使用Python,Keras和TensorFlow训练第一个CNN
这篇博客将介绍如何使用Python和Keras训练第一个卷积神经网络架构——ShallowNet,并在动物和CIFAR-10数据集上对其进行了训练。ShallowNet对动物的分类准确率为71%,比以前使用简单前馈神经网络的最佳分类准确率提高了12%。当应用于CIFAR-10时,ShallowNet达到了60%的精度,比以前使用简单多层神经网络的57%的最佳精度提高了(并且没有显著的过拟合)。
- ShallowNet是一种非常简单的CNN,只使用一个CONV层-通过使用多组CONV=>RELU=>POOL 操作训练更深层次的网络,可以获得更高的精度。
- ShallowNet架构只包含几个层-整个网络架构可以概括为:INPUT => CONV => RELU => FC。这种简单的网络架构将允许通过使用Keras库实现卷积神经网络来达到目的。
- 它是一个非常浅的CNN,然而ShallowNet能够在CIFAR-10和动物数据集上获得比许多其他方法更高的分类精度。
- ShallowNet CNN能够显著优于许多其他图像分类方法。
1. 效果图
python shallownet_animals.py --dataset datasets/animals
[INFO] loading images...
[INFO] processed500/36
[INFO] processed1000/36
[INFO] processed1500/36
[INFO] processed2000/36
[INFO] processed2500/38
[INFO] processed3000/38
[INFO] compiling model...
2022-07-03 12:28:08.856627: I tensorflow/core/platform/cpu_feature_guard.cc:142] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2
[INFO] training network...
Train on 4500 samples, validate on 1500 samples
Epoch 1/100
4500/4500 [==============================] - 6s 1ms/sample - loss: 0.9715 - accuracy: 0.4960 - val_loss: 0.9313 - val_accuracy: 0.5147
Epoch 2/100
4500/4500 [==============================] - 2s 536us/sample - loss: 0.8726 - accuracy: 0.5662 - val_loss: 0.8771 - val_accuracy: 0.5387
Epoch 3/100
4500/4500 [==============================] - 2s 509us/sample - loss: 0.8299 - accuracy: 0.5856 - val_loss: 0.8338 - val_accuracy: 0.5580
Epoch 4/100
4500/4500 [==============================] - 2s 504us/sample - loss: 0.8025 - accuracy: 0.6100 - val_loss: 0.8457 - val_accuracy: 0.5607
Epoch 5/100
4500/4500 [==============================] - 2s 501us/sample - loss: 0.7837 - accuracy: 0.6169 - val_loss: 0.8012 - val_accuracy: 0.6313
Epoch 6/100
4500/4500 [==============================] - 2s 516us/sample - loss: 0.7635 - accuracy: 0.6413 - val_loss: 0.7617 - val_accuracy: 0.6513
Epoch 7/100
4500/4500 [==============================] - 2s 541us/sample - loss: 0.7469 - accuracy: 0.6456 - val_loss: 0.7499 - val_accuracy: 0.6380
Epoch 8/100
4500/4500 [==============================] - 2s 534us/sample - loss: 0.7319 - accuracy: 0.6618 - val_loss: 0.7531 - val_accuracy: 0.6407
Epoch 9/100
4500/4500 [==============================] - 2s 525us/sample - loss: 0.7202 - accuracy: 0.6642 - val_loss: 0.7483 - val_accuracy: 0.6200
Epoch 10/100
4500/4500 [==============================] - 2s 549us/sample - loss: 0.7030 - accuracy: 0.6880 - val_loss: 0.7450 - val_accuracy: 0.6507
Epoch 11/100
4500/4500 [==============================] - 2s 526us/sample - loss: 0.6838 - accuracy: 0.6960 - val_loss: 0.7061 - val_accuracy: 0.6753
Epoch 12/100
4500/4500 [==============================] - 2s 517us/sample - loss: 0.6748 - accuracy: 0.6962 - val_loss: 0.7228 - val_accuracy: 0.6593
Epoch 13/100
4500/4500 [==============================] - 2s 528us/sample - loss: 0.6592 - accuracy: 0.7076 - val_loss: 0.6786 - val_accuracy: 0.6947
Epoch 14/100
4500/4500 [==============================] - 2s 523us/sample - loss: 0.6414 - accuracy: 0.7187 - val_loss: 0.6656 - val_accuracy: 0.7053
Epoch 15/100
4500/4500 [==============================] - 2s 513us/sample - loss: 0.6278 - accuracy: 0.7327 - val_loss: 0.6977 - val_accuracy: 0.6553
