文章目录
【语义分割】2022-HRViT CVPR
论文题目:Multi-Scale High-Resolution Vision Transformer for Semantic Segmentation
论文链接:https://arxiv.org/abs/2111.01236
论文代码:https://github.com/facebookresearch/HRViT
作者单位:Facebook, UT-Austin
发表时间:2021年11月
引用:Gu J, Kwon H, Wang D, et al. Multi-scale high-resolution vision transformer for semantic segmentation[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022: 12094-12103.
引用数:9
1. 简介
1.1 摘要
视觉Transformer(ViT) 因其在计算机视觉任务上的卓越性能而备受关注。为了解决其单尺度低分辨率表示的局限性,先前的工作使 ViT 适应具有分层架构的高分辨率密集预测任务,以生成金字塔特征。然而,鉴于 ViT 的类似分类的顺序拓扑结构,多尺度表示学习在 ViT 上的探索仍然不足。
为了增强 ViTs 学习语义丰富和空间精确的多尺度表示的能力,在这项工作中,我们提出了高分辨率多分支架构与视觉Transformer的有效集成,称为 HRViT,推动了密集的帕累托前沿预测任务提升到一个新的水平。
作者探索了异构分支设计,减少了线性层的冗余,并增加了模型的非线性,以平衡模型性能和硬件效率。本文所提出的HRViT在ADE20K上实现了50.20% mIoU,在Cityscapes上实现了83.16% mIoU,超过了最先进的MiT和CSWin,平均提高了1.78 mIoU,减少了28%的参数和21%的FLOPs。
1.2 介绍
HRViT不同于以往的ViT的几个方面是:
- 通过并行提取多尺度特征以及跨分辨率融合,提高了ViT的多尺度可表征性;
- 增强的局部自注意力,消除了冗余的key和value,提高了效率,并通过额外的卷积路径、额外的非线性和辅助快捷键增强了特征的多样性,增强了表达能力;
- 采用混合尺度卷积前馈网络加强多尺度特征提取;
- HR卷积stem和高效的patch embedding layer保持更多的低层次细粒度特征,降低了硬件成本。
同时,与HRNet-family不同的是,HRViT采用了独特的异构分支设计来平衡效率和性能,它不是简单的改进的HRNet,而是主要由自注意力算子构建的纯ViT拓扑结构。
主要贡献如下:
- 深入研究了ViT中的多尺度表示学习,并将高分辨率架构与Vision Transformer相结合,实现高性能密集预测视觉任务;
- 为了实现可扩展的HR-ViT集成,并实现更好的性能和效率权衡,利用了Transformer Block中的冗余,并通过异构分支设计对HRViT的关键部件进行联合优化;
- HRViT再语义分割任务的ADE20K达到50.20% mIoU,在Cityscapes上达到83.16% mIoU,超过了最先进的(SoTA)MiT和CSWin,同时参数减少28%,FLOPs降低21%。
2. 网络
2.1 网络总体架构

在图1中说明了HRViT的体系结构。它由卷积主干组成,在提取低层次特征的同时降低空间维数。然后构造了4个渐进式Transformer Stage,其中第n阶段包含了n个并行的多尺度Transformer branches。每个阶段可以有一个或多个模块。每个模块从一个轻量级的密集融合层开始,实现跨分辨率交互和一个高效的块嵌入局部特征提取,然后是重复增强的局部自注意力块(HRViTAttn)和混合尺度卷积前馈网络(MixCFN)。
不同于顺序的ViT主干逐步降低空间维度以生成金字塔特征,在整个网络中保持HR特征,通过交叉分辨率融合加强HR表示的质量。
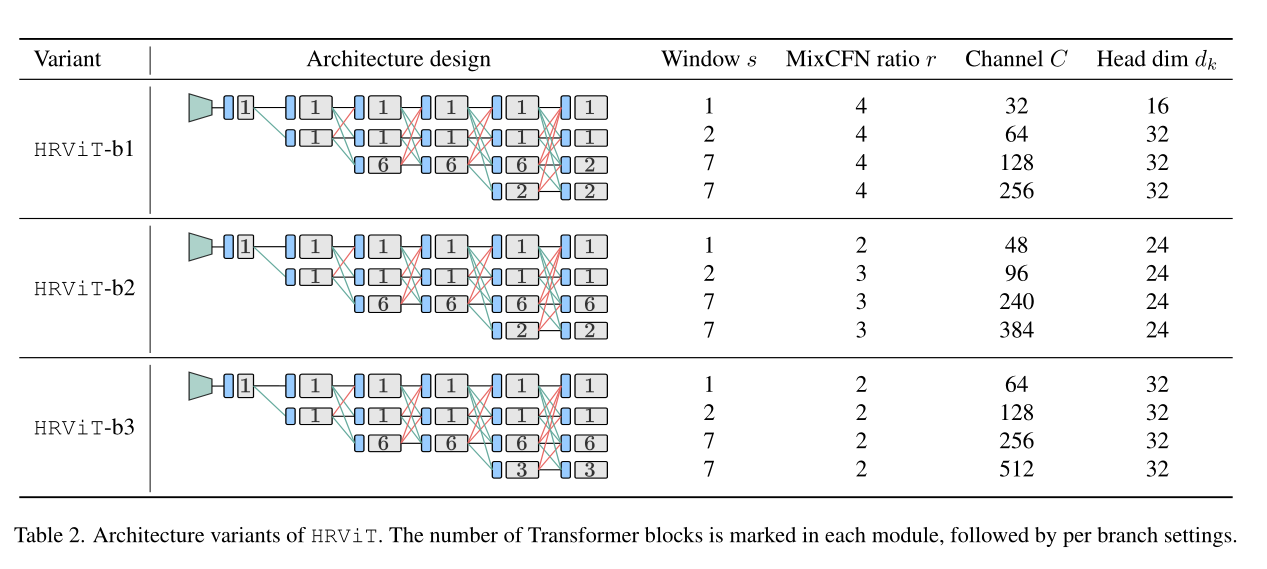
