
——大淘宝技术数据研发工程师 伯略

在日常的AB实验情景中,业务通常会遇到策略实际干预人群占分桶人群比例较低的问题,这通常会导致策略效果业务效果不明显以及统计检验难以判断是否显著等问题。作者对低响应实验的定义、影响以及可能的解决方案进行了梳理、介绍和分析,并基于仿真模拟数据和实际线上实验数据进行效果测试。核心结论如下:(1)对于业务效果不显著问题,通过最基础的工具变量方法估计可以一定程度上解决;优化后的倾向得分匹配方案也能较好地解决但需要以一定的偏误为代价(直接应用倾向得分匹配可以在单一场景做针对性优化,但作为通用化的解决方案难度较大);(2)对于统计效果不显著问题,如果在工具变量应用中能够找到合适的协变量则能够有一定程度的解决;优化后的倾向得分匹配方案也能较好地解决,但仍以一定的偏误为代价。

▐ 低响应实验的定义
在AB实验中,由于工程链路、业务要求、策略效果等因素导致样本分流的节点与策略生效的节点存在较大漏损,导致仅有少量用户实际被策略触达,这类实验称为低响应实验。在实际业务中存在很多典型例子,例如:在淘宝首页POP干预促活实验中,由于AB分流是在用户进入首页时触发的,但用户实际被策略影响(曝光或点击POP)受算法调控、用户选择的影响,最终实际被策略触达的人可能不到分桶用户的10%,从而导致策略效果被大幅稀释。
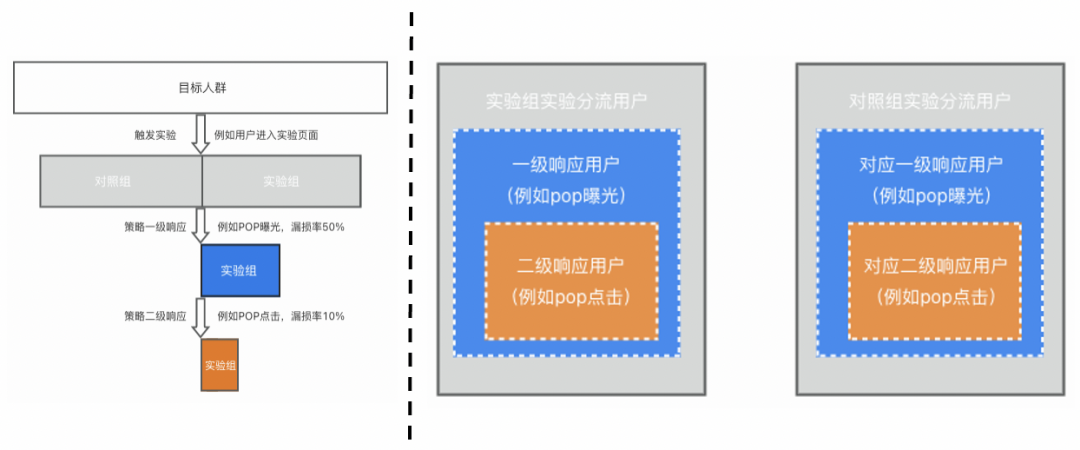
图一:实验链路及样本构成
-
该实验的分流节点为用户进入淘宝首页时,所以实验组、对照组实验分流用户为各自分桶进入首页的用户 -
受pop疲劳度算法控制等因素的影响,实验组仅有部分用户成功被pop曝光,这构成了该实验的第一个响应漏斗(首页->曝光);对照组在“平行世界”存在对应的一批用户也被pop曝光 -
对于pop曝光用户,用户将根据个人喜好选择是否点击pop,这构成了该实验的第二个响应漏斗(曝光->点击);对照组在“平行世界”存在对应的一批用户也会点击pop
▐ 低响应实验的影响
低响应实验的影响可以概括为两方面:(1)降低指标的业务显著性;(2)降低指标的统计显著性。业务显著性降低指指标的均值因为一部分用户为未被策略干预而拉低;统计显著性降低指由于引入了一部分不含任何增量信息的样本(即引入噪声),导致判断指标是否有增量的灵敏度降低(即统计检验的power降低)。
为方便后续的说明,首先对实验样本的相关指标进行定义。
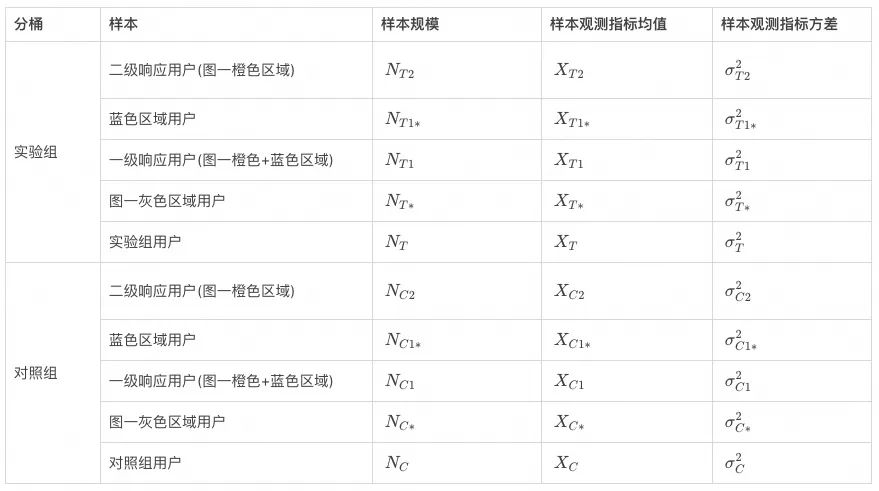
业务显著性
以“实验能力”漏斗为例(首页->曝光):
基于分桶用户计算的策略增量为:
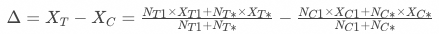
基于一级响应用户计算的策略增量为:
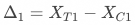
为方便讨论,假设各指标方差为0,实验组与对照组一级响应率相等且为
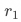 (期望形式的结果类似)
(期望形式的结果类似)根据“实验漏斗的定义”有:
