文章目录
【图像分类】2022-RepLKNet CVPR
论文题目:Scaling up your kernels to 31x31: Revisiting large kernel design in cnns
论文链接:https://arxiv.org/abs/2203.06717
论文代码:https://github.com/MegEngine/RepLKNet
论文团队:清华大学、旷视科技
引用:
Ding X, Zhang X, Han J, et al. Scaling up your kernels to 31x31: Revisiting large kernel design in cnns[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022: 11963-11975.
Ding X , Zhang X , Zhou Y , et al. Scaling Up Your Kernels to 31x31: Revisiting Large Kernel Design in CNNs[J]. arXiv e-prints, 2022.
1. 简介
1.1 简介
CVPR22最新论文,RepVGG作者提出RepLKNet:采用31×31大kernel的CNN网络,性能超过Swin,作者在论文中提出了大kernel size卷积的4个设计准则,并设计了31x32的纯CNN结构,在图像分类和下游检测分割上超过Swin!
1.2 摘要
在图像分类、特征学习等前置任务(pretext task)以及目标检测、语义分割等下游任务(downstream task)上,卷积网络的性能不断被ViTs(vision transformer)网络超越。人们普遍认为ViTs的性能主要得益于MHSA(multi-head self-attention)机制,并为此进行了很多研究,从不同的角度对比MHSA与卷积之间的优劣。

解释VisTs与CNNs的性能差异不是这篇论文的目的,相对于研究MHSA和卷积的差异,论文则关注于ViTs与CNNs在构建长距离位置关系(long-range spatial connections)的范式上的差异。
在ViTs中,MHSA通常使用较大的感受域( ≥ 7 × 7 \ge 7\times 7 ≥7×7),每个输出都能包含较大范围的信息。
而在CNNs中,目前的做法都是通过堆叠较小( 3 × 3 3\times 3 3×3)的卷积来增大感受域,每个输出所包含信息的范围较小。
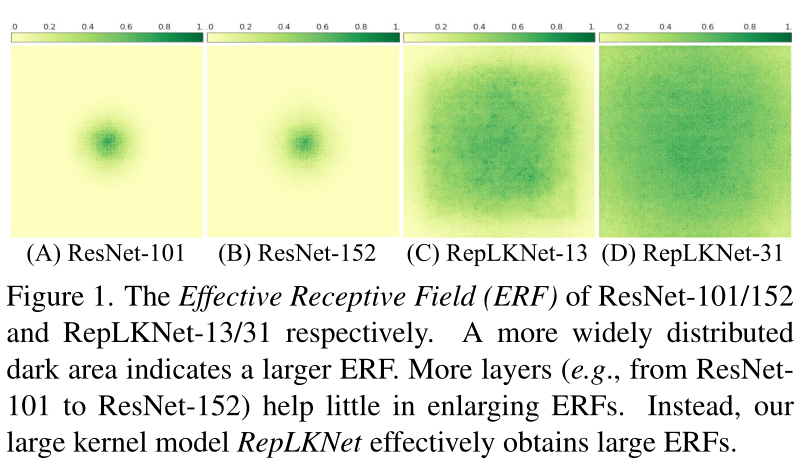
基于上面发现的感受域差异,论文尝试通过引入少量大核卷积层来弥补ViTs和CNNs之间的性能差异。借此提出了RepLKNet网络,通过重参数化的大卷积来建立空间关系。RepLKNet网络基于Swin Transformer主干进行改造,将MHSA替换为大的深度卷积,性能比ViTs网络更好。另外,论文通过图1的可视化发现,引入大卷积核相对于堆叠小卷积能显著提升有效感受域(ERFs),甚至可以跟ViTs一样能够关注形状特征。
1.3 创新点
-
我们提出了五条准则,例如应用重新参数化的大深度卷积,以设计高效、高性能的大内核CNN。根据指导原则,我们提出了RepLKNet,这是一种纯CNN架构
-
我们的研究进一步揭示,与小核CNN相比,大核CNN具有更大的有效感受野和更高的形状偏差,而不是纹理偏差。
2. 网络
2.1 网络简介
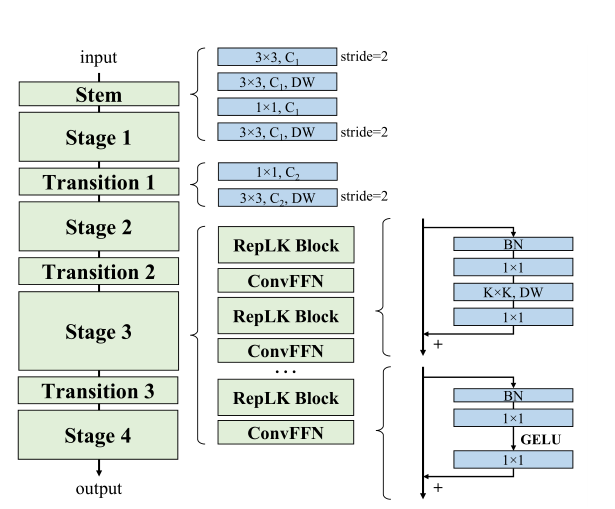
RepLKNet的结构如图4所示,各模块细节如下:
-
Stem:由于RepLKNet的主要应用是下游任务,所以需要在网络前期捕捉更多的细节。在开始的stride=2 3x3卷积下采样之后接一个3x3深度卷积来提取低维特征,之后接一个
1x1卷积和3x3深度卷积用于下采样 -
Stages 1-4:每个stage包含多个
RepLK Block,block里面包含了准则1建议的深度卷积和准则2建议的短路连接。根据准则3,每个深度卷积并行一个5x5深度卷积用于结构重参数。除了感受域和空间特征提取能力,模型的特征表达能力还和特征的维度有关。为了增加非线性和通道间的信息交流,在深度卷积前用1x1卷积增加特征维度。
