之前使用Pytorch深度学习架构复现了Classification,链接如下:
CV+Deep Learning——网络架构Pytorch复现系列——classification(一:LeNet5,VGG,AlexNet,ResNet)![]() https://blog.csdn.net/XiaoyYidiaodiao/article/details/125505058CV+Deep Learning——网络架构Pytorch复现系列——classification(二:ResNeXt,GoogLeNet,MobileNet)
https://blog.csdn.net/XiaoyYidiaodiao/article/details/125505058CV+Deep Learning——网络架构Pytorch复现系列——classification(二:ResNeXt,GoogLeNet,MobileNet)![]() https://blog.csdn.net/XiaoyYidiaodiao/article/details/125692368CV+Deep Learning——网络架构Pytorch复现系列——classification(三:MobileNet,ShuffleNet)
https://blog.csdn.net/XiaoyYidiaodiao/article/details/125692368CV+Deep Learning——网络架构Pytorch复现系列——classification(三:MobileNet,ShuffleNet)![]() https://blog.csdn.net/XiaoyYidiaodiao/article/details/126228934
https://blog.csdn.net/XiaoyYidiaodiao/article/details/126228934
现在开始复现Object Detection,会复现的网络架构有:
1.SSD: Single Shot MultiBox Detector(√)
2.RetinaNet
3.Faster RCNN
4.YOLO系列
....
代码:
1.复现SSD
1.1网络模型
如图1为SSD完整的网络模型,分为三大部分VGG Backbone,Extra Layers,Multi-box Layers。SSD大约发布于2015年左右,那个时间还没有一个统一的网络模型分解啥的比如什么是Backbone,什么是Neck,什么是Head...
如果想简单理解目标检测或者语义分割的网络模型,最好还是弄明白这些内容,所以总结如下。
- Backbone(骨干网络):用于特征提取,例如ResNet,VGG等。
- Neck:用于多层特征融合,连接骨干网络与头部网络,例如FPN,PAN等。
- DenseHead(头部网络):一般说为Head,用于处理特征图上密集的anchors,可分为AnchorHead,例如RPNHead,SSDHead,RetinaNetHead等;与AnchorFreeHead,例如FCOSHead等。

依据以上,SSD网络可重新分为Backbone(VGGBackbone),Neck(Extra Layers),Head(Multi-box Layers)。
Backbone(VGGBackbone)
SSD的backbone部分如图2,将VGG原网络的第三个pool改为ceil_mode=True,conv4_3的特征图保留作为后续Head的输入,将VGG原网络的第五个pool改为(kernel_size=3, stride=1, padding=1),并将VGG原有的所有全连接层改为conv6与conv7,注意conv4_3之后做了一个Normalization
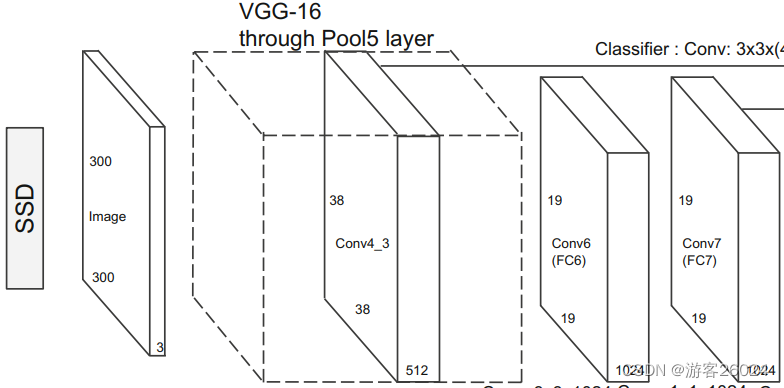
其分析,如图3所示。

原代码
def vgg(cfg, i, batch_norm=False):
layers = []
in_channels = i
for v in cfg:
if v == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
elif v == 'C':
layers += [nn.MaxPool2d(kernel_size=2, stride=2, ceil_mode=True)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
if batch_norm:
layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)]
else:
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = v
pool5 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
conv6 = nn.Conv2d(512, 1024, kernel_size=3, padding=6, dilation=6)
conv7 = nn.Conv2d(1024, 1024, kernel_size=1)
layers += [pool5, conv6,
nn.ReLU(inplace=True), conv7, nn.ReLU(inplace=True)]
return layers
if __name__ == "__main__":
base = {
'300': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'C', 512, 512, 512, 'M',
512, 512, 512],
'512': [],
}
layers = vgg(base['300'], 3)
print(nn.Sequential(*layers))bacbkone网络结构
Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=True)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace)
(30): MaxPool2d(kernel_size=3, stride=1, padding=1, dilation=1, ceil_mode=False)
(31): Conv2d(512, 1024, kernel_size=(3, 3), stride=(1, 1), padding=(6, 6), dilation=(6, 6))
(32): ReLU(inplace)
(33): Conv2d(1024, 1024, kernel_size=(1, 1), stride=(1, 1))
(34): ReLU(inplace)
)为了能更直观的表达,我把原代码改为如下,其中cfg表示配置文件的输出channels,M表示MaxPool,C表示MaxPool需要ceil_true=True;i表示最开始的输入channels,batch_norm表示需不需要做BatchNorm。
修改后的代码
from torch import nn
from torch.cuda.amp import autocast
from utils.L2Norm import L2Norm
class VggNetBackbone(nn.Module):
def __init__(self, cfg, i=3, batch_norm=False):
super(VggNetBackbone, self).__init__()
"""
cfg: channels of layer
i: nput_channels
batch_norm: whether to use BN
"""
in_channels = i
v = 0
conv1_1 = nn.Conv2d(in_channels=in_channels, out_channels=cfg[v], kernel_size=3, stride=1, padding=1)
batch_norm1_1 = nn.BatchNorm2d(cfg[v])