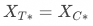
此时,
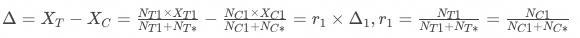
统计显著性
仍以“实验能力”漏斗为例(首页->曝光),基于分桶用户计算的策略增量 的方差为:
的方差为: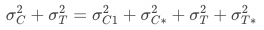 (假设实验组与对照组指标均值协方差为0),基于一级响应用户计算的策略增量
(假设实验组与对照组指标均值协方差为0),基于一级响应用户计算的策略增量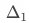 的方差为
的方差为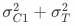 。由于方差大于0,因此基于分桶用户计算的策略增量的波动大于基于一级响应用户计算的策略增量的波动,导致统计上不易判断增量是否显著。
。由于方差大于0,因此基于分桶用户计算的策略增量的波动大于基于一级响应用户计算的策略增量的波动,导致统计上不易判断增量是否显著。
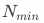 ,则实验漏斗为
,则实验漏斗为
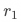 时需要的最小实验量大致为
时需要的最小实验量大致为
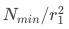 ,即当实验漏斗为10%时,需要的最小样本量会变大100倍。反过来讲,如果实验可用样本量不变,统计检验的灵敏度会相应下降。
,即当实验漏斗为10%时,需要的最小样本量会变大100倍。反过来讲,如果实验可用样本量不变,统计检验的灵敏度会相应下降。

低响应解决方案概览
不同的应用场景、不同的实验问题适用的方案有所差异。本文针对已了解的方案进行了梳理,大致可分为以下几类方案:
▐ 通过工程链路和数据底层改造将AB分流节点后移
▐ 工具变量估计
工具变量估计在经济、医学、生物领域有着广泛的应用,但通常面临着找不到合适的“工具变量”的问题。互联网场景下的AB实验为该方案提供了一个天然有效的工具变量(分桶变量),因此该方案具备通用化应用的可能。不含协变量的工具变量估计因为没有提供额外信息,所以理论上不会降低信噪比而提升统计检验灵敏度。引入协变量后的工具变量估计虽然提供了额外的信息可以提升检验灵敏度,但提供了未控制混杂变量对策略变量评估效果的影响路径,因此会导致估计结果不一致。
▐ 基于倾向得分匹配获得同质人群
AB实验的基础之一是对比的两个样本性质相同,因此对比得到的增量可归因为策略增量。类似的,当实验出现漏斗时,我们如果能够找到策略实际干预人群的同质人群,那么由此计算的增量也可归因为策略增量。为了获得同质人群,虽然我们可在众多维度上保持人群同质,但理论上我们无法控制住所有的混杂因素。因此,评估结果与真实值会存在偏差。