参考transformers和MLPs网络使用的Feed-Forward Network(FFN),论文提出CNN风格的ConvFFN,包含短路连接、两个1x1卷积核GELU。在应用时,ConvFFN的中间特征一般为输入的4倍。参照ViT和Swin,将ConvFFN放置在每个RepLK Block后面。
-
Transition Blocks:放在stage之间,先用1x1卷积扩大特征维度,再通过两个3x3深度卷积来进行2倍下采样。
总的来说,每个stage有3个超参数:ReLK Block数 B B B,维度 C C C,以及卷积核大小 K K K所以一个RepLKNet的结构可表达为。 [ B 1 , B 2 , B 3 , B 4 ] , [ C 1 , C 2 , C 3 , C 4 ] , [ K 1 , K 2 , K 3 , K 4 ] [B_1,B_2,B_3,B_4],[C_1,C_2,C_3,C_4],[K_1,K_2,K_3,K_4] [B1,B2,B3,B4],[C1,C2,C3,C4],[K1,K2,K3,K4]
2.2 五条准则
1) 准则一:大深度卷积在实践中是有效的
large depth-wise convolutions can be efficient in practice
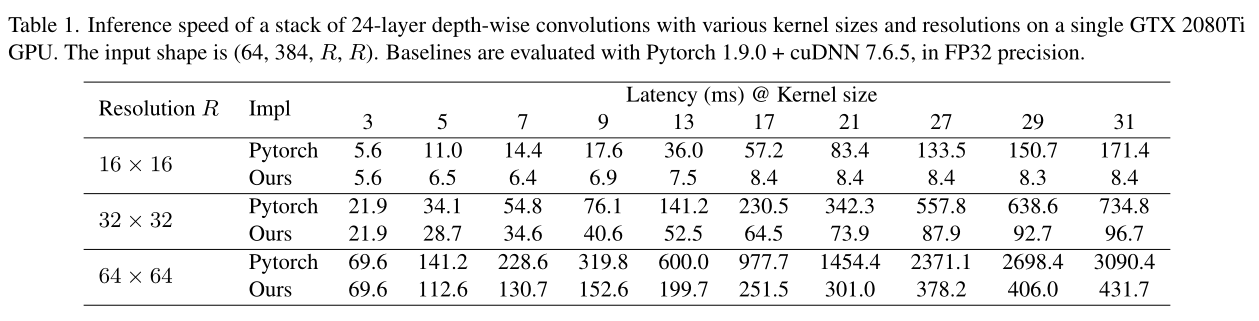
人们一般认为大卷积的计算成本很高,参数量和计算量与卷积核大小成二次方关系,而DW深度卷积恰好可以弥补这一缺点。将各stage的卷积核从 [ 3 , 3 , 3 , 3 ] [3,3,3,3] [3,3,3,3]提升到 [ 31 , 29 , 17 , 13 ] [31,29,17,13] [31,29,17,13]深度卷积,仅带来了18.6%的计算量增加和10.4%的参数量增加。
人们可能会担心,DW卷积在GPU等现代并行计算设备上可能非常低效。传统的DW 3×3内核也是如此,因为DW操作引入了较低的计算与内存访问成本之比,这对现代计算架构不友好。然而,我们发现,当内核大小变大时,计算密度会增加:例如,在DW 11×11内核中,每次我们从特征映射加载一个值时,它最多可以进行121次乘法,而在3×3内核中,这个数字只有9次。因此,根据屋顶线模型,当内核大小变大时,实际延迟的增加幅度不应超过触发器的增加幅度。
2) 残差连接对于大核卷积非常重要
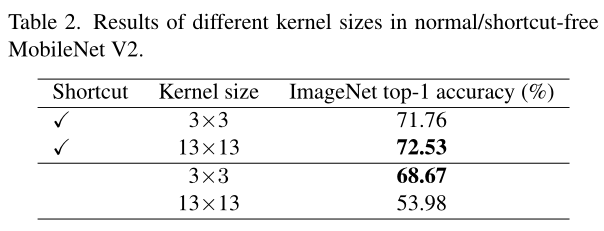
为了证明这一点,我们使用MobileNet V2[77]进行基准测试,因为它大量使用DW层,并且有两个已发布的变体。对于大型内核对应层,我们只需将所有DW 3×3层替换为13×13。所有模型都在ImageNet上进行了100个历元的相同训练配置。表2显示,大内核将具有快捷方式的MobileNet V2的精度提高了0.77%。然而,如果没有捷径,大核将精度降低到仅53.98%。
3) 重参数化小核有助于训练
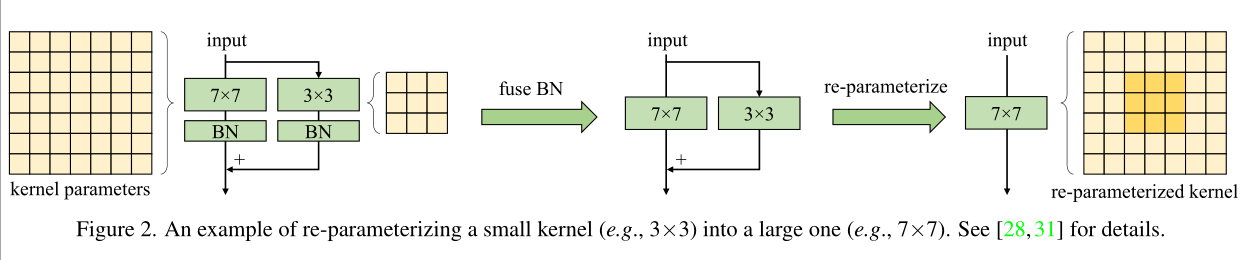
4) 大卷积核能够更好的用于下游任务中
large convolutions boost downstream tasks much more than ImageNet classification
如前面表3所示,相对于分类任务,卷积核增大为分割任务带来的收益更多。而表5的结果也有类似的现象,大卷积核在ADE20K数据集上的提升更为明显。这表明,即使预训练模型有相似的ImageNet性能,但其在下游任务中的性能可能差距较大。

论文认为导致这一现象的原因主要有两点:
-
大卷积核能显著增加有效感受域(ERF),可包含更多的上下文信息,这对下游任务十分关键。
-
大卷积能引导网络倾向于学习更多形状特征。图像分类仅需要上下文或形状信息,而目标识别则非常需要形状信息。所以,倾向于更多形状特征的模型显然更适合下游任务。
ViTs之所以在下游任务中表现强劲,也是得益于其强大的形状特征提取能力。相反,ImageNet预训练的传统卷积网络则倾向于上下文信息。
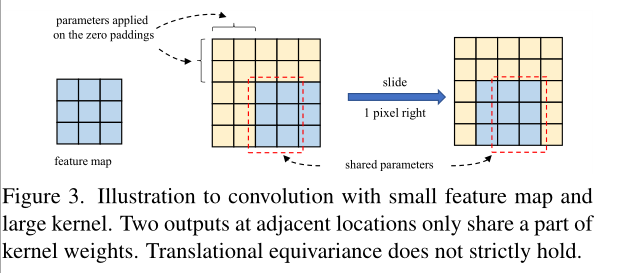
5) 大内核(例如13×13)即使在小特征映射(例如7×7)上也很有用。
为了验证大卷积在小特征图上的有效性,将MobileNetV2最后的stage(特征图大小为7x7)的深度卷积分别扩大至7x7和13x13进行对比,实验结构附带了准则3建议的结构重参数。结果如表4所示,尽管特征图已经很小了,增大卷积核依然可以带来性能提升。
2.3 总结