2.2 HRViTAttn
为了达到更高的效率和更高的性能,一个硬件高效的自注意力操作是必要的。HRViT采用一种有效的cross-shaped self-attention 作为baseline attention operator。结构如下图所示。
Attention 复杂度最高的部分就是 Q 和 K 的矩阵相似度的计算,每个像素都参与计算相似度复杂度过高。因此,作者将从一开始就将通道分为两半,上面一半做行注意力,下面一半做列注意力。
HRViT-Attn有以下优点:
- 细粒度注意:与全局下采样attention相比,HRViT-Attn具有保留详细信息的细粒度特征聚合;
- 近似全局视图:通过使用2个平行的正交局部注意力来收集全局信息;
- 可伸缩复杂度:window的一维是固定的,避免了图像尺寸的二次复杂度。
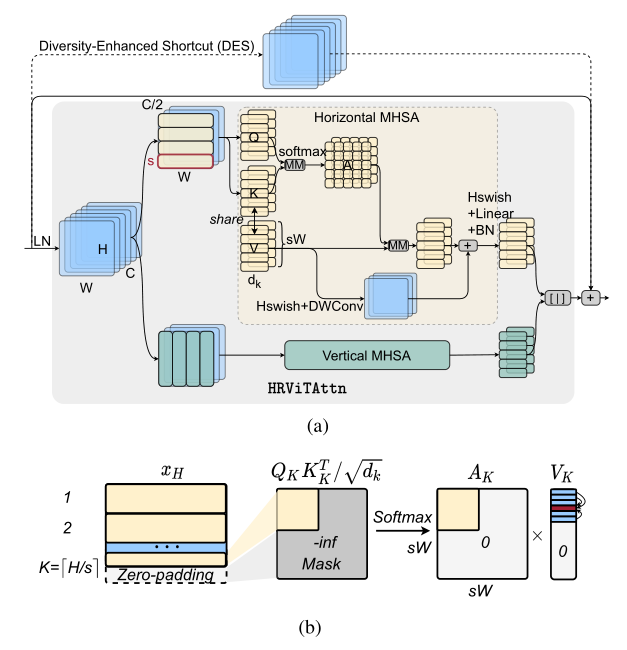
为了平衡性能和硬件效率,引入了扩展版本,表示为HRViT-Attn,有几个关键的优化。在图2(a)中,遵循CSWin中的cross-shaped window partitioning方法,将输入分割为2个部分。被分割成不相交的水平窗口,而另一半被分割成垂直窗口。窗口设置为s×W或H×s。在每个窗口内,patch被分块成K个维的Head,然后应用local self-attention,
HRViTAttn ( x ) = BN ( σ ( W O [ y 1 , ⋯ , y k , ⋯ , y K ] ) ) y k = z k + DWConv ( σ ( W k V x ) ) [ z k 1 , ⋯ , z k M ] = z k = { H − Attn k ( x ) , 1 ≤ k < K / 2 V − A Atn n k ( x ) , K / 2 ≤ k ≤ K z k m = MHSA ( W k Q x m , W k K x m , W k V x m ) [ x 1 , ⋯ , x m , ⋯ , x M ] = x , x m ∈ R ( H / s ) × W × C , \begin{array}{l} \operatorname{HRViTAttn}(x) = \operatorname{BN}\left(\sigma\left(W^{O}\left[y_{1}, \cdots, y_{k}, \cdots, y_{K}\right]\right)\right)\\ y_{k} = z_{k}+\operatorname{DWConv}\left(\sigma\left(W_{k}^{V} x\right)\right)\\ \left[z_{k}^{1}, \cdots, z_{k}^{M}\right] = z_{k} = \left\{\begin{array}{cc} \mathrm{H}-\operatorname{Attn}_{k}(x), & 1 \leq k<K / 2 \\ V-A \operatorname{Atn} n_{k}(x), & K / 2 \leq k \leq K \end{array}\right.\\ z_{k}^{m} = \operatorname{MHSA}\left(W_{k}^{Q} x^{m}, W_{k}^{K} x^{m}, W_{k}^{V} x^{m}\right)\\ \left[x^{1}, \cdots, x^{m}, \cdots, x^{M}\right] = x, \quad x^{m} \in \mathbb{R}^{(H / s) \times W \times C} \text {, } \end{array} HRViTAttn(x)=BN(σ(WO[y1,⋯,yk,⋯,yK]))yk=zk+DWConv(σ(WkVx))[zk1,⋯,zkM]=zk={
H−Attnk(x),V−AAtnnk(x),1≤k<K/2K/2≤k≤Kzkm=MHSA(WkQxm,WkKxm,WkVxm)[x1,⋯,xm,⋯,xM]=x,xm∈R(H/s)×W×C,