基于倾向得分匹配获得同质人群的估计方案由于引入了大量变量寻找同质人群,因而很难阻断未控制混杂因素通过这些变量对策略变量产生影响。与之不同,含协变量的工具变量估计方案可以只引入一个协变量,更容易阻断未控制混杂因素对策略变量产生影响,因而在提升统计显著性的同时更容易获得一致的评估结果。

工具变量与潜在结果分析框架
▐ 工具变量介绍
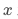 对
对
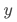 的影响时,我们往往得到的是相关性结论。之所以会这样,是因为其他影响
的因素
的影响时,我们往往得到的是相关性结论。之所以会这样,是因为其他影响
的因素
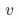 未被控制且这些因素与
相关,从而导致我们把一部分对的影响归结到对的影响上。上述文字表述,转化成数学公式可表示为:
未被控制且这些因素与
相关,从而导致我们把一部分对的影响归结到对的影响上。上述文字表述,转化成数学公式可表示为:
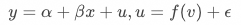 为业务关注的变量(例如,是否来访淘宝),
为业务关注的变量(例如,是否来访淘宝),
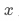 为策略变量(比如是否曝光pop),
为策略变量(比如是否曝光pop),
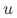 表示所有影响但未控制变量以及噪声的影响。对于上述回归模型,当
表示所有影响但未控制变量以及噪声的影响。对于上述回归模型,当
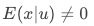 ( 即中未控制的变量与存在相关性)时,常用的估计方案无法得到
( 即中未控制的变量与存在相关性)时,常用的估计方案无法得到
 的无偏一致估计,得到的估计值将包含一部分对的影响。
的无偏一致估计,得到的估计值将包含一部分对的影响。
 满足以下条件,仍可通过一定方式得到的无偏一致估计:和相关;(2)和相关;(3)仅通过影响。用图的方式可表示为:
满足以下条件,仍可通过一定方式得到的无偏一致估计:和相关;(2)和相关;(3)仅通过影响。用图的方式可表示为:
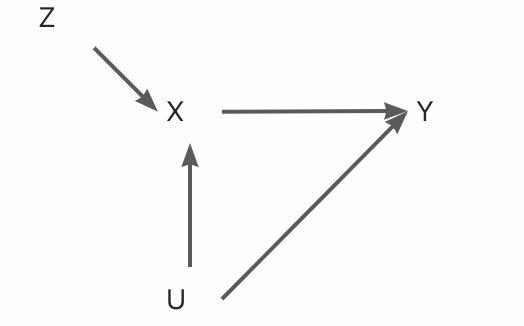
虽然工具变量方法非常简明,但在经济、生医领域一个符合假设要求的工具变量 非常难找到。与之不同,互联网的AB场景中,分桶变量(属于实验组为1,对照组为0)是一个完美的工具变量。以首页pop这个实验为例,假如我们关注的是用户是否曝光pop对用户来访淘宝的影响:(1)分桶变量与用户是否曝光pop()相关(因为只有实验组的用户才会曝光pop);(2)分桶变量与无关,因为分桶是随机的;(3)分桶变量仅通过影响用户曝光对用户淘宝来访产生影响,因为分流->曝光pop漏损的用户实际没有受到策略影响。因为满足工具变量的每个要求,所以分桶变量是一个合理的工具变量。当我们关注的是点击pop对用户来访淘宝的影响时,分桶变量可能不再是一个合适的工具变量。对于前两个假设要求,分桶变量仍旧满足。但对于第三个要求,如果图一蓝色区域的用户因为pop曝光受到了影响,此时除了通过(点击pop)影响以外,还可以通过曝光pop影响,那么第三个条件不再满足。所以,此时分桶变量不再是一个合理的工具变量。
