文章目录
机器学习任务攻略
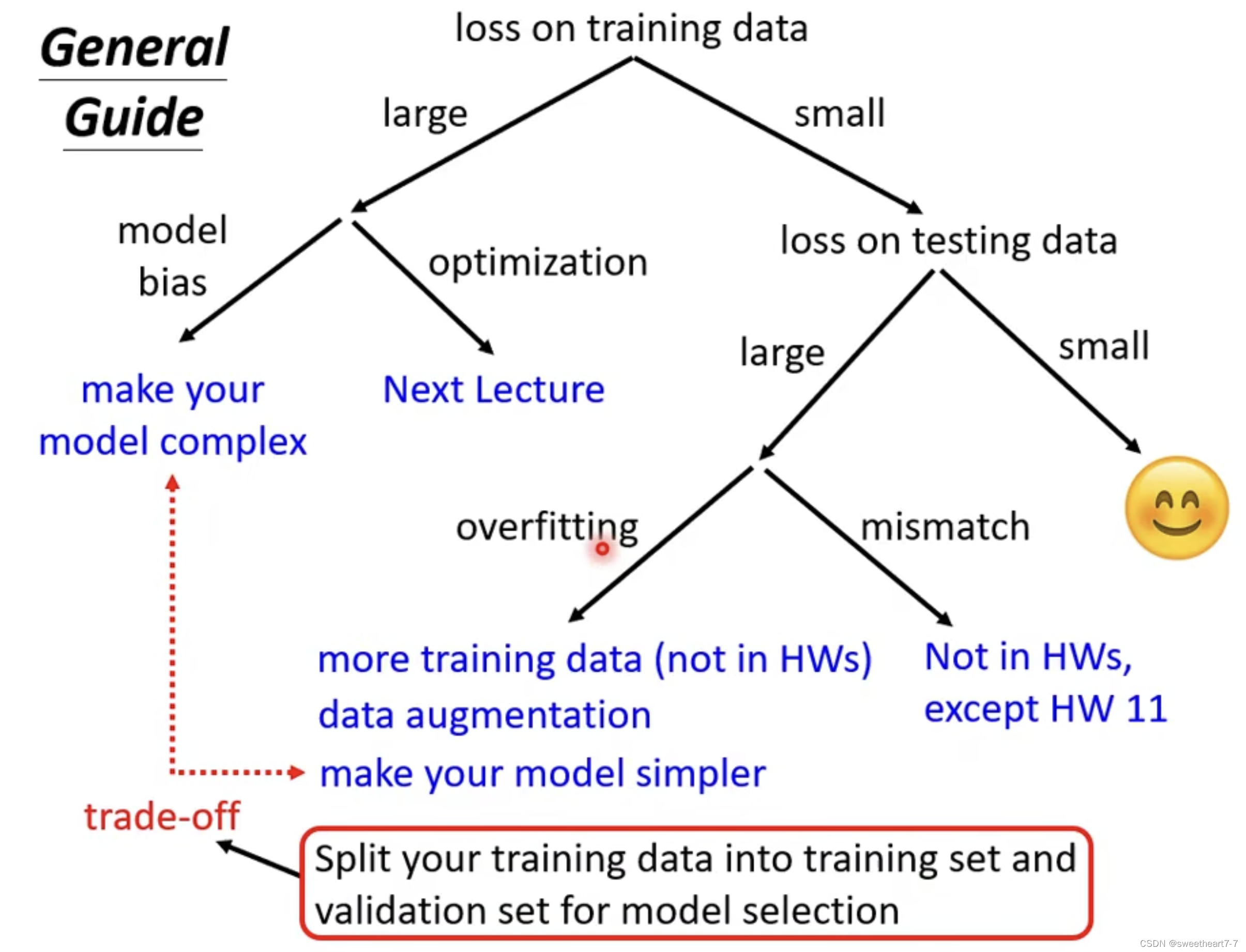
注意: 当 loss 在 training data 上就很大时,如果增加模型复杂度,但是 loss 并没有减少,大概率是 optimization 有问题。
解决 o v e r f i t t i n g overfitting overfitting 的几种常见办法:
- 减少模型复杂度,选择更简单更平滑的模型
- 增加训练集数据
- 减少参数或者共享参数
- 减少 feature
