
推荐语:学习java和jdk的新特性并积极应用,以达到优化系统,降本提效的作用,这是我们作为java研发同学的第一节课。本文从“为什么”起手,谈到“怎么做”,最后用数据证明“怎么样”。细致入微,深入浅出,让我获益匪浅。
——大淘宝技术开发工程师 闻尘

升级收益:介绍应用升级获得的性能提升及成本收益,供大家参考。 升级指南:为大家实际动手升级时提供操作指南,避免重复踩坑。升级的主要流程和常见二方、三方依赖的升级 文章里基本都有提到。 新特性:简单介绍下 Java 9 - 19 的改进点和新增 API,主要介绍一些个人认为比较有用的新特性,看能否应用到实际开发。

▐ 性能提升
通过运行 SPECJbb2015 对比分析性能,整体而言 JDK11 优于 JDK8,G1 优于 CMS。在两个 JDK 版本默认状态下(JDK11 + G1 V.S JDK8 + CMS),JDK11 max-jOPS(纯吞吐量) 分数提升 17%,critical-jOPS(限制响应时间下的吞吐量) 分数提升 105%。
注:以上数据源自内部测试,非权威数据,仅供参考。
附:本应用升级效果及成本收益
应用升级 JDK 11 + G1 GC 后,单机性能在 极限 QPS、CPU、RT、GC 表现上均有提升,落到成本上可以进一步缩减机器上百台,每年可节省数十万成本。其中:
单机极限 QPS 提升 11% (1.8K -> 2.0K)
CPU 降低 2 pt(55% -> 53%)
RT 降低 5% (41ms -> 39ms)
日常水位 和 极限 QPS 下,GC 表现均有所提升
YGC 平均次数 和 平均暂停时长均降低 40-50%
极限 QPS 下 吞吐量提升4.6pt:93.99% -> 98.65%
▐ 持续跟进 Java 新版本

升级指南
▐ 升级准备
-
IntelliJ IDEA: 2018.2(地址:https://blog.jetbrains.com/idea/2018/06/java-11-in-intellij-idea-2018-2/) -
Eclipse: Photon 4.9RC2 with Java 11 plugin(地址:https://nipafx.dev/) -
Maven: 3.5.0 -
Gradle: 5.0 (地址:https://docs.gradle.org/5.0/release-notes.html#java-11-runtime-support)
▐ 基础环境升级
JDK 升级,可以根据自己应用的部署模式升级
Tomcat 升级
https://openjdk.org/install/
https://github.com/docker-library/openjdk/issues/272
https://tomcat.apache.org/whichversion.html
▐ 依赖升级
依赖检查
<dependency><groupId>javax.annotation</groupId><artifactId>javax.annotation-api</artifactId><version>1.3.2</version></dependency>
-
JDK11删除功能和选项-阿里云开发者社区(地址:https://developer.aliyun.com/article/652709) -
Java 9: Removed APIs, Features, and Options(地址:https://www.oracle.com/java/technologies/javase/9-removed-features.html)
Maven 升级
-
升级 maven 至推荐版本 3.5.0 (release) -
升级 maven-compiler-plugin 到 3.8.0 以上,同时指定编译的目标文件和源文件的编译版本
<plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.8.1</version><configuration><source>11</source><target>11</target></configuration></plugin>
Spring 升级
由于 Spring 4.x 最多只支持到 JDK 8,因此若要升级 JDK 11,建议同时升级 Spring 至 5.x 版本。
附 Spring 各版本支持的 JDK 版本范围
Spring Framework 6.0.x: JDK 17-21 (expected)
Spring Framework 5.3.x: JDK 8-19 (expected)
Spring Framework 5.2.x: JDK 8-15
Spring Framework 5.1.x: JDK 8-12
Spring Framework 5.0.x: JDK 8-10
Spring Framework 4.3.x: JDK 6-8
升级到 Spring 5.x 的注意点:Upgrading-to-Spring-Framework-5.x(地址:https://github.com/spring-projects/spring-framework/wiki/Upgrading-to-Spring-Framework-5.x)
废弃 ref local 标签
spring-beans-4.0.xsd ref/idref 标签不再支持 local 属性,需要替换为 bean 或指定低版本的 xsd(不推荐)
The local attribute on the ref/idref element is no longer supported in the 4.0 beans XSD, since it does not provide value over a regular bean reference any more. Change your existing ref local references to ref bean when upgrading to the 4.0 schema.