非常难找到。与之不同,互联网的AB场景中,分桶变量(属于实验组为1,对照组为0)是一个完美的工具变量。以首页pop这个实验为例,假如我们关注的是用户是否曝光pop对用户来访淘宝的影响:(1)分桶变量与用户是否曝光pop()相关(因为只有实验组的用户才会曝光pop);(2)分桶变量与无关,因为分桶是随机的;(3)分桶变量仅通过影响用户曝光对用户淘宝来访产生影响,因为分流->曝光pop漏损的用户实际没有受到策略影响。因为满足工具变量的每个要求,所以分桶变量是一个合理的工具变量。当我们关注的是点击pop对用户来访淘宝的影响时,分桶变量可能不再是一个合适的工具变量。对于前两个假设要求,分桶变量仍旧满足。但对于第三个要求,如果图一蓝色区域的用户因为pop曝光受到了影响,此时除了通过(点击pop)影响以外,还可以通过曝光pop影响,那么第三个条件不再满足。所以,此时分桶变量不再是一个合理的工具变量。
▐ 不含协变量的工具变量估计结果
在互联网AB场景的应用中,由于工具变量是二值变量,通常也是个二值变量(例如是否曝光pop),此时基于工具变量的估计结果非常简单且符合直觉。
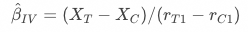
其中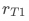 表示实验组pop曝光的响应率,
表示实验组pop曝光的响应率,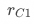 表示对照组pop曝光的响应率。对于上述提到的首页pop促活实验,由于对照组不会曝光pop,所以
表示对照组pop曝光的响应率。对于上述提到的首页pop促活实验,由于对照组不会曝光pop,所以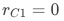 。该估计结果可由2SLS等相对通用的估计方法得到,但在和均为二值变量时,有一种更为简单的理解方式。根据增量的定义有:
。该估计结果可由2SLS等相对通用的估计方法得到,但在和均为二值变量时,有一种更为简单的理解方式。根据增量的定义有:
增量=实验组pop曝光用户的增量+实验组灰色区域用户的增量

-
根据工具变量的第3点假设有  ,所以大致有
,所以大致有
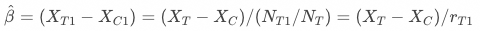
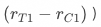 。看似我们已经解决了低响应问题业务显著性的问题,但实际上并不完全。识别的增量对应哪群用户?是否在策略推全后仍然有这么多的增量?这些问题我们并不清楚。
。看似我们已经解决了低响应问题业务显著性的问题,但实际上并不完全。识别的增量对应哪群用户?是否在策略推全后仍然有这么多的增量?这些问题我们并不清楚。
