文章目录
一、transformer模型
transformer模型一直在NLP和CV领域中很经典。
注意力机制:为了解决seq2seq模型记忆长序列能力不足,当要生成一个目标语言单词时,既要考虑前一个时刻和已经生成的单词,还需要考虑要生成的单词和源语言句子中哪个单词更加相关。

1.1 模型原理
(一)简单回顾transformer模型:
2017 年,Google 提出了 Transformer 模型,用 Self Attention 的结构,取代了以往 NLP 任务中的 RNN 网络结构,在 WMT 2014 Englishto-German 和 WMT 2014 English-to-French两个机器翻译任务上都取得了当时 SOTA 的效果。
(1)在 RNN 中,每一个 time step 的计算都依赖于上一个 time step 的输出,这就使得所有的 time step 必须串行化,无法并行计算,如下图所示。
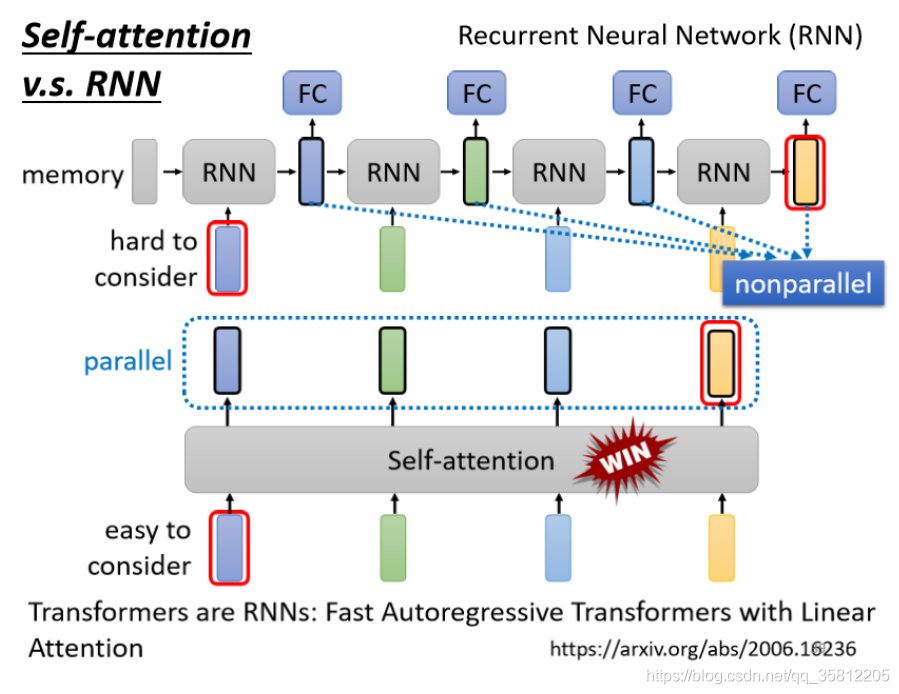
(2)transformer模型的其中一个优点,就是使得模型训练过程能够并行计算。在Transformer 中,所有 time step 的数据,都是经过 Self Attention 计算,使得整个运算过程可以并行化计算。
1.2 回顾几个经典问题
(1)为什么Transformer中加入了positional embedding?
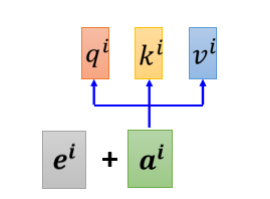
答:初始的self-attention的这个layer的每一个input,对于sequence中的最前还是最后的东东,缺少了重要的位置信息。如在做磁性标记POS tagging时,动词很少出现在句首,所哟某一个词汇如果放在句首的话,那么它是动词的可能性很低。所以在一开始paper《Attention Is All You Need》中将位置的信息塞进去(如下图所示),每一个位置设定一个 vector(positional vector,用 e i e^i ei 来表示),上标 i 代表是位置,每一个不同的位置。
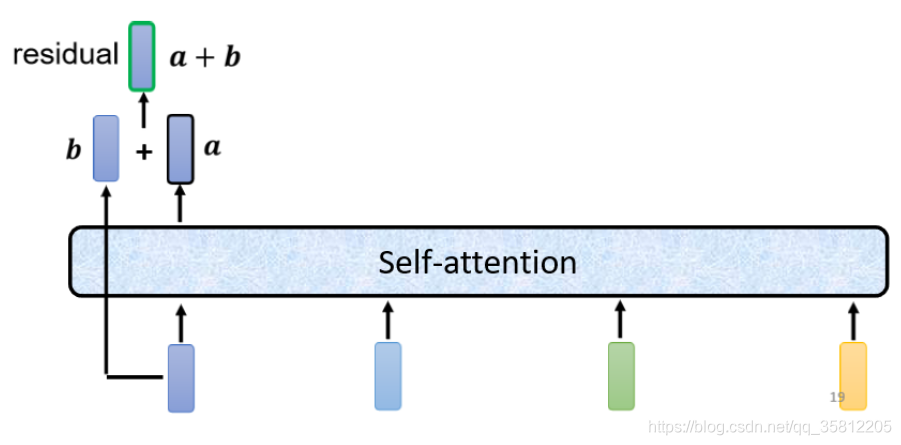
(2)Transformer中的残差网络结构(residual connecttion)作用是什么?
答:在transformer里面加了了一个设计——不只是输出这个vector,还要把这个vector加上它的input得到新的ouput。BN其实已经解决了梯度消失问题,resnet残差链接更多解决的是深层网络训练时候退化的问题,更多参考https://zhuanlan.zhihu.com/p/268308900。
(3)Transformer中的softmax计算为什么需要除以 d k d_k dk?
答:如果我们计算句子中第一个位置单词的 Attention Score(注意力分数),那么第一个分数就是 q1 和 k1 的内积,第二个分数就是 q1 和 k2 的点积。以此类推。而每个Attention Score(注意力分数)除以 ( d k e y ) \sqrt(d_{key}) (dkey) ( d k e y d_{key} dkey是 Key 向量的长度),当然也可以除以其他数,除以一个数是为了在反向传播时,求取梯度更加稳定( ps:在车万翔老师的书《自然语言处理》中说的是:避免因为向量维度d过大导致点积结果过大)。
(4)为什么 num_heads 的值需要能够被 embed_dim 整除:
这是为了把词的隐向量长度平分到每一组,这样多组注意力也能够放到一个矩阵里,从而并行计算多头注意力。例如,8 组注意力可以得到 8 组 Z 矩阵,然后把这些矩阵拼接起来,得到最终的输出。如果最终输出的每个词的向量维度是 512,那么每组注意力的向量维度应该是512 ÷8=64。如果不能够整除,那么这些向量的长度就无法平均分配。
二、代码部分
2.1 数据处理部分
NLTK提供了多种语料库(Corpora)和词典(Lexicon)资源,如WordNet等,以及常用工具集,如分句、标记解析(Tokenization)、词干提取(Stemming)、词性标注(POS Taggin)和句法分析(Syntactic Parsing)等,用于英文文本数据处理。
函数load_sentence_polarity中用到NLTK中的句子倾向性分析数据加载训练数据和测试数据,并且返回Vocab词表。在ML或者DL中的NLP中,一开始都需要将输入的语言符号(Token标记)映射为该标记的索引值or下标(即一个大于等于0、小于词表大小的整数)
import math
import torch
from torch import nn, optim
from torch.nn import functional as F
from torch.utils.data import Dataset, DataLoader
from torch.nn.utils.rnn import pad_sequence, pack_padded_sequence
from collections import defaultdict
from vocab import Vocab
from utils import load_sentence_polarity, length_to_mask
# tqdm是一个Pyth模块,能以进度条的方式显式迭代的进度
from tqdm.auto import tqdm
class TransformerDataset(Dataset):
def __init__(self, data):
self.data = data
def __len__(self):
return len(self.data)
def __getitem__(self, i):
return self.data[i]
Dataloader中几个参数:batch_size:mini-batch的大小shuffle:是否对数据进行随机采样dataset:这里即我们定义好的TransformerDataset类的一个数据集对象,用于存储数据(一般需要根据具体的数据存取需求创建Dataset类的子类,比如这里的TransformerDataset类)collate_fn:指向一个函数,用户对一个批次的样本进行整理,如可以将其转为张量等。
def collate_fn(examples):
lengths = torch.tensor([len(ex[0]) for ex in examples])
inputs = [torch.tensor(ex[0]) for ex in examples]
targets = torch.tensor([ex[1] for ex in examples], dtype=torch.long)
# 对batch内的样本进行padding,使其具有相同长度
inputs = pad_sequence(inputs, batch_first=True)
return inputs, lengths, targets
位置编码类:
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout=0.1, max_len=512):
super(PositionalEncoding, self).__init__()
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
# sin and cos position encoding
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0).transpose(0, 1)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + self.pe[:x.size(0), :]
return x
2.2 Transformer类
下面的模型Transformer类是关键:
(1)transformer类中length_to_mask函数:根据批次中每个序列长度生成mask矩阵,以便处理长度不一致的序列,忽略掉比较短的序列的无效部分(是TransformerEncoder中调用函数所需的src_key_padding_mask参数)。
(2)位置编码用上面的类,也可以用position embedding,直接调用nn.Embedding。
(3)nlp中每个batch中每个句子一般都是不等长的,先通过填充0的方式,将每个batch中每句话padding成相同长度形式;在模型中或者计算loss时就padding成0的部分mask掉。
class Transformer(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim, num_class,
dim_feedforward=512, num_head=2, num_layers=2, dropout=0.1, max_len=128, activation: str = "relu"):
super(Transformer, self).__init__()
# 词嵌入层
self.embedding_dim = embedding_dim
self.embeddings = nn.Embedding(vocab_size, embedding_dim)
self.position_embedding = PositionalEncoding(embedding_dim, dropout, max_len)
# 编码层:使用Transformer
encoder_layer = nn.TransformerEncoderLayer(hidden_dim, num_head, dim_feedforward, dropout, activation)
self.transformer = nn.TransformerEncoder(encoder_layer, num_layers)
# 输出层
self.output = nn.Linear(hidden_dim, num_class)
def forward(self, inputs, lengths):
inputs = torch.transpose(inputs, 0, 1)
# 与LSTM一样,输入数据的第1维是批次,需要转换为TransformerEncoder
# 所需要的第1维是长度,第2维是批次的形状
hidden_states = self.embeddings(inputs)
hidden_states = self.position_embedding(hidden_states)
attention_mask = length_to_mask(lengths) == False
# 根据批次batch中每个序列长度生成mask矩阵
hidden_states = self.transformer(hidden_states, src_key_padding_mask=attention_mask)
hidden_states = hidden_states[0, :, :]
# 取第一个标记的输出结果作为分类层的输入
output = self.output(hidden_states)
log_probs = F.log_softmax(output, dim=1)
return log_probs
2.3 训练和测试部分
训练和测试就没啥好说的了,还有一些参数的设定和调整。
embedding_dim = 128
hidden_dim = 128
num_class = 2
batch_size = 32
num_epoch = 5
# 加载数据
train_data, test_data, vocab = load_sentence_polarity()
train_dataset = TransformerDataset(train_data)
test_dataset = TransformerDataset(test_data)
train_data_loader = DataLoader(train_dataset, batch_size=batch_size, collate_fn=collate_fn, shuffle=True)
test_data_loader = DataLoader(test_dataset, batch_size=1, collate_fn=collate_fn, shuffle=False)
# 加载模型
# device = torch.device('cpu')
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
model = Transformer(len(vocab), embedding_dim, hidden_dim, num_class)
model.to(device) # 将模型加载到GPU中(如果已经正确安装)
# 训练过程
nll_loss = nn.NLLLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001) # 使用Adam优化器
model.train()
for epoch in range(num_epoch):
total_loss = 0
for batch in tqdm(train_data_loader, desc=f"Training Epoch {
epoch}"):
inputs, lengths, targets = [x.to(device) for x in batch]
log_probs = model(inputs, lengths)
loss = nll_loss(log_probs, targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
print(f"Loss: {
total_loss:.2f}")
# 测试过程
acc = 0
for batch in tqdm(test_data_loader, desc=f"Testing"):
inputs, lengths, targets = [x.to(device) for x in batch]
with torch.no_grad():
output = model(inputs, lengths)
acc += (output.argmax(dim=1) == targets).sum().item()
# 输出在测试集上的准确率
print(f"Acc: {
acc / len(test_data_loader):.2f}")
三、关于NLP中的mask
1、padding mask:处理非定长序列,区分padding和非padding部分,如在RNN等模型和Attention机制中的应用等
2、sequence mask:防止标签泄露,如:Transformer decoder中的mask矩阵,BERT中的[Mask]位,XLNet中的mask矩阵等
3. 1 RNN中的Mask
对于RNN等模型,本身是可以直接处理不定长数据的,因此它不需要提前告知 sequence length,如下是pytorch下的LSTM定义:
nn.LSTM(input_size, hidden_size, *args, **kwargs)
但是在实践中,为了 batch 训练,一般会把不定长的序列 padding 到相同长度,再用 mask 去区分非 padding 部分和 padding 部分。
区分的目的是使得RNN只作用到它实际长度的句子,而不会处理无用的 padding 部分,这样RNN的输出和隐状态都会是对应句子实际的最后一位。另外,对于token级别的任务,也可以通过mask去忽略 padding 部分对应的loss。
在 pytorch 中,对 mask 的具体实现形式不是mask矩阵,而是通过一个句子长度列表来实现的,但本质一样。实现如下,sentence_lens 表示的是这个batch中每一个句子的实际长度。
3.2 Attention中Mask
在 Attention 机制中,同样需要忽略 padding 部分的影响,这里以transformer encoder中的self-attention为例:
3.3 防止标签泄露
在语言模型中,常常需要从上一个词预测下一个词,但如果要在LM中应用 self attention 或者是同时使用上下文的信息,要想不泄露要预测的标签信息,就需要 mask 来“遮盖”它。不同的mask方式,也对应了一篇篇的paper,这里选取典型的几个。
3.4 Transformer中的Mask
Transformer 是包括 Encoder和 Decoder的,Encoder中 self-attention 的 padding mask 如上,而 Decoder 还需要防止标签泄露,即在 t 时刻不能看到 t 时刻之后的信息,因此在上述 padding mask的基础上,还要加上 sequence mask。
sequence mask 一般是通过生成一个上三角矩阵来实现的,上三角区域对应要mask的部分。
在Transformer 的 Decoder中,先不考虑 padding mask,一个包括四个词的句子[A,B,C,D]在计算了相似度scores之后,得到下面第一幅图,将scores的上三角区域mask掉,即替换为负无穷,再做softmax得到第三幅图。这样,比如输入 B 在self-attention之后,也只和A,B有关,而与后序信息无关。
self-attention中,Q和K在点积之后,需要先经过mask再进行softmax,因此,对于要屏蔽的部分,mask之后的输出需要为负无穷,这样softmax之后输出才为0。
四、使用Huggingface进行阅读理解任务训练(BERT)
4.1 SSC单句文本分类
这里我们用huggingface中bert进行单句文本分类(情感分类),模型由输入层、BERT编码层和分类输出层构成。
import numpy as np
from datasets import load_dataset, load_metric
from transformers import BertTokenizerFast, BertForSequenceClassification, TrainingArguments, Trainer
# 加载训练数据、分词器、预训练模型以及评价方法
dataset = load_dataset('glue', 'sst2')
tokenizer = BertTokenizerFast.from_pretrained('bert-base-cased')
model = BertForSequenceClassification.from_pretrained('bert-base-cased', return_dict=True)
metric = load_metric('glue', 'sst2')
# 对训练集进行分词
def tokenize(examples):
return tokenizer(examples['sentence'], truncation=True, padding='max_length')
dataset = dataset.map(tokenize, batched=True)
encoded_dataset = dataset.map(lambda examples: {
'labels': examples['label']}, batched=True)
# 将数据集格式化为torch.Tensor类型以训练PyTorch模型
columns = ['input_ids', 'token_type_ids', 'attention_mask', 'labels']
encoded_dataset.set_format(type='torch', columns=columns)
# 定义评价指标
def compute_metrics(eval_pred):
predictions, labels = eval_pred
return metric.compute(predictions=np.argmax(predictions, axis=1), references=labels)
# 定义训练参数TrainingArguments,默认使用AdamW优化器
args = TrainingArguments(
"ft-sst2", # 输出路径,存放检查点和其他输出文件
evaluation_strategy="epoch", # 定义每轮结束后进行评价
learning_rate=2e-5, # 定义初始学习率
per_device_train_batch_size=16, # 定义训练批次大小
per_device_eval_batch_size=16, # 定义测试批次大小
num_train_epochs=2, # 定义训练轮数
)
# 定义Trainer,指定模型和训练参数,输入训练集、验证集、分词器以及评价函数
trainer = Trainer(
model,
args,
train_dataset=encoded_dataset["train"],
eval_dataset=encoded_dataset["validation"],
tokenizer=tokenizer,
compute_metrics=compute_metrics
)