Epoch 16/100
4500/4500 [==============================] - 2s 531us/sample - loss: 0.6140 - accuracy: 0.7373 - val_loss: 0.7598 - val_accuracy: 0.6173
Epoch 17/100
4500/4500 [==============================] - 2s 509us/sample - loss: 0.5979 - accuracy: 0.7493 - val_loss: 0.6814 - val_accuracy: 0.6500
Epoch 18/100
4500/4500 [==============================] - 2s 512us/sample - loss: 0.5892 - accuracy: 0.7442 - val_loss: 0.6723 - val_accuracy: 0.6567
Epoch 19/100
4500/4500 [==============================] - 2s 503us/sample - loss: 0.5743 - accuracy: 0.7524 - val_loss: 0.6594 - val_accuracy: 0.6620
Epoch 20/100
4500/4500 [==============================] - 2s 534us/sample - loss: 0.5661 - accuracy: 0.7653 - val_loss: 0.6620 - val_accuracy: 0.6753
Epoch 21/100
4500/4500 [==============================] - 2s 524us/sample - loss: 0.5478 - accuracy: 0.7787 - val_loss: 0.6299 - val_accuracy: 0.6893
Epoch 22/100
4500/4500 [==============================] - 2s 515us/sample - loss: 0.5390 - accuracy: 0.7742 - val_loss: 0.5977 - val_accuracy: 0.7460
Epoch 23/100
4500/4500 [==============================] - 2s 532us/sample - loss: 0.5294 - accuracy: 0.7818 - val_loss: 0.6104 - val_accuracy: 0.7407
Epoch 24/100
4500/4500 [==============================] - 2s 518us/sample - loss: 0.5167 - accuracy: 0.7889 - val_loss: 0.5828 - val_accuracy: 0.7407
Epoch 25/100
4500/4500 [==============================] - 3s 561us/sample - loss: 0.5027 - accuracy: 0.7960 - val_loss: 0.6251 - val_accuracy: 0.7053
Epoch 26/100
4500/4500 [==============================] - 3s 588us/sample - loss: 0.4924 - accuracy: 0.8029 - val_loss: 0.6016 - val_accuracy: 0.7093
Epoch 27/100
4500/4500 [==============================] - 2s 547us/sample - loss: 0.4837 - accuracy: 0.8064 - val_loss: 0.5647 - val_accuracy: 0.7507
Epoch 28/100
4500/4500 [==============================] - 2s 513us/sample - loss: 0.4808 - accuracy: 0.8058 - val_loss: 0.5967 - val_accuracy: 0.7087
Epoch 29/100
4500/4500 [==============================] - 2s 517us/sample - loss: 0.4622 - accuracy: 0.8238 - val_loss: 0.5568 - val_accuracy: 0.7513
Epoch 30/100
4500/4500 [==============================] - 2s 524us/sample - loss: 0.4536 - accuracy: 0.8238 - val_loss: 0.5760 - val_accuracy: 0.7247
Epoch 31/100
4500/4500 [==============================] - 2s 537us/sample - loss: 0.4477 - accuracy: 0.8282 - val_loss: 0.5729 - val_accuracy: 0.7427
Epoch 32/100
4500/4500 [==============================] - 3s 565us/sample - loss: 0.4406 - accuracy: 0.8300 - val_loss: 0.5676 - val_accuracy: 0.7333
Epoch 33/100
4500/4500 [==============================] - 2s 539us/sample - loss: 0.4270 - accuracy: 0.8371 - val_loss: 0.5434 - val_accuracy: 0.7640
Epoch 34/100
4500/4500 [==============================] - 2s 530us/sample - loss: 0.4210 - accuracy: 0.8418 - val_loss: 0.5660 - val_accuracy: 0.7507
Epoch 35/100
4500/4500 [==============================] - 2s 531us/sample - loss: 0.4111 - accuracy: 0.8451 - val_loss: 0.5258 - val_accuracy: 0.7773
Epoch 36/100
4500/4500 [==============================] - 2s 511us/sample - loss: 0.4043 - accuracy: 0.8524 - val_loss: 0.5369 - val_accuracy: 0.7527
Epoch 37/100