参考: 官方文档(地址:https://docs.spring.io/spring-framework/docs/current/reference/html/core.html#beans-ref-element)
Spring 5.2.0 无法扫描非 Runtime 的注解
问题:线上压测时发现 某个二方库的本地缓存失效,导致下游依赖 QPS 大幅上涨。
原因:Spring 5.2.x 只能找到 @Retention(RetentionPolicy.RUNTIME) 的自定义注解,应用依赖的二方库中有非 RUNTIME 的注解,因此与 5.2.x 及以上版本不兼容。导致依赖注解扫描加载的富客户端本地缓存代理类 无法被加载,缓存失效,才会导致大量请求打到远端服务。
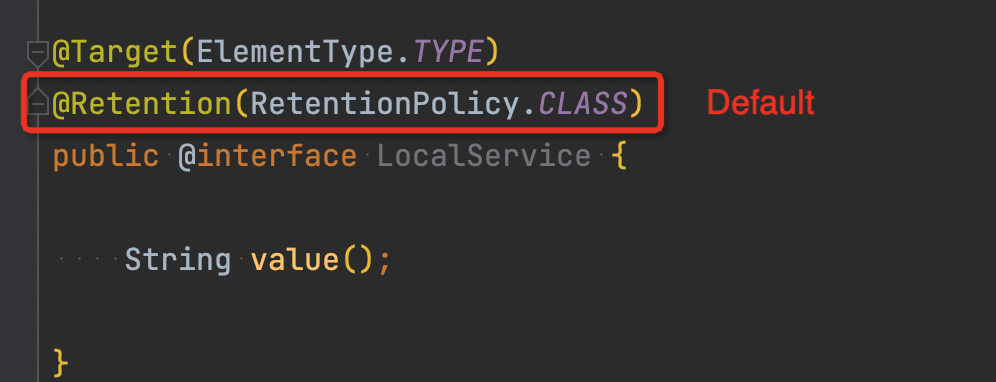
官方描述如下:
推进二方包升级
-
若 1 短期内无法升级,可临时将 Spring 回退到 5.1.0,兼容二方库中非 Runtime 的自定义注解。
Log4j 兼容/升级
Spring 4.2.1 起 废弃 Log4jConfigListener,支持Apache Log4j 2,官方表述如下:
Deprecated.as of Spring 4.2.1, in favor of Apache Log4j 2 (following Apache's EOL declaration for log4j 1.x)@Deprecatedpublic class Log4jConfigListenerextends java.lang.Objectimplements ServletContextListener
-
升级 Log4j2(推荐) -
手动使 Spring 5.x 兼容 Log4j 1.x,建议仅在依赖二方包无法平滑迁移 Log4j 2 情况下使用(不推荐)
升级 Log4j 2.x
-
Log4j 官方提供了 bridge 包进行平滑迁移,无需代码改动。但无法兼容编程配置方式、也无法支持访问 log4j 内部实现。 -
slf4j 版本 和 log4j-slf4j-impl 版本需要同步
-
log4j 2 不支持 Servlet 2.4 ref , 需要升级到 Servlet 3.0。
兼容 Log4j 1.x
若依赖的二方库使用 Log4j 1.x 导致应用无法通过官方适配包平滑迁移到 Log4j2,可以自行实现 Log4jConfigListener 初始化 log4j,使 Spring 5.x 兼容 Log4j1.x
验证日志是否正确输出时需要注意,相比于 Spring 4.x,Spring 5.x 部分日志级别有所调整。
Log4jConfigListener 实现参考:(见文末附录)
其他三方依赖
ASM : 7.0
Guice : 4.2
guava : 19.0
Lombok:1.18.x
Netty:需要升级到 4.1.33.Final或之后的版本,否则会引起堆外内存增长。
Apache Commons Lang3:3.9
注意:
任何操作字节码的依赖都需要关注是否需要升级,比如 ASM (7.0), Byte Buddy (1.9.0), cglib (3.2.8), or Javassist (3.23.1-GA)。
从 Java 9 开始,字节码级别每六个月增加一次,因此需要定期更新相关依赖,例如:任何使用在字节码上运行的东西,如 Spring (5.1)、Hibernate (unknown)、Mockito (2.20.0) 和许多其他项
▐ GC 升级
-
默认 GC 由 CMS 换成 G1 -
废弃了多种 GC 组合 和 GC 参数。 -
所有 GC 策略 GC log 打印出的文本格式发生了变化,和 JDK8 不兼容。
GC 参数
-
-Xloggc:<logfile> 改为-Xlog:gc:<logfile> -
JDK11 中不再支持 -XX:+PrintGCDetails,PrintGCDateStamps
GC 算法升级
G1 和 ZGC 的特点及适用场景见后文新特性中关于 GC 的介绍
配置调优参数
G1 配置和调优参数可参考:https://www.oracle.com/technical-resources/articles/java/g1gc.html
ZGC 配置参数
-XX:+UnlockExperimentalVMOptions-XX:+UseZGC
具体调优参数参考:https://docs.oracle.com/en/java/javase/11/gctuning/z-garbage-collector1.html#GUID-A5A42691-095E-47BA-B6DC-FB4E5FAA43D0
应用升级后单机 GC 性能压测表现
JDK 8 + CMS |
JDK 11 + G1 |
|
YGC 平均次数 |
7 次/min |
4 次/min(↓43%) |
YGC 平均时长 |
48ms |
25ms (↓48%) |
吞吐率 |
99.44% |
99.83% (↑0.40%) |
FGC |
0 |
0 |
极限 QPS (1.8K) 统计数据
JDK 8 + CMS |
JDK 11 + G1 |
|
YGC 平均次数 |
79 次/min |
36 次/min(↓54%) |
YGC 平均时长 |
45.3 ms |
22.3 ms(↓51%) |
吞吐率 |
93.99% |
98.65%(↑5%) |
FGC 总次数 (压测过程中) |
2 |
0 |
JDK 11 + ZGC 压测时,在 400 QPS 时 RT 和 CPU 开始不正常飙高,经分析 ZGC 由于不分代,适合老年代对象较少的场景,而本应用有大量常驻内存的对象,所以不适合使用 ZGC。
▐ 升级注意事项
-
注意观察下游依赖监控指标。 -
注意观察日志,包括但不限于:中间件、Spring 启动日志;业务日志;GC 日志(格式及内容);如果有升级 日志框架,还需要看文件名格式、内容时间格式、日志滚动等是否一致。 -