Large-Kernel CNNs have Larger ERF than Deep Small-Kernel Models
一般来说,堆叠的小卷积最终也能达到跟单个大卷积一样的感受域大小,但为什么传统网络的性能要低于大卷积核网络呢?论文认为,尽管能达到同样大小的感受域,单层大卷积核要比多层小卷积更有效,主要有两点:
- 根据有效感受域特性,其大小与 O ( K L ) \mathcal{O}(K\sqrt{L}) O(KL)成比例关系。可以看到,有效感受域与卷积核大小成线性关系,而与深度成次线性关系。
- 深度的增加会带来训练问题。尽管ResNet似乎已经解决了这个问题,但近期有研究表明,ResNet的有效感受域并没有随着深度增加而显著增加。
所以大卷积核的设计仅需要更少的层就可以达到预定的有效感受域,同时避免了深度增加带来的优化问题。
论文也对ResNet和RepLKNet的有效感受域进行可视化和统计,发现RepLkNet整体有效感受域要大于ResNet。
Large-kernel Models are More Similar to Human in Shape Bias
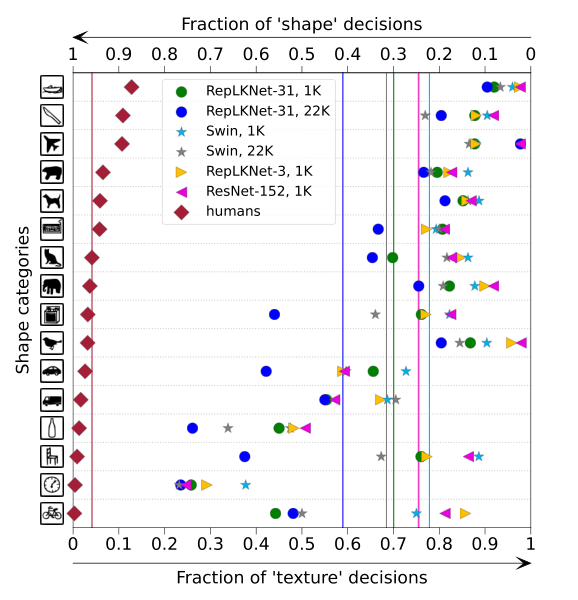
有研究发现ViT更接近人体视觉,基于目标的形状进行预测,而CNN则更多地依赖局部上下文。论文借用https://github.com/bethgelab/model-vs-human的工具来计算模型的形状特征的偏向性,得到图5的结果,结果越低越好。从结果来看,大卷积核的RepLKNet更注重形状特征,当卷积核减少时,RepLKNet-3则变为更注重上下文特征。
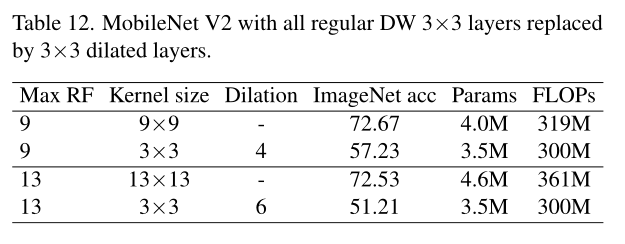
空洞卷积是一个常用的扩大卷积范围的方法,所以论文对空洞深度卷积和普通深度卷积进行了对比。如表11所示,尽管最大感受域可能一样,但空洞深度卷积的表达能力要弱很多,准确率下降非常明显。这也是符合预期的,虽然空洞卷积的感受域较大,但其计算用的特征非常少。
3. 代码
原版代码不能运行。因为有重参数化
import torch
import torch.nn as nn
from timm.models.layers import DropPath
"""
代码来自https://github.com/NNDEV1/RepLKNet
没有重参数
"""
class DepthWiseConv2d(nn.Module):
def __init__(self, c_in, c_out, kernels_per_layer, kernel_size, stride,padding=0):
super(DepthWiseConv2d, self).__init__()
self.conv_dw = nn.Conv2d(c_in, c_in * kernels_per_layer, kernel_size=kernel_size, padding=1, groups=c_in,
bias=False,)
self.conv_pw = nn.Conv2d(c_in * kernels_per_layer, c_out, kernel_size=1, stride=stride, bias=False)
def forward(self, x):
return self.conv_pw(self.conv_dw(x))
class Stem(nn.Module):
def __init__(self, c_in, c_out):
super(Stem, self).__init__()
self.conv1 = nn.Conv2d(c_in, c_out, kernel_size=3, stride=2, bias=False)
self.conv_dw1 = DepthWiseConv2d(c_out, c_out, kernels_per_layer=8, stride=1, kernel_size=3)
self.conv2 = nn.Conv2d(c_out, c_out, kernel_size=1, padding=0, stride=1, bias=False)
self.conv_dw2 = DepthWiseConv2d(c_out, c_out, kernels_per_layer=8, stride=2, kernel_size=3)
def forward(self, x):
x = self.conv1(x)
x = self.conv_dw1(x)