# 开始训练!
trainer.train()
在3090 GPU上训练2个epoch的结果:
{
'eval_loss': 0.9953321218490601, 'eval_runtime': 69.7044, 'eval_samples_per_second': 155.256, 'eval_steps_per_second': 9.712, 'epoch': 2.0}
100%|███████████████████████████████████| 11092/11092 [1:02:06<00:00, 3.57it/s]
100%|█████████████████████████████████████████| 677/677 [01:09<00:00, 9.63it/s]
Training completed. Do not forget to share your model on huggingface.co/models =)
{
'train_runtime': 3726.2181, 'train_samples_per_second': 47.624, 'train_steps_per_second': 2.977, 'train_loss': 1.024809235147393, 'epoch': 2.0}
100%|███████████████████████████████████| 11092/11092 [1:02:06<00:00, 2.98it/s]
4.2 SRC抽取式阅读理解
(1)SRC任务即抽取式阅读理解(Span-extraction Reading comprehension),这里我们使用BERT做阅读理解任务,SRC由篇章、问题和答案构成,即训练后的机器需要根据题目,从篇章中抽取出“答案”,即一个文本片段,即篇章passage中的一个起始位置和终止位置。
(2)SQuAD的解码过程较为复杂,因为涉及答案位置对齐、N-bert列表计算等操作。
import numpy as np
from datasets import load_dataset, load_metric
from transformers import BertTokenizerFast, BertForQuestionAnswering, TrainingArguments, Trainer, default_data_collator
# 加载训练数据、分词器、预训练模型以及评价方法
dataset = load_dataset('squad')
tokenizer = BertTokenizerFast.from_pretrained('bert-base-cased')
model = BertForQuestionAnswering.from_pretrained('bert-base-cased', return_dict=True)
metric = load_metric('squad')
# 准备训练数据并转换为feature
def prepare_train_features(examples):
tokenized_examples = tokenizer(
examples["question"], # 问题文本
examples["context"], # 篇章文本
truncation="only_second", # 截断只发生在第二部分,即篇章
max_length=384, # 设定最大长度为384
stride=128, # 设定篇章切片步长为128
return_overflowing_tokens=True, # 返回超出最大长度的标记,将篇章切成多片
return_offsets_mapping=True, # 返回偏置信息,用于对齐答案位置
padding="max_length", # 按最大长度进行补齐
)
# 如果篇章很长,则可能会被切成多个小篇章,需要通过以下函数建立feature到example的映射关系
sample_mapping = tokenized_examples.pop("overflow_to_sample_mapping")
# 建立token到原文的字符级映射关系,用于确定答案的开始和结束位置
offset_mapping = tokenized_examples.pop("offset_mapping")
# 获取开始和结束位置
tokenized_examples["start_positions"] = []
tokenized_examples["end_positions"] = []
for i, offsets in enumerate(offset_mapping):
# 获取输入序列的input_ids以及[CLS]标记的位置(在BERT中为第0位)
input_ids = tokenized_examples["input_ids"][i]
cls_index = input_ids.index(tokenizer.cls_token_id)
# 获取哪些部分是问题,哪些部分是篇章
sequence_ids = tokenized_examples.sequence_ids(i)
# 获取答案在文本中的字符级开始和结束位置
sample_index = sample_mapping[i]
answers = examples["answers"][sample_index]
start_char = answers["answer_start"][0]
end_char = start_char + len(answers["text"][0])
# 获取在当前切片中的开始和结束位置
token_start_index = 0
while sequence_ids[token_start_index] != 1:
token_start_index += 1
token_end_index = len(input_ids) - 1
while sequence_ids[token_end_index] != 1:
token_end_index -= 1
# 检测答案是否超出当前切片的范围
if not (offsets[token_start_index][0] <= start_char and offsets[token_end_index][1] >= end_char):
# 超出范围时,答案的开始和结束位置均设置为[CLS]标记的位置
tokenized_examples["start_positions"].append(cls_index)
tokenized_examples["end_positions"].append(cls_index)
else:
# 将token_start_index和token_end_index移至答案的两端
while token_start_index < len(offsets) and offsets[token_start_index][0] <= start_char:
token_start_index += 1
tokenized_examples["start_positions"].append(token_start_index - 1)
while offsets[token_end_index][1] >= end_char:
token_end_index -= 1
tokenized_examples["end_positions"].append(token_end_index + 1)
return tokenized_examples
# 通过函数prepare_train_features,建立分词后的训练集
tokenized_datasets = dataset.map(prepare_train_features, batched=True, remove_columns=dataset["train"].column_names)
# 定义训练参数TrainingArguments,默认使用AdamW优化器
args = TrainingArguments(
"ft-squad", # 输出路径,存放检查点和其他输出文件
evaluation_strategy="epoch", # 定义每轮结束后进行评价
learning_rate=2e-5, # 定义初始学习率
per_device_train_batch_size=16, # 定义训练批次大小
per_device_eval_batch_size=16, # 定义测试批次大小
num_train_epochs=2, # 定义训练轮数
)
# 定义Trainer,指定模型和训练参数,输入训练集、验证集、分词器以及评价函数
trainer = Trainer(
model,
args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
data_collator=default_data_collator,
tokenizer=tokenizer,
)
# 开始训练!(主流GPU上耗时约几小时)
trainer.train()
五、transformer完整Pytorch版
基于pytorch来实现一个Transformer
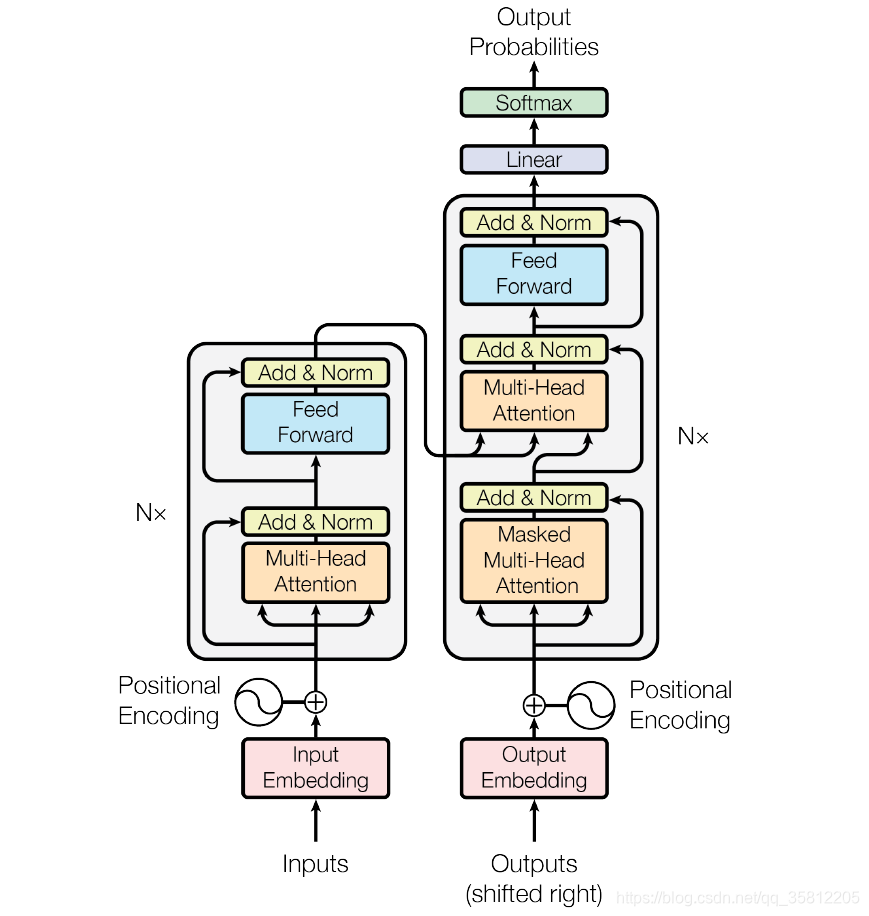
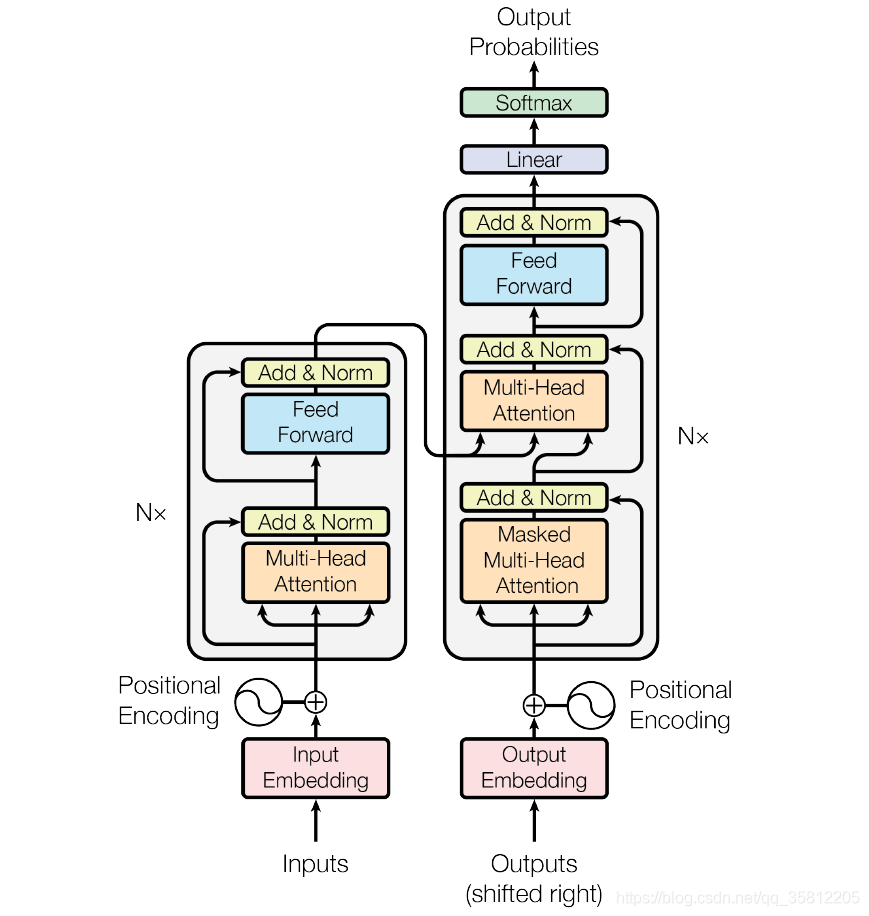
图:Transformer结构图
一、词嵌入