v += 1
conv1_2 = nn.Conv2d(in_channels=cfg[v - 1], out_channels=cfg[v], kernel_size=3, stride=1, padding=1)
batch_norm1_2 = nn.BatchNorm2d(cfg[v])
v += 1
pool1 = nn.MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
v += 1
conv2_1 = nn.Conv2d(in_channels=cfg[v - 2], out_channels=cfg[v], kernel_size=3, stride=1, padding=1)
batch_norm2_1 = nn.BatchNorm2d(cfg[v])
v += 1
conv2_2 = nn.Conv2d(in_channels=cfg[v - 1], out_channels=cfg[v], kernel_size=3, stride=1, padding=1)
batch_norm2_2 = nn.BatchNorm2d(cfg[v])
v += 1
pool2 = nn.MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
v += 1
conv3_1 = nn.Conv2d(in_channels=cfg[v - 2], out_channels=cfg[v], kernel_size=3, stride=1, padding=1)
batch_norm3_1 = nn.BatchNorm2d(cfg[v])
v += 1
conv3_2 = nn.Conv2d(in_channels=cfg[v - 1], out_channels=cfg[v], kernel_size=3, stride=1, padding=1)
batch_norm3_2 = nn.BatchNorm2d(cfg[v])
v += 1
conv3_3 = nn.Conv2d(in_channels=cfg[v - 1], out_channels=cfg[v], kernel_size=3, stride=1, padding=1)
batch_norm3_3 = nn.BatchNorm2d(cfg[v])
v += 1
pool3 = nn.MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=True)
v += 1
conv4_1 = nn.Conv2d(in_channels=cfg[v - 2], out_channels=cfg[v], kernel_size=3, stride=1, padding=1)
batch_norm4_1 = nn.BatchNorm2d(cfg[v])
v += 1
conv4_2 = nn.Conv2d(in_channels=cfg[v - 1], out_channels=cfg[v], kernel_size=3, stride=1, padding=1)
batch_norm4_2 = nn.BatchNorm2d(cfg[v])
v += 1
conv4_3 = nn.Conv2d(in_channels=cfg[v - 1], out_channels=cfg[v], kernel_size=3, stride=1, padding=1)
batch_norm4_3 = nn.BatchNorm2d(cfg[v])
v += 1
pool4 = nn.MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
v += 1
conv5_1 = nn.Conv2d(in_channels=cfg[v - 2], out_channels=cfg[v], kernel_size=3, stride=1, padding=1)
batch_norm5_1 = nn.BatchNorm2d(cfg[v])
v += 1
conv5_2 = nn.Conv2d(in_channels=cfg[v - 1], out_channels=cfg[v], kernel_size=3, stride=1, padding=1)
batch_norm5_2 = nn.BatchNorm2d(cfg[v])
v += 1
conv5_3 = nn.Conv2d(in_channels=cfg[v - 1], out_channels=cfg[v], kernel_size=3, stride=1, padding=1)
batch_norm5_3 = nn.BatchNorm2d(cfg[v])
pool5 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1, dilation=1, ceil_mode=False)
conv6 = nn.Conv2d(in_channels=512, out_channels=1024, kernel_size=3, stride=1, padding=6, dilation=6)
batch_norm6 = nn.BatchNorm2d(1024)
conv7 = nn.Conv2d(in_channels=1024, out_channels=1024, kernel_size=1, stride=1)
batch_norm7 = nn.BatchNorm2d(1024)
relu = nn.ReLU()
if batch_norm:
self.block1_1 = nn.Sequential(conv1_1, batch_norm1_1, relu)
self.block1_2 = nn.Sequential(conv1_2, batch_norm1_2, relu)
self.pool1 = nn.Sequential(pool1)
self.block2_1 = nn.Sequential(conv2_1, batch_norm2_1, relu)
self.block2_2 = nn.Sequential(conv2_2, batch_norm2_2, relu)
self.pool2 = nn.Sequential(pool2)
self.block3_1 = nn.Sequential(conv3_1, batch_norm3_1, relu)
self.block3_2 = nn.Sequential(conv3_2, batch_norm3_2, relu)
self.block3_3 = nn.Sequential(conv3_3, batch_norm3_3, relu)
self.pool3 = nn.Sequential(pool3)
self.block4_1 = nn.Sequential(conv4_1, batch_norm4_1, relu)
self.block4_2 = nn.Sequential(conv4_2, batch_norm4_2, relu)
self.block4_3 = nn.Sequential(conv4_3, batch_norm4_3, relu)
self.L2Norm = nn.Sequential(L2Norm(512, 20))
self.pool4 = nn.Sequential(pool4)
self.block5_1 = nn.Sequential(conv5_1, batch_norm5_1, relu)
self.block5_2 = nn.Sequential(conv5_2, batch_norm5_2, relu)
self.block5_3 = nn.Sequential(conv5_3, batch_norm5_3, relu)
self.pool5 = nn.Sequential(pool5)
self.block6 = nn.Sequential(conv6, batch_norm6, relu)
self.block7 = nn.Sequential(conv7, batch_norm7, relu)