升级 G1 GC 后,JVM 进程大小会有所增加(Remembered Sets、Collection Sets 占用),需要注意应用内存变化。

新特性
▐ Java 9
模块化
-
更清晰的依赖关系和系统结构。 -
按需使用,提高性能和降低使用复杂度。 -
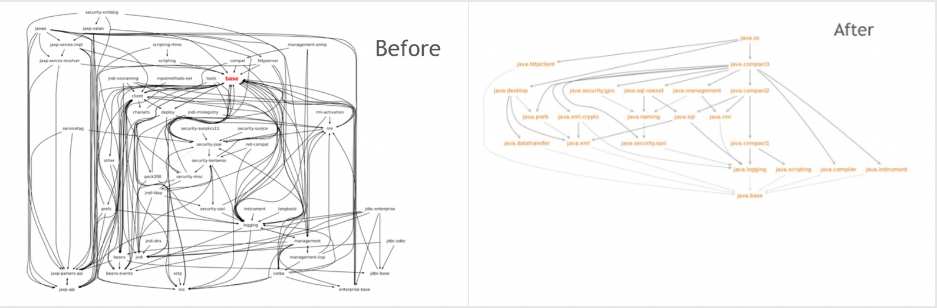
模块系统的一个关键动机是强封装(模块默认非公开),提高性能和安全性。
-
Maven 访问是单向的,而 Java 9 的模块化特性是双向协议。 模块默认非公开,因此需要显式 export 以被其他模块使用。使用某个模块时,也需要明确声明依赖该模块。 -
Maven 管理的是整个 Jar 的依赖,关注整体。而模块化管理的是 Jar 中的模块需要对外暴露的内容和对外依赖的模块,关注细节。Maven 的依赖是将整个 Jar 都给你了,哪怕你仅仅只需要其中的一个类。模块化的依赖则是更细粒度的管理,你只能使用你依赖的模块下被暴露出来的 package。
G1 成为默认垃圾收集器
-
Parallel GC:吞吐率高,GC 暂停时间长; -
G1 GC,CMS GC:吞吐率和 GC 暂停时间都比较好,G1 GC 是 Java11 的默认 GC(目标 GC 暂停时间为 200ms),而 CMS GC 在 Java11 中已经不推荐使用,并且会在 Java14 中正式废弃。 -
ZGC,Shenandaoh GC:GC 暂停时间短,吞吐率一般。
G1
-
开创面向局部收集、化整为零的设计思路和基于 Region 的内存布局形式。G1 将 Region 作为单次回收的最小单元,优先处理回收价值收益最大的 Region ,有计划地避免在整个 Java 堆中进行垃圾收集。 -
提供可预测的停顿时间模型,即软实时(soft real-time)。能够支持指定在一个长度为M毫秒的时间片段内,消耗在垃圾收集上的时间大概率不超过N毫秒这样的目标。 -
compacting 收集:由于都是以相等大小的分区为单位进行操作,因此 G1 天然适合压缩收集(局部压缩),通过将存活对象复制到另一个空闲分区中,消除潜在的碎片问题。适合短命对象多的场景。 -
JVM 进程变大:比起 CMS,G1 为了完成 GC 而额外占用的空间有所增加,主要包括:
-
大堆应用,实时对象占用了超过半数的堆空间; -
期望消除耗时较长的GC或停顿(超过 0.5 - 1 s)
ZGC
-
不分代,因此不适合常驻内存对象(老年代对象)较多的应用,本次升级的应用就属于此类情况。 -
主要通过并发转移降低暂停时间。并发转移通过 着色指针和读屏障 来保证转移过程中对象被应用线程访问的问题。 -
ZGC 的 GC 触发机制有很大不同。ZGC 的核心特点是并发,GC 过程中一直有新的对象产生。如何保证在 GC 完成之前,新产生的对象不会将堆占满,是ZGC参数调优的第一大目标,也是最大可能瓶颈。
-
对长尾请求 RT P99/P999 等指标有高要求的 Java 业务:这些业务通常要求 -
实时响应,对最慢的 1% 或 0.1% 的请求非常敏感; -
长寿对象相对较少:Java11 的 ZGC 尚未分代,无法高效地处理此类对象。 -
机器的内存与 CPU 资源丰富:丰富的计算资源可以开启更大的堆和更多的并发 GC 线程; -
可以容忍吞吐率降低:业务经过权衡后,认为 RT P99/P999 的指标比 QPS 指标更重要;
参考资料:
Getting Started with the G1 Garbage Collector(地址:https://www.oracle.com/technetwork/tutorials/tutorials-1876574.html)
不可变集合:List.of(), Set.of() And Map.of()
Set<String> set = new HashSet<>();set.add("a");set.add("b");set.add("c");set = Collections.unmodifiableSet(set);// 需要通过复制构造 HashSetList<String> stringList = Arrays.asList("a", "b", "c");Set<String> set = Collections.unmodifiableSet(new HashSet<String>(stringList));// 创建匿名内部类实例,可能导致内存泄漏Set<String> set = Collections.unmodifiableSet(new HashSet<String>() {{add("a"); add("b"); add("c");}});// StreamSet<String> set = Collections.unmodifiableSet(Stream.of("a", "b", "c").collect(toSet()));// GuavaList<String> strings = ImmutableList.of("a", "b", "c");
JDK 9 提供了不可变集合的工厂方法:
Set<String> set = Set.of("a", "b", "c");// 任意数量的元素List.of(E… elements)Set.of(E… elements)// 支持最多 10 对 k-v,超过 10 可以使用 ofEntriesMap.of(K k1, V v1, K k2, V v2, K k3, V v3, K k4, V v4, K k5, V v5, K k6, V v6, K k7, V v7, K k8, V v8, K k9, V v9, K k10, V v10)// 支持任意数量 entry(Guava 最多支持创建 5 个键值对的 Map)Map.ofEntries(entry(k1, v1), entry(k2, v2), entry(k3, v3), ..., entry(kn, vn));
