作者 | Asimov_Liu
编辑 | 3D视觉开发者社区
文章目录
1 概述
为了让计算机更能理解人类行为,参与人类的生活,与人类交互,获取人体3D姿态和形状就显得尤为重要。目前3D人体重建的方法按照使用的方法不同可以归纳为2类:其一利用已有的人体数据模型,直接从单张RGB图片或视频中恢复人体三维模型(模型匹配);二是用深度传感器直接采集深度信息,再用拼接的方式构建完整模型(Fusion 方式)。下面回顾这两种方法的研究现状。
2 模型匹配的方法
直接从RGB图片或者视频中恢复3D模型的难点在于人体的复杂性,清晰度,遮挡,衣服,照明以及2D推断3D姿态的固有歧义性等。该方法不需要用特定的深度传感器,应用范围广,对环境要求低,但目前构建的模型精度不高,特别是手部,面部等细节特征缺失明显,目前大多数方法是基于目标函数的最优化迭代,故求解速度较慢, 很难做到实时重构。
2.1 SMPL(Skinned Multi-Person Linear model)模型
SMPL1模型是一种参数化的线性的3D人体建模方法,该方法可以进行任意的人体建模和动画驱动。这种方法可以模拟人的肌肉在肢体运动过程中的凸起和凹陷,因此可以避免人体在运动过程中的表面失真,可以精准的刻画人的肌肉拉伸以及收缩运动的形貌。
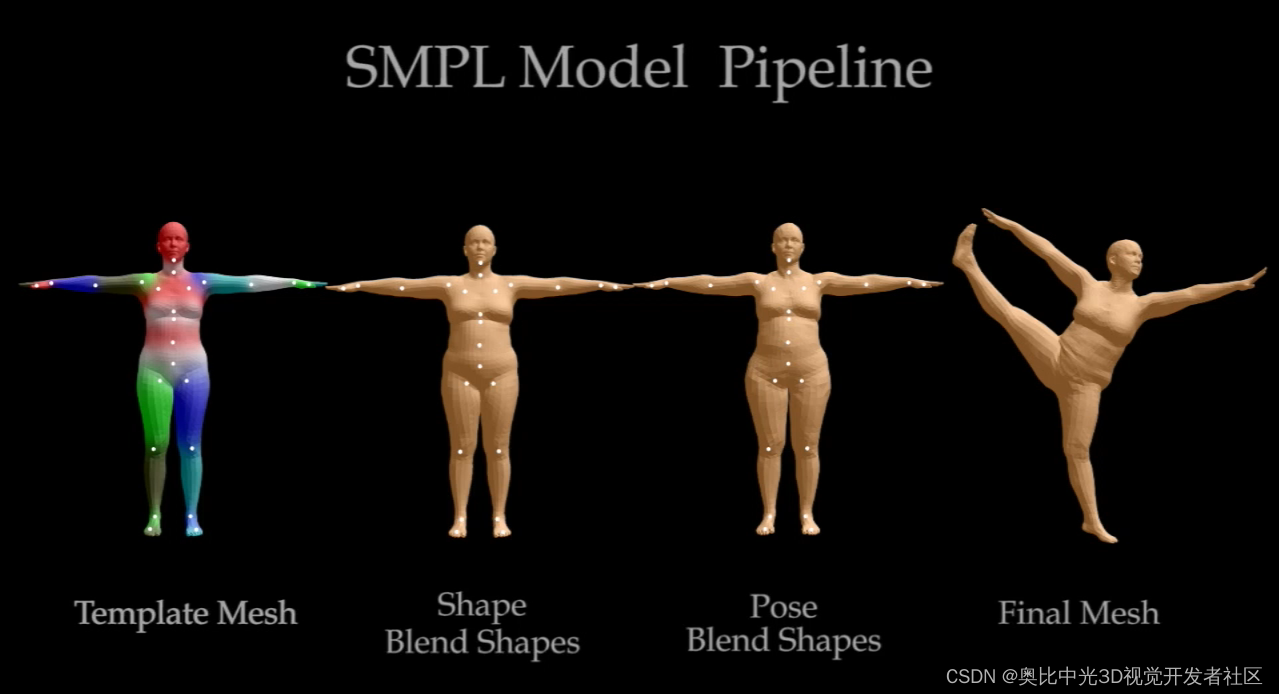
SMPL是通过已有的模型训练出的参数模型,模型参数包括,关节角参数θ(即人体整体运动位姿的24个关节的欧拉角,每个关节在空间中有Pitch,Roll,Yaw3个自由度,故共有75个参数)和形状参数β(人体的高矮胖瘦、头身比例等 10个参数),通过改变上述变量可以得到不同形状和姿态的3D人体模型, SMPL模型的表示形式如下:
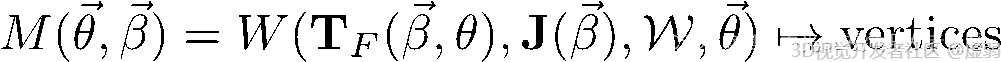
2.2 SMPLify
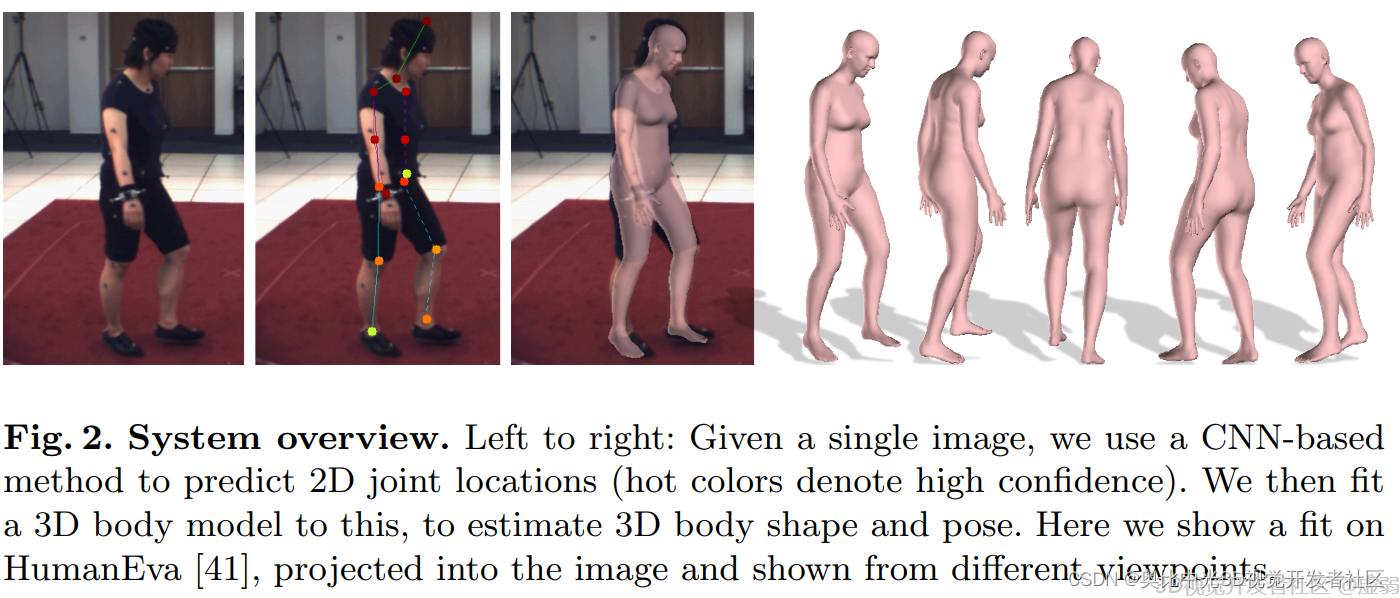
SMPLify 2 在 2016年 由 Bogo et al. 3提出,它能将一张 2D 人像转化为对应的 3D 模型,并在包含众多复杂姿势的 Leeds Sports Pose Dataset 中取得了不错的成绩,SMPLify中首先使用基于CNN的方法DeepCut[4]来预测(自下而上)2D身体关节位置。然后用 SMPL(自上而下)拟合到2D关节,是第一种从单个无约束图像自动估计人体3D姿态及其3D形状的方法。