else:
self.block1_1 = nn.Sequential(conv1_1, relu)
self.block1_2 = nn.Sequential(conv1_2, relu)
self.pool1 = nn.Sequential(pool1)
self.block2_1 = nn.Sequential(conv2_1, relu)
self.block2_2 = nn.Sequential(conv2_2, relu)
self.pool2 = nn.Sequential(pool2)
self.block3_1 = nn.Sequential(conv3_1, relu)
self.block3_2 = nn.Sequential(conv3_2, relu)
self.block3_3 = nn.Sequential(conv3_3, relu)
self.pool3 = nn.Sequential(pool3)
self.block4_1 = nn.Sequential(conv4_1, relu)
self.block4_2 = nn.Sequential(conv4_2, relu)
self.block4_3 = nn.Sequential(conv4_3, relu)
self.L2Norm = nn.Sequential(L2Norm(512, 20))
self.pool4 = nn.Sequential(pool4)
self.block5_1 = nn.Sequential(conv5_1, relu)
self.block5_2 = nn.Sequential(conv5_2, relu)
self.block5_3 = nn.Sequential(conv5_3, relu)
self.pool5 = nn.Sequential(pool5)
self.block6 = nn.Sequential(conv6, relu)
self.block7 = nn.Sequential(conv7, relu)
@autocast()
def forward(self, x):
x = self.block1_1(x)
x = self.block1_2(x)
x = self.pool1(x)
x = self.block2_1(x)
x = self.block2_2(x)
x = self.pool2(x)
x = self.block3_1(x)
x = self.block3_2(x)
x = self.block3_3(x)
x = self.pool3(x)
x = self.block4_1(x)
x = self.block4_2(x)
out1 = self.block4_3(x)
x = self.L2Norm(out1)
x = self.pool4(x)
x = self.block5_1(x)
x = self.block5_2(x)
x = self.block5_3(x)
x = self.pool5(x)
x = self.block6(x)
out2 = self.block7(x)
return [out1, out2]
if __name__ == "__main__":
backbone = {
'300': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'C', 512, 512, 512, 'M', 512, 512, 512],
'512': [],
}
layers_1 = VggNetBackbone(backbone['300'], 3, batch_norm=True)
print(layers_1)
layers_2 = VggNetBackbone(backbone['300'], 3)
print(layers_2)修改后的bacbkone网络结构
VggNetBackbone(
(block1_1): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(block1_2): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(pool1): Sequential(
(0): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(block2_1): Sequential(
(0): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(block2_2): Sequential(
(0): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(pool2): Sequential(
(0): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(block3_1): Sequential(
(0): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(block3_2): Sequential(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(block3_3): Sequential(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(pool3): Sequential(
(0): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=True)
)
(block4_1): Sequential(
(0): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(block4_2): Sequential(
(0): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(block4_3): Sequential(
(0): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(L2Norm): Sequential(
(0): L2Norm()
)
(pool4): Sequential(
(0): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(block5_1): Sequential(
(0): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(block5_2): Sequential(
(0): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(block5_3): Sequential(
(0): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(pool5): Sequential(
(0): MaxPool2d(kernel_size=3, stride=1, padding=1, dilation=1, ceil_mode=False)
)
(block6): Sequential(
(0): Conv2d(512, 1024, kernel_size=(3, 3), stride=(1, 1), padding=(6, 6), dilation=(6, 6))
(1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(block7): Sequential(
(0): Conv2d(1024, 1024, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
)
VggNetBackbone(
(block1_1): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
)
