1.数据集的制作和使用
数据可以使用labelme进行数据标注,labelme还提供了数据集格式转换脚本,可以将labelme数据集格式转换为voc数据集格式
转换后:
JPEGImages为图片,SegmentationClassPNG为标签

2.配置文件的修改
1.运行train.py,生成完整的模型配置文件,对完整的模型配置文件进行修改。
配置文件每个GPU的batch_size一定要大于1
# E:/MMLAB/mmsegmentation/tools/models/deeplabv3plus_r50-d8_512x512_20k_voc12aug_20200617_102323-aad58ef1.pth
norm_cfg = dict(type='SyncBN', requires_grad=True)
model = dict(
type='EncoderDecoder',
pretrained='open-mmlab://resnet50_v1c',
backbone=dict(
type='ResNetV1c',
depth=50,
num_stages=4,
out_indices=(0, 1, 2, 3),
dilations=(1, 1, 2, 4),
strides=(1, 2, 1, 1),
norm_cfg=dict(type='SyncBN', requires_grad=True),
norm_eval=False,
style='pytorch',
contract_dilation=True),
decode_head=dict(
type='DepthwiseSeparableASPPHead',
in_channels=2048,
in_index=3,
channels=512,
dilations=(1, 12, 24, 36),
c1_in_channels=256,
c1_channels=48,
dropout_ratio=0.1,
num_classes=2,
norm_cfg=dict(type='SyncBN', requires_grad=True),
align_corners=False,
loss_decode=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
auxiliary_head=dict(
type='FCNHead',
in_channels=1024,
in_index=2,
channels=256,
num_convs=1,
concat_input=False,
dropout_ratio=0.1,
num_classes=2,
norm_cfg=dict(type='SyncBN', requires_grad=True),
align_corners=False,
loss_decode=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.4)),
train_cfg=dict(),
test_cfg=dict(mode='slide', crop_size=(480, 480), stride=(320, 320)))
dataset_type = 'PascalContextDataset'
data_root = 'E:/MMLAB/mmsegmentation/data/my_cell_voc'
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
img_scale = (520, 520)
crop_size = (480, 480)
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations'),
dict(type='Resize', img_scale=(520, 520), ratio_range=(0.5, 2.0)),
dict(type='RandomCrop', crop_size=(480, 480), cat_max_ratio=0.75),
dict(type='RandomFlip', prob=0.5),
dict(type='PhotoMetricDistortion'),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='Pad', size=(480, 480), pad_val=0, seg_pad_val=255),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_semantic_seg'])
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(520, 520),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img'])
])
]
data = dict(
samples_per_gpu=2,
workers_per_gpu=1,
train=dict(
type='PascalContextDataset',
data_root='E:/MMLAB/mmsegmentation/data/my_cell_voc/',
img_dir='JPEGImages',
ann_dir='SegmentationClassPNG',
split='train.txt',
pipeline=[
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations'),
dict(type='Resize', img_scale=(520, 520), ratio_range=(0.5, 2.0)),
dict(type='RandomCrop', crop_size=(480, 480), cat_max_ratio=0.75),
dict(type='RandomFlip', prob=0.5),
dict(type='PhotoMetricDistortion'),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='Pad', size=(480, 480), pad_val=0, seg_pad_val=255),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_semantic_seg'])
]),
val=dict(
type='PascalContextDataset',
data_root='E:/MMLAB/mmsegmentation/data/my_cell_voc/',
img_dir='JPEGImages',
ann_dir='SegmentationClassPNG',
split='val.txt',
pipeline=[
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(520, 520),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img'])
])
]),
test=dict(
type='PascalContextDataset',
data_root='E:/MMLAB/mmsegmentation/data/my_cell_voc/',
img_dir='JPEGImages',
ann_dir='SegmentationClassPNG',
split='test.txt',
pipeline=[
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(520, 520),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img'])
])
]))
log_config = dict(
interval=50, hooks=[dict(type='TextLoggerHook', by_epoch=False)])
dist_params = dict(backend='nccl')
log_level = 'INFO'
load_from = ''
resume_from = None
workflow = [('train', 1)]
cudnn_benchmark = True
optimizer = dict(type='SGD', lr=0.004, momentum=0.9, weight_decay=0.0001)
optimizer_config = dict()
lr_config = dict(policy='poly', power=0.9, min_lr=0.0001, by_epoch=False)
runner = dict(type='IterBasedRunner', max_iters=100)
checkpoint_config = dict(by_epoch=False, interval=50)
evaluation = dict(interval=1, metric='mIoU', pre_eval=True)
work_dir = './work_dirs/deeplabv3plus_r50-d8_480x480_40k_pascal_context'
gpu_ids = [0]
auto_resume = False
2.修改mmsegmentation/mmseg/datasets/voc.py文件中的类别和颜色