-
「不可修改集合」 只是原始集合的只读视图。我们仍旧可以对原始集合执行修改操作,这些修改将反映返回的不可修改集合中。 -
Java 9 静态工厂方法返回的「不可变集合」是 100% 不可变的。
-
不允许修改 -
不允许空元素 -
线程安全 -
非常节省空间,比可变集合消耗更少的内存。
集合中有很多已知数据,且在整个执行过程中永远不会更改并且这些值被频繁检索,那么可以考虑使用 Java 9 不可变集合。在这种情况下,不可变集合比可变集合提供更好的性能。
Java 11 中也新增创建不可变或不可修改集合的方法:
方法 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
String 存储结构变更
Java 9 中 String 类通过 byte[] 存储字符串内容(之前是 char[]),原因是大多数 String 对象只包含 LATIN1 字符,此类字符只需要 1 字节的存储空间。
附 本应用升级前后 堆内存数据对比:
(GC 刚发生后的统计值) |
JDK 8 + CMS |
JDK 11 + G1 |
堆大小 |
4.08G |
3.83G(-256M, -6.13%) |
对象数量 |
106.6m |
106.8m |
String 数量 |
15,073,418 |
15,132,185 |
String Shallow Size |
345M |
346M |
String Retained Size |
>=1.26G |
>=961M(约 -329M) |
byte[] / char[] 数量 |
15,077,296 |
15,152,173 |
byte[] / char[] Shallow Size |
960M |
668M(约 -292M) |
byte[] / char[] Retained Size |
>=960M |
>=668M |
Try-Recourse
public static void main(String[] args) throws FileNotFoundException {FileOutputStream fos = new FileOutputStream("Resource.txt");//OR try(FileOutputStream fos = new FileOutputStream("Resource.txt"))try (FileOutputStream localFos = fos) {//Using the resources} catch (IOException e) {}//No need to close the resources explicitly.//Resources are implicitly closed.}
从 Java 9 开始,可以将外部声明的资源的引用直接传递给 try with resources 块。无需在 try 块中本地声明资源。但声明的资源引用必须是事实不可变。
public static void main(String[] args) throws FileNotFoundException {FileOutputStream fos = new FileOutputStream("Resource.txt");// No need to declare resources locally// Variable used as a try-with-resources resource should be final or effectively finaltry (fos) {//Using the resources} catch (IOException e) {}//No need to close the resources explicitly.//Resources are implicitly closed}
Stream API
Java 9 新增了一些 Stream API,如下:
方法 |
解释 |
takeWhile(Predicate<? super T> predicate) |
从流中的头开始取元素,直到不满足 Predicate 为止。 |
dropWhile(Predicate<? super T> predicate) |
从头开始删除满足条件的数据,直到遇见第一个不满足 Predicate 的位置,并保留剩余元素。 |
ofNullable(T t) |
ofNullable 允许创建 Stream 流时,只放入一个 null,返回的是一个空 Stream |
iterate(T seed, Predicate<? super T> hasNext, UnaryOperator<T> next) |
增加额外 Predicate 类型参数 hasNext 来决定何时终止操作。 |
Stream.iterate(1, i -> i <= 100000, i -> i*10).forEach(System.out::println); 接口支持私有方法
Java 8 中,接口支持 静态方法 和 default 方法。
Java 9 开始,接口支持 私有方法 和 私有静态方法,但仍旧不支持私有成员变量。
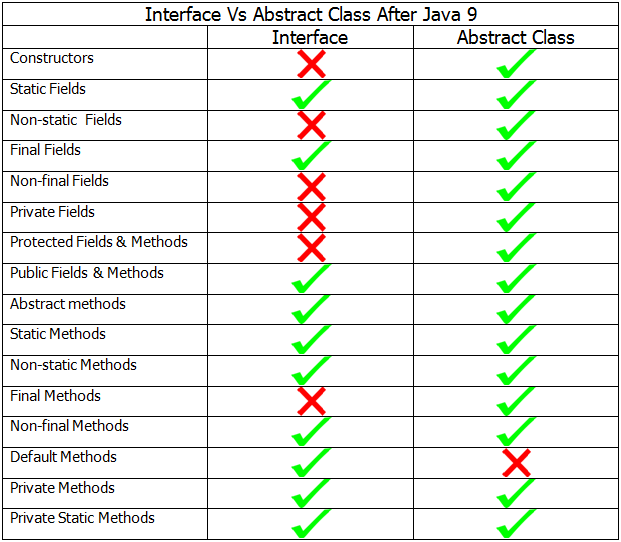
ref地址:https://javaconceptoftheday.com/java-9-interface-private-methods/
-
<> 支持匿名内部类
// Before Java 9:'<>' cannot be used with anonymous classesAddition<Integer> integerAddition = new Addition<Integer>() {@Overridevoid add(Integer t1, Integer t2) {System.out.println(t1+t2);}};// Java 9Addition<Integer> integerAddition = new Addition<>() {@Overridevoid add(Integer t1, Integer t2) {System.out.println(t1+t2);}};
