用explain关键字可以模拟优化器执行SQL查询语句,来分析SQL查询语句,看是否使用到了索引,以及具体的数据表访问方式。
- 使用SHOW PROFILE 进一步分析SQL的每一步执行时间以及CPU、IO等资源使用情况。
- 通过查询的结果进行优化。
优化方式有以下:
- 首先分析语句,看看是否包含了额外的数据,可能是查询了多余的行并抛弃掉了,也可能是加了结果中不需要的列,要对sql语句进行分析和重写。
- 分析优化器中索引的使用情况,要修改语句使得更可能的命中索引。比如使用组合索引的时候符合最左前缀匹配原则。not in,not like都不会走索引,可以优化为in。
- 如果对语句的优化已经无法执行,可以考虑表中的数据是否太大,如果是的话可以横向和纵向的切表。
1、慢查询日志定位慢SQL
慢查询日志是MySQL提供的一种日志记录,它用来记录所有执行时间超过long_query_time参数值的SQL。long_query_time的默认值为10秒,默认情况下执行超过10s的SQL语句,会被记录到慢查询日志中。
如果开启了mysql的慢日志,那么该日志会记录下所有mysql认为效率低的sql语句,我们可以通过查看慢日志获取这些语句并进行优化。
MySQL的慢查询日志比较粗略,主要是基于以下3项基本的信息:
- Query_time:查询耗时。
- Rows_examined:检查了多少条记录。
- Rows_sent:返回了多少行记录(结果集)。 以上3个值可以大致衡量一条查询的成本。 如果检查了大量记录,而只返回很小的结果集,则往往意味着查询质量不佳。
其他信息包括如下几点:
- Time:执行SQL的开始时间。
- Lock_time:等待tablelock的时间,注意InnoDB的行锁等待是不会反应在这里的。
- User@Host:执行查询的用户和客户端IP。
1. 开启慢查询日志
在使用前,我们需要先看下慢查询是否已经开启,使用下面这条命令查看是否开启。
show variables like '%slow_query_log%';
slow_query_log=OFF,表示未开启。 slow_query_log=ON表示慢查询已经开启,如果未开启,通过以下命令开启:
set global slow_query_log='ON';开启后,使用show variables like '%slow_query_log%'再来看下是否开启。
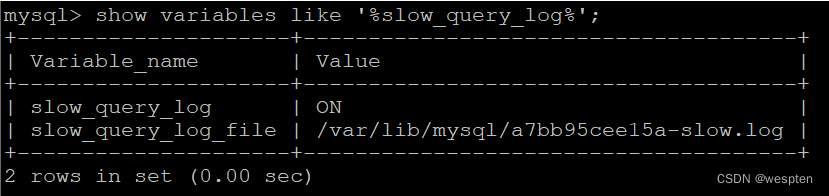
slow_query_log_file是慢查询日志文件目录。
Mysql支持文件和数据库表两种日志存储方式,默认将日志存储在文件中,使用下面这条命令查看存储方式:
show variables like '%log_output%';
可以修改为存储到数据库表,这样日志信息就会被写入到mysql.slow_log表中。
set global log_output='TABLE';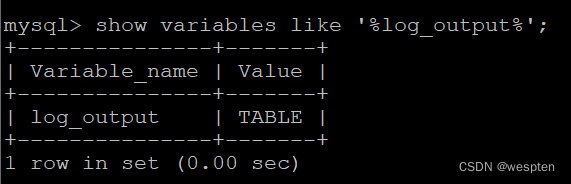
MySQL数据库同时支持两种日志存储方式,配置的时候以逗号隔开即可。
set global log_output='TABLE,FILE';日志记录到系统的专用日志表中,要比记录到文件耗费更多的系统资源,因此对于需要启用慢查询日志,又需要能够获得更高的系统性能,那么建议优先记录到文件。
2. 设置慢查询的时间阈值
long_query_time的默认值为10秒,通过以下命令可以查看慢查询的时间阈值。
show variables like '%long_query_time%';
如果我们想修改long_query_time参数值,通过以下命令即可,假如我们把long_query_time值设置为1。
set global long_query_time = 1;注意:修改完再次执行show variables like ‘%long_query_time%’,发现还是默认的10S,是不是没有修改成功呢?