x = self.conv2(x)
x = self.conv_dw2(x)
return x
class Transition(nn.Module):
def __init__(self, c_in, c_out, kernels_per_layer, kernel_size):
super(Transition, self).__init__()
self.conv1 = nn.Conv2d(c_in, c_in, kernel_size=1, stride=1, padding="same", bias=False)
self.dw_conv = DepthWiseConv2d(c_in, c_out, kernels_per_layer, kernel_size, stride=2)
def forward(self, x):
x = self.conv1(x)
x = self.dw_conv(x)
return x
class RepLKBlock(nn.Module):
def __init__(self, kernel_size, c_in, c_out, prob):
super(RepLKBlock, self).__init__()
# Only works for kernel sizes up to 9x9 5 1 7 2 9 3 11 4 13 5 15 6 17 7 19 8 21 9 23 10 25 11 27 12 29 13 31 14
if kernel_size <= 9:
padding = kernel_size // 3
elif kernel_size % 2 == 1:
padding = kernel_size // 2 - 1
# print(kernel_size)
self.bn = nn.BatchNorm2d(c_in)
self.conv1 = nn.Conv2d(c_in, c_out, kernel_size=1, stride=1, bias=False)
self.conv_dw = DepthWiseConv2d(c_out, c_out, kernel_size=kernel_size, stride=1, kernels_per_layer=8)
self.conv2 = nn.Conv2d(c_out, c_out, kernel_size=1, stride=1, padding=padding, bias=False)
self.drop_path = DropPath(prob)
def forward(self, x):
add = x
x = self.bn(x)
x = self.conv1(x)
x = self.conv_dw(x)
x = self.conv2(x)
return self.drop_path(x) + add
class ConvFFN(nn.Module):
def __init__(self, c_in, c_out, prob):
super(ConvFFN, self).__init__()
self.bn = nn.BatchNorm2d(c_in)
self.conv1 = nn.Conv2d(c_in, c_out, kernel_size=3, padding="same", stride=1, bias=False)
self.gelu = nn.GELU()
self.conv2 = nn.Conv2d(c_out, c_out, kernel_size=3, padding="same", stride=1, bias=False)
self.drop_path = DropPath(prob)
def forward(self, x):
add = x
x = self.bn(x)
x = self.conv1(x)
x = self.gelu(x)
x = self.conv2(x)
return self.drop_path(x) + add
# Stem
# Stage 1: (RepLKBlock, ConvFFN, ..., RepLKBlock, ConvFFN)
# Transition 1
# Stage 2: (RepLKBlock, ConvFFN, ..., RepLKBlock, ConvFFN)
# Transition 2
# Stage 3: (RepLKBlock, ConvFFN, ..., RepLKBlock, ConvFFN)
# Transition 3
# Stage 4: (RepLKBlock, ConvFFN, ..., RepLKBlock, ConvFFN)
# Transition 4
class RepLKNet(nn.Module):