Optional 改进
Optional 类新增 API 如下:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
其他
提升内置锁竞争性能
提高竞争 Java Monitor 的性能。
-
Field reordering and cache line alignment -
Speed up PlatformEvent::unpark() -
Fast Java monitor enter operations -
Fast Java monitor exit operations -
Fast Java monitor notify/notifyAll operations
HttpClient
HttpClient 在 Java 9 引入,Java 11 正式使用。替代仅适用于 bolocking 模式的 HTTPUrlConnection,并提供对 WebSocket 和 HTTP2 的支持。
▐ Java 10
局部变量类型推断
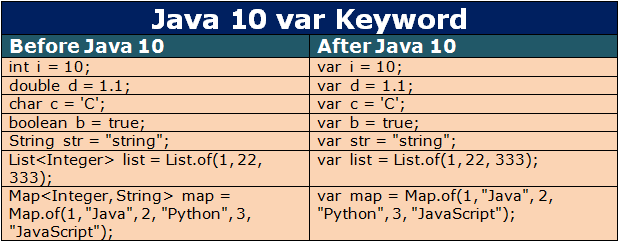
在 Java 10 可以使用 var 声明局部变量,省略变量具体类型,编译器可以根据变量初始化进行类型推断。
var 仅在显式初始化变量时有效。
var 仅适用于局部变量,不适用于全局变量。
var 不能用作方法参数和返回类型。
var 不适用于 lambda 表达式。
var 声明的变量必须始终为同一类型。
var 不能用于 null 。
// Java 10,参数不可以用注解修饰。(m, n) -> m * n;// Java 11,参数可以用注解修饰。( var m, var n) -> m * n;
▐ Java 11
String 新增方法
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
-
String.trim() 判断是否是空格的标准是 小于或等于 U+0020。 -
String.strip() 系列方法判断是否空格基于 Character.isWhiteSpace()。换句话说,它关注的是 Unicode whitespace 字符。

Predicate.not()
Before Java 11 |
After Java 11 |
version -> !version.isValid() |
Predicate.not(Version::isValid) |
▐ After Java 11
Java 15:Text Block
-
支持跨行字符串 -
避免常见转义的使用,如 "。 -
可自动格式化,支持自定义字符串格式、参数值替换等。
-
可直接使用 ",不需要转义 \" -
可直接换行,不需要 \n -
可以使用 String::format 、 String::replace 、 String::formatted 进行参数值替换 -
其他方法:
// before: 使用“一维”字符串String s = "function hello() {\n" +" print('\"Hello, world\"');\n" +"}\n" +"\n" +"hello();\n";// after: 使用“二维”文本块String s = """function hello() {print('"Hello, world"');}hello();""";// 3. 参数值替换示例String code = """public void print($type o) {System.out.println(Objects.toString(o));}""".replace("$type", type);String code = String.format("""public void print(%s o) {System.out.println(Objects.toString(o));}""", type);String source = """public void print(%s object) {System.out.println(Objects.toString(object));}""".formatted(type);
-
转换行终止符:Text Block 内容中的行终止符被统一转换为 LF (\u000A)。目的是在跨平台移动 Java 源代码时遵循最小意外原则。 -
重新缩进:Text Block 为匹配 Java 源代码的缩进而引入空白符将会被删除。 -
转义处理:解释 Text Block 内容中的转义序列。这意味着开发人员可以编写转义序列,例如 \n,而不会被前续步骤修改或删除。
-
删除所有行的公共空白前缀,开发人员可以通过结束"""的缩进来控制编译器的重新缩进。 -
删除所有行尾的空白符。
String html = """........ <html>........... <body>........... <p>Hello, world</p>........... </body>........... </html>...........""";// 重新缩进后| <html>|| <body>|| <p>Hello, world</p>|| </body>|| </html>|String html = """..............<html>................. <body>................. <p>Hello, world</p>................. </body>.................</html>................. """;// 重新缩进后|<html>|| <body>|| <p>Hello, world</p>|| </body>||</html>|