我们可以从以下的效果图2中观察到,SMPLify 在处理 2D 人像转化为对应的 3D 模型的问题上有优秀的表现,同时,它的最大优点在于不需要进行手动特征标注即可获得很好的转换效果(尽管如此,手动进行性别标注可以获得更好的效果)。当然,由于实际场景的复杂性,SMPLift也会出现错误的情况:不同四肢的高度重叠、在缺少深度信息情况下不同人物的重叠、无法正确分辨人物朝向。

2.3 SMPL-X模型
G. Pavlakos*4 等提出的SMPL-X5模型是针对SMPL模型的优化,增加了面部表情,手势姿态,脚的姿态以及人的性别,改进了重建出人体的3D细节,更能反应人体真实的3D结构。


3 Fusion Method(实时扫描融合)
利用单/多个深度相机的实时扫描拼接算法也逐步成为主流的3D人体重建方法。其中具有代表性的有Kinect Fusion, Dynamic Fusion 以及最新的Body Fusion和Double Fusion等。
3.1 Kinect Fusion
Kinect Fusion6 是一种利用Kinect相机的深度数据进行实时三维重建的技术, 开创了Fusion 系列方法的先河,并提出利用GPU+TSDF方法实时场景重建。具体步骤如下:
1.深度数据处理:利用相机内参将深度图转换成3D点云,并计算每个点的法向量;
2.相机追踪:将当前帧3D点云和由现有模型生成的预测的3D点云进行ICP匹配,计算得到当前相机的位姿;
3.深度数据融合:根据所计算出的当前相机位姿,使用TSDF点云融合算法将当前帧的3D点云融合到现有模型中;
4.场景渲染:是使用光线跟踪的方法,根据现有模型和当前相机位姿预测出当前相机观察到的环境点云,一方面用于显示,另一方面提供给步骤2)进行ICP匹配。


Kinect Fusion利用GPU的高并行,首次实现了稠密的实时三维重建,效果是非常稳定和优秀的。但是也存在缺点:1)只能针对刚体做3D 重建;2)对显卡内存要求较高,重建空间的大小取决于显存的大小。此外,重建的质量与Voxel的大小也有关,Voxel 尺寸越大,重建的模型越粗糙,而Voxel 尺寸设置较小会导致计算量增加。后续Kintinuous7 基于Kinect Fusion,在重建空间范围,相机位姿估计以及回环检测等方面做了优化。
3.2 Dynamic Fusion
Dynamic Fusion8 是在Kinect Fusion 的基础上,增加了非刚体的变形估计。 解决了非刚体的实时动态重建。