如上图所示,Transformer图里左边的是Encoder,右边是Decoder部分。Encoder输入源语言序列,Decoder里面输入需要被翻译的语言文本(在训练时)。一个文本常有许多序列组成,常见操作为将序列进行一些预处理(如词切分等)变成列表,一个序列的列表的元素通常为词表中不可切分的最小词,整个文本就是一个大列表,元素为一个一个由序列组成的列表。如一个序列经过切分后变为[“am”, “##ro”, “##zi”, “meets”, “his”, “father”],接下来按照它们在词表中对应的索引进行转换,假设结果如[23, 94, 13, 41, 27, 96]。假如整个文本一共100个句子,那么就有100个列表为它的元素,因为每个序列的长度不一,需要设定最大长度,这里不妨设为128,那么将整个文本转换为数组之后,形状即为100 x 128,这就对应着batch_size和seq_length。
输入之后,紧接着进行词嵌入处理,词嵌入就是将每一个词用预先训练好的向量进行映射。
词嵌入在torch里基于torch.nn.Embedding实现,实例化时需要设置的参数为词表的大小和被映射的向量的维度比如embed = nn.Embedding(10,8)。向量的维度通俗来说就是向量里面有多少个数。注意,第一个参数是词表的大小,如果你目前最多有8个词,通常填写10(多一个位置留给unk和pad),你后面万一进入与这8个词不同的词就映射到unk上,序列padding的部分就映射到pad上。
假如我们打算映射到8维(num_features或者embed_dim),那么,整个文本的形状变为100 x 128 x 8。接下来举个小例子解释一下:假设我们词表一共有10个词(算上unk和pad),文本里有2个句子,每个句子有4个词,我们想要把每个词映射到8维的向量。于是2,4,8对应于batch_size, seq_length, embed_dim(如果batch在第一维的话)。
另外,一般深度学习任务只改变num_features,所以讲维度一般是针对最后特征所在的维度。
所有需要的包的导入:
import torch
import torch.nn as nn
from torch.nn.parameter import Parameter
from torch.nn.init import xavier_uniform_
from torch.nn.init import constant_
from torch.nn.init import xavier_normal_
import torch.nn.functional as F
from typing import Optional, Tuple, Any
from typing import List, Optional, Tuple
import math
import warnings
X = torch.zeros((2,4),dtype=torch.long)
embed = nn.Embedding(10,8)
print(embed(X).shape)
# 打印出torch.Size([2, 4, 8])
二、位置编码
词嵌入之后紧接着就是位置编码,位置编码用以区分不同词以及同词不同特征之间的关系。代码中需要注意:X_只是初始化的矩阵,并不是输入进来的;完成位置编码之后会加一个dropout。另外,位置编码是最后加上去的,因此输入输出形状不变。
Tensor = torch.Tensor
def positional_encoding(X, num_features, dropout_p=0.1, max_len=512) -> Tensor:
r'''
给输入加入位置编码
参数:
- num_features: 输入进来的维度
- dropout_p: dropout的概率,当其为非零时执行dropout
- max_len: 句子的最大长度,默认512
形状:
- 输入: [batch_size, seq_length, num_features]
- 输出: [batch_size, seq_length, num_features]
例子:
>>> X = torch.randn((2,4,10))
>>> X = positional_encoding(X, 10)
>>> print(X.shape)
>>> torch.Size([2, 4, 10])
'''
dropout = nn.Dropout(dropout_p)
P = torch.zeros((1,max_len,num_features))
X_ = torch.arange(max_len,dtype=torch.float32).reshape(-1,1) / torch.pow(
10000,
torch.arange(0,num_features,2,dtype=torch.float32) /num_features)
P[:,:,0::2] = torch.sin(X_)
P[:,:,1::2] = torch.cos(X_)
X = X + P[:,:X.shape[1],:].to(X.device)
return dropout(X)
# 位置编码例子
X = torch.randn((2,4,10))
X = positional_encoding(X, 10)
print(X.shape)
# 打印出torch.Size([2, 4, 10])
三、多头注意力机制
3.1 拆开看多头注意力机制
多头注意力类主要成分是:参数初始化、multi_head_attention_forward
A.初始化参数
if self._qkv_same_embed_dim is False:
# 初始化前后形状维持不变
# (seq_length x embed_dim) x (embed_dim x embed_dim) ==> (seq_length x embed_dim)
self.q_proj_weight = Parameter(torch.empty((embed_dim, embed_dim)))
self.k_proj_weight = Parameter(torch.empty((embed_dim, self.kdim)))
self.v_proj_weight = Parameter(torch.empty((embed_dim, self.vdim)))
self.register_parameter('in_proj_weight', None)
else:
self.in_proj_weight = Parameter(torch.empty((3 * embed_dim, embed_dim)))
self.register_parameter('q_proj_weight', None)
self.register_parameter('k_proj_weight', None)
self.register_parameter('v_proj_weight', None)
if bias:
self.in_proj_bias = Parameter(torch.empty(3 * embed_dim))
else:
self.register_parameter('in_proj_bias', None)
# 后期会将所有头的注意力拼接在一起然后乘上权重矩阵输出
# out_proj是为了后期准备的
self.out_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
self._reset_parameters()
torch.empty是按照所给的形状形成对应的tensor,特点是填充的值还未初始化,类比torch.randn(标准正态分布),这就是一种初始化的方式。在PyTorch中,变量类型是tensor的话是无法修改值的,而Parameter()函数可以看作为一种类型转变函数,将不可改值的tensor转换为可训练可修改的模型参数,即与model.parameters绑定在一起,register_parameter的意思是是否将这个参数放到model.parameters,None的意思是没有这个参数。
这里有个if判断,用以判断q,k,v的最后一维是否一致,若一致,则一个大的权重矩阵全部乘然后分割出来,若不是,则各初始化各的,其实初始化是不会改变原来的形状的(如,见注释)。
(1)最后有一个_reset_parameters()函数,这个是用来初始化参数数值的。xavier_uniform意思是从连续型均匀分布里面随机取样出值来作为初始化的值,xavier_normal_取样的分布是正态分布。正因为初始化值在训练神经网络的时候很重要,所以才需要这两个函数。
(2)constant_意思是用所给值来填充输入的向量。
(3)在PyTorch的源码里,似乎projection代表是一种线性变换的意思,in_proj_bias的意思就是一开始的线性变换的偏置
def _reset_parameters(self):
if self._qkv_same_embed_dim:
xavier_uniform_(self.in_proj_weight)
else:
xavier_uniform_(self.q_proj_weight)
xavier_uniform_(self.k_proj_weight)
xavier_uniform_(self.v_proj_weight)
if self.in_proj_bias is not None:
constant_(self.in_proj_bias, 0.)
constant_(self.out_proj.bias, 0.)