-
Text Block 支持字符串中支持的所有转义序列,包括 \n、\t、\'、\" 和 \\。可以访问通过 String::translateEscapes 转义处理,这是一个新的实例方法。 -
可以直接使用 " 、 "",但使用连续三个 """ 需要对其中一个转义,即 ""\""\"",以区分 Text Block 结束符。 -
新增两个转义字符:
// beforeString literal = "Lorem ipsum dolor sit amet, consectetur adipiscing " +"elit, sed do eiusmod tempor incididunt ut labore " +"et dolore magna aliqua.";// With the \<line-terminator> escape sequence this could be expressed as:String text = """Lorem ipsum dolor sit amet, consectetur adipiscing \elit, sed do eiusmod tempor incididunt ut labore \et dolore magna aliqua.\""";// Using \s at the end of each line guarantees each line is exactly six characters longString colors = """red \sgreen\sblue \s""";
Java 16:Record 定义值对象类型
record Point(int x, int y) { }// 被编译为record Point(int x, int y) {// Implicitly declared fieldsprivate final int x;private final int y;// Other implicit declarations elided ...// Implicitly declared canonical constructorPoint(int x, int y) {this.x = x;this.y = y;}}
JEP 395: Records地址:https://openjdk.org/jeps/395
Java 16:Pattern matching for instanceof
instanceof 运算符支持模式匹配
A pattern is a combination of (1) a predicate, or test, that can be applied to a target, and (2) a set of local variables, known as pattern variables, that are extracted from the target only if the predicate successfully applies to it.
// beforeif (obj instanceof String) {String s = (String) obj; // grr......}// afterif (obj instanceof String s) {// Let pattern matching do the work!...}// complex conditionif (obj instanceof String s && s.length() > 5) {flag = s.contains("jdk");}
JEP 394: Pattern Matching for instanceof地址:https://openjdk.org/jeps/394
Java 17 - 20:Pattern Matching for switch
-
支持模式匹配 -
case 支持 when 子句 -
case 支持匹配 null 和 常量
SwitchLabel:case CaseConstant { , CaseConstant }case null [, default]case Patterndefault
record Point(int i, int j) {}enum Color { RED, GREEN, BLUE; }static void typeTester(Object obj) {switch (obj) {// null 匹配case null -> System.out.println("null");// when 子句case String s when s.length() > 5 -> System.out.println("Long String");// 模式匹配case String s -> System.out.println("Short String");case Color c -> System.out.println("Color: " + c.toString());case Point p -> System.out.println("Record class: " + p.toString());case int[] ia -> System.out.println("Array of ints of length" + ia.length);default -> System.out.println("Something else");}}
Java 19:Virtual Thread
虚拟线程在 Java 19 中作为预览 API 被发布。旨在减少编写、维护和观测分析高吞吐量并发应用程序的工作量。
为什么需要虚拟线程?