3.3 Body Fusion & Double Fusion
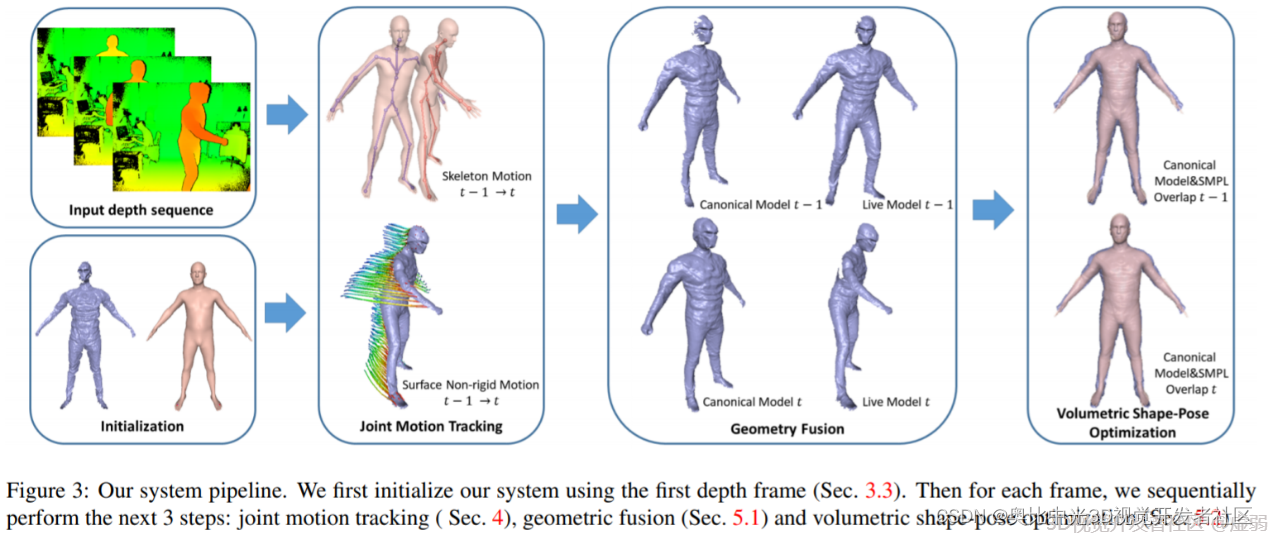
BodyFusion 9和Double Fusion 10均是由Tao Yu 等提出的利用单个深度相机实时捕捉人体运动和表面结构的方法。其中BodyFusion 提出了一种骨架嵌入式表面融合(SSF:skeleton-embedded surface fusion)的方法,基本上是在Dynamic Fusion 的基础上增加了人体骨骼的约束,基于骨架和图形节点之间的附带信息来共同解决骨骼和图形节点的形变问题。但是在快速运动以及初始人体姿态(骨骼)估计错误的情况下,该重构方法会失效。

DoubleFusion基于SMPL提出了“双层表面表示”模型对人体进行实时的3D重建,内层(inner body layer)是依据观测到的关节点和人体形状推测的SMPL模型,而外层(outer surface)则是利用深度信息融合出的人体表面,他们相互制约,相互融合和优化,最终生成完整的人体模型。当然Double Fusion还是存在局限,例如,当用户穿着较厚的衣服时,这个方案在捕捉过程中会将衣服的厚度都当成人的身体来计算,导致身体建模的误差出现;另外,目前的方案还无法处理人物对象之间的交互。
4 参考文献
http://smpl.is.tue.mpg.de/. ↩︎
http://smplify.is.tue.mpg.de/. ↩︎
Bogo F, Kanazawa A, Lassner C, et al. Keep it SMPL: Automatic estimation of 3D human pose and shape from a single image[C]//European Conference on Computer Vision. Springer, Cham, 2016: 561-578. ↩︎
Pavlakos G, Choutas V, Ghorbani N, et al. Expressive body capture: 3d hands, face, and body from a single image[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019: 10975-10985. ↩︎