4500/4500 [==============================] - 3s 574us/sample - loss: 0.3980 - accuracy: 0.8518 - val_loss: 0.5137 - val_accuracy: 0.7840
Epoch 38/100
4500/4500 [==============================] - 2s 537us/sample - loss: 0.3853 - accuracy: 0.8598 - val_loss: 0.5773 - val_accuracy: 0.7107
Epoch 39/100
4500/4500 [==============================] - 2s 509us/sample - loss: 0.3818 - accuracy: 0.8578 - val_loss: 0.5110 - val_accuracy: 0.7753
Epoch 40/100
4500/4500 [==============================] - 2s 509us/sample - loss: 0.3731 - accuracy: 0.8669 - val_loss: 0.5063 - val_accuracy: 0.7773
Epoch 41/100
4500/4500 [==============================] - 2s 527us/sample - loss: 0.3639 - accuracy: 0.8707 - val_loss: 0.5468 - val_accuracy: 0.7720
Epoch 42/100
4500/4500 [==============================] - 2s 512us/sample - loss: 0.3588 - accuracy: 0.8764 - val_loss: 0.5168 - val_accuracy: 0.7607
Epoch 43/100
4500/4500 [==============================] - 3s 582us/sample - loss: 0.3509 - accuracy: 0.8749 - val_loss: 0.4909 - val_accuracy: 0.8113
Epoch 44/100
4500/4500 [==============================] - 3s 612us/sample - loss: 0.3460 - accuracy: 0.8813 - val_loss: 0.4830 - val_accuracy: 0.8087
Epoch 45/100
4500/4500 [==============================] - 3s 604us/sample - loss: 0.3385 - accuracy: 0.8824 - val_loss: 0.4841 - val_accuracy: 0.8080
Epoch 46/100
4500/4500 [==============================] - 3s 574us/sample - loss: 0.3321 - accuracy: 0.8867 - val_loss: 0.4977 - val_accuracy: 0.7747
Epoch 47/100
4500/4500 [==============================] - 3s 581us/sample - loss: 0.3237 - accuracy: 0.8940 - val_loss: 0.4790 - val_accuracy: 0.8100
Epoch 48/100
4500/4500 [==============================] - 2s 524us/sample - loss: 0.3195 - accuracy: 0.8909 - val_loss: 0.4732 - val_accuracy: 0.8073
Epoch 49/100
4500/4500 [==============================] - 2s 535us/sample - loss: 0.3139 - accuracy: 0.8964 - val_loss: 0.5134 - val_accuracy: 0.7687
Epoch 50/100
4500/4500 [==============================] - 2s 519us/sample - loss: 0.3089 - accuracy: 0.8949 - val_loss: 0.4775 - val_accuracy: 0.7960
Epoch 51/100
4500/4500 [==============================] - 3s 558us/sample - loss: 0.2988 - accuracy: 0.9076 - val_loss: 0.4618 - val_accuracy: 0.8160
Epoch 52/100
4500/4500 [==============================] - 2s 538us/sample - loss: 0.2974 - accuracy: 0.9049 - val_loss: 0.4629 - val_accuracy: 0.8147
Epoch 53/100
4500/4500 [==============================] - 2s 542us/sample - loss: 0.2949 - accuracy: 0.9047 - val_loss: 0.4793 - val_accuracy: 0.7953
Epoch 54/100
4500/4500 [==============================] - 2s 534us/sample - loss: 0.2883 - accuracy: 0.9096 - val_loss: 0.4598 - val_accuracy: 0.8047
Epoch 55/100
4500/4500 [==============================] - 2s 535us/sample - loss: 0.2810 - accuracy: 0.9122 - val_loss: 0.4782 - val_accuracy: 0.7920
Epoch 56/100
4500/4500 [==============================] - 2s 519us/sample - loss: 0.2800 - accuracy: 0.9131 - val_loss: 0.4675 - val_accuracy: 0.8120
Epoch 57/100
4500/4500 [==============================] - 2s 544us/sample - loss: 0.2707 - accuracy: 0.9180 - val_loss: 0.4547 - val_accuracy: 0.8153
Epoch 58/100
4500/4500 [==============================] - 2s 540us/sample - loss: 0.2657 - accuracy: 0.9209 - val_loss: 0.4744 - val_accuracy: 0.8047