式中为生成第k个Head的query 、key 和value 张量的投影矩阵,为输出投影矩阵,σ为Hardswish激活函数。如果图像大小不是窗口大小的倍数,对输入x应用零填充,以允许一个完整的第k个窗口,如图2(b)所示。然后将Attention Map中的padding区域Mask为0,以避免语义不贯。
原有的QKV线性层在计算和参数上都非常昂贵。共享HRViT-Attn中key张量和value张量的线性投影,以节省计算和参数,如下所示:
MHSA ( W k Q x m , W k V x m , W k V x m ) = softmax ( Q k m ( V k m ) T d k ) V k m \operatorname{MHSA}\left(W_{k}^{Q} x^{m}, W_{k}^{V} x^{m}, W_{k}^{V} x^{m}\right)=\operatorname{softmax}\left(\frac{Q_{k}^{m}\left(V_{k}^{m}\right)^{T}}{\sqrt{d_{k}}}\right) V_{k}^{m} MHSA(WkQxm,WkVxm,WkVxm)=softmax(dkQkm(Vkm)T)Vkm
此外,作者还引入了一个具有并行深度卷积的辅助路径来注入感应偏差以促进训练。与CSWin中的局部位置编码不同,HRViT的并行路径是非线性的,并应用于整个4-D特征图上,而不需要进行窗口划分。这条路径可以看作是一个反向残差模,与自注意力的线性投影层共享point-wise卷积。该共享路径可以有效地注入感应偏差,并在硬件开销较小的情况下加强局部特征聚合。
作为对上述key-value共享的性能补偿,作者引入了一个额外的Hardswish函数来改善非线性。同时还附加了一个BatchNorm(BN)层,该层被初始化为一个identity投影,以稳定分布获得更好的可训练性。
最近的研究表明,不同的Transformer layer往往具有非常相似的特性,其中Shortcut起着至关重要的作用。受augmented shortcut方式的启发,作者添加了一个通道式投影作为多样性增强shortcut方式(DES)。主要的区别是本文的Shortcut具有更高的非线性,并且不依赖于不友好的硬件傅里叶变换。
投影矩阵DES 近似为Kronecker分解,使参数代价最小,其中P最优设置为。然后将x折叠为,并将转换为以节省计算。进一步在B投影后插入Hardswish以增加非线性,
DES ( x ) = A ⋅ Hardswish ( x ~ B T ) \operatorname{DES}(x)=A \cdot \text { Hardswish }\left(\tilde{x} B^{T}\right) DES(x)=A⋅ Hardswish (x~BT)
总结:作者主要进行了四处改进:
- s行为一个token,每个 token 的特征为 s × W s \times W s×W或者$ s \times H ,同时,相似度矩阵就为 ,同时,相似度矩阵就为 ,同时,相似度矩阵就为s \times s$了,相似度的计算就简化了。(这里的处理方法和 Restormer 类似,大家可以回顾);
- 正常得到 K,Q,V时,需要三个 1x1 卷积,这里作者只使用了两个,K 和 V 是共享的,又进一步简化了计算;
- V 额外使用了 Hardwith 激活函数和 DWConv 处理,作者解释是增加了归纳偏置。
添加了一个 diversity-enhanced shortcut,这里是受了 NeurIPS2021 论文 Augmented Shortcuts for Vision Transformers 的启发,非常类似。
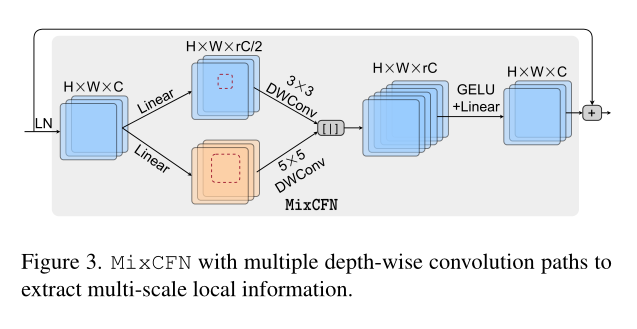
2.3 MixCFN
作者提出的 MixCFN 和大多数的 FFN 类似,都是先升维,后降维。不同的地方就是为了增强多尺度特征的提取,作者使用了 3X3 卷积和 5X5 卷积,如下图所示。