(block1_2): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
)
(pool1): Sequential(
(0): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(block2_1): Sequential(
(0): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
)
(block2_2): Sequential(
(0): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
)
(pool2): Sequential(
(0): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(block3_1): Sequential(
(0): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
)
(block3_2): Sequential(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
)
(block3_3): Sequential(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
)
(pool3): Sequential(
(0): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=True)
)
(block4_1): Sequential(
(0): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
)
(block4_2): Sequential(
(0): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
)
(block4_3): Sequential(
(0): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
)
(L2Norm): Sequential(
(0): L2Norm()
)
(pool4): Sequential(
(0): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(block5_1): Sequential(
(0): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
)
(block5_2): Sequential(
(0): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
)
(block5_3): Sequential(
(0): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
)
(pool5): Sequential(
(0): MaxPool2d(kernel_size=3, stride=1, padding=1, dilation=1, ceil_mode=False)
)
(block6): Sequential(
(0): Conv2d(512, 1024, kernel_size=(3, 3), stride=(1, 1), padding=(6, 6), dilation=(6, 6))
(1): ReLU()
)
(block7): Sequential(
(0): Conv2d(1024, 1024, kernel_size=(1, 1), stride=(1, 1))
(1): ReLU()
)
)
Process finished with exit code 0Neck(Extra Layers)
SSD的Neck(Extra Layers)部分如图4,其分析如图5,其中Conv8_2,Conv9_2,Conv10_2,Conv11_2的输出特征图为Head输入所需的特征图。


原代码
def add_extras(cfg, i, batch_norm=False):
# Extra layers added to VGG for feature scaling
layers = []
in_channels = i
flag = False
for k, v in enumerate(cfg):
if in_channels != 'S':
if v == 'S':
layers += [nn.Conv2d(in_channels, cfg[k + 1],
kernel_size=(1, 3)[flag], stride=2, padding=1)]
else:
layers += [nn.Conv2d(in_channels, v, kernel_size=(1, 3)[flag])]
flag = not flag
in_channels = v
return layers
if __name__ == "__main__":
extras = {
'300': [256, 'S', 512, 128, 'S', 256, 128, 256, 128, 256],
'512': [],
}
layers = add_extras(extras['300'], 1024)
print(nn.Sequential(*layers))Neck网络结构
Sequential(
(0): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1))
(1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(2): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1))
(3): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(4): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1))
(5): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1))
(6): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1))
(7): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1))
)修改后的代码
from torch import nn
from torch.cuda.amp import autocast
class SSDNecks(nn.Module):
def __init__(self, cfg, i, batch_norm=False):
super(SSDNecks, self).__init__()
"""
cfg: channels of layer
i: nput_channels
batch_norm: whether to use BN
"""
# 1024
in_channels = i
v = 0
conv8_1 = nn.Conv2d(in_channels=in_channels, out_channels=cfg[v], kernel_size=1, stride=1)
batch_norm8_1 = nn.BatchNorm2d(cfg[v])
v += 2
conv8_2 = nn.Conv2d(in_channels=cfg[v - 2], out_channels=cfg[v], kernel_size=3, stride=2, padding=1)
batch_norm8_2 = nn.BatchNorm2d(cfg[v])
v += 1
conv9_1 = nn.Conv2d(in_channels=cfg[v - 1], out_channels=cfg[v], kernel_size=1, stride=1, padding=0)