Epoch 59/100
4500/4500 [==============================] - 2s 511us/sample - loss: 0.2593 - accuracy: 0.9242 - val_loss: 0.4545 - val_accuracy: 0.8153
Epoch 60/100
4500/4500 [==============================] - 2s 522us/sample - loss: 0.2565 - accuracy: 0.9273 - val_loss: 0.4403 - val_accuracy: 0.8327
Epoch 61/100
4500/4500 [==============================] - 2s 521us/sample - loss: 0.2499 - accuracy: 0.9287 - val_loss: 0.4413 - val_accuracy: 0.8260
Epoch 62/100
4500/4500 [==============================] - 2s 512us/sample - loss: 0.2486 - accuracy: 0.9267 - val_loss: 0.4380 - val_accuracy: 0.8320
Epoch 63/100
4500/4500 [==============================] - 2s 536us/sample - loss: 0.2442 - accuracy: 0.9307 - val_loss: 0.4845 - val_accuracy: 0.7993
Epoch 64/100
4500/4500 [==============================] - 2s 547us/sample - loss: 0.2388 - accuracy: 0.9324 - val_loss: 0.4481 - val_accuracy: 0.8180
Epoch 65/100
4500/4500 [==============================] - 2s 549us/sample - loss: 0.2340 - accuracy: 0.9351 - val_loss: 0.4482 - val_accuracy: 0.8153
Epoch 66/100
4500/4500 [==============================] - 2s 549us/sample - loss: 0.2257 - accuracy: 0.9416 - val_loss: 0.4270 - val_accuracy: 0.8373
Epoch 67/100
4500/4500 [==============================] - 2s 549us/sample - loss: 0.2234 - accuracy: 0.9404 - val_loss: 0.4280 - val_accuracy: 0.8420
Epoch 68/100
4500/4500 [==============================] - 2s 553us/sample - loss: 0.2198 - accuracy: 0.9387 - val_loss: 0.4197 - val_accuracy: 0.8440
Epoch 69/100
4500/4500 [==============================] - 3s 559us/sample - loss: 0.2134 - accuracy: 0.9444 - val_loss: 0.4445 - val_accuracy: 0.8207
Epoch 70/100
4500/4500 [==============================] - 3s 563us/sample - loss: 0.2108 - accuracy: 0.9438 - val_loss: 0.4566 - val_accuracy: 0.8120
Epoch 71/100
4500/4500 [==============================] - 3s 562us/sample - loss: 0.2076 - accuracy: 0.9444 - val_loss: 0.4114 - val_accuracy: 0.8480
Epoch 72/100
4500/4500 [==============================] - 2s 552us/sample - loss: 0.2048 - accuracy: 0.9469 - val_loss: 0.4330 - val_accuracy: 0.8293
Epoch 73/100
4500/4500 [==============================] - 2s 549us/sample - loss: 0.2003 - accuracy: 0.9524 - val_loss: 0.4188 - val_accuracy: 0.8433
Epoch 74/100
4500/4500 [==============================] - 2s 542us/sample - loss: 0.2010 - accuracy: 0.9522 - val_loss: 0.4207 - val_accuracy: 0.8360
Epoch 75/100
4500/4500 [==============================] - 2s 533us/sample - loss: 0.1966 - accuracy: 0.9507 - val_loss: 0.4021 - val_accuracy: 0.8587
Epoch 76/100
4500/4500 [==============================] - 3s 571us/sample - loss: 0.1922 - accuracy: 0.9522 - val_loss: 0.3985 - val_accuracy: 0.8567
Epoch 77/100
4500/4500 [==============================] - 2s 532us/sample - loss: 0.1872 - accuracy: 0.9580 - val_loss: 0.4055 - val_accuracy: 0.8587
Epoch 78/100
4500/4500 [==============================] - 2s 537us/sample - loss: 0.1853 - accuracy: 0.9602 - val_loss: 0.4003 - val_accuracy: 0.8547
Epoch 79/100
4500/4500 [==============================] - 2s 528us/sample - loss: 0.1804 - accuracy: 0.9596 - val_loss: 0.3963 - val_accuracy: 0.8553