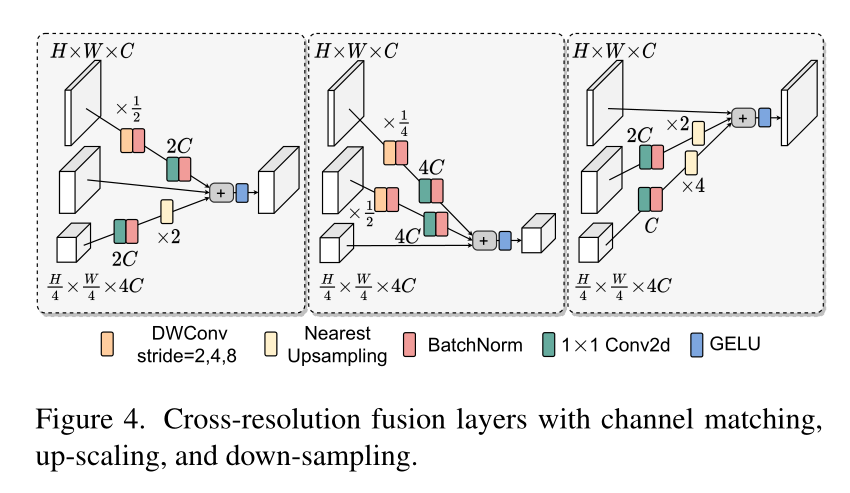
2.4 融合模块
3. 代码
# Copyright (c) Meta Platforms, Inc. and affiliates. All Rights Reserved.
import logging
import math
from functools import lru_cache
from typing import List, Optional, Tuple
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.checkpoint as cp
from einops import rearrange
from timm.data import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD
from timm.models.layers import DropPath, to_2tuple
from timm.models.registry import register_model
from torch import Tensor
from torch.types import _size
logger = logging.getLogger(__name__)
def _cfg(url="", **kwargs):
return {
"url": url,
"num_classes": 1000,
"input_size": (3, 224, 224),
"pool_size": None,
"crop_pct": 0.9,
"interpolation": "bicubic",
"mean": IMAGENET_DEFAULT_MEAN,
"std": IMAGENET_DEFAULT_STD,
"first_conv": "patch_embed.proj",
"classifier": "head",
**kwargs,
}
default_cfgs = {
"hrvit_224": _cfg(),
}
class MixConv2d(nn.Module):
def __init__(
self,
in_channels: int,
out_channels: int,
kernel_size: int = 3,
stride: int = 1,
padding: int = 0,
dilation: int = 1,
groups: int = 1,
bias: bool = True,
) -> None:
super().__init__()
self.conv_3 = nn.Conv2d(
in_channels // 2,
out_channels // 2,
kernel_size,
stride=1,
padding=padding,
dilation=dilation,
groups=groups // 2,
bias=bias,
)
self.conv_5 = nn.Conv2d(
in_channels - in_channels // 2,
out_channels - out_channels // 2,
kernel_size + 2,
stride=stride,
padding=padding + 1,
dilation=dilation,
groups=groups - groups // 2,
bias=bias,
)
def forward(self, x: Tensor) -> Tensor:
x1, x2 = x.chunk(2, dim=1)
x1 = self.conv_3(x1)
x2 = self.conv_5(x2)
x = torch.cat([x1, x2], dim=1)
return x
class DES(nn.Module):
def __init__(
self,
in_features: int,
out_features: int,
bias: bool = True,
act_func: nn.Module = nn.GELU,
) -> None:
super().__init__()
_, self.p = self._decompose(min(in_features, out_features))
self.k_out = out_features // self.p
self.k_in = in_features // self.p
self.proj_right = nn.Linear(self.p, self.p, bias=bias)
self.act = act_func()
self.proj_left = nn.Linear(self.k_in, self.k_out, bias=bias)
def _decompose(self, n: int) -> List[int]:
assert n % 2 == 0, f"Feature dimension has to be a multiple of 2, but got {
n}"
e = int(math.log2(n))
e1 = e // 2
e2 = e - e // 2
return 2 ** e1, 2 ** e2
def forward(self, x: Tensor) -> Tensor:
B = x.shape[:-1]
x = x.view(*B, self.k_in, self.p)
x = self.proj_right(x).transpose(-1, -2)
if self.act is not None:
x = self.act(x)
x = self.proj_left(x).transpose(-1, -2).flatten(-2, -1)
return x
class MixCFN(nn.Module):
def __init__(
self,
in_features: int,
hidden_features: Optional[int] = None,
out_features: Optional[int] = None,
act_func: nn.Module = nn.GELU,
with_cp: bool = False,
):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.with_cp = with_cp
self.fc1 = nn.Linear(in_features, hidden_features)
self.conv = MixConv2d(
hidden_features,
hidden_features,
kernel_size=3,
stride=1,
padding=1,
groups=hidden_features,
dilation=1,
bias=True,
)
self.act = act_func()
self.fc2 = nn.Linear(hidden_features, out_features)
def forward(self, x: Tensor, H: int, W: int) -> Tensor:
def _inner_forward(x: Tensor) -> Tensor:
x = self.fc1(x)
B, N, C = x.shape
x = self.conv(x.transpose(1, 2).view(B, C, H, W))
x = self.act(x)
x = self.fc2(x.flatten(2).transpose(-1, -2))
return x
if self.with_cp and x.requires_grad:
x = cp.checkpoint(_inner_forward, x)
else:
x = _inner_forward(x)
return x
class Bottleneck(nn.Module):
expansion = 4
def __init__(
self,
inplanes: int,
planes: int,
stride: int = 1,
with_cp: bool = False,
):
super(Bottleneck, self).__init__()
self.with_cp = with_cp
self.conv1 = nn.Conv2d(
inplanes,
planes,
kernel_size=1,
stride=1,
dilation=1,
padding=0,
groups=1,
bias=False,
)
self.bn1 = nn.BatchNorm2d(
planes, momentum=1 - 0.9 ** 0.5 if self.with_cp else 0.1
)
self.conv2 = nn.Conv2d(
planes,
planes,
kernel_size=3,
stride=stride,
dilation=1,
padding=1,
groups=1,
bias=False,
)
self.bn2 = nn.BatchNorm2d(
planes, momentum=1 - 0.9 ** 0.5 if self.with_cp else 0.1
)
self.conv3 = nn.Conv2d(
planes,
planes * self.expansion,
kernel_size=1,
stride=1,
dilation=1,
padding=0,
groups=1,
bias=False,
)
self.bn3 = nn.BatchNorm2d(
planes * self.expansion, momentum=1 - 0.9 ** 0.5 if self.with_cp else 0.1
)
self.relu = nn.ReLU(inplace=True)
self.downsample = None
if stride != 1 or inplanes != planes * self.expansion:
self.downsample = nn.Sequential(
nn.Conv2d(
inplanes,
planes * self.expansion,
kernel_size=1,
stride=stride,
dilation=1,
padding=0,
groups=1,
bias=False,
),
nn.BatchNorm2d(
planes * self.expansion,
momentum=1 - 0.9 ** 0.5 if self.with_cp else 0.1,
),
)
self.stride = stride
def forward(self, x: Tensor) -> Tensor:
def _inner_forward(x: Tensor) -> Tensor:
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
residual = self.downsample(x)
out = out.add(residual)
return out
if self.with_cp and x.requires_grad:
x = cp.checkpoint(_inner_forward, x)
else:
x = _inner_forward(x)
x = self.relu(x)
return x
class HRViTClassifier(nn.Module):