batch_norm9_1 = nn.BatchNorm2d(cfg[v])
v += 2
conv9_2 = nn.Conv2d(in_channels=cfg[v - 2], out_channels=cfg[v], kernel_size=3, stride=2, padding=1)
batch_norm9_2 = nn.BatchNorm2d(cfg[v])
v += 1
conv10_1 = nn.Conv2d(in_channels=cfg[v - 1], out_channels=cfg[v], kernel_size=1, stride=1, padding=0)
batch_norm10_1 = nn.BatchNorm2d(cfg[v])
v += 1
conv10_2 = nn.Conv2d(in_channels=cfg[v - 1], out_channels=cfg[v], kernel_size=3, stride=1, padding=0)
batch_norm10_2 = nn.BatchNorm2d(cfg[v])
v += 1
conv11_1 = nn.Conv2d(in_channels=cfg[v - 1], out_channels=cfg[v], kernel_size=1, stride=1, padding=0)
batch_norm11_1 = nn.BatchNorm2d(cfg[v])
v += 1
conv11_2 = nn.Conv2d(in_channels=cfg[v - 1], out_channels=cfg[v], kernel_size=3, stride=1, padding=0)
batch_norm11_2 = nn.BatchNorm2d(cfg[v])
relu = nn.ReLU()
if batch_norm:
self.block8_1 = nn.Sequential(conv8_1, batch_norm8_1, relu)
self.block8_2 = nn.Sequential(conv8_2, batch_norm8_2, relu)
self.block9_1 = nn.Sequential(conv9_1, batch_norm9_1, relu)
self.block9_2 = nn.Sequential(conv9_2, batch_norm9_2, relu)
self.block10_1 = nn.Sequential(conv10_1, batch_norm10_1, relu)
self.block10_2 = nn.Sequential(conv10_2, batch_norm10_2, relu)
self.block11_1 = nn.Sequential(conv11_1, batch_norm11_1, relu)
self.block11_2 = nn.Sequential(conv11_2, batch_norm11_2, relu)
else:
self.block8_1 = nn.Sequential(conv8_1, relu)
self.block8_2 = nn.Sequential(conv8_2, relu)
self.block9_1 = nn.Sequential(conv9_1, relu)
self.block9_2 = nn.Sequential(conv9_2, relu)
self.block10_1 = nn.Sequential(conv10_1, relu)
self.block10_2 = nn.Sequential(conv10_2, relu)
self.block11_1 = nn.Sequential(conv11_1, relu)
self.block11_2 = nn.Sequential(conv11_2, relu)
@autocast()
def forward(self, x):
out8_1 = self.block8_1(x)
out8_2 = self.block8_2(out8_1)
out9_1 = self.block9_1(out8_2)
out9_2 = self.block9_2(out9_1)
out10_1 = self.block10_1(out9_2)
out10_2 = self.block10_2(out10_1)
out11_1 = self.block11_1(out10_2)
out11_2 = self.block11_2(out11_1)
return [out8_2, out9_2, out10_2, out11_2]
if __name__ == "__main__":
neck = {
'300': [256, 'S', 512, 128, 'S', 256, 128, 256, 128, 256],
'512': [],
}
neck = SSDNecks(neck['300'], 1024)
print(neck)修改后的Neck输出网络结构
SSDNecks(
(block8_1): Sequential(
(0): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1))
(1): ReLU()
)
(block8_2): Sequential(
(0): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(1): ReLU()
)
(block9_1): Sequential(
(0): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1))
(1): ReLU()
)
(block9_2): Sequential(
(0): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(1): ReLU()
)
(block10_1): Sequential(
(0): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1))
(1): ReLU()
)
(block10_2): Sequential(
(0): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1))
(1): ReLU()
)
(block11_1): Sequential(
(0): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1))
(1): ReLU()
)
(block11_2): Sequential(
(0): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1))
(1): ReLU()
)
)
Process finished with exit code 0Head(Multi-box Layers)
SSD的Head部分如图6,将之前VGG Backbone的Conv4_3,Conv7的输出,与Extral Layers的Conv8_2,Conv9_2,Conv10_2,Conv11_2的输出,作为Head(Multi-box Layers)的输入。

原代码
def multibox(vgg, extra_layers, cfg, num_classes):
loc_layers = []
conf_layers = []
vgg_source = [21, -2]
for k, v in enumerate(vgg_source):
loc_layers += [nn.Conv2d(vgg[v].out_channels,
cfg[k] * 4, kernel_size=3, padding=1)]
conf_layers += [nn.Conv2d(vgg[v].out_channels,
cfg[k] * num_classes, kernel_size=3, padding=1)]
for k, v in enumerate(extra_layers[1::2], 2):