▐ 不含协变量的工具变量估计与潜在结果分析框架
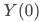 、
、
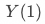 为用户在未响应策略、响应策略(曝光pop、点击pop)时观测指标的结果;
为用户在未响应策略、响应策略(曝光pop、点击pop)时观测指标的结果;
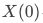 、
、
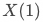 为用户在对照组和实验组时策略响应的情况。
为用户在对照组和实验组时策略响应的情况。
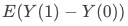 通常称作ATE(平均处理效应),即用户在策略上的平均处理效果,对其展开有:
通常称作ATE(平均处理效应),即用户在策略上的平均处理效果,对其展开有:
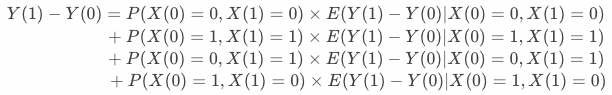
永不响应用户
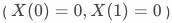 ,即不管有无策略干预,总不响应
,即不管有无策略干预,总不响应总是响应用户
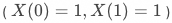 ,即不管有无策略干预,总是响应
,即不管有无策略干预,总是响应顺从用户
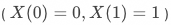 ,即受实验干预时响应,否则不响应
,即受实验干预时响应,否则不响应对抗用户
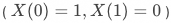 ,即受实验干预时不响应,否则响应
,即受实验干预时不响应,否则响应
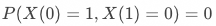
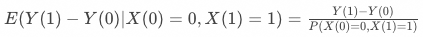
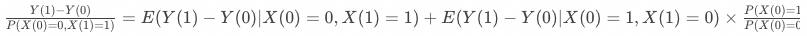
▐ 含协变量的工具变量估计
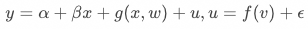
其中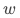 为引入的可观测的协变量。类似对的要求,需要混杂因素无法通过影响对的效应,我们才能获得的一致估计结果。然而这样的协变量相对难找,能否找到取决于研究的指标和分析的场景。假如某个实验考虑的是红包策略对饿了么DAU的影响,那么用户所在地的降雨量可能是一个很好的协变量:既影响用户是否来访饿了么,也是个相对外生的变量不受用户自身主观因素的影响。对于淘宝的DAU场景,由于降雨量对用户是否来访淘宝影响可能很弱,降雨量不再是个很好的指标。如果有比较合适的协变量能够引入,则可既解决低响应实验的业务显著问题、也能解决统计显著问题。