Little Law 排队理论告诉我们:系统中的长期平均客户数量 L = 客户有效到达率 λ * 客户在系统中花费的时机 W,即 L = λW。因此,要想提高系统吞吐量:要么提高并发数,要么缩短处理时延。
Thread-per-request 传统风格
传统的 Java 线程与操作系统线程 1:1,而操作系统线程昂贵且有限,将应用程序的吞吐量限制在远低于硬件所能支持的水平。
即使将线程池化,也只能避免启动新线程的高成本,但不会增加线程总数。
反应式编程
开发者想要提高吞吐,就不得不实现更细粒度的线程共享。于是有了反应式编程。
必须采用新的编码风格,编写和理解成本高。(即将其请求处理逻辑分解为小阶段,通常编写为lambda 表达式)
异步程序在不同的线程中执行,难以追踪和调试。
虚拟线程
虚拟线程有助于在相同的硬件配置下实现与反应式编程相当的高可扩展性和吞吐量,而不会增加语法的复杂性。
保留 thread-per-request 风格,通过将大量虚拟线程映射到少量操作系统线程上,最佳化硬件利用率,实现高并发、高吞吐量、高可伸缩性。
使用 java.lang.Thread API 的现有代码能够以最小的更改采用虚拟线程,开发人员使用成本低。
使用虚拟线程 vs 平台线程
虚拟线程可以在以下场景下显着提高应用程序吞吐量
任务并发数高(几千以上):虚拟线程作为普通 Java 对象由 JVM 管理,因此我们可以在一个应用程序中创建数百万的虚拟线程,不受平台线程数量的限制。
工作负载不受 CPU 限制(非 CPU 密集型):虚拟线程只在 CPU 计算时占用平台线程,在等待或睡眠时不会阻塞操作系统线程。
try (var executor = Executors.newVirtualThreadPerTaskExecutor()) {IntStream.range(0, 10_000).forEach(i -> {executor.submit(() -> {Thread.sleep(Duration.ofSeconds(1));return i;});});} // executor.close() is called implicitly, and waits
Instant start = Instant.now();//使用虚拟线程的代码:try (var executor = Executors.newVirtualThreadPerTaskExecutor())try (var executor = Executors.newFixedThreadPool(100)) {IntStream.range(0, 10_000).forEach(i -> {executor.submit(() -> {Thread.sleep(Duration.ofSeconds(sleepSeconds));return i;});});}Instant finish = Instant.now();long timeElapsed = Duration.between(start, finish).toMillis();System.out.println("Total elapsed time : " + timeElapsed);
使用平台线程执行任务,程序可扩展性有限,无法通过提高并发数(线程数)来无限扩大吞吐量。 而虚拟线程几乎能够同时执行 10000 个任务。
(本机简单模拟测试,非权威数据) |
|||
|
|
|
|
|
|
|
||
1000 |
10497 |
||
2000 |
6035 |
||
3000 |
6338 |
||
4000 |
7324 |
||
5000 |
OOM |
||
100 |
1000555 |
||
1000 |
100502 |
||
2000 |
51018 |
||
3000 |
41127 |
||
4000 |
31172 |
||
5000 |
OOM |
||
(本机简单模拟测试,非权威数据) |
|
任务数量 |
虚拟线程执行时间(毫秒) |
10_000 |
1255 |
20_000 |
1319 |
40_000 |
1433 |
80_000 |
(2000, 4000) |
100_000 |
(3000, 6000) |
可以看到在同时开启 4 万个虚拟线程的情况下,耗时还是较为稳定的。由此看来,虚拟线程的性能还是很值得我们期待的。
最佳实践
不要池化虚拟线程,虚拟线程并不是昂贵资源,应该为每个应用程序任务创建一个新的虚拟线程。
尽量避免在虚拟线程中使用 ThreadLocal。由于虚拟线程可以创建数百万个,所以使用 ThreadLocal 要慎重。
使用 ReentrantLock 而不是同步块。执行同步块或本地方法时,虚拟线程会阻塞平台线程。
JEP 425: Virtual Threads (Preview)地址:https://openjdk.org/jeps/425

Log4jConfigListener 实现参考:
import java.io.FileNotFoundException;import java.net.URL;import javax.servlet.ServletContext;import javax.servlet.ServletContextEvent;import javax.servlet.ServletContextListener;import org.apache.log4j.LogManager;import org.apache.log4j.PropertyConfigurator;import org.apache.log4j.xml.DOMConfigurator;import org.springframework.util.ResourceUtils;import org.springframework.util.SystemPropertyUtils;import org.springframework.web.util.WebUtils;/*** copy from Spring 2.0.7, reserve necessary method and args.** Bootstrap listener for custom Log4J initialization in a web environment.* Delegates to Log4jWebConfigurer (see its javadoc for configuration details).** <b>WARNING: Assumes an expanded WAR file</b>, both for loading the configuration* file and for writing the log files. If you want to keep your WAR unexpanded or* don't need application-specific log files within the WAR directory, don't use* Log4J setup within the application (thus, don't use Log4jConfigListener or* Log4jConfigServlet). Instead, use a global, VM-wide Log4J setup (for example,* in JBoss) or JDK 1.4's <code>java.util.logging</code> (which is global too).** <p>This listener should be registered before ContextLoaderListener in web.xml,* when using custom Log4J initialization.