loc_layers += [nn.Conv2d(v.out_channels, cfg[k]
* 4, kernel_size=3, padding=1)]
conf_layers += [nn.Conv2d(v.out_channels, cfg[k]
* num_classes, kernel_size=3, padding=1)]
return vgg, extra_layers, (loc_layers, conf_layers)
if __name__ == "__main__":
vgg, extra_layers, (l, c) = multibox(vgg(base['300'], 3),
add_extras(extras['300'], 1024),
[4, 6, 6, 6, 4, 4], 21)
print(nn.Sequential(*l))
print('---------------------------')
print(nn.Sequential(*c))Head网络结构
'''
loc layers:
'''
Sequential(
(0): Conv2d(512, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): Conv2d(1024, 24, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(2): Conv2d(512, 24, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): Conv2d(256, 24, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): Conv2d(256, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(5): Conv2d(256, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
---------------------------
'''
conf layers:
'''
Sequential(
(0): Conv2d(512, 84, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): Conv2d(1024, 126, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(2): Conv2d(512, 126, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): Conv2d(256, 126, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): Conv2d(256, 84, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(5): Conv2d(256, 84, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)修改后的代码
import torch
from torch import nn
from torch.cuda.amp import autocast
from models.detection.necks.SSDNecks import SSDNecks
from models.detection.backbones.VggNetBackbone import VggNetBackbone
class confHeads(nn.Module):
def __init__(self, vgg, neck, cfg, num_classes, batch_norm=False):
super(confHeads, self).__init__()
self.num_classes = num_classes
v = 0
conf1 = nn.Conv2d(in_channels=vgg.block4_3[0].out_channels, out_channels=cfg[v] * num_classes, kernel_size=3,
stride=1,
padding=1)
v += 1
conf2 = nn.Conv2d(in_channels=vgg.block7[0].out_channels, out_channels=cfg[v] * num_classes, kernel_size=3,
stride=1,
padding=1)
v += 1
conf3 = nn.Conv2d(in_channels=neck.block8_2[0].out_channels, out_channels=cfg[v] * num_classes, kernel_size=3,
stride=1,
padding=1)
v += 1
conf4 = nn.Conv2d(in_channels=neck.block9_2[0].out_channels, out_channels=cfg[v] * num_classes, kernel_size=3,
stride=1,
padding=1)
v += 1
conf5 = nn.Conv2d(in_channels=neck.block10_2[0].out_channels, out_channels=cfg[v] * num_classes, kernel_size=3,
stride=1,
padding=1)
v += 1
conf6 = nn.Conv2d(in_channels=neck.block11_2[0].out_channels, out_channels=cfg[v] * num_classes, kernel_size=3,
stride=1,
padding=1)
relu = nn.ReLU()
self.conf1 = nn.Sequential(conf1, relu)
self.conf2 = nn.Sequential(conf2, relu)
self.conf3 = nn.Sequential(conf3, relu)
self.conf4 = nn.Sequential(conf4, relu)
self.conf5 = nn.Sequential(conf5, relu)
self.conf6 = nn.Sequential(conf6, relu)
@autocast()
def forward(self, x):
out1 = self.conf1(x[0])
out1 = out1.permute(0, 2, 3, 1).contiguous()
out2 = self.conf2(x[1])
out2 = out2.permute(0, 2, 3, 1).contiguous()
out3 = self.conf3(x[2])
out3 = out3.permute(0, 2, 3, 1).contiguous()
out4 = self.conf4(x[3])
out4 = out4.permute(0, 2, 3, 1).contiguous()
out5 = self.conf5(x[4])
out5 = out5.permute(0, 2, 3, 1).contiguous()
out6 = self.conf6(x[5])
out6 = out6.permute(0, 2, 3, 1).contiguous()
del x
out = [out1, out2, out3, out4, out5, out6]
del out1, out2, out3, out4, out5, out6
conf = torch.cat([o.view(o.size(0), -1, self.num_classes) for o in out], dim=1)
del out
return conf
class locHeads(nn.Module):
def __init__(self, vgg, neck, cfg, batch_norm=False):