3.修改mmsegmentation/mmseg/core/evaluation/class_names.py中的voc_classes()中的类别

展示验证数据
如图所示:mmsegmentation/tools/browse_dataset.py可以展示数据

3.模型的测试以及推理
mmsegmentation/demo/image_demo.py可以进行模型的推理,参数有图片路径、配置文件、权重文件等。 同时,需要修改mmseg.core.evaluation相应的类别以及颜色
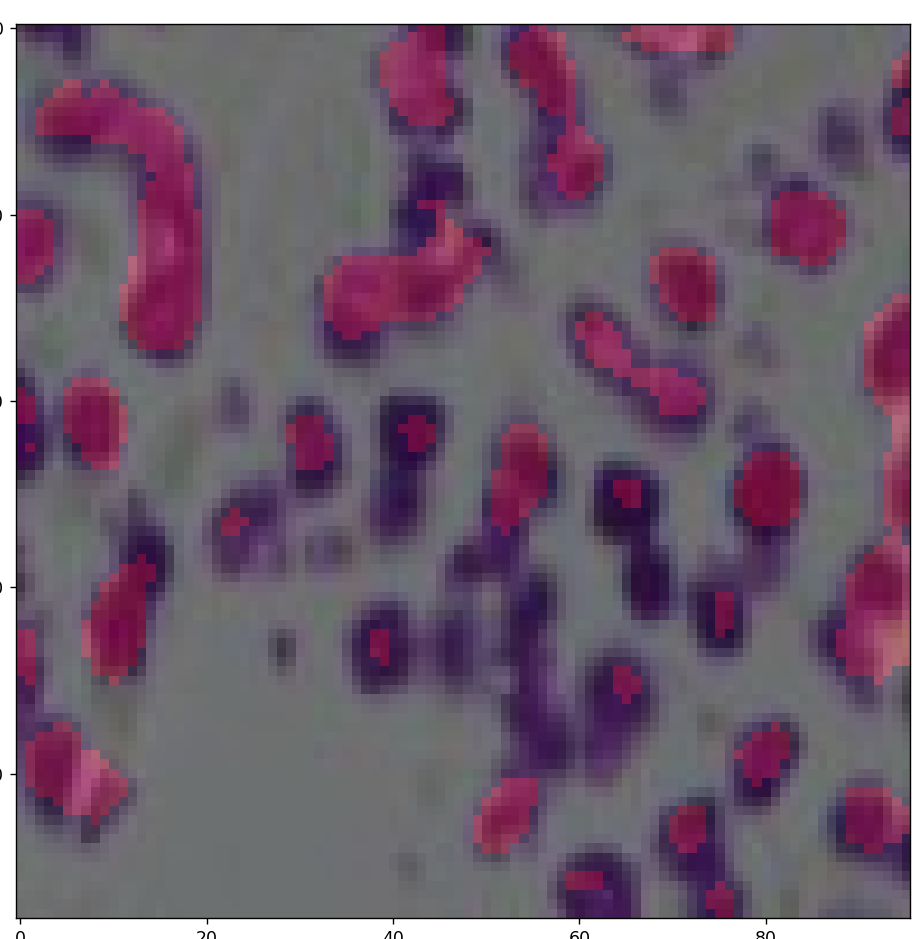
运行测试文件结果:
