目录
1. 只出现一次的数字
题目链接:136. 只出现一次的数字
题目要求:
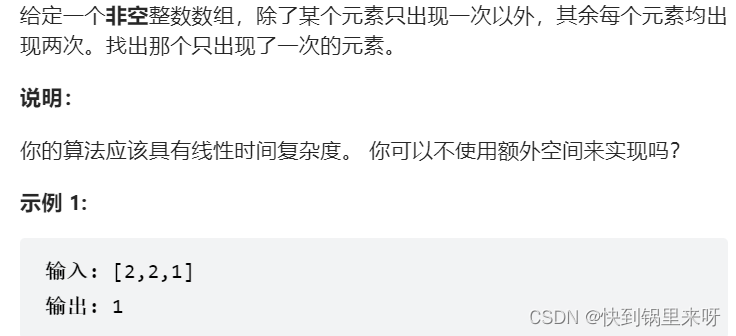
分析一下:

上代码:
//2.使用集合
//时间复杂度:O(n)
public int singleNumber(int[] nums) {
Set<Integer> set = new HashSet<>();
for(int i = 0; i < nums.length; i++) {
int key = nums[i];
if(!set.contains(key)) {
set.add(nums[i]);
}else {
set.remove(key);
}
}
//此时集合,就剩一个元素了 找到这个元素
for(int i = 0; i < nums.length; i++) {
int key = nums[i];
if(set.contains(key)) {
return nums[i];
}
}
return -1;
}2. 复制带随机指针的链表
题目链接:138. 复制带随机指针的链表
题目要求:

分析一下:
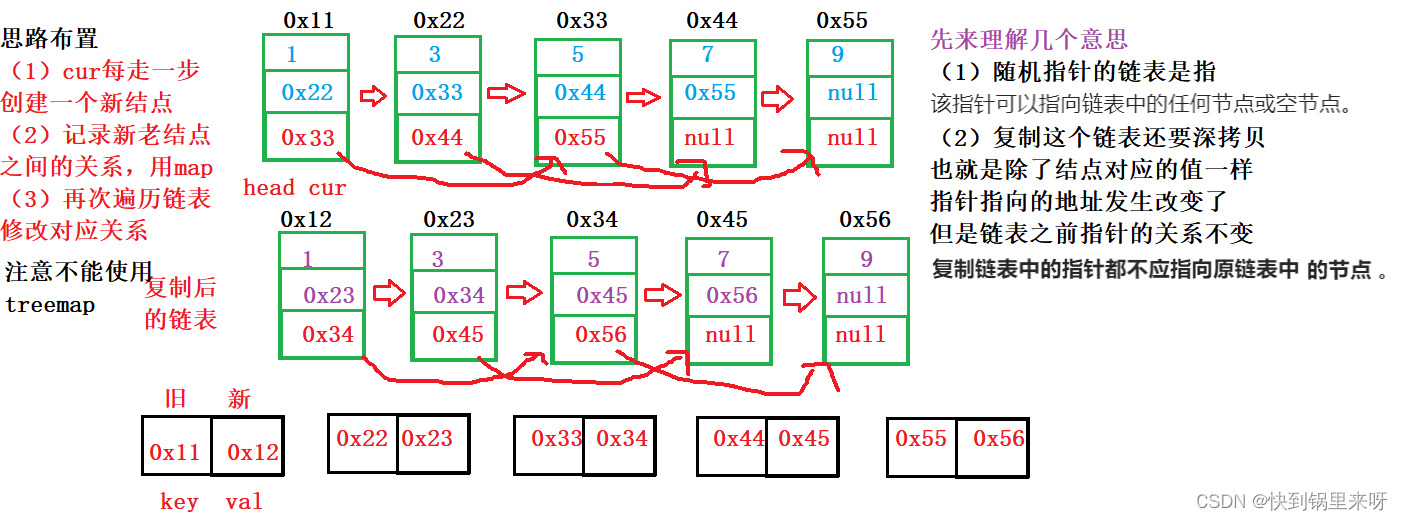
上代码:
class Solution {
public Node copyRandomList(Node head) {
//注意不能使用treemap不然不能比较
Map<Node,Node> map = new HashMap<>();
//1.第一次遍历链表
Node cur = head;
while(cur != null) {
Node node = new Node(cur.val);
map.put(cur,node);
cur = cur.next;
}
//2.第二次遍历链表
cur = head;
while(cur != null) {
map.get(cur).next = map.get(cur.next);
map.get(cur).random = map.get(cur.random);
cur = cur.next;
}
return map.get(head);
}
}3. 宝石与石头
题目链接:771. 宝石与石头
题目要求:

分析一下:

上代码:
class Solution {
public int numJewelsInStones(String jewels, String stones) {
Set<Character> set = new HashSet<>();
//把宝石放进集合中
for(char ch : jewels.toCharArray()) {
set.add(ch);
}
int count = 0;
//遍历石头,在石头中找宝石,计数++
for(char ch : stones.toCharArray()) {
if(set.contains(ch)) {
count++;
}
}
return count;
}
}4. 旧键盘
题目链接:旧键盘 (20)__牛客网 (nowcoder.com)
题目要求:

分析一下:

上代码:
import java.util.*;
public class Main {
public static void func(String str1,String str2) {
Set<Character> set = new HashSet<>();
//str2先转大写,再转数组,然后放入集合
for(char ch : str2.toUpperCase().toCharArray()) {
set.add(ch);
}
//遍历希望输入的,转为大写,再转数组,和实际输入进行比较
Set<Character> set2 = new HashSet<>();
for(char ch : str1.toUpperCase().toCharArray()) {
if(!set.contains(ch) && !set2.contains(ch)) {
System.out.print(ch);
set2.add(ch);
}
}
}
public static void main(String[] args) {
Scanner scan = new Scanner(System.in);
while(scan.hasNextLine()) {
String str1 = scan.nextLine();//希望输入的
String str2 = scan.nextLine();//实际输入的
func(str1,str2);
}
}
}5. 前k个高频单词
题目链接:692. 前K个高频单词
题目要求:

分析一下:

上代码:
class Solution {
public List<String> topKFrequent(String[] words, int k) {
//1.统计单词出现的次数
Map<String,Integer> map = new HashMap<>();
for(String key : words) {
if(map.get(key) == null) {
map.put(key,1);
}else {
int val = map.get(key);
map.put(key,val+1);
}
}
//2.建立大小为k的小根堆
PriorityQueue<Map.Entry<String,Integer>> minQ = new PriorityQueue<>(k,new Comparator<Map.Entry<String,Integer>>(){
@Override
public int compare(Map.Entry<String,Integer> o1, Map.Entry<String,Integer> o2) {
//单词出现次数相同时,调整以key为准的大根堆
if(o1.getValue().compareTo(o2.getValue()) == 0) {
return o2.getKey().compareTo(o1.getKey());
}
return o1.getValue().compareTo(o2.getValue());
//根据单词出现的次数创建小根堆
}
});
//3.遍历map,先给小根堆放满k个,然后从第k+1开始,和堆顶元素比较
for(Map.Entry<String,Integer> entry : map.entrySet()) {
if(minQ.size() < k) {
//如果小根堆没有放满,就继续放
minQ.offer(entry);
}else {
//如果已经放满了小根堆,那么此时就要让当前元素和堆顶元素进行比较
Map.Entry<String,Integer> top = minQ.peek();
if(top != null) {
if(entry.getValue() > top.getValue()) {
minQ.poll();
minQ.offer(entry);
}else {
//如果此时<不用管,但如果=,就要根据题意按字典顺序排
if(top.getValue().compareTo(entry.getValue()) == 0) {
//value一样,看key
if(top.getKey().compareTo(entry.getKey()) > 0) {
minQ.poll();
minQ.offer(entry);
}
}
}
}
}
}
//此时前k个次数最多的单词,已经全部放入堆中了,将堆中元素出堆
List<String> ret = new ArrayList<>();
for(int i = 0; i < k; i++) {
Map.Entry<String,Integer> top = minQ.poll();
if(top != null) {
ret.add(top.getKey());
}
}
//前面是小根堆出堆的,根据次数高到低的要求,这就要逆置
Collections.reverse(ret);
return ret;
}
}