super(locHeads, self).__init__()
v = 0
loc1 = nn.Conv2d(in_channels=vgg.block4_3[0].out_channels, out_channels=cfg[v] * 4, kernel_size=3,
stride=1,
padding=1)
v += 1
loc2 = nn.Conv2d(in_channels=vgg.block7[0].out_channels, out_channels=cfg[v] * 4, kernel_size=3, stride=1,
padding=1)
v += 1
loc3 = nn.Conv2d(in_channels=neck.block8_2[0].out_channels, out_channels=cfg[v] * 4, kernel_size=3,
stride=1,
padding=1)
v += 1
loc4 = nn.Conv2d(in_channels=neck.block9_2[0].out_channels, out_channels=cfg[v] * 4, kernel_size=3,
stride=1,
padding=1)
v += 1
loc5 = nn.Conv2d(in_channels=neck.block10_2[0].out_channels, out_channels=cfg[v] * 4, kernel_size=3,
stride=1,
padding=1)
v += 1
loc6 = nn.Conv2d(in_channels=neck.block11_2[0].out_channels, out_channels=cfg[v] * 4, kernel_size=3,
stride=1,
padding=1)
relu = nn.ReLU()
self.loc1 = nn.Sequential(loc1, relu)
self.loc2 = nn.Sequential(loc2, relu)
self.loc3 = nn.Sequential(loc3, relu)
self.loc4 = nn.Sequential(loc4, relu)
self.loc5 = nn.Sequential(loc5, relu)
self.loc6 = nn.Sequential(loc6, relu)
@autocast()
def forward(self, x):
out1 = self.loc1(x[0])
out1 = out1.permute(0, 2, 3, 1).contiguous()
out2 = self.loc2(x[1])
out2 = out2.permute(0, 2, 3, 1).contiguous()
out3 = self.loc3(x[2])
out3 = out3.permute(0, 2, 3, 1).contiguous()
out4 = self.loc4(x[3])
out4 = out4.permute(0, 2, 3, 1).contiguous()
out5 = self.loc5(x[4])
out5 = out5.permute(0, 2, 3, 1).contiguous()
out6 = self.loc6(x[5])
out6 = out6.permute(0, 2, 3, 1).contiguous()
del x
out = [out1, out2, out3, out4, out5, out6]
del out1, out2, out3, out4, out5, out6
loc = torch.cat([o.view(o.size(0), -1, 4) for o in out], dim=1)
del out
return loc
if __name__ == "__main__":
backbone = {
'300': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'C', 512, 512, 512, 'M', 512, 512, 512],
'512': [],
}
neck = {
'300': [256, 'S', 512, 128, 'S', 256, 128, 256, 128, 256],
'512': [],
}
head = {
'300': [4, 6, 6, 6, 4, 4],
'512': [],
}
backbones_1 = VggNetBackbone(backbone['300'], 3, batch_norm=True)
necks_1 = SSDNecks(neck['300'], 1024, batch_norm=True)
loc_head = locHeads(backbones_1, necks_1, head['300'], batch_norm=True)
print(loc_head)
backbones_2 = VggNetBackbone(backbone['300'], 3)
necks_2 = SSDNecks(neck['300'], 1024)
conf_head = confHeads(backbones_2, necks_2, head['300'], 21)
print(conf_head)修改后的Head网络结构
locHeads(
(loc1): Sequential(
(0): Conv2d(512, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
)
(loc2): Sequential(
(0): Conv2d(1024, 24, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
)
(loc3): Sequential(
(0): Conv2d(512, 24, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
)
(loc4): Sequential(
(0): Conv2d(256, 24, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
)
(loc5): Sequential(
(0): Conv2d(256, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
)
(loc6): Sequential(
(0): Conv2d(256, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
)
)
confHeads(
(conf1): Sequential(
(0): Conv2d(512, 84, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
)
(conf2): Sequential(
(0): Conv2d(1024, 126, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
)
(conf3): Sequential(
(0): Conv2d(512, 126, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
)
(conf4): Sequential(
(0): Conv2d(256, 126, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
)
(conf5): Sequential(
(0): Conv2d(256, 84, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
)
(conf6): Sequential(
(0): Conv2d(256, 84, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
)
)
Process finished with exit code 0下一话