B.multi_head_attention_forward
这个函数如下代码所示,主要分成3个部分:
- query, key, value通过_in_projection_packed变换得到q,k,v
- 遮挡机制
- 点积注意力
import torch
Tensor = torch.Tensor
def multi_head_attention_forward(
query: Tensor,
key: Tensor,
value: Tensor,
num_heads: int,
in_proj_weight: Tensor,
in_proj_bias: Optional[Tensor],
dropout_p: float,
out_proj_weight: Tensor,
out_proj_bias: Optional[Tensor],
training: bool = True,
key_padding_mask: Optional[Tensor] = None,
need_weights: bool = True,
attn_mask: Optional[Tensor] = None,
use_seperate_proj_weight = None,
q_proj_weight: Optional[Tensor] = None,
k_proj_weight: Optional[Tensor] = None,
v_proj_weight: Optional[Tensor] = None,
) -> Tuple[Tensor, Optional[Tensor]]:
r'''
形状:
输入:
- query:`(L, N, E)`
- key: `(S, N, E)`
- value: `(S, N, E)`
- key_padding_mask: `(N, S)`
- attn_mask: `(L, S)` or `(N * num_heads, L, S)`
输出:
- attn_output:`(L, N, E)`
- attn_output_weights:`(N, L, S)`
'''
tgt_len, bsz, embed_dim = query.shape
src_len, _, _ = key.shape
head_dim = embed_dim // num_heads
q, k, v = _in_projection_packed(query, key, value, in_proj_weight, in_proj_bias)
if attn_mask is not None:
if attn_mask.dtype == torch.uint8:
warnings.warn("Byte tensor for attn_mask in nn.MultiheadAttention is deprecated. Use bool tensor instead.")
attn_mask = attn_mask.to(torch.bool)
else:
assert attn_mask.is_floating_point() or attn_mask.dtype == torch.bool, \
f"Only float, byte, and bool types are supported for attn_mask, not {
attn_mask.dtype}"
if attn_mask.dim() == 2:
correct_2d_size = (tgt_len, src_len)
if attn_mask.shape != correct_2d_size:
raise RuntimeError(f"The shape of the 2D attn_mask is {
attn_mask.shape}, but should be {
correct_2d_size}.")
attn_mask = attn_mask.unsqueeze(0)
elif attn_mask.dim() == 3:
correct_3d_size = (bsz * num_heads, tgt_len, src_len)
if attn_mask.shape != correct_3d_size:
raise RuntimeError(f"The shape of the 3D attn_mask is {
attn_mask.shape}, but should be {
correct_3d_size}.")
else:
raise RuntimeError(f"attn_mask's dimension {
attn_mask.dim()} is not supported")
if key_padding_mask is not None and key_padding_mask.dtype == torch.uint8:
warnings.warn("Byte tensor for key_padding_mask in nn.MultiheadAttention is deprecated. Use bool tensor instead.")
key_padding_mask = key_padding_mask.to(torch.bool)
# reshape q,k,v将Batch放在第一维以适合点积注意力
# 同时为多头机制,将不同的头拼在一起组成一层
q = q.contiguous().view(tgt_len, bsz * num_heads, head_dim).transpose(0, 1)
k = k.contiguous().view(-1, bsz * num_heads, head_dim).transpose(0, 1)
v = v.contiguous().view(-1, bsz * num_heads, head_dim).transpose(0, 1)
if key_padding_mask is not None:
assert key_padding_mask.shape == (bsz, src_len), \
f"expecting key_padding_mask shape of {
(bsz, src_len)}, but got {
key_padding_mask.shape}"
key_padding_mask = key_padding_mask.view(bsz, 1, 1, src_len). \
expand(-1, num_heads, -1, -1).reshape(bsz * num_heads, 1, src_len)
if attn_mask is None:
attn_mask = key_padding_mask
elif attn_mask.dtype == torch.bool:
attn_mask = attn_mask.logical_or(key_padding_mask)
else:
attn_mask = attn_mask.masked_fill(key_padding_mask, float("-inf"))
# 若attn_mask值是布尔值,则将mask转换为float
if attn_mask is not None and attn_mask.dtype == torch.bool:
new_attn_mask = torch.zeros_like(attn_mask, dtype=torch.float)
new_attn_mask.masked_fill_(attn_mask, float("-inf"))
attn_mask = new_attn_mask
# 若training为True时才应用dropout
if not training:
dropout_p = 0.0
attn_output, attn_output_weights = _scaled_dot_product_attention(q, k, v, attn_mask, dropout_p)
attn_output = attn_output.transpose(0, 1).contiguous().view(tgt_len, bsz, embed_dim)
attn_output = nn.functional.linear(attn_output, out_proj_weight, out_proj_bias)
if need_weights:
# average attention weights over heads
attn_output_weights = attn_output_weights.view(bsz, num_heads, tgt_len, src_len)
return attn_output, attn_output_weights.sum(dim=1) / num_heads
else:
return attn_output, None
(1)query, key, value通过_in_projection_packed变换得到q,k,v
q, k, v = _in_projection_packed(query, key, value, in_proj_weight, in_proj_bias)
对于nn.functional.linear函数,其实就是一个线性变换,与nn.Linear不同的是,前者可以提供权重矩阵和偏置,执行,而后者是可以自由决定输出的维度。
def _in_projection_packed(
q: Tensor,
k: Tensor,
v: Tensor,
w: Tensor,
b: Optional[Tensor] = None,
) -> List[Tensor]:
r"""
用一个大的权重参数矩阵进行线性变换
参数:
q, k, v: 对自注意来说,三者都是src;对于seq2seq模型,k和v是一致的tensor。
但它们的最后一维(num_features或者叫做embed_dim)都必须保持一致。
w: 用以线性变换的大矩阵,按照q,k,v的顺序压在一个tensor里面。
b: 用以线性变换的偏置,按照q,k,v的顺序压在一个tensor里面。
形状:
输入:
- q: shape:`(..., E)`,E是词嵌入的维度(下面出现的E均为此意)。
- k: shape:`(..., E)`
- v: shape:`(..., E)`
- w: shape:`(E * 3, E)`
- b: shape:`E * 3`
输出:
- 输出列表 :`[q', k', v']`,q,k,v经过线性变换前后的形状都一致。
"""
E = q.size(-1)
# 若为自注意,则q = k = v = src,因此它们的引用变量都是src
# 即k is v和q is k结果均为True
# 若为seq2seq,k = v,因而k is v的结果是True
if k is v:
if q is k:
return F.linear(q, w, b).chunk(3, dim=-1)
else:
# seq2seq模型
w_q, w_kv = w.split([E, E * 2])
if b is None:
b_q = b_kv = None
else:
b_q, b_kv = b.split([E, E * 2])
return (F.linear(q, w_q, b_q),) + F.linear(k, w_kv, b_kv).chunk(2, dim=-1)
else:
w_q, w_k, w_v = w.chunk(3)
if b is None:
b_q = b_k = b_v = None
else:
b_q, b_k, b_v = b.chunk(3)
return F.linear(q, w_q, b_q), F.linear(k, w_k, b_k), F.linear(v, w_v, b_v)
# q, k, v = _in_projection_packed(query, key, value, in_proj_weight, in_proj_bias)
(2)遮挡机制
对于attn_mask来说,若为2D,形状如(L, S),L和S分别代表着目标语言和源语言序列长度,若为3D,形状如(N * num_heads, L, S),N代表着batch_size,num_heads代表注意力头的数目。若为attn_mask的dtype为ByteTensor,非0的位置会被忽略不做注意力;若为BoolTensor,True对应的位置会被忽略;若为数值,则会直接加到attn_weights。
因为在decoder解码的时候,只能看该位置和它之前的,如果看后面就犯规了,所以需要attn_mask遮挡住。
下面函数直接复制PyTorch的,意思是确保不同维度的mask形状正确以及不同类型的转换
if attn_mask is not None:
if attn_mask.dtype == torch.uint8:
warnings.warn("Byte tensor for attn_mask in nn.MultiheadAttention is deprecated. Use bool tensor instead.")