Epoch 80/100
4500/4500 [==============================] - 2s 525us/sample - loss: 0.1744 - accuracy: 0.9631 - val_loss: 0.4004 - val_accuracy: 0.8600
Epoch 81/100
4500/4500 [==============================] - 2s 526us/sample - loss: 0.1735 - accuracy: 0.9627 - val_loss: 0.3991 - val_accuracy: 0.8547
Epoch 82/100
4500/4500 [==============================] - 2s 530us/sample - loss: 0.1718 - accuracy: 0.9620 - val_loss: 0.4186 - val_accuracy: 0.8433
Epoch 83/100
4500/4500 [==============================] - 2s 513us/sample - loss: 0.1693 - accuracy: 0.9640 - val_loss: 0.3919 - val_accuracy: 0.8593
Epoch 84/100
4500/4500 [==============================] - 2s 535us/sample - loss: 0.1657 - accuracy: 0.9656 - val_loss: 0.4512 - val_accuracy: 0.8207
Epoch 85/100
4500/4500 [==============================] - 2s 545us/sample - loss: 0.1630 - accuracy: 0.9662 - val_loss: 0.3851 - val_accuracy: 0.8653
Epoch 86/100
4500/4500 [==============================] - 2s 546us/sample - loss: 0.1599 - accuracy: 0.9676 - val_loss: 0.4135 - val_accuracy: 0.8493
Epoch 87/100
4500/4500 [==============================] - 2s 517us/sample - loss: 0.1577 - accuracy: 0.9689 - val_loss: 0.3942 - val_accuracy: 0.8647
Epoch 88/100
4500/4500 [==============================] - 2s 505us/sample - loss: 0.1549 - accuracy: 0.9702 - val_loss: 0.3897 - val_accuracy: 0.8647
Epoch 89/100
4500/4500 [==============================] - 2s 516us/sample - loss: 0.1520 - accuracy: 0.9702 - val_loss: 0.4174 - val_accuracy: 0.8433
Epoch 90/100
4500/4500 [==============================] - 2s 542us/sample - loss: 0.1489 - accuracy: 0.9707 - val_loss: 0.3888 - val_accuracy: 0.8660
Epoch 91/100
4500/4500 [==============================] - 2s 550us/sample - loss: 0.1474 - accuracy: 0.9713 - val_loss: 0.3773 - val_accuracy: 0.8760
Epoch 92/100
4500/4500 [==============================] - 2s 527us/sample - loss: 0.1436 - accuracy: 0.9736 - val_loss: 0.4097 - val_accuracy: 0.8533
Epoch 93/100
4500/4500 [==============================] - 2s 525us/sample - loss: 0.1413 - accuracy: 0.9740 - val_loss: 0.3924 - val_accuracy: 0.8607
Epoch 94/100
4500/4500 [==============================] - 2s 535us/sample - loss: 0.1373 - accuracy: 0.9762 - val_loss: 0.3740 - val_accuracy: 0.8807
Epoch 95/100
4500/4500 [==============================] - 2s 522us/sample - loss: 0.1378 - accuracy: 0.9749 - val_loss: 0.3856 - val_accuracy: 0.8707
Epoch 96/100
4500/4500 [==============================] - 2s 530us/sample - loss: 0.1346 - accuracy: 0.9764 - val_loss: 0.3705 - val_accuracy: 0.8820
Epoch 97/100
4500/4500 [==============================] - 3s 591us/sample - loss: 0.1309 - accuracy: 0.9787 - val_loss: 0.3811 - val_accuracy: 0.8700
Epoch 98/100
4500/4500 [==============================] - 3s 557us/sample - loss: 0.1284 - accuracy: 0.9789 - val_loss: 0.3752 - val_accuracy: 0.8773
Epoch 99/100
4500/4500 [==============================] - 2s 551us/sample - loss: 0.1283 - accuracy: 0.9793 - val_loss: 0.4012 - val_accuracy: 0.8620
Epoch 100/100
4500/4500 [==============================] - 2s 518us/sample - loss: 0.1275 - accuracy: 0.9771 - val_loss: 0.3684 - val_accuracy: 0.8867
[INFO] evaluating network...