def __init__(self,
num_classes=1000,
layers=[3, 3, 3, 3],
drop_path_rate=0.3,
kernel_sizes=[31, 29, 15, 7],
c_in=3,
channels=[32, 32, 32, 32]):
super(RepLKNet, self).__init__()
c_out = channels[0]
self.stem = Stem(c_in, c_out)
################
c_out = channels[0]
modules1 = []
for i in range(layers[0]):
modules1.append(RepLKBlock(kernel_sizes[0], c_out, c_out, prob=drop_path_rate))
modules1.append(ConvFFN(c_out, c_out, prob=drop_path_rate))
# stage 1
self.stage1 = nn.Sequential(*modules1)
self.transition1 = Transition(c_out, channels[1], kernels_per_layer=8, kernel_size=3)
#####################
c_out = channels[1]
modules2 = []
for i in range(layers[1]):
modules2.append(RepLKBlock(kernel_sizes[1], c_out, c_out, prob=drop_path_rate))
modules2.append(ConvFFN(c_out, c_out, prob=drop_path_rate))
self.stage2 = nn.Sequential(*modules2)
self.transition2 = Transition(c_out, channels[2], kernels_per_layer=16, kernel_size=3)
#####################
c_out = channels[2]
modules3 = []
for i in range(layers[2]):
modules3.append(RepLKBlock(kernel_sizes[2], c_out, c_out, prob=drop_path_rate))
modules3.append(ConvFFN(c_out, c_out, prob=drop_path_rate))
self.stage3 = nn.Sequential(*modules3)
self.transition3 = Transition(c_out, channels[3], kernels_per_layer=32, kernel_size=3)
#####################
c_out = channels[3]
modules4 = []
for i in range(layers[3]):
modules4.append(RepLKBlock(kernel_sizes[3], c_out, c_out, prob=drop_path_rate))
modules4.append(ConvFFN(c_out, c_out, prob=drop_path_rate))
self.stage4 = nn.Sequential(*modules4)
# self.transition4 = Transition(c_out, channels[3], kernels_per_layer=64, kernel_size=3)
c_out = channels[3]
self.adaptive_pool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Sequential(*[nn.Linear(c_out, c_out // 2),
nn.ReLU(inplace=True),