attn_mask = attn_mask.to(torch.bool)
else:
assert attn_mask.is_floating_point() or attn_mask.dtype == torch.bool, \
f"Only float, byte, and bool types are supported for attn_mask, not {
attn_mask.dtype}"
# 对不同维度的形状判定
if attn_mask.dim() == 2:
correct_2d_size = (tgt_len, src_len)
if attn_mask.shape != correct_2d_size:
raise RuntimeError(f"The shape of the 2D attn_mask is {
attn_mask.shape}, but should be {
correct_2d_size}.")
attn_mask = attn_mask.unsqueeze(0)
elif attn_mask.dim() == 3:
correct_3d_size = (bsz * num_heads, tgt_len, src_len)
if attn_mask.shape != correct_3d_size:
raise RuntimeError(f"The shape of the 3D attn_mask is {
attn_mask.shape}, but should be {
correct_3d_size}.")
else:
raise RuntimeError(f"attn_mask's dimension {
attn_mask.dim()} is not supported")
与attn_mask不同的是,key_padding_mask是用来遮挡住key里面的值,详细来说应该是<PAD>,被忽略的情况与attn_mask一致。
# 将key_padding_mask值改为布尔值
if key_padding_mask is not None and key_padding_mask.dtype == torch.uint8:
warnings.warn("Byte tensor for key_padding_mask in nn.MultiheadAttention is deprecated. Use bool tensor instead.")
key_padding_mask = key_padding_mask.to(torch.bool)
先介绍两个小函数:
(1)logical_or,输入两个tensor,并对这两个tensor里的值做逻辑或运算,只有当两个值均为0的时候才为False,其他时候均为True
(2)另一个是masked_fill,输入是一个mask,和用以填充的值。mask由1,0组成,0的位置值维持不变,1的位置用新值填充。
a = torch.tensor([0,1,10,0],dtype=torch.int8)
b = torch.tensor([4,0,1,0],dtype=torch.int8)
print(torch.logical_or(a,b))
# tensor([ True, True, True, False])
r = torch.tensor([[0,0,0,0],[0,0,0,0]])
mask = torch.tensor([[1,1,1,1],[0,0,0,0]])
print(r.masked_fill(mask,1))
# tensor([[1, 1, 1, 1],
# [0, 0, 0, 0]])
其实attn_mask和key_padding_mask有些时候对象是一致的,所以有时候可以合起来看。-inf做softmax之后值为0,即被忽略。
if key_padding_mask is not None:
assert key_padding_mask.shape == (bsz, src_len), \
f"expecting key_padding_mask shape of {
(bsz, src_len)}, but got {
key_padding_mask.shape}"
key_padding_mask = key_padding_mask.view(bsz, 1, 1, src_len). \
expand(-1, num_heads, -1, -1).reshape(bsz * num_heads, 1, src_len)
# 若attn_mask为空,直接用key_padding_mask
if attn_mask is None:
attn_mask = key_padding_mask
elif attn_mask.dtype == torch.bool:
attn_mask = attn_mask.logical_or(key_padding_mask)
else:
attn_mask = attn_mask.masked_fill(key_padding_mask, float("-inf"))
# 若attn_mask值是布尔值,则将mask转换为float
if attn_mask is not None and attn_mask.dtype == torch.bool:
new_attn_mask = torch.zeros_like(attn_mask, dtype=torch.float)
new_attn_mask.masked_fill_(attn_mask, float("-inf"))
attn_mask = new_attn_mask
(3)点积注意力
from typing import Optional, Tuple, Any
def _scaled_dot_product_attention(
q: Tensor,
k: Tensor,
v: Tensor,
attn_mask: Optional[Tensor] = None,
dropout_p: float = 0.0,
) -> Tuple[Tensor, Tensor]:
r'''
在query, key, value上计算点积注意力,若有注意力遮盖则使用,并且应用一个概率为dropout_p的dropout
参数:
- q: shape:`(B, Nt, E)` B代表batch size, Nt是目标语言序列长度,E是嵌入后的特征维度
- key: shape:`(B, Ns, E)` Ns是源语言序列长度
- value: shape:`(B, Ns, E)`与key形状一样
- attn_mask: 要么是3D的tensor,形状为:`(B, Nt, Ns)`或者2D的tensor,形状如:`(Nt, Ns)`
- Output: attention values: shape:`(B, Nt, E)`,与q的形状一致;attention weights: shape:`(B, Nt, Ns)`
例子:
>>> q = torch.randn((2,3,6))
>>> k = torch.randn((2,4,6))
>>> v = torch.randn((2,4,6))
>>> out = scaled_dot_product_attention(q, k, v)
>>> out[0].shape, out[1].shape
>>> torch.Size([2, 3, 6]) torch.Size([2, 3, 4])
'''
B, Nt, E = q.shape
q = q / math.sqrt(E)
# (B, Nt, E) x (B, E, Ns) -> (B, Nt, Ns)
attn = torch.bmm(q, k.transpose(-2,-1))
if attn_mask is not None:
attn += attn_mask
# attn意味着目标序列的每个词对源语言序列做注意力
attn = F.softmax(attn, dim=-1)
if dropout_p:
attn = F.dropout(attn, p=dropout_p)
# (B, Nt, Ns) x (B, Ns, E) -> (B, Nt, E)
output = torch.bmm(attn, v)
return output, attn
3.2 完整的多头注意力机制-MultiheadAttention
class MultiheadAttention(nn.Module):
r'''
参数:
embed_dim: 词嵌入的维度
num_heads: 平行头的数量
batch_first: 若`True`,则为(batch, seq, feture),若为`False`,则为(seq, batch, feature)
例子:
>>> multihead_attn = MultiheadAttention(embed_dim, num_heads)
>>> attn_output, attn_output_weights = multihead_attn(query, key, value)
'''
def __init__(self, embed_dim, num_heads, dropout=0., bias=True,
kdim=None, vdim=None, batch_first=False) -> None:
# factory_kwargs = {'device': device, 'dtype': dtype}
super(MultiheadAttention, self).__init__()
self.embed_dim = embed_dim
self.kdim = kdim if kdim is not None else embed_dim
self.vdim = vdim if vdim is not None else embed_dim
self._qkv_same_embed_dim = self.kdim == embed_dim and self.vdim == embed_dim
self.num_heads = num_heads
self.dropout = dropout
self.batch_first = batch_first
self.head_dim = embed_dim // num_heads
assert self.head_dim * num_heads == self.embed_dim, "embed_dim must be divisible by num_heads"
if self._qkv_same_embed_dim is False:
self.q_proj_weight = Parameter(torch.empty((embed_dim, embed_dim)))
self.k_proj_weight = Parameter(torch.empty((embed_dim, self.kdim)))
self.v_proj_weight = Parameter(torch.empty((embed_dim, self.vdim)))
self.register_parameter('in_proj_weight', None)
else:
self.in_proj_weight = Parameter(torch.empty((3 * embed_dim, embed_dim)))
self.register_parameter('q_proj_weight', None)
self.register_parameter('k_proj_weight', None)
self.register_parameter('v_proj_weight', None)
if bias:
self.in_proj_bias = Parameter(torch.empty(3 * embed_dim))
else:
self.register_parameter('in_proj_bias', None)
self.out_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
self._reset_parameters()
def _reset_parameters(self):
if self._qkv_same_embed_dim:
xavier_uniform_(self.in_proj_weight)
else:
xavier_uniform_(self.q_proj_weight)
xavier_uniform_(self.k_proj_weight)
xavier_uniform_(self.v_proj_weight)
if self.in_proj_bias is not None:
constant_(self.in_proj_bias, 0.)