其实已经修改成功了,此时只需要关闭当前连接,再重新连接就可以了。
使用set global slow_query_log=1开启了慢查询日志只对当前数据库生效,如果MySQL重启后则会失效。
如果要永久生效,需要修改my.cnf配置文件,配置文件如下:
[mysqld]
slow_query_log = 1 # 开启慢查询
slow_query_log_file = /data/mysql/logs/slow.log # 慢查询日期路径
long_query_time = 1 # 慢查询时间阈值
log_timestamps = SYSTEM
log_output = FILE3. 慢查询日志内容
如果自己mysql上没有慢查询,可以通过sleep(N)函数来模拟慢查询操作,比如下面这条模拟慢查询的语句。
SELECT *, sleep(3) FROM tb_user WHERE id<4注意:sleep(N)函数表示,每返回一行数据经过WHERE条件判断后,都会触发Sleep函数,比如上面的SQL语句,返回3条数据,每条阻塞3秒,查询时间总共是9秒。

有了慢查询日志,可以使用以下命令获取有多少条日志。
show global status like '%Slow_queries%';
可以看到现在有两条慢查询,接下来我们来看下慢查询日志具体记录哪些内容。
# Time: 2022-01-22T12:56:00.070149Z
# User@Host: root[root] @ localhost [] Id: 8
# Query_time: 4.006927 Lock_time: 0.000074 Rows_sent: 4 Rows_examined: 4
SET timestamp=1642856160;
SELECT *, sleep(1) FROM tb_user WHERE id<5;第一行,记录的是该条 SQL 语句执行的时间。
第二行,记录的是执行该SQL语句的用户和 IP 以及链接 id。
第三行的几个字段解释如下:
- Query_time: duration 语句执行时间,以秒为单位。
- Lock_time: duration 获取锁的时间(以秒为单位)。
- Rows_sent: 发送给 Client 端的行数。
- Rows_examined: 服务器层检查的行数(不计算存储引擎内部的任何处理)
第四行,记录是此SQL语句执行时候的时间戳。
第五行,就是具体的慢SQL,也是我们需要优化的SQL。
2、分析慢查询日志
可以使用mysqldumpslow命令获得慢查询日志摘要来处理慢查询日志,或者使用更好的第三方工具pt-query-digest。
慢查询日志里的慢查询不一定就是不良SQL,还可能是受其他的查询影响,或者受系统资源限制所导致的慢查询。 比如会话被阻塞了,实际上是一个行锁等待50s超时,也会被记录到了慢查询日志里。
1. mysqldumpslow 日志分析工具
MySQL 提供了 mysqldumpslow 工具统计慢查询日志。mysqldumpslow 命令的参数如下:
- -s:采用 order 排序的方式,排序方式可以有以下几种。分别是 c(访问次数)、t(查询时间)、l(锁定时间)、r(返回记录)、ac(平均查询次数)、al(平均锁定时间)、ar(平均返回记录数)和 at(平均查询时间)。其中 at 为默认排序方式。
- -t:返回前 N 条数据 。
- -g:后面可以是正则表达式,对大小写不敏感。
mysqldumpslow常见用法:
mysqldumpslow -t10 绝对路径 # 获取访问时长最长的10条语句,并存到指定路径中
mysqldumpslow -s c -t10 绝对路径 # 访问次数最多的10条语句
mysqldumpslow -s r -t10 绝对路径 # 访问条数最多的10条比如我们想要按照查询时间排序,查看前3条 SQL 语句,这样写即可:
mysqldumpslow -s r -t 3 /var/lib/mysql/a7bb95cee15a-slow.log得到访问次数最多的5个SQL:
mysqldumpslow -s c -t 5 /var/lib/mysql/a7bb95cee15a-slow.log得到按照时间排序的前5条里面含有左连接的查询语句:
mysqldumpslow -s t -t 10 -g “left join” /var/lib/mysql/a7bb95cee15a-slow.log另外建议在使用这些命令时结合 | 和more 使用 ,否则有可能出现刷屏的情况。
mysqldumpslow -s r -t 5 /var/lib/mysql/a7bb95cee15a-slow.log | more2. pt-query-digest 日志分析工具
首先安装pt-query_digest命令。
wget www.percona.com/get/pt-query-digest chmod u+x pt-query-digest # 下载pt-query-digest命令
chmod u+x pt-query-digest基本命令格式:
pt-query-digest [options] [files] [dsn]常见用法:假设慢日志路径为 /tmp/mysql-slow.log。
pt-query-digest /tmp/mysql-slow.log > slow.rtf #直接分析慢查询
pt-query-digest --since 1800s /tmp/mysql-slow > slow.rtf #分析半小时内的慢查询
pt-query-digest --since '2020-01-01 00:00:00' --until '2020-01-02 00:00:00' /tmp/mysql-slow > slow.rtf #分析指定范围内时间的慢查询
pt-query-digest --limit 95%:20 /tmp/mysql-slow > slow.rtf #显示95%的最差查询或者20个最差查询相应参数解释:
- Exectime:执行时间。
- Lock time:表锁的时间。
- Rows sent:返回的结果集记录数。
- Rowsexamine:实际扫描的记录数。
- Query size:应用和数据库交互的查询文本大小。
- Rank:所有查询日志分析完毕后,此查询的排序。
- Query ID:查询的标识字符串。
- Responsetime:总的响应时间,以及总占比。一般小于5%可以不用关注。
- Calls:查询被调用执行的次数。
- R/Call:每次执行的平均响应时间。
- Apdx:应用程序的性能指数得分。(Apdex响应的时间越长,得分越低。)
- V/M:响应时间的方差均值比(变异数对平均数比,变异系数)。可说明样本的分散程度,这个值越大,往往是越值得考 虑优化的对象。
- Item:查询的简单显示,包括查询的类型和所涉及的表。
当然该命令也可以用于分析mysql二进制日志文件。
注意,二进制日志不是mysql服务的日志,二进制日志一般放在数据目录,可以通过show master status查看是否开启二进制日志。
mysqlbinlog mysql-bin.012639 > /tmp/012639.log # 将二进制文件转为文本格式
pt-query-digest --type binlog /tmp/012639.log > binlog.rtf对于以上分析命令,同样可以加上参数筛选信息,如“--since”、“--until”。
3. show profile 进行性能分析
show profile 相比 EXPLAIN 能看到更进一步的执行解析,包括 SQL 都做了什么、所花费的时间等。
默认情况下,show profile 是关闭的,使用下面的命令查看状态。
mysql> show variables like 'profiling';
通过设置 profiling='ON’来开启 show profile:
mysql > set profiling = 'ON';
show profile命令只是在本会话内起作用,即无法分析本会话外的语句。
开启分析功能后,所有本会话中的语句都被分析(甚至包括执行错误的语句),除了SHOW PROFILE和SHOW PROFILES两句本身。
查看当前会话都有哪些 profiles,使用下面这条命令:
mysql > show profiles;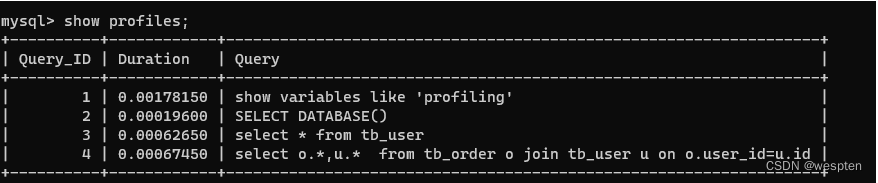
使用下面的命令我们可以查看上一个查询的开销:
mysql > show profile;
可以给show profile 指定一个 for query id 来查看指定 id 的语句,比如查看Query_ID为4的SQL信息。