** <p>For Servlet 2.2 containers and Servlet 2.3 ones that do not* initalize listeners before servlets, use Log4jConfigServlet.* See the ContextLoaderServlet javadoc for details.** @author Juergen Hoeller* @since 13.03.2003*/public class Log4jConfigListener implements ServletContextListener {/*** Parameter specifying the location of the Log4J config file*/public static final String CONFIG_LOCATION_PARAM = "log4jConfigLocation";/*** Extension that indicates a Log4J XML config file: ".xml"*/public static final String XML_FILE_EXTENSION = ".xml";public void contextInitialized(ServletContextEvent event) {initLogging(event.getServletContext());}public void contextDestroyed(ServletContextEvent event) {shutdownLogging(event.getServletContext());}/*** Initialize Log4J, including setting the web app root system property.** @param servletContext the current ServletContext* @see WebUtils#setWebAppRootSystemProperty*/public static void initLogging(ServletContext servletContext) {// Only perform custom Log4J initialization in case of a config file.String location = servletContext.getInitParameter(CONFIG_LOCATION_PARAM);if (location != null) {// Perform actual Log4J initialization; else rely on Log4J's default initialization.try {// Return a URL (e.g. "classpath:" or "file:") as-is;// consider a plain file path as relative to the web application root directory.if (!ResourceUtils.isUrl(location)) {// Resolve system property placeholders before resolving real path.location = SystemPropertyUtils.resolvePlaceholders(location);location = WebUtils.getRealPath(servletContext, location);}// Write log message to server log.servletContext.log("Initializing Log4J from [" + location + "]");// Initialize without refresh check, i.e. without Log4J's watchdog thread.initLogging(location);} catch (FileNotFoundException ex) {throw new IllegalArgumentException("Invalid 'log4jConfigLocation' parameter: " + ex.getMessage());}}}/*** Shut down Log4J, properly releasing all file locks* and resetting the web app root system property.** @param servletContext the current ServletContext*/public static void shutdownLogging(ServletContext servletContext) {servletContext.log("Shutting down Log4J");LogManager.shutdown();}/*** Initialize Log4J from the given file location, with no config file refreshing.* Assumes an XML file in case of a ".xml" file extension, and a properties file else.** @param location the location of the config file: either a "classpath:" location* (e.g. "classpath:myLog4j.properties"), an absolute file URL* (e.g. "file:C:/log4j.properties), or a plain absolute path in the file system* (e.g. "C:/log4j.properties")* @throws FileNotFoundException if the location specifies an invalid file path*/public static void initLogging(String location) throws FileNotFoundException {String resolvedLocation = SystemPropertyUtils.resolvePlaceholders(location);URL url = ResourceUtils.getURL(resolvedLocation);if (resolvedLocation.toLowerCase().endsWith(XML_FILE_EXTENSION)) {DOMConfigurator.configure(url);} else {PropertyConfigurator.configure(url);}}}

1. 业务高可用的解决方案与核心能力(应用高可用:为业务提供自适应限流、隔离与熔断的柔性高可用解决方案,站点高可用:故障自愈、多机房与异地容灾与快速切流恢复);
2. 新一代的业务研发模式FaaS(一站式函数研发Gaia平台);
3. 下一代网络协议QUIC实现与落地;
4. 移动中间件(API网关MTop、域名调度AMDC、消息/推送、文件上传AUS、移动配置推送Orange 等等)
简历投递至:泽彬 [email protected]
本文分享自微信公众号 - 大淘宝技术(AlibabaMTT)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。