constant_(self.out_proj.bias, 0.)
def forward(self, query: Tensor, key: Tensor, value: Tensor, key_padding_mask: Optional[Tensor] = None,
need_weights: bool = True, attn_mask: Optional[Tensor] = None) -> Tuple[Tensor, Optional[Tensor]]:
if self.batch_first:
query, key, value = [x.transpose(1, 0) for x in (query, key, value)]
if not self._qkv_same_embed_dim:
attn_output, attn_output_weights = multi_head_attention_forward(
query, key, value, self.num_heads,
self.in_proj_weight, self.in_proj_bias,
self.dropout, self.out_proj.weight, self.out_proj.bias,
training=self.training,
key_padding_mask=key_padding_mask, need_weights=need_weights,
attn_mask=attn_mask, use_separate_proj_weight=True,
q_proj_weight=self.q_proj_weight, k_proj_weight=self.k_proj_weight,
v_proj_weight=self.v_proj_weight)
else:
attn_output, attn_output_weights = multi_head_attention_forward(
query, key, value, self.num_heads,
self.in_proj_weight, self.in_proj_bias,
self.dropout, self.out_proj.weight, self.out_proj.bias,
training=self.training,
key_padding_mask=key_padding_mask, need_weights=need_weights,
attn_mask=attn_mask)
if self.batch_first:
return attn_output.transpose(1, 0), attn_output_weights
else:
return attn_output, attn_output_weights
接下来可以实践一下,并且把位置编码加起来,可以发现加入位置编码和进行多头注意力的前后形状都是不会变的
# 因为batch_first为False,所以src的shape:`(seq, batch, embed_dim)`
src = torch.randn((2,4,100))
src = positional_encoding(src,100,0.1)
print(src.shape)
multihead_attn = MultiheadAttention(100, 4, 0.1)
attn_output, attn_output_weights = multihead_attn(src,src,src)
print(attn_output.shape, attn_output_weights.shape)
# 打印出torch.Size([2, 4, 100])
# 打印出torch.Size([2, 4, 100]) torch.Size([4, 2, 2])
四、Transformer的EncoderLayer
- Encoder Layer
class TransformerEncoderLayer(nn.Module):
r'''
参数:
d_model: 词嵌入的维度(必备)
nhead: 多头注意力中平行头的数目(必备)
dim_feedforward: 全连接层的神经元的数目,又称经过此层输入的维度(Default = 2048)
dropout: dropout的概率(Default = 0.1)
activation: 两个线性层中间的激活函数,默认relu或gelu
lay_norm_eps: layer normalization中的微小量,防止分母为0(Default = 1e-5)
batch_first: 若`True`,则为(batch, seq, feture),若为`False`,则为(seq, batch, feature)(Default:False)
例子:
>>> encoder_layer = TransformerEncoderLayer(d_model=512, nhead=8)
>>> src = torch.randn((32, 10, 512))
>>> out = encoder_layer(src)
'''
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1, activation=F.relu,
layer_norm_eps=1e-5, batch_first=False) -> None:
super(TransformerEncoderLayer, self).__init__()
self.self_attn = MultiheadAttention(d_model, nhead, dropout=dropout, batch_first=batch_first)
self.linear1 = nn.Linear(d_model, dim_feedforward)
self.dropout = nn.Dropout(dropout)
self.linear2 = nn.Linear(dim_feedforward, d_model)
self.norm1 = nn.LayerNorm(d_model, eps=layer_norm_eps)
self.norm2 = nn.LayerNorm(d_model, eps=layer_norm_eps)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.activation = activation
def forward(self, src: Tensor, src_mask: Optional[Tensor] = None, src_key_padding_mask: Optional[Tensor] = None) -> Tensor:
src = positional_encoding(src, src.shape[-1])
src2 = self.self_attn(src, src, src, attn_mask=src_mask,
key_padding_mask=src_key_padding_mask)[0]
src = src + self.dropout1(src2)
src = self.norm1(src)
src2 = self.linear2(self.dropout(self.activation(self.linear1(src))))
src = src + self.dropout(src2)
src = self.norm2(src)
return src
# 用小例子看一下
encoder_layer = TransformerEncoderLayer(d_model=512, nhead=8)
src = torch.randn((32, 10, 512))
out = encoder_layer(src)
print(out.shape)
# torch.Size([32, 10, 512])
五、Transformer layer组成Encoder
class TransformerEncoder(nn.Module):
r'''
参数:
encoder_layer(必备)
num_layers: encoder_layer的层数(必备)
norm: 归一化的选择(可选)
例子:
>>> encoder_layer = TransformerEncoderLayer(d_model=512, nhead=8)
>>> transformer_encoder = TransformerEncoder(encoder_layer, num_layers=6)
>>> src = torch.randn((10, 32, 512))
>>> out = transformer_encoder(src)
'''
def __init__(self, encoder_layer, num_layers, norm=None):
super(TransformerEncoder, self).__init__()
self.layer = encoder_layer
self.num_layers = num_layers
self.norm = norm
def forward(self, src: Tensor, mask: Optional[Tensor] = None, src_key_padding_mask: Optional[Tensor] = None) -> Tensor:
output = positional_encoding(src, src.shape[-1])
for _ in range(self.num_layers):
output = self.layer(output, src_mask=mask, src_key_padding_mask=src_key_padding_mask)
if self.norm is not None:
output = self.norm(output)
return output
# 例子
encoder_layer = TransformerEncoderLayer(d_model=512, nhead=8)
transformer_encoder = TransformerEncoder(encoder_layer, num_layers=6)
src = torch.randn((10, 32, 512))
out = transformer_encoder(src)
print(out.shape)
# torch.Size([10, 32, 512])
六、Decoder Layer:
class TransformerDecoderLayer(nn.Module):
r'''
参数:
d_model: 词嵌入的维度(必备)
nhead: 多头注意力中平行头的数目(必备)
dim_feedforward: 全连接层的神经元的数目,又称经过此层输入的维度(Default = 2048)
dropout: dropout的概率(Default = 0.1)
activation: 两个线性层中间的激活函数,默认relu或gelu
lay_norm_eps: layer normalization中的微小量,防止分母为0(Default = 1e-5)
batch_first: 若`True`,则为(batch, seq, feture),若为`False`,则为(seq, batch, feature)(Default:False)
例子:
>>> decoder_layer = TransformerDecoderLayer(d_model=512, nhead=8)
>>> memory = torch.randn((10, 32, 512))
>>> tgt = torch.randn((20, 32, 512))
>>> out = decoder_layer(tgt, memory)
'''
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1, activation=F.relu,
layer_norm_eps=1e-5, batch_first=False) -> None:
super(TransformerDecoderLayer, self).__init__()
self.self_attn = MultiheadAttention(d_model, nhead, dropout=dropout, batch_first=batch_first)
self.multihead_attn = MultiheadAttention(d_model, nhead, dropout=dropout, batch_first=batch_first)
self.linear1 = nn.Linear(d_model, dim_feedforward)
self.dropout = nn.Dropout(dropout)
self.linear2 = nn.Linear(dim_feedforward, d_model)
self.norm1 = nn.LayerNorm(d_model, eps=layer_norm_eps)
self.norm2 = nn.LayerNorm(d_model, eps=layer_norm_eps)
self.norm3 = nn.LayerNorm(d_model, eps=layer_norm_eps)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.dropout3 = nn.Dropout(dropout)
self.activation = activation
def forward(self, tgt: Tensor, memory: Tensor, tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,tgt_key_padding_mask: Optional[Tensor] = None, memory_key_padding_mask: Optional[Tensor] = None) -> Tensor:
r'''
参数:
tgt: 目标语言序列(必备)
memory: 从最后一个encoder_layer跑出的句子(必备)
tgt_mask: 目标语言序列的mask(可选)
memory_mask(可选)
tgt_key_padding_mask(可选)
memory_key_padding_mask(可选)
'''
tgt2 = self.self_attn(tgt, tgt, tgt, attn_mask=tgt_mask,
key_padding_mask=tgt_key_padding_mask)[0]
tgt = tgt + self.dropout1(tgt2)
tgt = self.norm1(tgt)