mysql> show profile for query 4;还可以给输出添加新的列,取值范围可以如下:
- ALL 显示所有性能信息;
- BLOCK IO 显示块IO操作的次数;
- CONTEXT SWITCHES 显示上下文切换次数,不管是主动还是被动;
- CPU 显示用户CPU时间、系统CPU时间;
- IPC 显示发送和接收的消息数量;
- PAGE FAULTS 显示页错误数量;
- SOURCE 显示源码中的函数名称与位置;
- SWAPS 显示SWAP的次数;
比如:
mysql> show profile cpu,block io,swaps for query 4;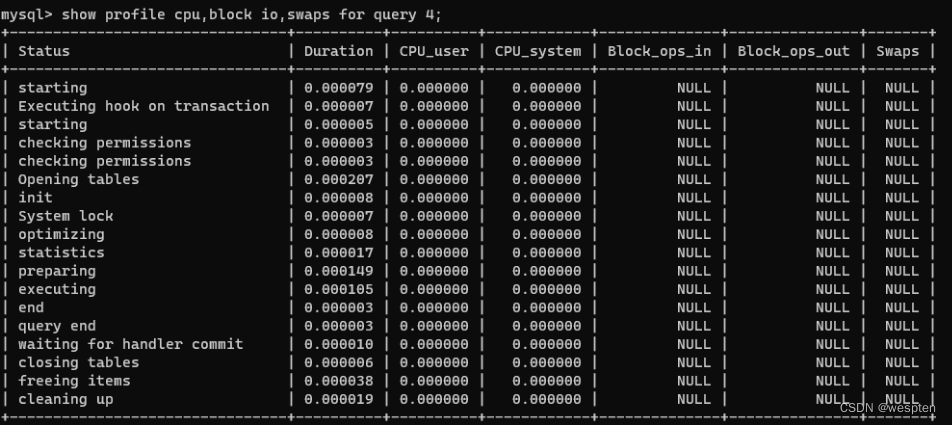
通过上面的结果,我们可以弄清楚每一步骤的耗时,以及在不同部分,比如 CPU、block io 的执行时间,这样我们就可以判断出来 SQL 到底慢在哪里。
总结:
进行MySQL慢查询分析时,首先通过慢查询日志定位执行慢的 SQL,然后通过 EXPLAIN 分析该 SQL 语句是否使用到了索引和具体的数据表访问方式是怎样的。
如果有需要最后再使用 SHOW PROFILE 进一步了解 SQL 每一步的执行时间,包括CPU 、I/O 等资源的使用情况。
四、SQL优化案例
1、案例一
有一个文章表,只有id主键,其他字段没有建立索引。
现要求查询 category_id 为1 且 comments 大于1 的情况下,按views排序的数据。
Select * article where category_id = 1 and comments > 1 order by viewsExplain 分析如下:

没有使用索引,而且排序是一个文件排序。
优化1: 创建联合索引 index idx_article_ccv (category_id, comments, views)
此时再查,结果如下:

使用了key字段表示使用了联合索引idx_article_ccv,type表示访问类型是一个range按范围查询,但是还是使用了文件排序(using filesort)。
原因是使用了范围条件(comments>1)之后的条件或排序无法使用索引,也就是说 views 字段排序没用到索引。
优化2:删掉刚刚的索引,重新创建联合索引 index idx_article_ccv (category_id, views)
这个索引只包含两个字段,不含comments字段。

Type的类型是ref,使用到了索引,而且没有用到文件排序,而是使用了索引B+树中的排序。
mysql会找到B+树中满足category_id=1的叶子节点(包含其他列数据),从磁盘读取到内存,然后再在内存中过滤找到comments>1的数据。由于在B+树中已经排好了序所以不会在内存中对views排序。
2、案例二
现在有一个博客表(也是一个文章表)blogs,还有一个分类表 category 。我想做一个关联查询,关联字段是category.id = blogs.tid。假设现在category.id是主键,但是blogs.tid没有建立索引。
explain select * from blogs b join category c on b.tid=c.id;结果如下:

发现blogs表全表扫描(type为All),没有用到索引(key为null),扫描条数为185(我的博客表一共只有185条记录);而category是唯一索引扫描(type为eq_ref),使用了主键(key为primary),只扫描了1条(category表共10个分类,有10条记录)。
博客表是一个全表扫描,效率很低。
优化1:对blogs的tid建立单列索引后再查

发现现在变成 category没有使用索引,而blogs使用了索引tid,访问类型是ref。扫描的条数变为 10+23 = 33。效率明显提高。
这个例子想说明的是:
- .inner join联查,mysql默认小表作为驱动表,大表作为被驱动表,让小表驱动大表。Left join联查,mysql会让左边的表作为驱动表,右边的表作为被驱动表。Right join同理;
- 多表联查会全表扫描驱动表的(例子中的表category),所以在使用left join的时候尽量把小表放在左边,让小表成为驱动表,这样会对小表进行全表扫描,好过去对大表全表扫描;
- 多表联查中要保证关联字段建立了索引;