目录
前言
Pandas处理字符文本等数据技术以及函数设计迭代的过程已经很长了,处理方法也多。很多时候我们是通过一系列需求或者想要实现的一个效果去搜寻答案和代码。或者是当获取到了这个实现功能的函数却不知道这个函数的使用方法和参数调整,这是实际开发常常遇到的问题,也是比较头疼。但是如果能够对Pandas对整个数据类型体系处理方法有个明确的认知和大体处理操作,那么久可以节省很多我们盲目搜索答案的时间,大大加快我们分析数据的效率。
此篇文章依旧紧接着上篇文章的内容,常用的处理方法已经将近讲述到过半了。处理字符文本的Pandas数据分析系列应该会随后完结。
Pandas数据分析系列专栏已经更新了很久了,基本覆盖到使用pandas处理日常业务以及常规的数据分析方方面面的问题。从基础的数据结构逐步入门到处理各类数据以及专业的pandas常用函数讲解都花费了大量时间和心思创作,如果大家有需要从事数据分析或者大数据开发的朋友推荐订阅专栏,将在第一时间学习到Pandas数据分析最实用常用的知识。此篇博客篇幅较长,涉及到处理文本数据(str/object)等各类操作,值得细读实践一番,我会将Pandas的精华部分挑出细讲实践。博主会长期维护博文,有错误或者疑惑可以在评论区指出,感谢大家的支持。
一、子串提取
提取匹配首位子串
在版本0.23之前,extract方法的参数扩展默认为False。当expand=False时,expand根据subject和正则表达式模式返回Series、Index或DataFrame。当expand=True时,它总是返回一个数据帧,从用户的角度来看,该数据帧更一致,更容易混淆。自0.23.0版以来,expand=True一直是默认值。
extract方法接受具有至少一个正则表达式。提取包含多个组的正则表达式将返回每个组一列的DataFrame。
pd.Series(
["a1", "b2", "c3"],
dtype="string",
).str.extract(r"([ab])(\d)", expand=False)
不匹配的元素返回一个填充有NaN的行。因此,一系列杂乱的字符串可以被“转换”成一个类似的索引序列或DataFrame,其中包含清理过的或更有用的字符串,而不需要get()来访问元组或re.match对象。结果的数据类型始终为object,即使未找到匹配项且结果仅包含NaN。
分组时列名设置:
pd.Series(["a1", "b2", "c3"], dtype="string").str.extract(
r"(?P<letter>[ab])(?P<digit>\d)", expand=False
) 
可选分组:
pd.Series(
["a1", "b2", "3"],
dtype="string",
).str.extract(r"([ab])?(\d)", expand=False) 
正则表达式中的任何捕获组名称都将用于列名;否则将使用捕获组编号。
如果expand=True,提取一组正则表达式将返回一列DataFrame。
pd.Series(["a1", "b2", "c3"], dtype="string").str.extract(r"[ab](\d)", expand=True) 
如果expand=False,则返回为Series。
pd.Series(["a1", "b2", "c3"], dtype="string").str.extract(r"[ab](\d)", expand=False) 
如果expand=True,则使用正则表达式调用具有一个捕获组的索引将返回一个具有一列的DataFrame。
s = pd.Series(["a1", "b2", "c3"], ["A11", "B22", "C33"], dtype="string")
s.index.str.extract("(?P<letter>[a-zA-Z])", expand=True) 
如果expand=False,则返回索引。
s.index.str.extract("(?P<letter>[a-zA-Z])", expand=False) ![]()
如果expand=True,则使用具有多个捕获组的正则表达式调用索引将返回DataFrame。
s.index.str.extract("(?P<letter>[a-zA-Z])([0-9]+)", expand=True) 
如果expand=False,则会引发ValueError。
s.index.str.extract("(?P<letter>[a-zA-Z])([0-9]+)", expand=False) ![]()
下表总结了extract(expand=False)的情况(第一列中输入主题,第一行中regex中的组数)
| 1 group | >1 group | |
| Index | Index | ValueError |
| Series | Series | DataFrame |
提取所有匹配项(extractall)
与extract(仅返回第一个匹配)不同:
s = pd.Series(["a1a2", "b1", "c1"], index=["A", "B", "C"], dtype="string")
s 
two_groups = "(?P<letter>[a-z])(?P<digit>[0-9])"
s.str.extract(two_groups, expand=True) 
extractall方法返回每个匹配项。extractall的结果总是一个DataFrame,其行上有MultiIndex。多重索引的最后一级名为match,表示主题中的顺序。
s.str.extractall(two_groups) 
当Series中的每个subject中正好有一个匹配时,extractall(pat).xs(0,level='match')与extract(pat)将得到一样的结果:
s = pd.Series(["a3", "b3", "c2"], dtype="string")
s
extract_result = s.str.extract(two_groups, expand=True)
extract_result 
extractall_result = s.str.extractall(two_groups)
extractall_result
extractall_result.xs(0, level="match") 
索引Index还支持.str.extractall。它返回一个DataFrame,其结果与带有默认索引(从0开始)的Series.str.extractall相同。
pd.Index(["a1a2", "b1", "c1"]).str.extractall(two_groups)
二、全局字符匹配
contain检验
使用contain函数可以检测series或者dataframe中是否包含检测字符:
pattern = r"[0-9][a-z]"
pd.Series(
["1", "2", "3a", "3b", "03c", "4dx"],
dtype="string",
).str.contains(pattern)

match元素匹配
pd.Series(
["1", "2", "3a", "3b", "03c", "4dx"],
dtype="string",
).str.match(pattern) 
match、fullmatch和contains之间的区别在于严格性:
- fullmatch测试整个字符串是否与正则表达式匹配;
- match是否存在从字符串的第一个字符开始的正则表达式的匹配;
- contain在字符串中的任何位置是否存在正则表达式的匹配。
这三种匹配模式的re包中的相应函数为re。完全匹配,重新。匹配,再重新。搜索。
match、fullmatch、contains、StartWith和endswith等方法采用额外的na参数,因此丢失的值可以被视为True或False:
s4 = pd.Series(
["A", "B", "C", "Aaba", "Baca", np.nan, "CABA", "dog", "cat"], dtype="string"
)
s4.str.contains("A", na=False) 
创建指标变量
可以从字符串列中提取虚拟变量。例如,如果它们由“|”分隔:
s = pd.Series(["a", "a|b", np.nan, "a|c"], dtype="string")
s.str.get_dummies(sep="|") 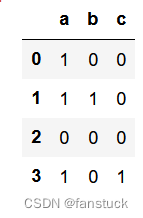
字符串索引还支持get_dummies,它返回多索引。
idx = pd.Index(["a", "a|b", np.nan, "a|c"])
idx.str.get_dummies(sep="|") 
以上我们的处理文本数据(str/object)各类操作系列文章就讲完了。博主会长期维护博文,有错误或者疑惑可以在评论区指出,感谢大家的支持。
点关注,防走丢,如有纰漏之处,请留言指教,非常感谢
以上就是本期全部内容。我是fanstuck ,有问题大家随时留言讨论 ,我们下期见。