precision recall f1-score support
cat 0.86 0.87 0.87 533
dog 0.87 0.83 0.85 491
panda 0.93 0.97 0.95 476
accuracy 0.89 1500
macro avg 0.89 0.89 0.89 1500
weighted avg 0.89 0.89 0.89 1500
ShallowNet在动物测试数据上获得了89%的分类精度,这比以前使用简单前馈神经网络获得的59%的最佳分类精度有了很大的提高。使用更先进的训练网络,以及更强大的架构,将能够提高分类精度甚至更高。
随时间绘制的损耗和准确度(在动物数据集上训练的Shallownet在100个纪元的过程中的损失和准确性图)如下图所示:
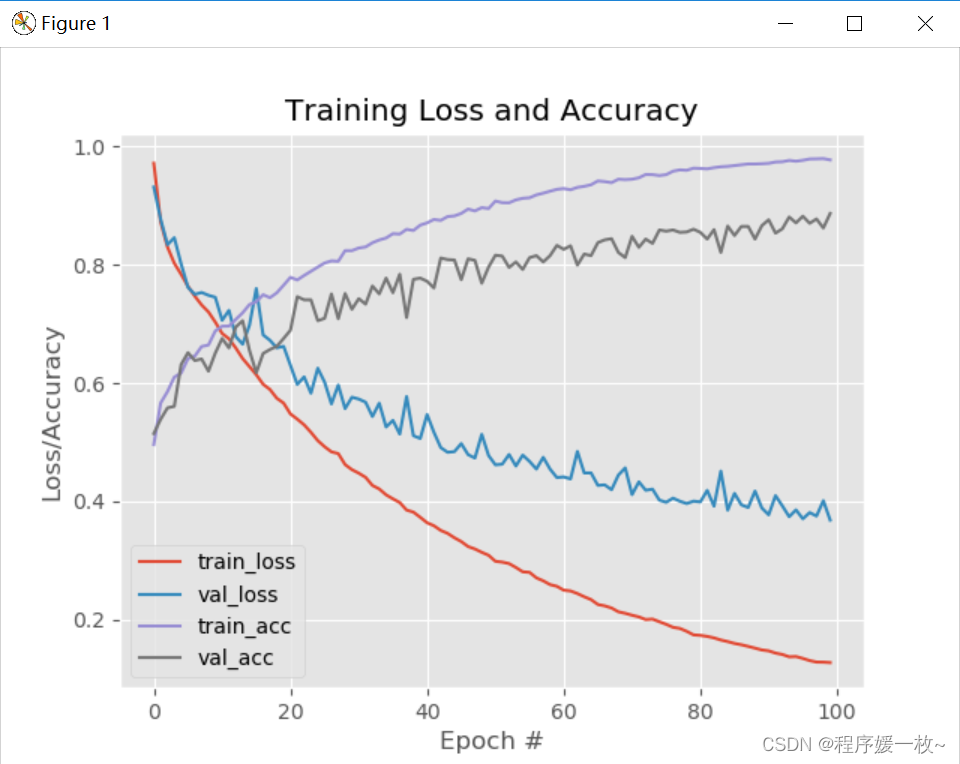
x轴纪元数,y轴损耗和精度。可以看到学习率有点不稳定,在第18,38等纪元附近有很大的损失峰值-这可能是由于学习率太高。
训练和测试损失在超过第18个纪元后严重发散,这意味着网络对训练数据的建模过于紧密和过度拟合。可以通过获取更多数据或应用数据增强等技术来解决这个问题。(收集更多的训练数据,应用数据增强,并更加注意调整学习速度,将有助于在未来改善结果。)
这里的关键点是,一个非常简单的卷积神经网络能够在动物数据集上获得89%的分类准确率,而以前的最佳分类准确率只有59%——这是超过12%的改进!
