典型相关分析(Canonical Correlation Analysis)是一种分析多变量与多变量之间关系的统计方法。比如我们现在有自变量 ( x 1 , x 2 , x 3 ) = ( (x_1,x_2,x_3)=( (x1,x2,x3)=(身高,体重,肺活量 ) ) ),因变量 ( y 1 , y 2 ) = ( 50 (y_1,y_2)=(50 (y1,y2)=(50米成绩,立定跳远成绩 ) ) ),我们想要研究自变量对因变量的作用。如果分别求取 x i x_i xi对 y j y_j yj的相关系数,在变量个数较多时比较麻烦。CCA与主成分分析的思想(见上一篇文章)类似,它利用原变量的线性组合来简化分析。
基本思想
设 n n n维自变量 X = ( x 1 , x 2 , . . . , x n ) X=(x_1,x_2,...,x_n) X=(x1,x2,...,xn), m m m维因变量 Y = ( y 1 , y 2 , . . . , y m ) Y=(y_1,y_2,...,y_m) Y=(y1,y2,...,ym),我们想确定若干对典型相关变量 ( U i , V i ) (U_i,V_i) (Ui,Vi),使得
U i = a i 1 x 1 + a i 2 x 2 + . . . + a i n x n U_i=a_{i1}x_1+a_{i2}x_2+...+a_{in}x_n Ui=ai1x1+ai2x2+...+ainxn
V i = b i 1 y 1 + b i 2 y 2 + . . . + b i m y m V_i=b_{i1}y_1+b_{i2}y_2+...+b_{im}y_m Vi=bi1y1+bi2y2+...+bimym
之间有最大的相关系数。此外,不同组的典型相关变量对之间应该不相关,即
ρ ( U i , V j ) = 0 ( i ≠ j ) . \rho(U_i,V_j)=0(i \neq j). ρ(Ui,Vj)=0(i=j).
约定 U i , V i U_i,V_i Ui,Vi均为标准化变量,即
v a r ( U i ) = v a r ( V i ) = 1 , var(U_i)=var(V_i)=1, var(Ui)=var(Vi)=1,其中 v a r ( X ) var(X) var(X)为 X X X的方差。
求解过程
1. 设 X 为标准化后的自变量样本矩阵 ( x 11 ⋯ x 1 t ⋮ ⋮ x n 1 ⋯ x n t ) , 其中 n 为自变量维数 , t 为样本数 ; 1.设X为标准化后的自变量样本矩阵\begin{pmatrix}x_{11} &\cdots &x_{1t} \\ \vdots & & \vdots \\ x_{n1} & \cdots & x_{nt}\end{pmatrix},其中n为自变量维数,t为样本数; 1.设X为标准化后的自变量样本矩阵⎝
⎛x11⋮xn1⋯⋯x1t⋮xnt⎠
⎞,其中n为自变量维数,t为样本数;
2. 设 Y 为标准化后的因变量样本矩阵 ( y 11 ⋯ y 1 t ⋮ ⋮ y m 1 ⋯ y m t ) , 其中 m 为因变量维数 , t 为样本数 ; 2.设Y为标准化后的因变量样本矩阵\begin{pmatrix}y_{11} &\cdots &y_{1t} \\ \vdots & & \vdots \\ y_{m1} & \cdots & y_{mt}\end{pmatrix},其中m为因变量维数,t为样本数; 2.设Y为标准化后的因变量样本矩阵⎝
⎛y11⋮ym1⋯⋯y1t⋮ymt⎠
⎞,其中m为因变量维数,t为样本数;
3. 计算 A = ( X Y ) 的协方差矩阵 C o v ( A ) ; 3.计算A=\begin{pmatrix}X\\ Y \end{pmatrix}的协方差矩阵Cov(A); 3.计算A=(XY)的协方差矩阵Cov(A);
4. 设 C o v ( A ) = ( R 11 R 12 R 21 R 22 ) , 其中 R 11 为 n × n 矩阵, R 22 为 m × m 矩阵, R 12 和 R 21 分别为 n × m 和 m × n 矩阵 ; 4.设Cov(A)=\begin{pmatrix}R_{11} & R_{12} \\ R_{21} & R_{22}\end{pmatrix},其中R_{11}为n\times n 矩阵,R_{22}为m \times m 矩阵,R_{12}和R_{21}分别为n \times m 和 m \times n 矩阵; 4.设Cov(A)=(R11R21R12R22),其中R11为n×n矩阵,R22为m×m矩阵,R12和R21分别为n×m和m×n矩阵;