def __init__(
self,
in_channels: Tuple[int] = (32, 64, 128, 256),
head_channels: Tuple[int] = (32, 64, 128, 256),
num_classes: int = 1000,
dropout: float = 0.0,
act_func: nn.Module = nn.ReLU,
with_cp: bool = False,
) -> None:
super().__init__()
self.with_cp = with_cp
head_block = Bottleneck
# Increasing the #channels on each resolution
# from C, 2C, 4C, 8C to 128, 256, 512, 1024
incre_modules = []
for i, channels in enumerate(in_channels):
incre_module = self._make_layer(
head_block,
channels,
head_channels[i],
1,
stride=1,
)
incre_modules.append(incre_module)
self.incre_modules = nn.ModuleList(incre_modules)
# downsampling modules
downsamp_modules = []
for i in range(len(in_channels) - 1):
inc = head_channels[i] * head_block.expansion
outc = head_channels[i + 1] * head_block.expansion
downsamp_module = nn.Sequential(
nn.Conv2d(
in_channels=inc,
out_channels=outc,
kernel_size=3,
stride=2,
dilation=1,
padding=1,
groups=1,
bias=True,
),
nn.BatchNorm2d(outc),
act_func(inplace=True),
)
downsamp_modules.append(downsamp_module)
self.downsamp_modules = nn.ModuleList(downsamp_modules)
self.final_layer = nn.Sequential(
nn.Conv2d(
in_channels=head_channels[3] * head_block.expansion,
out_channels=2048,
kernel_size=1,
stride=1,
dilation=1,
padding=0,
groups=1,
bias=True,
),
nn.BatchNorm2d(2048),
act_func(inplace=True),
)
self.pool = nn.AdaptiveAvgPool2d(1)
self.dropout = nn.Dropout(dropout)
self.classifier = (
nn.Linear(2048, num_classes) if num_classes > 0 else nn.Identity()
)
def _make_layer(
self, block: nn.Module, inplanes: int, planes: int, blocks: int, stride: int = 1
) -> nn.Module:
layers = []
layers.append(
block(
inplanes=inplanes,
planes=planes,
stride=stride,
with_cp=self.with_cp,
)
)
inplanes = planes * block.expansion
for _ in range(1, blocks):
layers.append(
block(
inplanes,
planes,
with_cp=self.with_cp,
)
)
return nn.Sequential(*layers)
def forward(
self,
y_list: Tuple[
Tensor,
],
) -> Tensor:
# Classification Head
y = self.incre_modules[0](y_list[0])
for i in range(len(self.downsamp_modules)):
y = self.incre_modules[i + 1](y_list[i + 1]) + self.downsamp_modules[i](y)
y = self.final_layer(y)
y = self.pool(y).flatten(1)
y = self.dropout(y)
y = self.classifier(y)
return y
class HRViTAttention(nn.Module):
def __init__(
self,
in_dim: int = 64,
dim: int = 64,
heads: int = 2,
ws: int = 1, # window size
qk_scale: Optional[float] = None,
proj_drop: float = 0.0,
with_cp: bool = False,
):
super().__init__()
assert dim % heads == 0, f"dim {
dim} should be divided by num_heads {
heads}."
self.in_dim = in_dim
self.dim = dim
self.heads = heads
self.dim_head = dim // heads
self.ws = ws
self.with_cp = with_cp
self.to_qkv = nn.Linear(in_dim, 2 * dim)
self.scale = qk_scale or self.dim_head ** -0.5
self.attend = nn.Softmax(dim=-1)
self.attn_act = nn.Hardswish(inplace=True)
self.to_out = nn.Sequential(
nn.Linear(dim, dim),
nn.Dropout(proj_drop),
)
self.attn_bn = nn.BatchNorm1d(
dim, momentum=1 - 0.9 ** 0.5 if self.with_cp else 0.1
)
nn.init.constant_(self.attn_bn.bias, 0)
nn.init.constant_(self.attn_bn.weight, 0)
self.parallel_conv = nn.Sequential(
nn.Hardswish(inplace=False),
nn.Conv2d(
dim,
dim,
kernel_size=3,
padding=1,
groups=dim,
),
)
@lru_cache(maxsize=4)
def _generate_attn_mask(self, h: int, hp: int, device):
x = torch.empty(hp, hp, device=device).fill_(-100.0)
x[:h, :h] = 0
return x
def _cross_shaped_attention(
self,
q: Tensor,
k: Tensor,
v: Tensor,
H: int,
W: int,
HP: int,
WP: int,
ws: int,
horizontal: bool = True,
):
B, N, C = q.shape
if C < self.dim_head: # half channels are smaller than the defined dim_head
dim_head = C
scale = dim_head ** -0.5
else:
scale = self.scale
dim_head = self.dim_head
if horizontal:
q, k, v = map(
lambda y: y.reshape(B, HP // ws, ws, W, C // dim_head, -1)
.permute(0, 1, 4, 2, 3, 5)
.flatten(3, 4),
(q, k, v),
)
else:
q, k, v = map(
lambda y: y.reshape(B, H, WP // ws, ws, C // dim_head, -1)
.permute(0, 2, 4, 3, 1, 5)
.flatten(3, 4),
(q, k, v),
)
attn = q.matmul(k.transpose(-2, -1)).mul(
scale
) # [B,H_2//ws,W_2//ws,h,(b1*b2+1)*(ws*ws),(b1*b2+1)*(ws*ws)]
## need to mask zero padding before softmax
if horizontal and HP != H:
attn_pad = attn[:, -1:] # [B, 1, num_heads, ws*W, ws*W]
mask = self._generate_attn_mask(
h=(ws - HP + H) * W, hp=attn.size(-2), device=attn.device
) # [ws*W, ws*W]
attn_pad = attn_pad + mask
attn = torch.cat([attn[:, :-1], attn_pad], dim=1)
if not horizontal and WP != W:
attn_pad = attn[:, -1:] # [B, 1, num_head, ws*H, ws*H]
mask = self._generate_attn_mask(
h=(ws - WP + W) * H, hp=attn.size(-2), device=attn.device
) # [ws*H, ws*H]
attn_pad = attn_pad + mask
attn = torch.cat([attn[:, :-1], attn_pad], dim=1)
attn = self.attend(attn)
attn = attn.matmul(v) # [B,H_2//ws,W_2//ws,h,(b1*b2+1)*(ws*ws),D//h]
attn = rearrange(
attn,
"B H h (b W) d -> B (H b) W (h d)"
if horizontal
else "B W h (b H) d -> B H (W b) (h d)",
b=ws,
) # [B,H_1, W_1,D]
if horizontal and HP != H:
attn = attn[:, :H, ...]
if not horizontal and WP != W:
attn = attn[:, :, :W, ...]