nn.Linear(c_out // 2, c_out // 4),
nn.ReLU(inplace=True),
nn.Linear(c_out // 4, num_classes)])
def forward(self, x):
x = self.stem(x) # 1/4 图
x = self.stage1(x)
x = self.transition1(x) # 1/8 图
x = self.stage2(x) # torch.Size([1, 256, 28, 28])
# print(x.shape)
x = self.transition2(x) # 1/16 图
x = self.stage3(x) # torch.Size([1, 512, 14, 14])
x = self.transition3(x) # # 1/32 图
x = self.stage4(x) # 1/32 图
x = self.adaptive_pool(x)
x = x.view((x.size(0), -1))
x = self.fc(x)
return x
def create_RepLKNet31Small(drop_path_rate=0.3, num_classes=1000, **kwargs):
return RepLKNet(kernel_sizes=[31, 29, 15, 7],
layers=[2, 2, 18, 2],
channels=[128, 256, 512, 1024],
drop_path_rate=drop_path_rate,
num_classes=num_classes, **kwargs)
def create_RepLKNet31B(drop_path_rate=0.3, num_classes=1000, **kwargs):
return RepLKNet(kernel_sizes=[31, 29, 27, 13],
layers=[2, 2, 18, 2],
channels=[128, 256, 512, 1024],
drop_path_rate=drop_path_rate,
num_classes=num_classes, **kwargs)
def create_RepLKNet31L(drop_path_rate=0.3, num_classes=1000, **kwargs):
return RepLKNet(kernel_sizes=[31, 29, 27, 13],
layers=[2, 2, 18, 2],
channels=[192, 384, 768, 1536],
drop_path_rate=drop_path_rate,
num_classes=num_classes, **kwargs)
def create_RepLKNetXL(drop_path_rate=0.3, num_classes=1000, **kwargs):
return RepLKNet(kernel_sizes=[27, 27, 27, 13],
layers=[2, 2, 18, 2],
channels=[256, 512, 1024, 2048],
drop_path_rate=drop_path_rate,
num_classes=num_classes, **kwargs)
if __name__ == '__main__':
from thop import profile
model = create_RepLKNet31Small(num_classes=1000)
input = torch.randn(1, 3, 224, 224)
# 使用B的模型时,1/16的特征图必须大于 27的kernel_size。所以 B 以上模型,必须 input = torch.randn(1, 3, 432,432)
# model = create_RepLKNet31B(num_classes=1000)
# input = torch.randn(1, 3, 512,512)
y = model(input)
print(y.shape)
# flops, params = profile(model, inputs=(input,))
# print("flops:{:.3f}G".format(flops / 1e9))
# print("params:{:.3f}M".format(params / 1e6))