tgt2 = self.multihead_attn(tgt, memory, memory, attn_mask=memory_mask,
key_padding_mask=memory_key_padding_mask)[0]
tgt = tgt + self.dropout2(tgt2)
tgt = self.norm2(tgt)
tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt))))
tgt = tgt + self.dropout3(tgt2)
tgt = self.norm3(tgt)
return tgt
# 可爱的小例子
decoder_layer = nn.TransformerDecoderLayer(d_model=512, nhead=8)
memory = torch.randn((10, 32, 512))
tgt = torch.randn((20, 32, 512))
out = decoder_layer(tgt, memory)
print(out.shape)
# torch.Size([20, 32, 512])
Decoder代码
class TransformerDecoder(nn.Module):
r'''
参数:
decoder_layer(必备)
num_layers: decoder_layer的层数(必备)
norm: 归一化选择
例子:
>>> decoder_layer =TransformerDecoderLayer(d_model=512, nhead=8)
>>> transformer_decoder = TransformerDecoder(decoder_layer, num_layers=6)
>>> memory = torch.rand(10, 32, 512)
>>> tgt = torch.rand(20, 32, 512)
>>> out = transformer_decoder(tgt, memory)
'''
def __init__(self, decoder_layer, num_layers, norm=None):
super(TransformerDecoder, self).__init__()
self.layer = decoder_layer
self.num_layers = num_layers
self.norm = norm
def forward(self, tgt: Tensor, memory: Tensor, tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None, tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None) -> Tensor:
output = tgt
for _ in range(self.num_layers):
output = self.layer(output, memory, tgt_mask=tgt_mask,
memory_mask=memory_mask,
tgt_key_padding_mask=tgt_key_padding_mask,
memory_key_padding_mask=memory_key_padding_mask)
if self.norm is not None:
output = self.norm(output)
return output
# 可爱的小例子
decoder_layer =TransformerDecoderLayer(d_model=512, nhead=8)
transformer_decoder = TransformerDecoder(decoder_layer, num_layers=6)
memory = torch.rand(10, 32, 512)
tgt = torch.rand(20, 32, 512)
out = transformer_decoder(tgt, memory)
print(out.shape)
# torch.Size([20, 32, 512])
总结:其实经过位置编码,多头注意力,Encoder Layer和Decoder Layer形状不会变的,而Encoder和Decoder分别与src和tgt形状一致
七、Transformer类
class Transformer(nn.Module):
r'''
参数:
d_model: 词嵌入的维度(必备)(Default=512)
nhead: 多头注意力中平行头的数目(必备)(Default=8)
num_encoder_layers:编码层层数(Default=8)
num_decoder_layers:解码层层数(Default=8)
dim_feedforward: 全连接层的神经元的数目,又称经过此层输入的维度(Default = 2048)
dropout: dropout的概率(Default = 0.1)
activation: 两个线性层中间的激活函数,默认relu或gelu
custom_encoder: 自定义encoder(Default=None)
custom_decoder: 自定义decoder(Default=None)
lay_norm_eps: layer normalization中的微小量,防止分母为0(Default = 1e-5)
batch_first: 若`True`,则为(batch, seq, feture),若为`False`,则为(seq, batch, feature)(Default:False)
例子:
>>> transformer_model = Transformer(nhead=16, num_encoder_layers=12)
>>> src = torch.rand((10, 32, 512))
>>> tgt = torch.rand((20, 32, 512))
>>> out = transformer_model(src, tgt)
'''
def __init__(self, d_model: int = 512, nhead: int = 8, num_encoder_layers: int = 6,
num_decoder_layers: int = 6, dim_feedforward: int = 2048, dropout: float = 0.1,
activation = F.relu, custom_encoder: Optional[Any] = None, custom_decoder: Optional[Any] = None,
layer_norm_eps: float = 1e-5, batch_first: bool = False) -> None:
super(Transformer, self).__init__()
if custom_encoder is not None:
self.encoder = custom_encoder
else:
encoder_layer = TransformerEncoderLayer(d_model, nhead, dim_feedforward, dropout,
activation, layer_norm_eps, batch_first)
encoder_norm = nn.LayerNorm(d_model, eps=layer_norm_eps)
self.encoder = TransformerEncoder(encoder_layer, num_encoder_layers)
if custom_decoder is not None:
self.decoder = custom_decoder
else:
decoder_layer = TransformerDecoderLayer(d_model, nhead, dim_feedforward, dropout,
activation, layer_norm_eps, batch_first)
decoder_norm = nn.LayerNorm(d_model, eps=layer_norm_eps)
self.decoder = TransformerDecoder(decoder_layer, num_decoder_layers, decoder_norm)
self._reset_parameters()
self.d_model = d_model
self.nhead = nhead
self.batch_first = batch_first
def forward(self, src: Tensor, tgt: Tensor, src_mask: Optional[Tensor] = None, tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None, src_key_padding_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None, memory_key_padding_mask: Optional[Tensor] = None) -> Tensor:
r'''
参数:
src: 源语言序列(送入Encoder)(必备)
tgt: 目标语言序列(送入Decoder)(必备)
src_mask: (可选)
tgt_mask: (可选)
memory_mask: (可选)
src_key_padding_mask: (可选)
tgt_key_padding_mask: (可选)
memory_key_padding_mask: (可选)
形状:
- src: shape:`(S, N, E)`, `(N, S, E)` if batch_first.
- tgt: shape:`(T, N, E)`, `(N, T, E)` if batch_first.
- src_mask: shape:`(S, S)`.
- tgt_mask: shape:`(T, T)`.
- memory_mask: shape:`(T, S)`.
- src_key_padding_mask: shape:`(N, S)`.
- tgt_key_padding_mask: shape:`(N, T)`.
- memory_key_padding_mask: shape:`(N, S)`.
[src/tgt/memory]_mask确保有些位置不被看到,如做decode的时候,只能看该位置及其以前的,而不能看后面的。
若为ByteTensor,非0的位置会被忽略不做注意力;若为BoolTensor,True对应的位置会被忽略;
若为数值,则会直接加到attn_weights
[src/tgt/memory]_key_padding_mask 使得key里面的某些元素不参与attention计算,三种情况同上
- output: shape:`(T, N, E)`, `(N, T, E)` if batch_first.
注意:
src和tgt的最后一维需要等于d_model,batch的那一维需要相等
例子:
>>> output = transformer_model(src, tgt, src_mask=src_mask, tgt_mask=tgt_mask)
'''
memory = self.encoder(src, mask=src_mask, src_key_padding_mask=src_key_padding_mask)
output = self.decoder(tgt, memory, tgt_mask=tgt_mask, memory_mask=memory_mask,
tgt_key_padding_mask=tgt_key_padding_mask,
memory_key_padding_mask=memory_key_padding_mask)
return output
def generate_square_subsequent_mask(self, sz: int) -> Tensor:
r'''产生关于序列的mask,被遮住的区域赋值`-inf`,未被遮住的区域赋值为`0`'''
mask = (torch.triu(torch.ones(sz, sz)) == 1).transpose(0, 1)
mask = mask.float().masked_fill(mask == 0, float('-inf')).masked_fill(mask == 1, float(0.0))
return mask
def _reset_parameters(self):
r'''用正态分布初始化参数'''
for p in self.parameters():
if p.dim() > 1:
xavier_uniform_(p)
# 小例子
transformer_model = Transformer(nhead=16, num_encoder_layers=12)
src = torch.rand((10, 32, 512))
tgt = torch.rand((20, 32, 512))
out = transformer_model(src, tgt)
print(out.shape)
# torch.Size([20, 32, 512])
Reference
[1] 自然语言处理[基于预训练模型的方法] 哈工大
[2] https://www.cnblogs.com/gaowenxingxing/p/13709013.html
[3] pytorch官方文档:https://pytorch.org/tutorials/beginner/transformer_tutorial.html#load-and-batch-data
[4] pytorch 中 利用自定义函数 get_mask_from_lengths(lengths, max_len)获取每个batch的mask
[5] NLP中mask的作用
[6] NLP 中的Mask全解
[7] torch.nn.Transformer官网介绍
[8] Understanding mask size in Transformer Example
[9] language model with nn.transformer and torchtext
[10] transformer多头注意力的不同框架实现(tensorflow+pytorch)
[11] 动图图解Transformer及其工程领域应用(NLP外)
[12] 从2022年的这几篇论文看推荐系统序列建模的趋势
[13] 超详细图解Self-Attention
[14] transformer学习之位置编码
[15] Self-attention中的QKV是相等的,还是通过输入数据学出来的