为引入的可观测的协变量。类似对的要求,需要混杂因素无法通过影响对的效应,我们才能获得的一致估计结果。然而这样的协变量相对难找,能否找到取决于研究的指标和分析的场景。假如某个实验考虑的是红包策略对饿了么DAU的影响,那么用户所在地的降雨量可能是一个很好的协变量:既影响用户是否来访饿了么,也是个相对外生的变量不受用户自身主观因素的影响。对于淘宝的DAU场景,由于降雨量对用户是否来访淘宝影响可能很弱,降雨量不再是个很好的指标。如果有比较合适的协变量能够引入,则可既解决低响应实验的业务显著问题、也能解决统计显著问题。

▐ 倾向得分匹配简介
-
条件独立假设(Conditional Independence Assumption) 用数学公式可表述为: 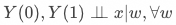
即给定协变量 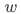 时,用户是否响应策略与潜在结果无关。该假设核心是保证匹配结果的同质性。
时,用户是否响应策略与潜在结果无关。该假设核心是保证匹配结果的同质性。
-
共同支撑假设(Common Support) 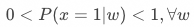
即给定变量
时,用户既可能响应策略也可能不响应策略。该条件保证了可以匹配到响应用户的对应用户
▐ 倾向得分匹配方案测试效果
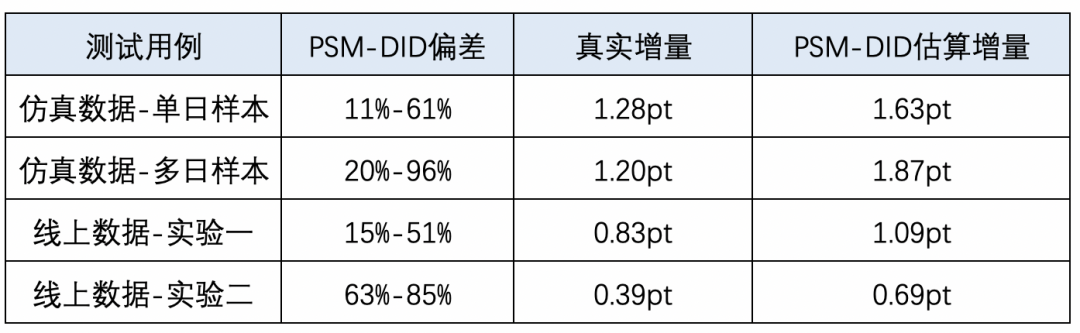
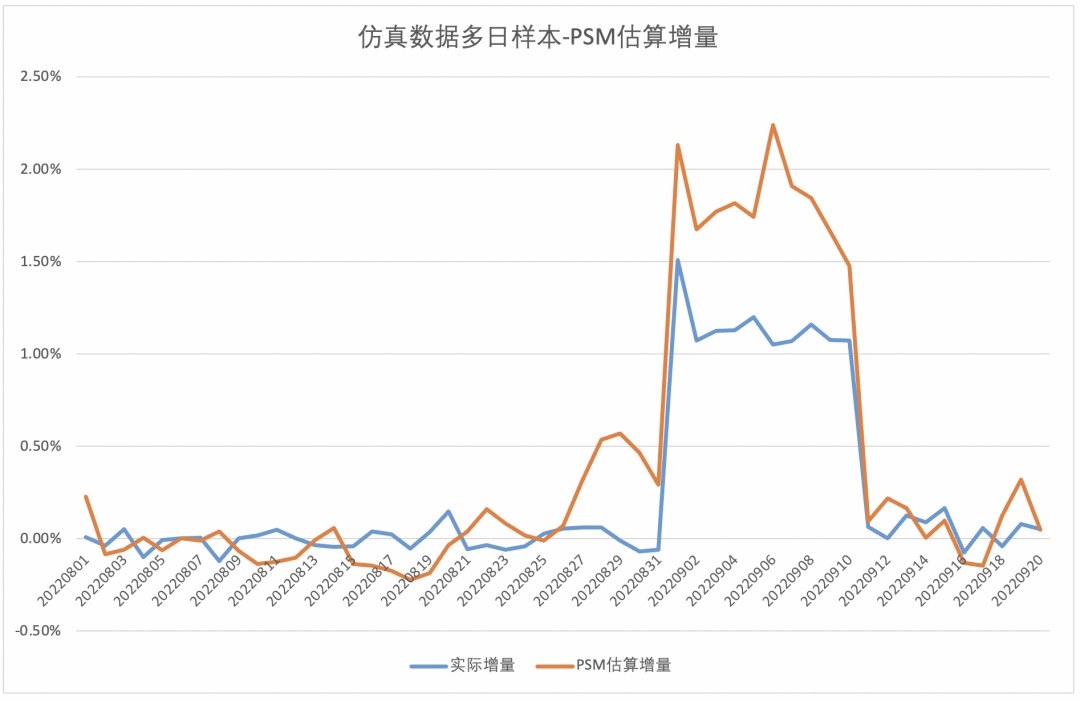
▐ 倾向得分匹配方案优化及效果
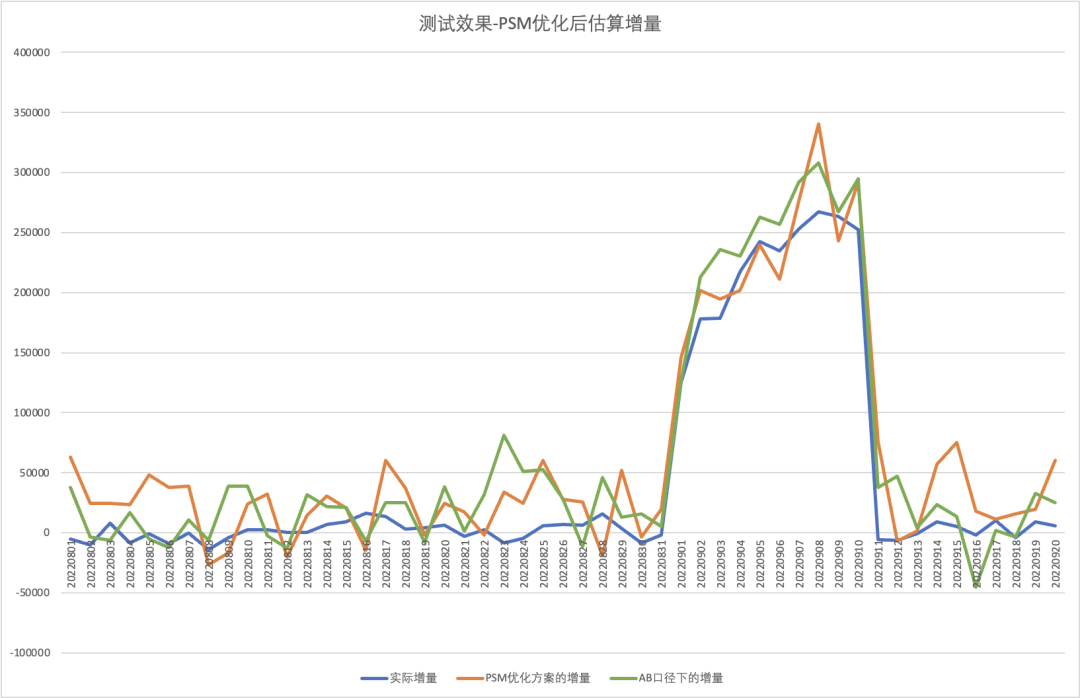
优化后的倾向得分匹配方案已经融入一休平台科学评估体系中,若有使用需要可以联系平台相关同学。

对于业务效果不显著问题,通过最基础的工具变量方法估计可以一定程度上解决;优化后的倾向得分匹配方案也能较好地解决但需要以一定的偏误为代价。
对于统计效果不显著问题,如果在工具变量应用中能够找到合适的协变量则能够有一定程度的解决;优化后的倾向得分匹配方案也能较好地解决,但仍以一定的偏误为代价。
响应程度的高低取决于我们认为策略从何时产生作用,不同的响应定义对应不同的增量含义;只有当漏斗能够通过一定策略、工程手段避免时,该漏斗才应该考虑通过数据手段修正以降低对实验评估产生影响。

大淘宝技术用户平台数据洞察团队,负责淘宝用户增长、私域、会员、互动业务的“人”“货”“场”的分析建模、运营策略洞察,为千万级 DAU 增量目标提供运营策略支持,为订阅、店铺等私域场景定义优质店铺标准和内容优选策略,科学衡量数亿“人店”关系的质量,同时参与 88VIP、省钱月卡、淘金币等会员和货币流通体系设计,以及淘宝互动游戏的潜客挖掘、分层运营、促活促购策略优化。团队目前有数据科学岗位杭州 hc,欢迎加入,一起为淘宝核心业务的增长做出贡献!简历投递邮箱:[email protected]。
本文分享自微信公众号 - 大淘宝技术(AlibabaMTT)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。