attn = attn.flatten(1, 2)
return attn
def forward(self, x: Tensor, H: int, W: int) -> Tensor:
def _inner_forward(x: Tensor) -> Tensor:
B = x.shape[0]
ws = self.ws
qv = self.to_qkv(x)
q, v = qv.chunk(2, dim=-1)
v_conv = (
self.parallel_conv(v.reshape(B, H, W, -1).permute(0, 3, 1, 2))
.flatten(2)
.transpose(-1, -2)
)
qh, qv = q.chunk(2, dim=-1)
vh, vv = v.chunk(2, dim=-1)
kh, kv = vh, vv # share key and value
# padding to a multple of window size
if H % ws != 0:
HP = int((H + ws - 1) / ws) * ws
qh = (
F.pad(
qh.transpose(-1, -2).reshape(B, -1, H, W),
pad=[0, 0, 0, HP - H],
)
.flatten(2, 3)
.transpose(-1, -2)
)
vh = (
F.pad(
vh.transpose(-1, -2).reshape(B, -1, H, W),
pad=[0, 0, 0, HP - H],
)
.flatten(2, 3)
.transpose(-1, -2)
)
kh = vh
else:
HP = H
if W % ws != 0:
WP = int((W + ws - 1) / ws) * ws
qv = (
F.pad(
qv.transpose(-1, -2).reshape(B, -1, H, W),
pad=[0, WP - W, 0, 0],
)
.flatten(2, 3)
.transpose(-1, -2)
)
vv = (
F.pad(
vv.transpose(-1, -2).reshape(B, -1, H, W),
pad=[0, WP - W, 0, 0],
)
.flatten(2, 3)
.transpose(-1, -2)
)
kv = vv
else:
WP = W
attn_h = self._cross_shaped_attention(
qh,
kh,
vh,
H,
W,
HP,
W,
ws,
horizontal=True,
)
attn_v = self._cross_shaped_attention(
qv,
kv,
vv,
H,
W,
H,
WP,
ws,
horizontal=False,
)
attn = torch.cat([attn_h, attn_v], dim=-1)
attn = attn.add(v_conv)
attn = self.attn_act(attn)
attn = self.to_out(attn)
attn = self.attn_bn(attn.flatten(0, 1)).view_as(attn)
return attn
if self.with_cp and x.requires_grad:
x = cp.checkpoint(_inner_forward, x)
else:
x = _inner_forward(x)
return x
def extra_repr(self) -> str:
s = f"window_size={
self.ws}"
return s
class HRViTBlock(nn.Module):
def __init__(
self,
in_dim: int = 64,
dim: int = 64,
heads: int = 2,
proj_dropout: float = 0.0,
mlp_ratio: float = 4.0,
drop_path: float = 0.0,
ws: int = 1,
with_cp: bool = False,
) -> None:
super().__init__()
self.with_cp = with_cp
# build layer normalization
self.attn_norm = nn.LayerNorm(in_dim)
# build attention layer
self.attn = HRViTAttention(
in_dim=in_dim,
dim=dim,
heads=heads,
ws=ws,
proj_drop=proj_dropout,
with_cp=with_cp,
)
# build diversity-enhanced shortcut DES
self.des = DES(
in_features=in_dim,
out_features=dim,
bias=True,
act_func=nn.GELU,
)
# build drop path
self.attn_drop_path = DropPath(drop_path) if drop_path > 0.0 else nn.Identity()
# build layer normalization
self.ffn_norm = nn.LayerNorm(in_dim)
# build FFN
self.ffn = MixCFN(
in_features=in_dim,
hidden_features=int(dim * mlp_ratio),
out_features=dim,
act_func=nn.GELU,
with_cp=with_cp,
)
# build drop path
self.ffn_drop_path = DropPath(drop_path) if drop_path > 0.0 else nn.Identity()
def forward(self, x: Tensor, H: int, W: int) -> Tensor:
# attention block
res = x
x = self.attn_norm(x)
x = self.attn(x, H, W)
x_des = self.des(res)
x = self.attn_drop_path(x.add(x_des)).add(res)
# ffn block
res = x
x = self.ffn_norm(x)
x = self.ffn(x, H, W)
x = self.ffn_drop_path(x).add(res)
return x
class HRViTPatchEmbed(nn.Module):
def __init__(
self,
in_channels: int = 3,
patch_size: _size = 3,
stride: int = 1,
dim: int = 64,
) -> None:
super().__init__()
self.patch_size = to_2tuple(patch_size)
self.dim = dim
self.proj = nn.Sequential(
nn.Conv2d(
in_channels,
dim,
kernel_size=1,
stride=1,
padding=0,
),
nn.Conv2d(
dim,
dim,
kernel_size=self.patch_size,
stride=stride,
padding=(self.patch_size[0] // 2, self.patch_size[1] // 2),
groups=dim,
),
)
self.norm = nn.LayerNorm(dim)
def forward(self, x: Tensor) -> Tuple[Tensor, int, int]:
x = self.proj(x)
H, W = x.shape[-2:]
x = x.flatten(2).transpose(1, 2)
x = self.norm(x)
return x, H, W
class HRViTFusionBlock(nn.Module):
def __init__(
self,
in_channels: Tuple[int] = (32, 64, 128, 256),
out_channels: Tuple[int] = (32, 64, 128, 256),
act_func: nn.Module = nn.GELU,
with_cp: bool = False,
) -> None:
super().__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.act_func = act_func
self.with_cp = with_cp
self.n_outputs = len(out_channels)
self._build_fuse_layers()
def _build_fuse_layers(self):
self.blocks = nn.ModuleList([])
n_inputs = len(self.in_channels)
for i, outc in enumerate(self.out_channels):
blocks = nn.ModuleList([])
start = 0
end = n_inputs
for j in range(start, end):
inc = self.in_channels[j]
if j == i:
blocks.append(nn.Identity())
elif j < i:
block = [
nn.Conv2d(
inc,
inc,
kernel_size=2 ** (i - j) + 1,
stride=2 ** (i - j),
dilation=1,
padding=2 ** (i - j) // 2,
groups=inc,