- Early stopping
- Regularization
- Dropout
如何尽可能选出在未知的 testing data 上面表现更好的 model
可以加入验证集来选更好的 model,通常采用 N 折交叉验证来分割数据集并进行验证。
类神经网络训练不起来怎么办
optimization Fails because…
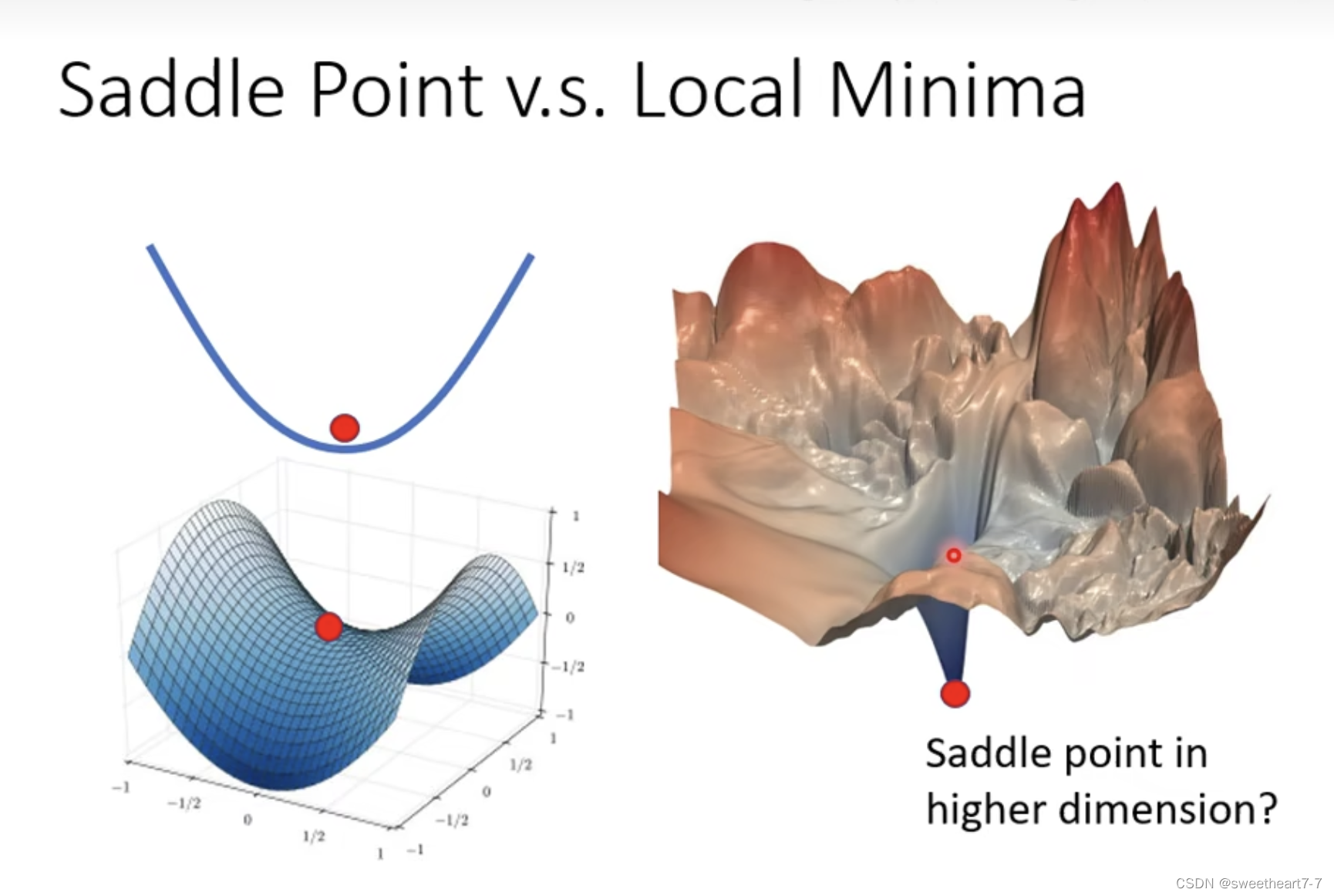
Local minima(局部最小值)与 saddle point(鞍点)
梯度为 0
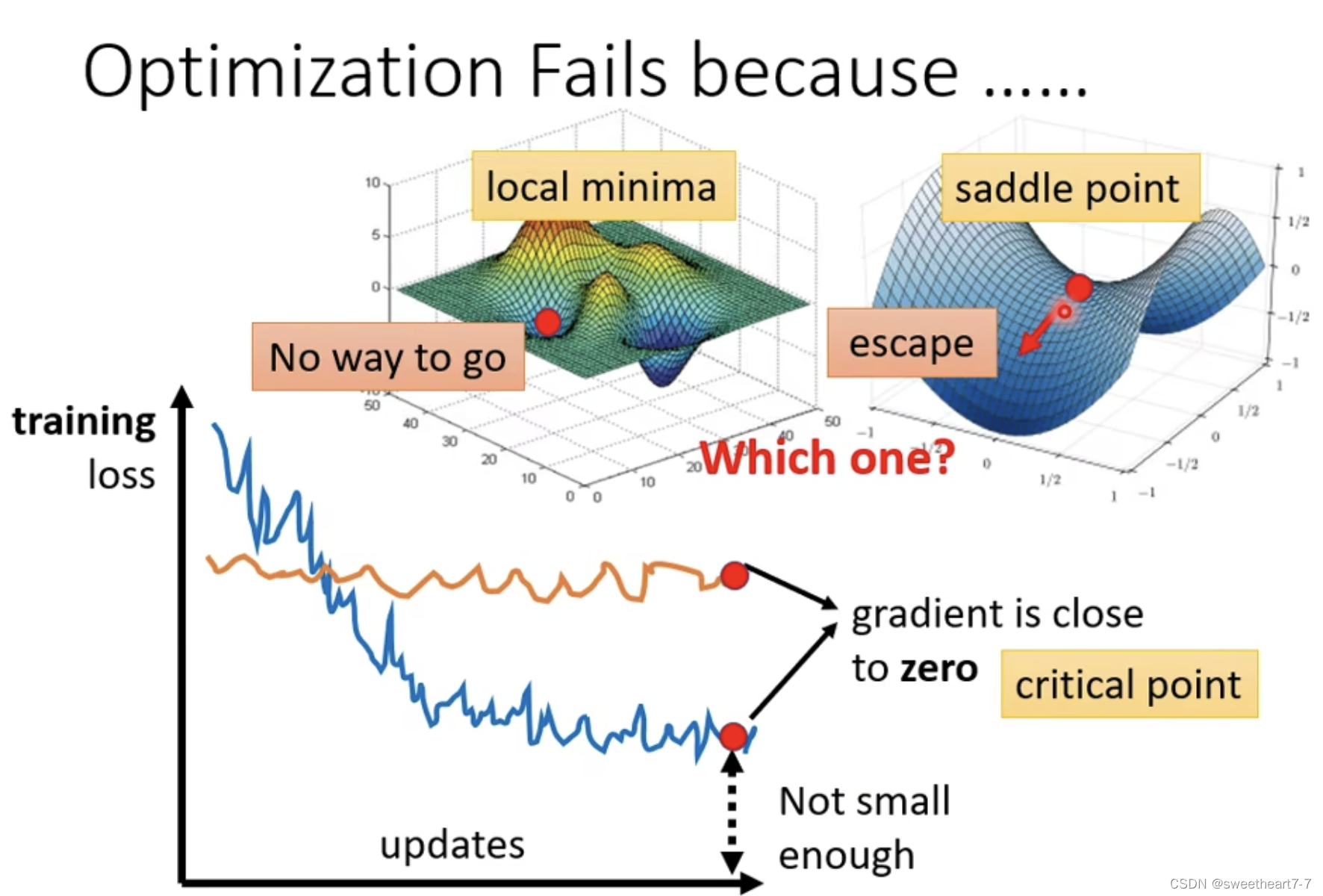
如何判断在 θ = θ ′ θ=θ' θ=θ′ Loss function 形状:通过泰勒级数展开描述。

当满足 critical point 时,grdient 为 0
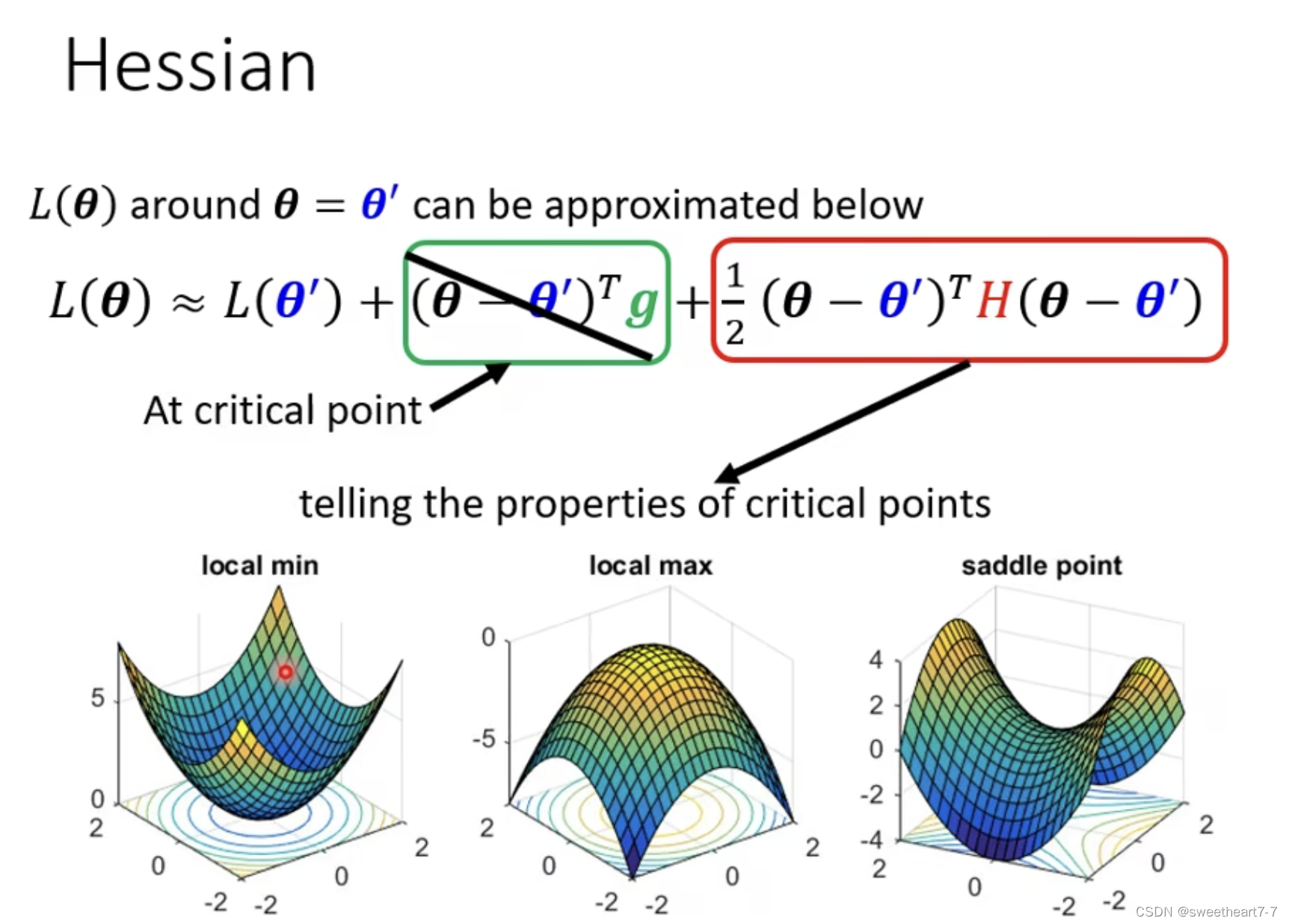
在 θ θ θ 为其他值时,如果都大于 L ( θ ′ ) L(θ') L(θ′) 时,说明此处是局部最小值点…
但是我们不可能带所有 v v v 值,所以可以转为如下判断:
满足 v T H v > 0 v^THv > 0 vTHv>0 的 H H H(hessian) 矩阵叫做 positive definite。
positive definite 的特性:所有的特征值都是正的。

例子:

当 critical point 是 saddle point(鞍点)时,可以通过 Hessian 来帮我们判断 update 的方向。
找特征值是 负的对应的 特征向量的方向,朝着此方向前进,就会使梯度减小。

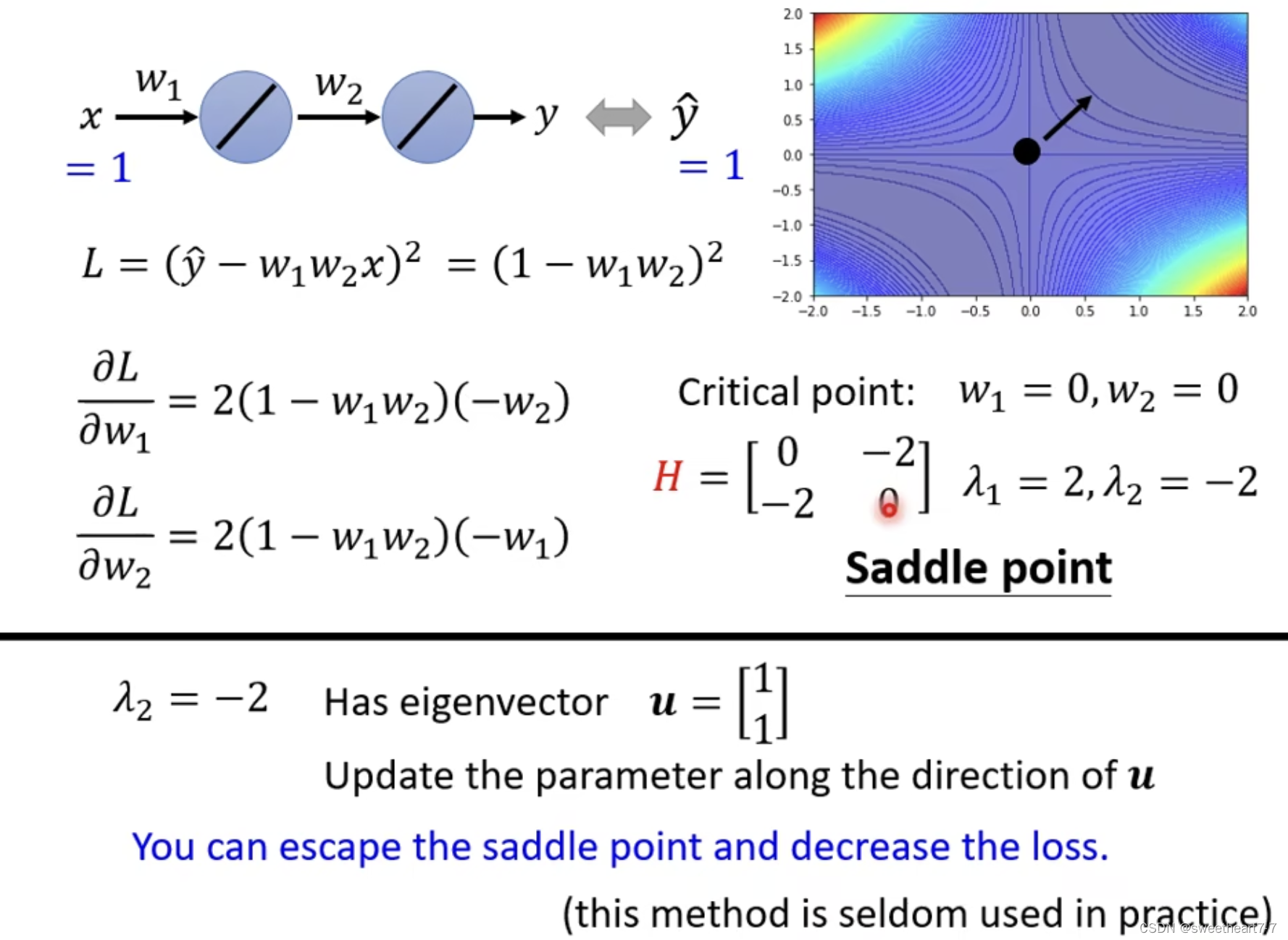
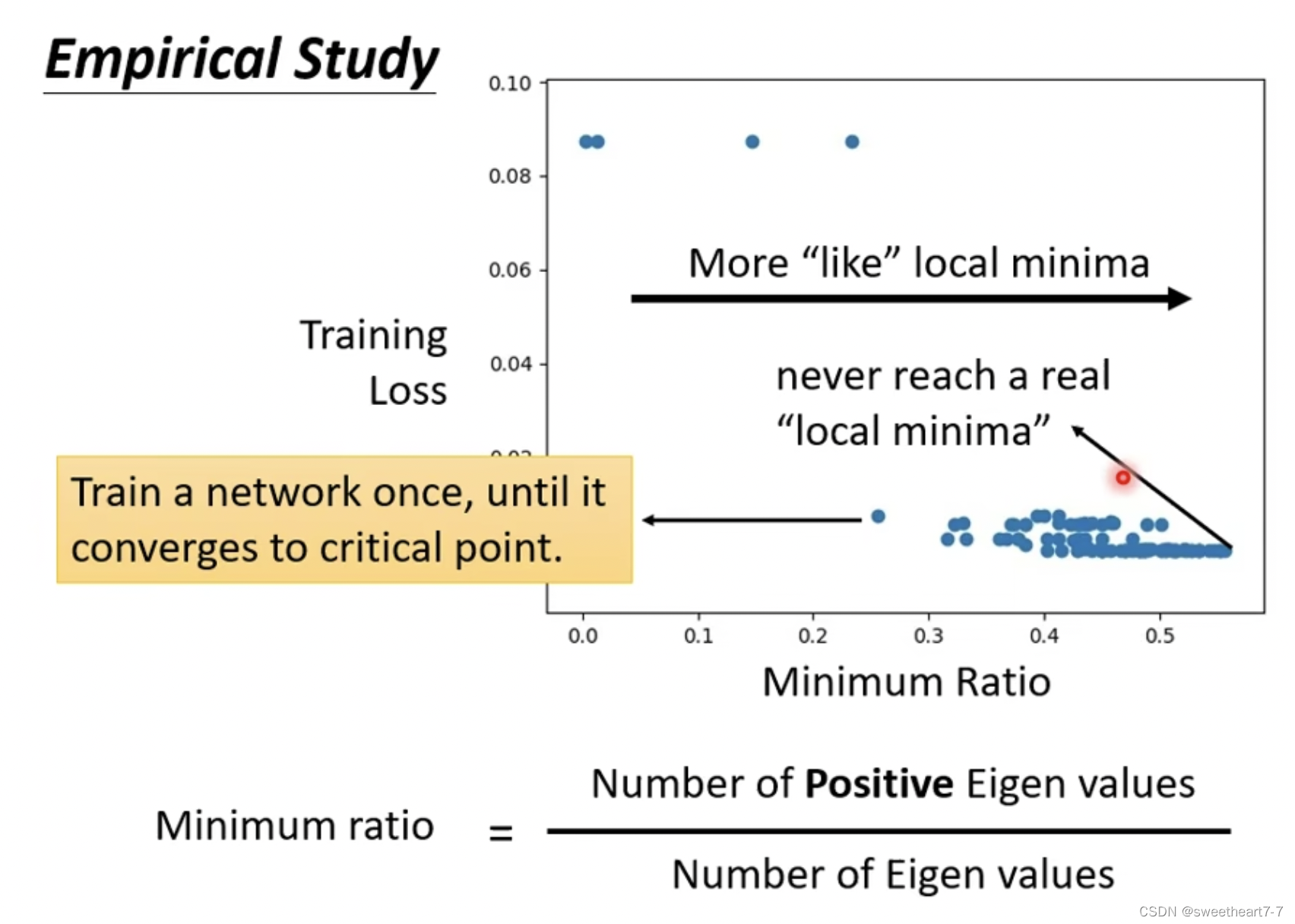
一个点代表一个 network。
纵轴代表训练停下时,Loss 的大小。
横轴代表训练停下时,特征值为正的特征值占所有特征值的比率。
所以在高维空间中大多数都是鞍点而不是局部最小值。
batch 与 momentum
batch
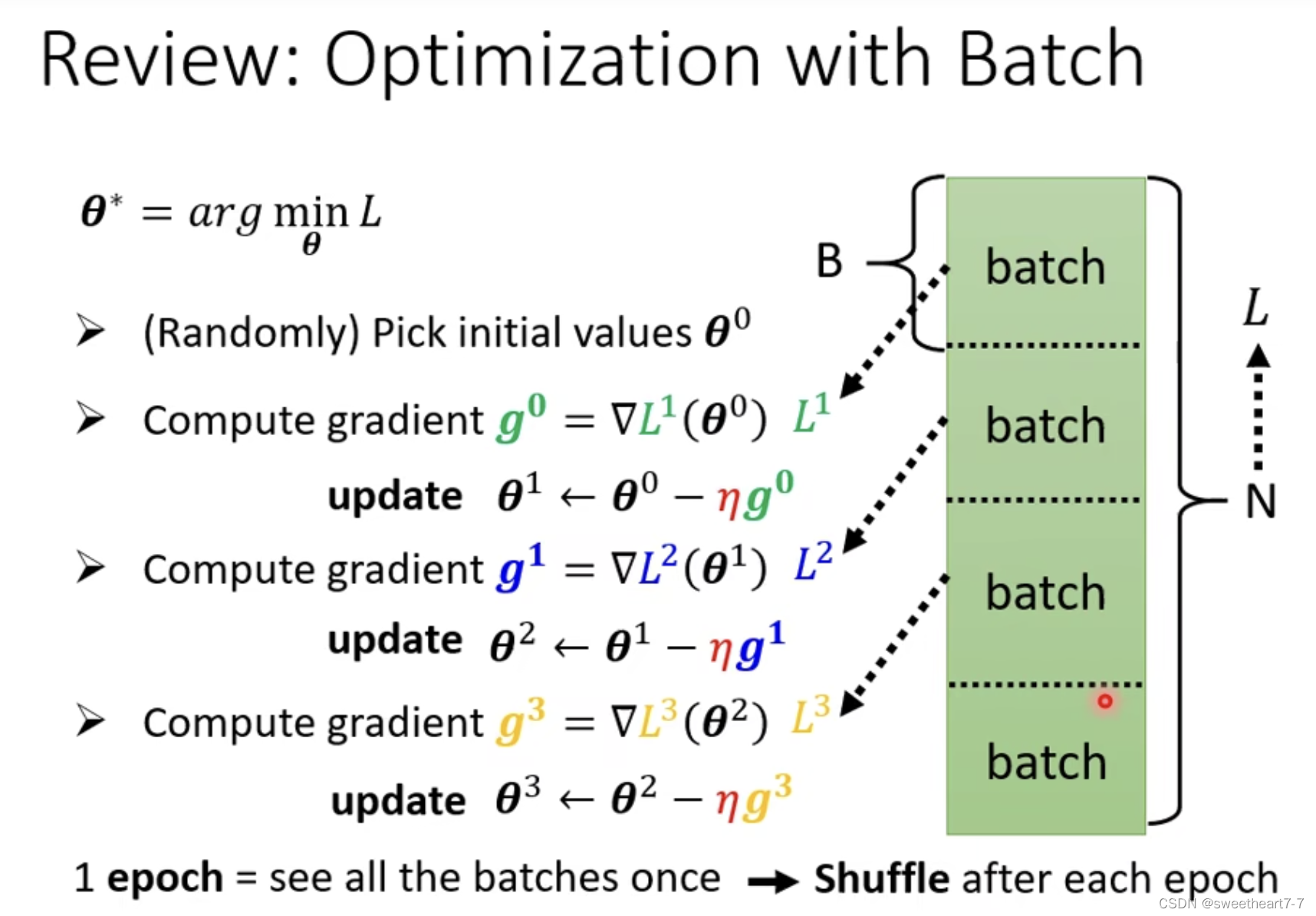
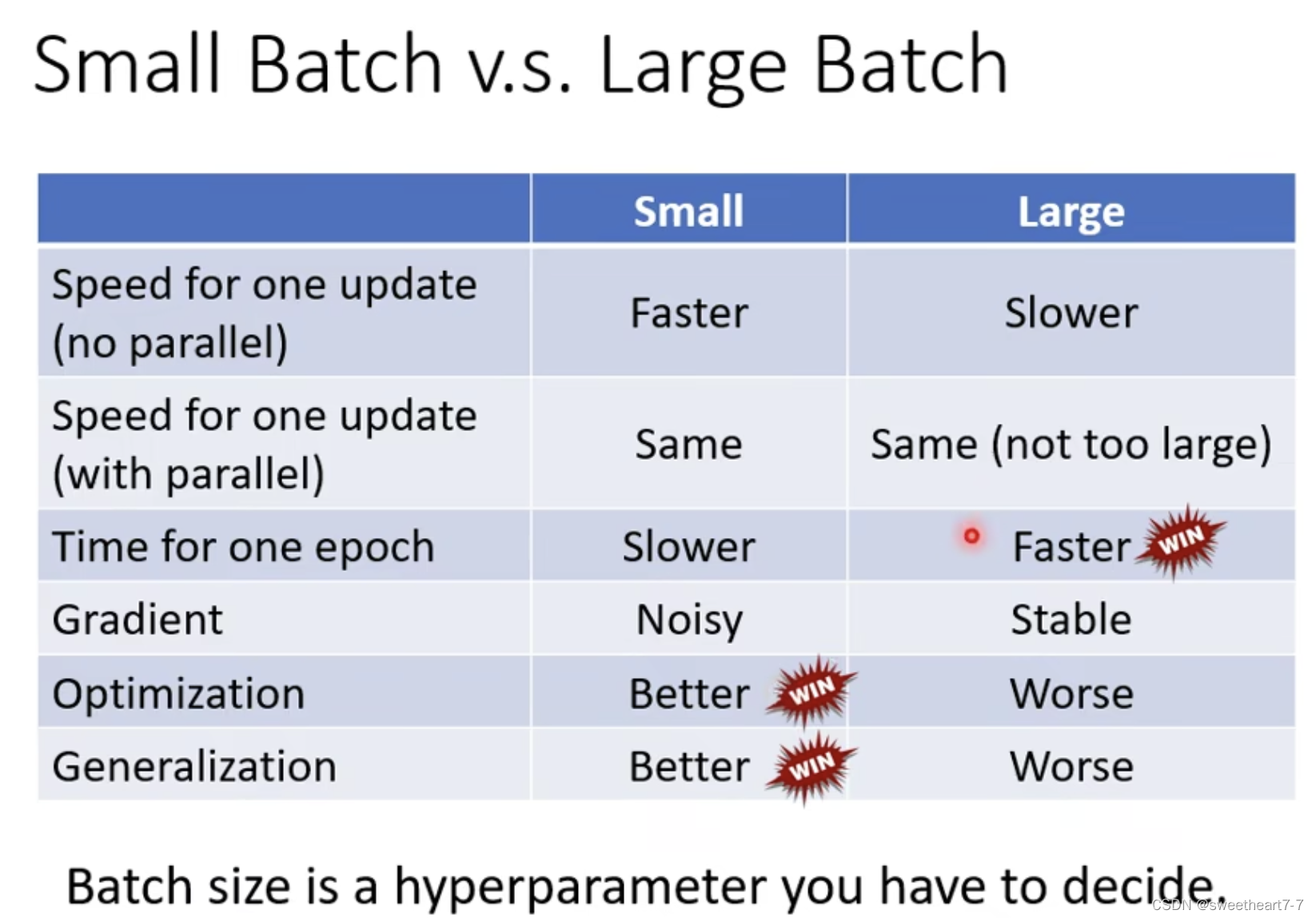