cifer-10训练结果如下:
在对40个纪元的ShallowNet进行评估后,发现它在测试集上获得了60%的准确性,比之前使用简单神经网络的57%的准确性有所提高。
更重要的是,下图的损失和准确性图表明验证损失并没有飙升。训练和测试损失/准确性从第10纪元开始偏离。同样这可以归因于更高的学习率,以及没有使用方法来帮助对抗过度拟合(正则化参数、退出、数据增强等)。
众所周知,由于低分辨率训练样本的数量有限,在CIFAR-10数据集上很容易过度拟合。随着对构建和训练自己的自定义卷积神经网络变得更加舒适,将发现一些方法来提高CIFAR-10的分类精度,同时减少过度拟合。
2. 原理
Keras配置和将图像转换为阵列
ImageToArrayProcessor,接受输入图像,然后将其转换为Keras可以处理的NumPy数组。
Keras库提供img_to_array(),该函数接受输入图像,然后根据image_data_format设置正确排序通道。将把这个函数封装在一个名为ImageToArrayProcessor的新类中。创建一个具有特殊预处理函数的类将允许创建预处理器的“链”,以有效地准备训练和测试集图像。
3. 源码
3.1 shallownet_animals.py
# USAGE
# python shallownet_animals.py --dataset datasets/animals
import argparse
import matplotlib.pyplot as plt
import numpy as np
from imutils import paths
from pyimagesearch.datasets.simpledatasetloader import SimpleDatasetLoader
from pyimagesearch.nn.conv.shallownet import ShallowNet
from pyimagesearch.preprocessing.imagetoarraypreprocessor import ImageToArrayPreprocessor
from pyimagesearch.preprocessing.simplepreprocessor import SimplePreprocessor
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
# 导入必要的包
from sklearn.preprocessing import LabelBinarizer
from tensorflow.keras.optimizers import SGD # 将使用随机梯度下降(Stochastic Gradient Descent SGD)来训练ShallowNet
# 构建命令行参数及解析
# --dataset 数据集路径
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", required=True,
help="path to input dataset")
args = vars(ap.parse_args())
# 获取图片列表,获取动物数据集中所有3000个图像的文件路径
print("[INFO] loading images...")
imagePaths = list(paths.list_images(args["dataset"]))
# 初始化图像预处理器
sp = SimplePreprocessor(32, 32)
iap = ImageToArrayPreprocessor()
# 从磁盘加载数据集,缩放像素强度范围为[0,1]
sdl = SimpleDatasetLoader(preprocessors=[sp, iap])
(data, labels) = sdl.load(imagePaths, verbose=500)
data = data.astype("float") / 255.0
# 执行训练75%和测试集25%分割
(trainX, testX, trainY, testY) = train_test_split(data, labels,
test_size=0.25, random_state=42)
# 对标签进行热编码(从int转为向量)
trainY = LabelBinarizer().fit_transform(trainY)
testY = LabelBinarizer().fit_transform(testY)
# 初始化优化器和模型
# 使用0.005的学习率初始化SGD优化器
# 实例化了ShallowNet架构,提供了32像素的宽度和高度以及3个深度-这意味着输入图像是32×32像素,有三个通道。由于动物数据集有三个类标签将类设置为3。
# 编译该模型,使用交叉熵作为损失函数,SGD作为优化器。model.fit模型拟合方法,在每个历元后评估ShallowNet的性能
# 将使用32的最小批量大小进行100个纪元的训练(即一次将向网络呈现32个图像,并将进行完全正向和反向传递以更新网络参数)
print("[INFO] compiling model...")
opt = SGD(lr=0.005)
model = ShallowNet.build(width=32, height=32, depth=3, classes=3)
model.compile(loss="categorical_crossentropy", optimizer=opt,
metrics=["accuracy"])
# 训练模型
print("[INFO] training network...")