5. 令 M = R 11 − 1 R 12 R 22 − 1 R 21 , 计算 M 的所有正特征值 λ 1 , λ 2 , . . . , λ s ( 默认已经从大到小排序 ) ; 5.令M=R_{11}^{-1}R_{12}R_{22}^{-1}R_{21},计算M的所有正特征值\lambda_1,\lambda_2,...,\lambda_s(默认已经从大到小排序); 5.令M=R11−1R12R22−1R21,计算M的所有正特征值λ1,λ2,...,λs(默认已经从大到小排序);
6. 设 α i 为 M 的对应特征值 λ i 的特征向量, k = 1 / α i T R 11 α i , 将 α i 乘以 k ; 6.设\pmb \alpha_i为M的对应特征值\lambda_i的特征向量,k=1/\sqrt{\pmb \alpha_i^TR_{11}\pmb\alpha_i},将\pmb \alpha_i 乘以k; 6.设ααi为M的对应特征值λi的特征向量,k=1/ααiTR11ααi,将ααi乘以k;
7. 令 β i = R 22 − 1 R 21 α i / ρ i , 其中 ρ i = λ i 即为第 i 对典型变量的相关系数 ; 7.令\pmb \beta_i=R_{22}^{-1}R_{21}\pmb\alpha_i/\rho_i,其中\rho_i=\sqrt\lambda_i即为第i对典型变量的相关系数; 7.令ββi=R22−1R21ααi/ρi,其中ρi=λi即为第i对典型变量的相关系数;
8. α i , β i 即为自变量和因变量各个变量前的系数 ( 已经标准化 ) . 8.\pmb \alpha_i,\pmb\beta_i即为自变量和因变量各个变量前的系数(已经标准化). 8.ααi,ββi即为自变量和因变量各个变量前的系数(已经标准化).
说明:
( 1 ) (1) (1)在第 4 4 4步中, R i j R_{ij} Rij代表协方差矩阵, 1 1 1为自变量, 2 2 2为因变量;
( 2 ) (2) (2)第 6 6 6步将特征向量乘以 k k k是为了标准化典型变量(注意是直接乘在 α i \pmb \alpha_i ααi上的)。
经过上述过程,我们求出了三个我们关心的参数: α i , β i 和 ρ i ( i = 1 , 2 , . . . , s ) \pmb \alpha_i,\pmb \beta_i和\rho_i(i=1,2,...,s) ααi,ββi和ρi(i=1,2,...,s).
证明过程很多资料都已经给出了(见最后参考材料部分),这里不再证明。
python实现
这里采用参考材料3(ppt)中的一个例子,要分析 x 1 , x 2 , x 3 x_1,x_2,x_3 x1,x2,x3与 y 1 , y 2 , y 3 y_1,y_2,y_3 y1,y2,y3的关系,下面我们用python来实现一下:
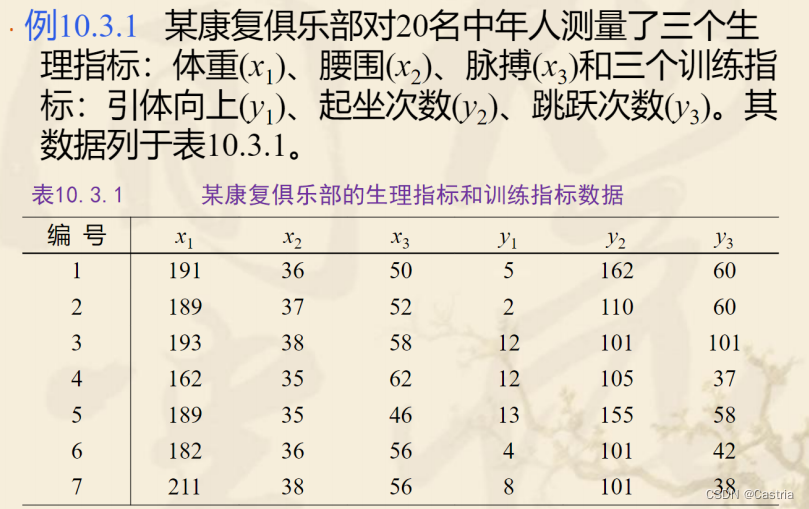
样本一共20组,代码中再给出。
from math import sqrt
import numpy as np
class CCA:
'''
# 说明
该类用于典型相关分析。
# 参数
x_dataset 自变量数据,以[样本1, 样本2, ..., 样本t] 给出。
y_dataset 因变量数据,以[样本1, 样本2, ..., 样本t] 给出。
x_dataset 和 y_dataset 的样本应该一一对应。(第i个自变量决定第i个因变量)
'''
def __init__(self, x_dataset, y_dataset):
# 需要对数据转置一下,才能跟上文对上
self.x_dataset = np.array(x_dataset, dtype = 'float64').T
self.y_dataset = np.array(y_dataset, dtype = 'float64').T
'''
结果以三元组(rho, alpha, beta)形式给出:
- rho: 典型变量的相关系数
- alpha: 自变量系数
- beta: 因变量系数
'''
def fit(self):
A = []
for sample in self.x_dataset:
A.append(list(sample))
for sample in self.y_dataset:
A.append(list(sample))
# 构造上面提到的A矩阵
A = np.array(A, dtype = 'float64')
# 标准化: 减去每行均值再除以标准差
for i in range(A.shape[0]):