为什么要用 batch:每个 batch 都可以更新一波参数

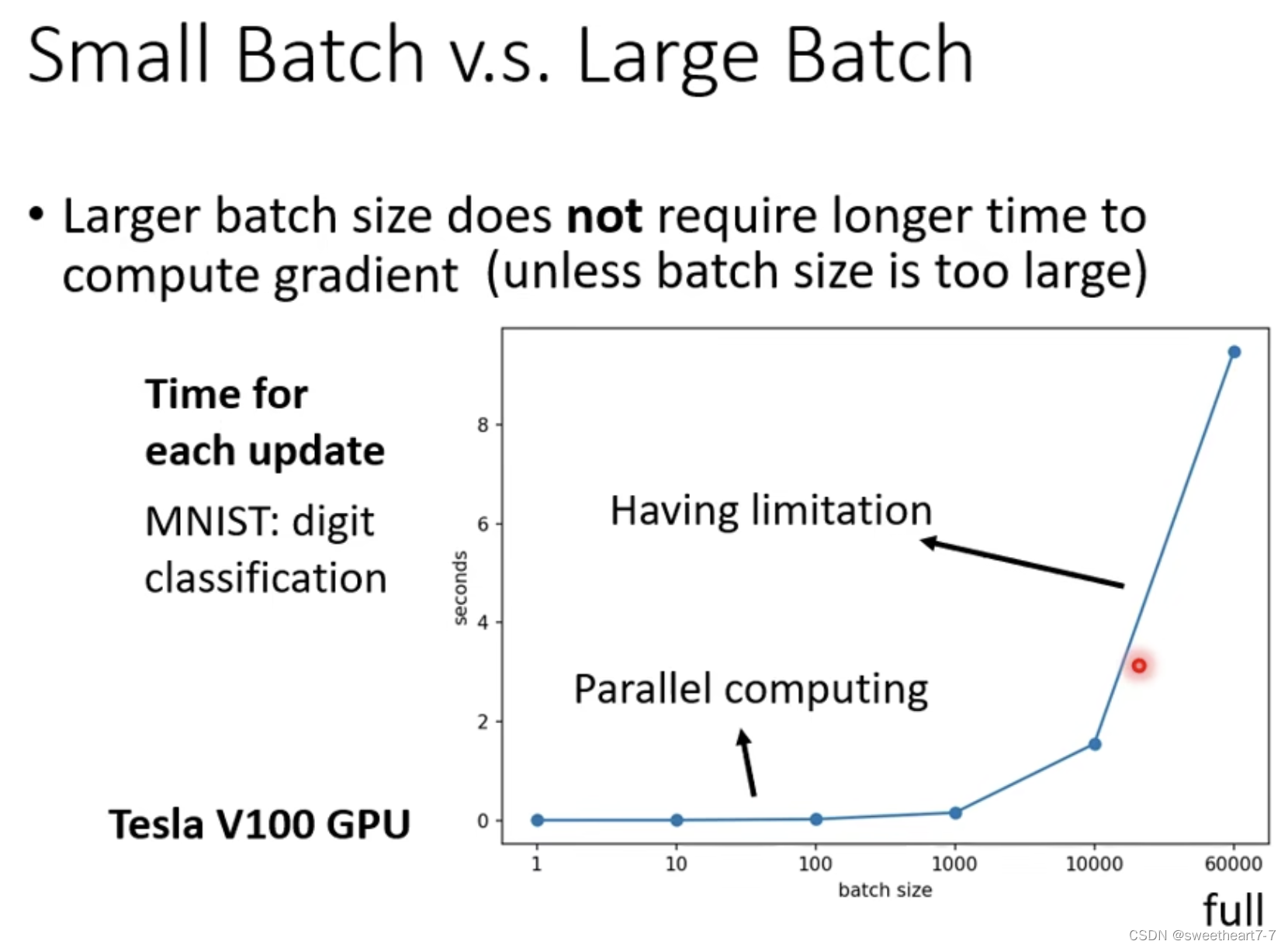
有并行运算时,batch size 大的可能训练一个 epoch 会更快。

但是在 batch size 小的 noise 对 optimization 可能有更好的结果。
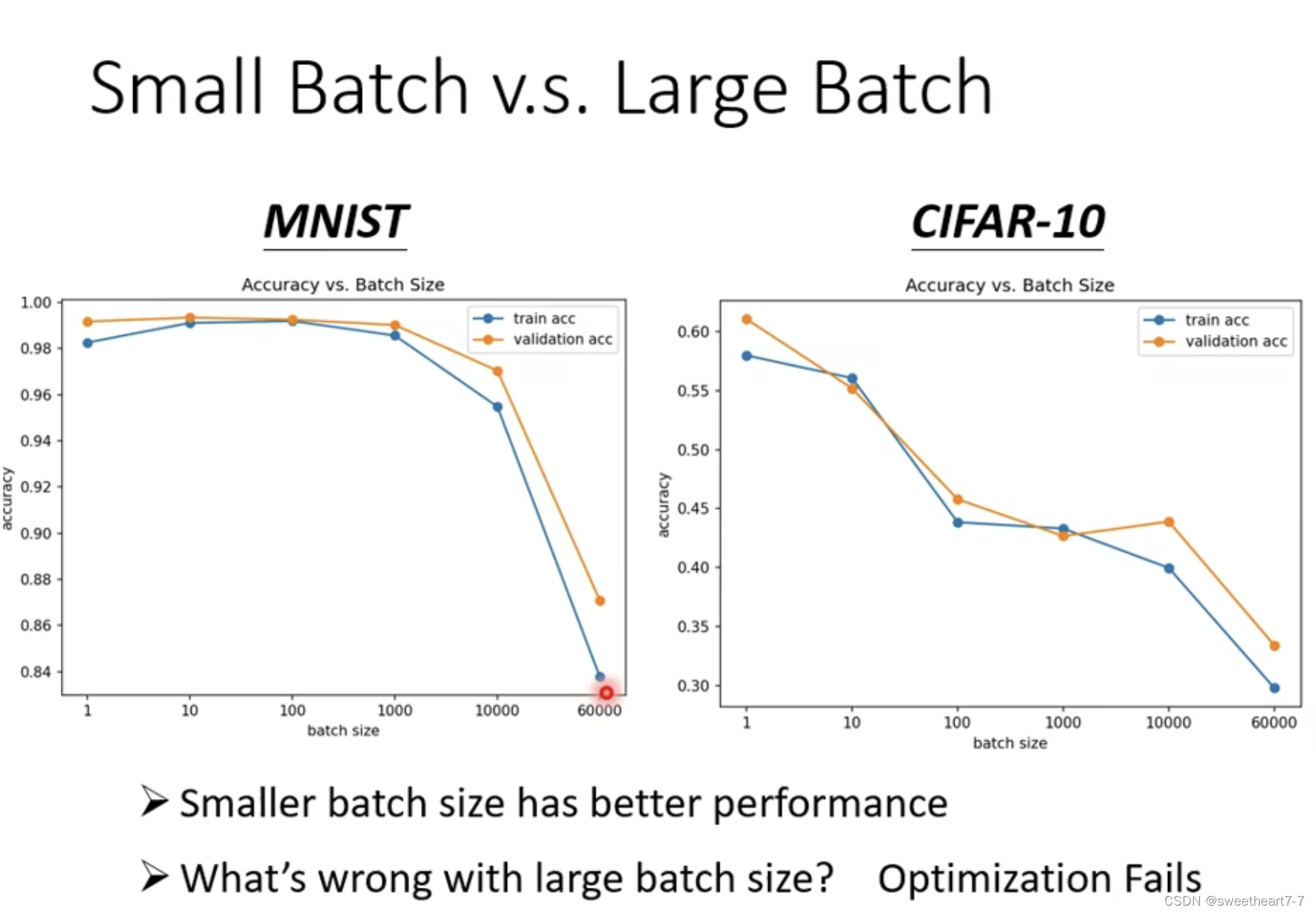
小的 batch 对 training 更好 可能的解释:
每次 batch 时对应的 loss function 有差异,对应的梯度有差异。
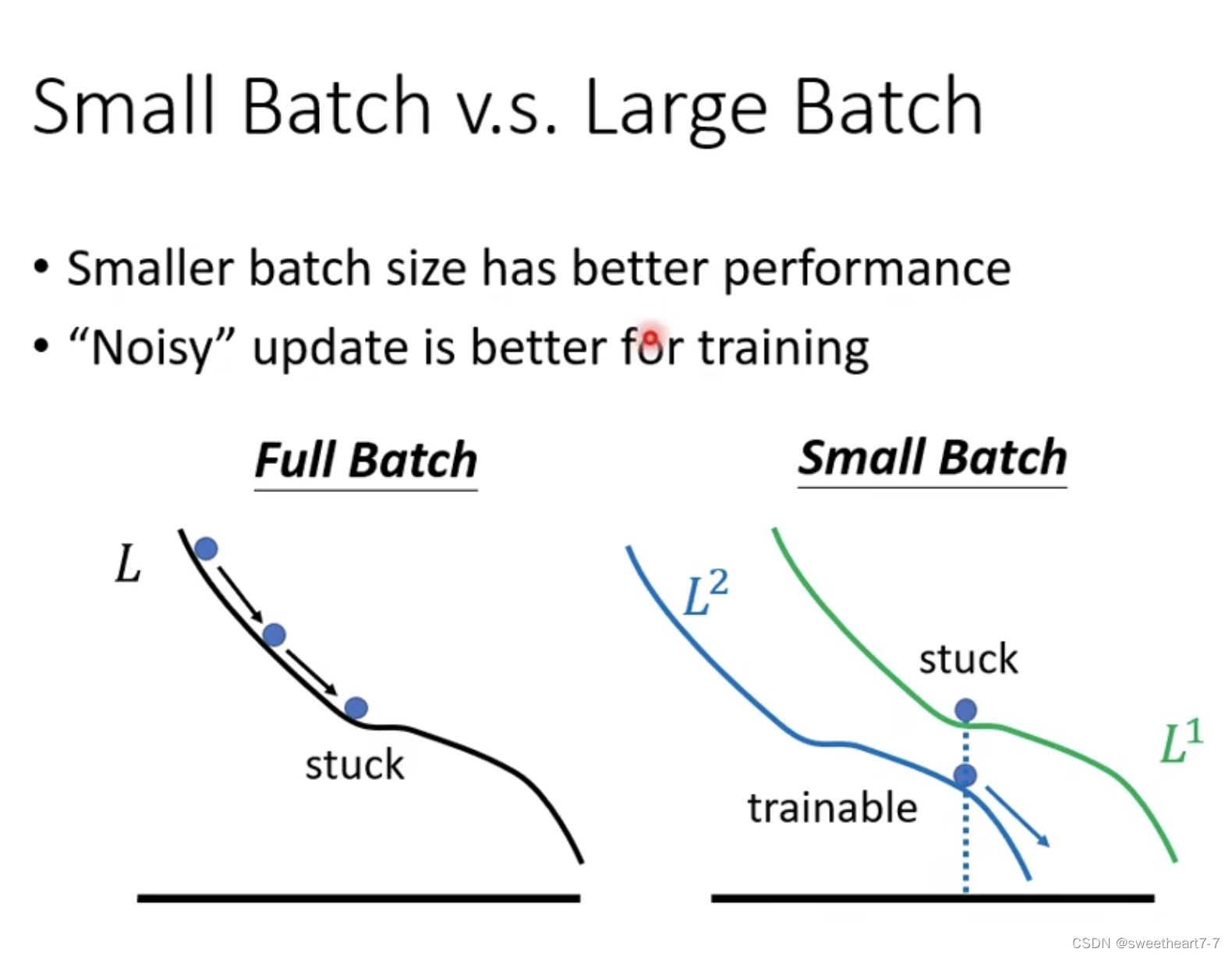
小 batch size 对 testing 更好:
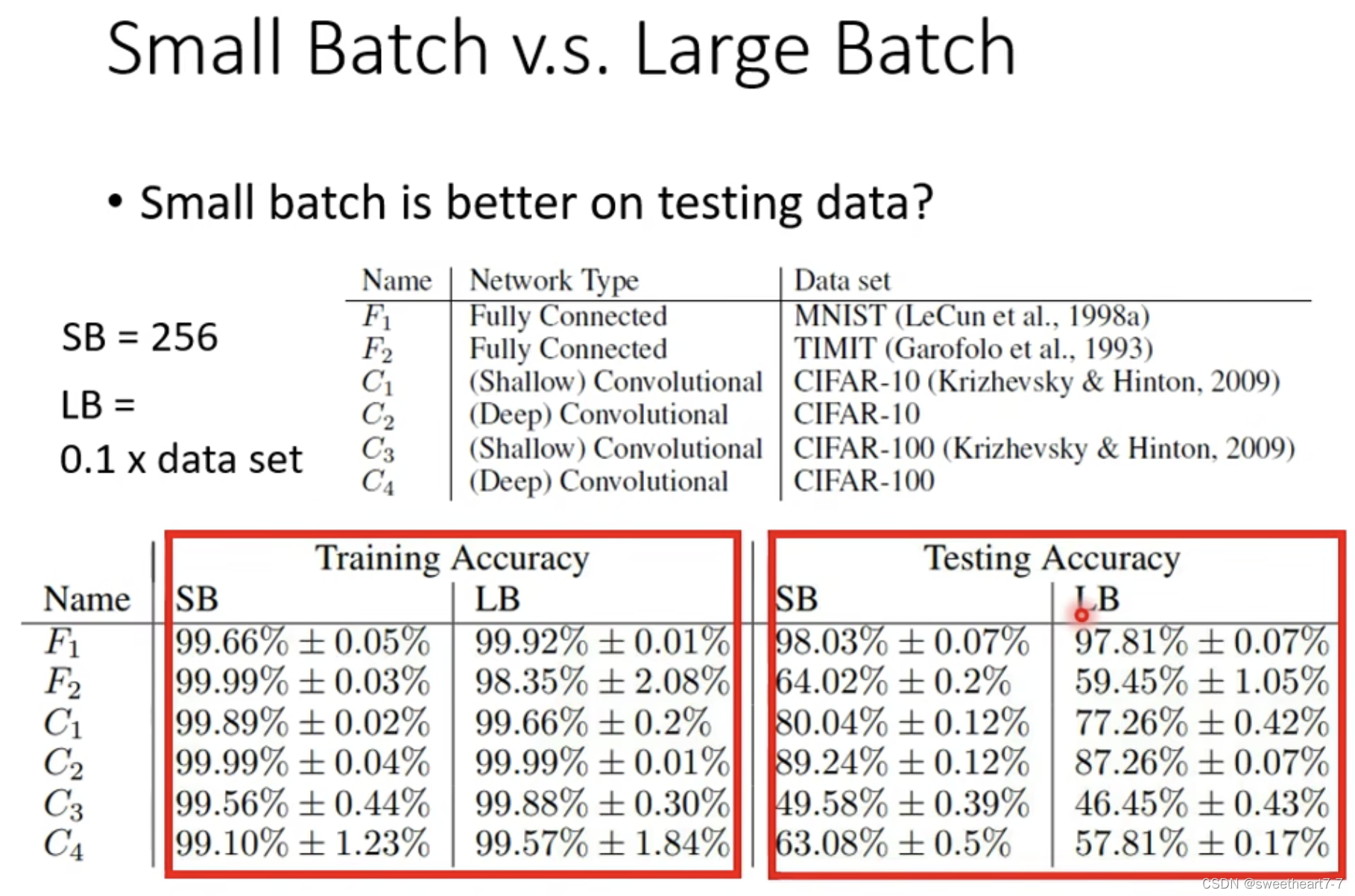
Local minima 也有好坏之分,平原上的 Local minima 更好,峡谷中的 Local minima 更差,而 大的 batch size 会更倾向于 峡谷中的 Local minima。