https://smpl-x.is.tue.mpg.de/. ↩︎
Newcombe R A, Izadi S, Hilliges O, et al. Kinectfusion: Real-time dense surface mapping and tracking[C]//ISMAR. 2011, 11(2011): 127-136. ↩︎
Whelan T, Kaess M, Fallon M, et al. Kintinuous: Spatially extended kinectfusion[J]. 2012. ↩︎
Newcombe R A, Fox D, Seitz S M. Dynamicfusion: Reconstruction and tracking of non-rigid scenes in real-time[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2015: 343-352. ↩︎
Yu T, Guo K, Xu F, et al. Bodyfusion: Real-time capture of human motion and surface geometry using a single depth camera[C]//Proceedings of the IEEE International Conference on Computer Vision. 2017: 910-919. ↩︎
Yu T, Zheng Z, Guo K, et al. Doublefusion: Real-time capture of human performances with inner body shapes from a single depth sensor[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 7287-7296. ↩︎
版权声明:本文为作者授权转载,由3D视觉开发者社区编辑整理发布,仅做学术分享,未经授权请勿二次传播,版权归原作者所有。
3D视觉开发者社区是由奥比中光给所有开发者打造的分享与交流平台,旨在将3D视觉技术开放给开发者。平台为开发者提供3D视觉领域免费课程、奥比中光独家资源与专业技术支持。
点击加入3D视觉开发者社区,和开发者们一起讨论分享吧~
也可移步微信关注官方公众号 3D视觉开发者社区 ,获取更多干货知识哦!