avg = np.mean(A[i])
std = np.std(A[i])
A[i] = (A[i] - avg) / std
# bias = True 即计算时不采用对方差的无偏修正(除以n-1,样本方差)
# 这里只是为了跟ppt里的数据对上,实际可以取消这个可选参数
Cov = np.cov(A, bias = True)
n = self.x_dataset.shape[0]
R_11 = np.matrix(Cov[:n, :n])
R_12 = np.matrix(Cov[:n, n:])
R_21 = np.matrix(Cov[n:, :n])
R_22 = np.matrix(Cov[n:, n:])
M = np.linalg.inv(R_11) * R_12 * np.linalg.inv(R_22) * R_21
N = np.linalg.inv(R_22) * R_21 * np.linalg.inv(R_11) * R_12
eig1, vector1 = np.linalg.eig(M)
data = []
for i in range(len(eig1)):
# 若为0(精度误差,改为"绝对值小于一个很小的值")
if abs(eig1[i]) < 1e-10:
continue
# 下面变量与上面步骤中的意义相同
rho = np.round(sqrt(eig1[i]), decimals = 5)
alpha = np.round(vector1[:, i], decimals = 5)
k = 1 / (alpha.T * R_11 * alpha)
alpha *= sqrt(k)
beta = np.round(np.linalg.inv(R_22) * R_21 * alpha / rho, decimals = 5)
# 三元组分别为相关系数, 自变量系数, 因变量系数
data.append((rho, alpha, beta))
data.sort(key = lambda x: x[0], reverse = True)
return data
结果:
# 为了便于观察做了格式调整
[
(0.79561, # 第一对典型变量
array([[ 0.7753969 ],[-1.5793479 ],[ 0.05911508]]), # 自变量系数(第一对)
array([[ 0.3495 ],[ 1.05401],[-0.71642]])), # 因变量系数(第一对)
(0.20056, # 第二对
array([[-1.88437283],[ 1.18065335],[-0.23110043]]),
array([[-0.37555],[ 0.12347],[ 1.06216]])),
(0.07257, # 第三对
array([[-0.19098071],[ 0.50601614],[ 1.05078388]]),
array([[-1.29659],[ 1.23682],[-0.41883]]))
]
结论:
我们得到了第一对典型变量
U 1 = 0.7754 x 1 − 1.5793 x 2 + 0.0591 x 3 U_1=0.7754x_1-1.5793x_2+0.0591x_3 U1=0.7754x1−1.5793x2+0.0591x3
V 1 = 0.3495 y 1 + 1.054 y 2 − 0.7164 y 3 V_1=0.3495y_1+1.054y_2-0.7164y_3 V1=0.3495y1+1.054y2−0.7164y3,
且它们的相关系数 ρ 1 = 0.79561 \rho_1=0.79561 ρ1=0.79561,是高度相关的。此外, x 2 x_2 x2即腰围的系数为 − 1.5793 , -1.5793, −1.5793,是绝对值最大的,说明腰围对成绩会有很大影响; x 3 x_3 x3即脉搏的系数仅为 0.059 0.059 0.059,它的贡献比较低,说明脉搏这个自变量对成绩的影响可能不太大。可以类似地分析其它结果。如果一对典型变量不足以说明,还可以取第二对 ρ 2 = 0.20056 \rho_2=0.20056 ρ2=0.20056继续分析。
参考材料
1.https://blog.csdn.net/weixin_44333889/article/details/119379776
2.https://zhuanlan.zhihu.com/p/372774724
3.https://max.book118.com/html/2019/0828/5343340333002121.shtm(这里提供该ppt的下载。)