H = model.fit(trainX, trainY, validation_data=(testX, testY),
batch_size=32, epochs=100, verbose=1)
# 评估网络
# 为了获得测试数据的输出预测,调用model.predict 并显示格式良好的分类报告。
print("[INFO] evaluating network...")
predictions = model.predict(testX, batch_size=32)
print(classification_report(testY.argmax(axis=1),
predictions.argmax(axis=1),
target_names=["cat", "dog", "panda"]))
# 绘制训练和测试数据的准确度和随时间的损失
plt.style.use("ggplot")
plt.figure()
plt.plot(np.arange(0, 100), H.history["loss"], label="train_loss")
plt.plot(np.arange(0, 100), H.history["val_loss"], label="val_loss")
plt.plot(np.arange(0, 100), H.history["accuracy"], label="train_acc")
plt.plot(np.arange(0, 100), H.history["val_accuracy"], label="val_acc")
plt.title("Training Loss and Accuracy")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend()
plt.show()
3.2 shallownet_cifar10.py
# USAGE
# python shallownet_cifar10.py
# 导入必要的包
from sklearn.preprocessing import LabelBinarizer
from sklearn.metrics import classification_report
from pyimagesearch.nn.conv.shallownet import ShallowNet
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.datasets import cifar10
import matplotlib.pyplot as plt
import numpy as np
# 加载训练/测试数据集,并缩放为[0,1]
# 加载CIFAR-10数据集(预拆分为训练集和测试集),然后将图像像素强度缩放到范围[0,1]。由于CIFAR-10图像经过预处理,通道排序在cifar10内部自动处理。
# 加载数据时,不需要应用任何自定义预处理类。
print("[INFO] loading CIFAR-10 data...")
((trainX, trainY), (testX, testY)) = cifar10.load_data()
trainX = trainX.astype("float") / 255.0
testX = testX.astype("float") / 255.0
# 一键热编码
lb = LabelBinarizer()
trainY = lb.fit_transform(trainY)
testY = lb.transform(testY)
# 初始化CIFAR-10 dataset的标签
labelNames = ["airplane", "automobile", "bird", "cat", "deer",
"dog", "frog", "horse", "ship", "truck"]
# 初始化优化器和模型
# 使用0.01的学习率初始化SGD优化器
# 实例化了ShallowNet架构,提供了32像素的宽度和高度以及3个深度-这意味着输入图像是32×32像素,有三个通道。由于cifer-10数据集有10个类标签将类设置为10。
# 编译该模型,使用交叉熵作为损失函数,SGD作为优化器。model.fit模型拟合方法,在每个历元后评估ShallowNet的性能
# 将使用32的最小批量大小进行40个纪元的训练(即一次将向网络呈现32个图像,并将进行完全正向和反向传递以更新网络参数)
print("[INFO] compiling model...")
opt = SGD(lr=0.01)
model = ShallowNet.build(width=32, height=32, depth=3, classes=10)
model.compile(loss="categorical_crossentropy", optimizer=opt,
metrics=["accuracy"])
# 训练网络
print("[INFO] training network...")
H = model.fit(trainX, trainY, validation_data=(testX, testY),
batch_size=32, epochs=40, verbose=1)
# 评估网络
# 为了获得测试数据的输出预测,调用model.predict 并显示格式良好的分类报告。
print("[INFO] evaluating network...")
predictions = model.predict(testX, batch_size=32)
print(classification_report(testY.argmax(axis=1),
predictions.argmax(axis=1), target_names=labelNames))
# 绘制训练和测试数据的准确度和随时间的损失
plt.style.use("ggplot")
plt.figure()
plt.plot(np.arange(0, 40), H.history["loss"], label="train_loss")
plt.plot(np.arange(0, 40), H.history["val_loss"], label="val_loss")
plt.plot(np.arange(0, 40), H.history["accuracy"], label="train_acc")
plt.plot(np.arange(0, 40), H.history["val_accuracy"], label="val_acc")
plt.title("Training Loss and Accuracy")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend()
plt.show()