bias=False,
),
nn.BatchNorm2d(inc),
nn.Conv2d(
inc,
outc,
kernel_size=1,
stride=1,
dilation=1,
padding=0,
groups=1,
bias=True,
),
nn.BatchNorm2d(outc),
]
blocks.append(nn.Sequential(*block))
else:
block = [
nn.Conv2d(
inc,
outc,
kernel_size=1,
stride=1,
dilation=1,
padding=0,
groups=1,
bias=True,
),
nn.BatchNorm2d(outc),
]
block.append(
nn.Upsample(
scale_factor=2 ** (j - i),
mode="nearest",
),
)
blocks.append(nn.Sequential(*block))
self.blocks.append(blocks)
self.act = nn.ModuleList([self.act_func() for _ in self.out_channels])
def forward(
self,
x: Tuple[
Tensor,
],
) -> Tuple[Tensor,]:
out = [None] * len(self.blocks)
n_inputs = len(x)
for i, (blocks, act) in enumerate(zip(self.blocks, self.act)):
start = 0
end = n_inputs
for j, block in zip(range(start, end), blocks):
out[i] = block(x[j]) if out[i] is None else out[i] + block(x[j])
out[i] = act(out[i])
return out
class HRViTStem(nn.Module):
def __init__(
self,
in_channels: int,
out_channels: int,
kernel_size: _size = 3,
stride: _size = 4,
dilation: _size = 1,
groups: int = 1,
bias: bool = True,
) -> None:
super().__init__()
kernel_size = to_2tuple(kernel_size)
stride = to_2tuple(stride)
stride = (stride[0]//2, stride[1]//2)
dilation = to_2tuple(dilation)
# same padding
padding = [
(dilation[i] * (kernel_size[i] - 1) + 1) // 2
for i in range(len(kernel_size))
]
self.conv1 = nn.Conv2d(
in_channels,
out_channels // 2,
kernel_size,
stride=stride,
padding=padding,
dilation=dilation,
groups=groups,
bias=bias,
)
self.bn1 = nn.BatchNorm2d(out_channels // 2)
self.act1 = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(
out_channels // 2,
out_channels,
kernel_size,
stride=stride,
padding=padding,
dilation=dilation,
groups=groups,
bias=bias,
)
self.bn2 = nn.BatchNorm2d(out_channels)
self.act2 = nn.ReLU(inplace=True)
def forward(self, x: Tensor) -> Tensor:
x = self.act1(self.bn1(self.conv1(x)))
x = self.act2(self.bn2(self.conv2(x)))
return x
class HRViTStage(nn.Module):
def __init__(
self,
#### Patch Embed Config ####
in_channels: Tuple[
int,
] = (32, 64, 128, 256),
out_channels: Tuple[
int,
] = (32, 64, 128, 256),
block_list: Tuple[
int,
] = (1, 1, 6, 2),
#### HRViTAttention Config ####
dim_head: int = 32,
ws_list: Tuple[
int,
] = (1, 2, 7, 7),
proj_dropout: float = 0.0,
drop_path_rates: Tuple[float] = (
0.0,
), # different droprate for different attn/mlp
#### MixCFN Config ####
mlp_ratio_list: Tuple[
int,
] = (4, 4, 4, 4),
dropout: float = 0.0,
#### Gradient Checkpointing #####
with_cp: bool = False,
) -> None:
super().__init__()
self.patch_embed = nn.ModuleList(
[
HRViTPatchEmbed(
in_channels=inc,
patch_size=3,
stride=1,
dim=outc,
)
for inc, outc in zip(in_channels, out_channels)
]
) # one patch embedding for each branch
## we arrange blocks in stages/layers
n_inputs = len(out_channels)
self.branches = nn.ModuleList([])
for i, n_blocks in enumerate(block_list[:n_inputs]):
blocks = []
for j in range(n_blocks):
blocks += [
HRViTBlock(
in_dim=out_channels[i],
dim=out_channels[i],
heads=out_channels[i] // dim_head, # automatically derive heads
proj_dropout=proj_dropout,
mlp_ratio=mlp_ratio_list[i],
drop_path=drop_path_rates[j],
ws=ws_list[i],
with_cp=with_cp,
)
]
blocks = nn.ModuleList(blocks)
self.branches.append(blocks)
self.norm = nn.ModuleList([nn.LayerNorm(outc) for outc in out_channels])
def forward(
self,
x: Tuple[
Tensor,
],
) -> Tuple[Tensor,]:
B = x[0].shape[0]
x = list(x)
H, W = [], []
## patch embed
for i, (xx, embed) in enumerate(zip(x, self.patch_embed)):
xx, h, w = embed(xx)
x[i] = xx
H.append(h)
W.append(w)
## HRViT blocks
for i, (branch, h, w) in enumerate(zip(self.branches, H, W)):
for block in branch:
x[i] = block(x[i], h, w)
## LN at the end of each stage
for i, (xx, norm, h, w) in enumerate(zip(x, self.norm, H, W)):
xx = norm(xx)
xx = xx.reshape(B, h, w, -1).permute(0, 3, 1, 2).contiguous()
x[i] = xx
return x
class HRViT(nn.Module):
def __init__(
self,
#### HRViT Stem Config ####
in_channels: int = 3,
stride: int = 4,
channels: int = 64,
#### Branch Config ####
channel_list: Tuple[Tuple[int,],] = (
(32,),
(32, 64),
(32, 64, 128),
(32, 64, 128),
(32, 64, 128, 256),
(32, 64, 128, 256),
),
block_list: Tuple[Tuple[int]] = (
(1,),
(1, 1),
(1, 1, 6),
(1, 1, 6),
(1, 1, 6, 2),
(1, 1, 2, 2),
),
#### HRViTAttention Config ####
dim_head: int = 32,
ws_list: Tuple[
int,
] = (1, 2, 7, 7),
proj_dropout: float = 0.0,
drop_path_rate: float = 0.0, # different droprate for different attn/mlp
#### HRViTFeedForward Config ####
mlp_ratio_list: Tuple[
int,
] = (4, 4, 4, 4),
dropout: float = 0.0,
#### Classification Head Config ####
num_classes: int = 1000,
head_dropout: float = 0.1,
#### Gradient Checkpointing #####
with_cp: bool = False,
) -> None:
super().__init__()
self.features = []
self.ws_list = ws_list
self.head_dropout = head_dropout
self.with_cp = with_cp
# calculate drop path rates
total_blocks = sum(max(b) for b in block_list)
total_drop_path_rates = (
torch.linspace(0, drop_path_rate, total_blocks).numpy().tolist()
)
cur = 0
self.channel_list = channel_list = [[channels]] + list(channel_list)
# build stem
self.stem = HRViTStem(
in_channels=in_channels, out_channels=channels, kernel_size=3, stride=4
)
# build backbone
for i, blocks in enumerate(block_list):
inc, outc = channel_list[i : i + 2]
depth_per_stage = max(blocks)
self.features.extend(
[
HRViTFusionBlock(
in_channels=inc,
out_channels=inc
if len(inc) == len(outc)
else list(inc) + [outc[-1]],
act_func=nn.GELU,
with_cp=False,
),
HRViTStage(
#### Patch Embed Config ####
in_channels=inc
if len(inc) == len(outc)
else list(inc) + [outc[-1]],
out_channels=outc,
block_list=blocks,
dim_head=dim_head,
#### HRViTBlock Config ####
ws_list=ws_list,
proj_dropout=proj_dropout,
drop_path_rates=total_drop_path_rates[
cur : cur + depth_per_stage
], # different droprate for different attn/mlp
#### MixCFN Config ####
mlp_ratio_list=mlp_ratio_list,
dropout=dropout,
#### Gradient Checkpointing #####
with_cp=with_cp,
),
]
)
cur += depth_per_stage
self.features = nn.Sequential(*self.features)
# build classification head
self.head = HRViTClassifier(
in_channels=channel_list[-1],
num_classes=num_classes,
dropout=head_dropout,
)
@torch.jit.ignore
def no_weight_decay(self):
return {
"pos_embed", "cls_token"}
def get_classifier(self):
return self.head
def reset_classifier(self, num_classes, global_pool=""):
if self.num_classes != num_classes:
logger.info("Reset head to", num_classes)
self.num_classes = num_classes
self.head = HRViTClassifier(
in_channels=self.channel_list[-1],
num_classes=num_classes,
dropout=self.head_dropout,
).cuda()
def forward_features(
self, x: Tensor
) -> Tuple[Tensor,]:
# stem
x = self.stem(x)
# backbone
x = self.features((x,))
return x
def forward(self, x: Tensor) -> Tensor:
# stem and backbone
x = self.forward_features(x)
# classifier
x = self.head(x)
return x
@register_model
def HRViT_b1_224(pretrained=False, **kwargs):
model = HRViT(
stride=4,
channels=64,
channel_list=(
(32,),
(32, 64),
(32, 64, 128),
(32, 64, 128),
(32, 64, 128, 256),
(32, 64, 128, 256),
),
block_list=(
(1,),
(1, 1),
(1, 1, 6),
(1, 1, 6),
(1, 1, 6, 2),
(1, 1, 2, 2),
),
dim_head=32,
ws_list=(1, 2, 7, 7),
proj_dropout=0.0,
# drop_path_rate=0.1,
mlp_ratio_list=(4, 4, 4, 4),
dropout=0.0,
# head_dropout=0.1,
**kwargs,
)
model.default_cfg = default_cfgs["hrvit_224"]
return model
@register_model
def HRViT_b2_224(pretrained=False, **kwargs):
model = HRViT(
stride=4,
channels=64,
channel_list=(
(48,),
(48, 96),
(48, 96, 240),
(48, 96, 240),
(48, 96, 240, 384),
(48, 96, 240, 384),
),
block_list=(
(1,),
(1, 1),
(1, 1, 6),
(1, 1, 6),
(1, 1, 6, 2),
(1, 1, 6, 2),
),
dim_head=24,
ws_list=(1, 2, 7, 7),
proj_dropout=0.0,
# drop_path_rate=0.1,
mlp_ratio_list=(2, 3, 3, 3),
dropout=0.0,
# head_dropout=0.1,
**kwargs,
)
model.default_cfg = default_cfgs["hrvit_224"]
return model
@register_model
def HRViT_b3_224(pretrained=False, **kwargs):
model = HRViT(
stride=4,
channels=64,
channel_list=(
(64,),
(64, 128),
(64, 128, 256),
(64, 128, 256),
(64, 128, 256, 512),
(64, 128, 256, 512),
),
block_list=(
(1,),
(1, 1),
(1, 1, 6),
(1, 1, 6),
(1, 1, 6, 3),
(1, 1, 6, 3),
),
dim_head=32,
ws_list=(1, 2, 7, 7),
proj_dropout=0.0,
# drop_path_rate=0.1,
mlp_ratio_list=(2, 2, 2, 2),
dropout=0.0,
# head_dropout=0.1,
**kwargs,
)
model.default_cfg = default_cfgs["hrvit_224"]
return model
if __name__ == '__main__':
from thop import profile
model = HRViT_b1_224(num_classes=1000)
input = torch.randn(1, 3, 224, 224)
flops, params = profile(model, inputs=(input,))
print("flops:{:.3f}G".format(flops/1e9))
print("params:{:.3f}M".format(params/1e6))
参考资料
Facebook提出HRViT:多尺度高分辨率视觉Transformer - 知乎 (zhihu.com)
【CVPR2022】Multi-Scale High-Resolution Vision Transformer for Semantic Segmentation - 知乎 (zhihu.com)