因为小的 batch size 的 update 方向具有随机性,其更容易跳出 Sharp Minima。
Momentum
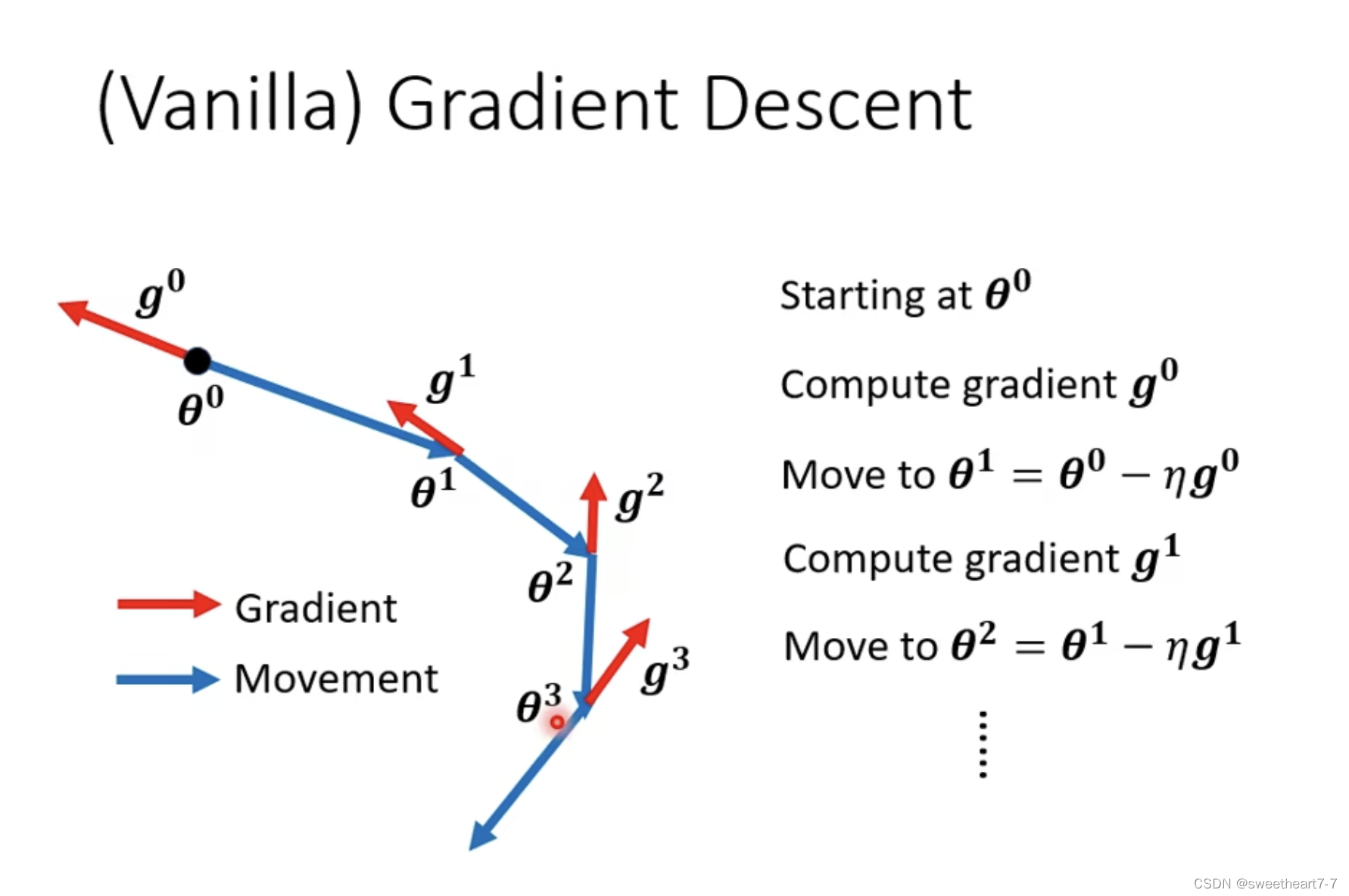
普通的 grident descent 在 update 时只会走 梯度的反方向
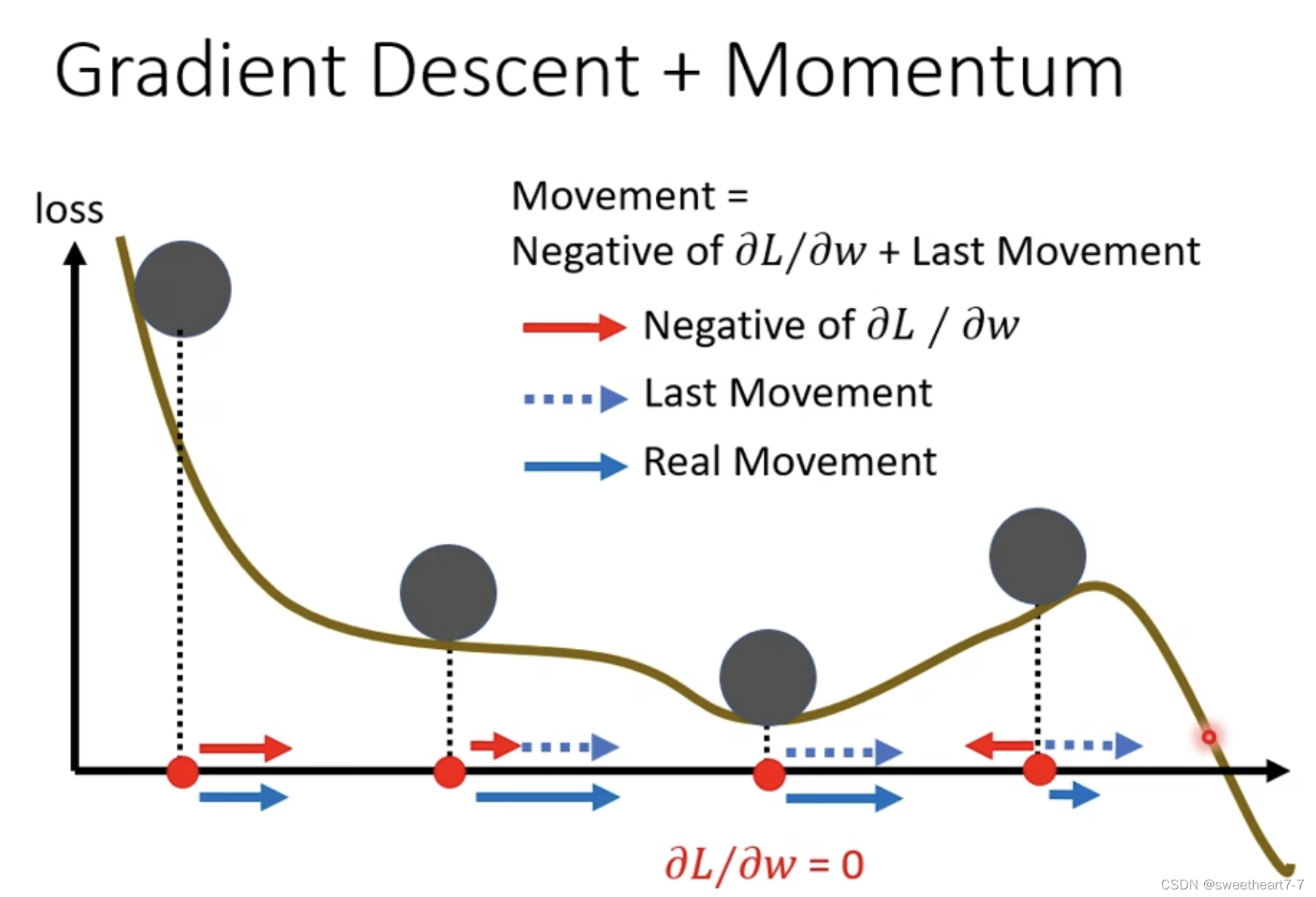
加上 Momentum 后,update 时,会走梯度的此时梯度的反方向以及 momentum(前一步所走的方向) 的和的反向。
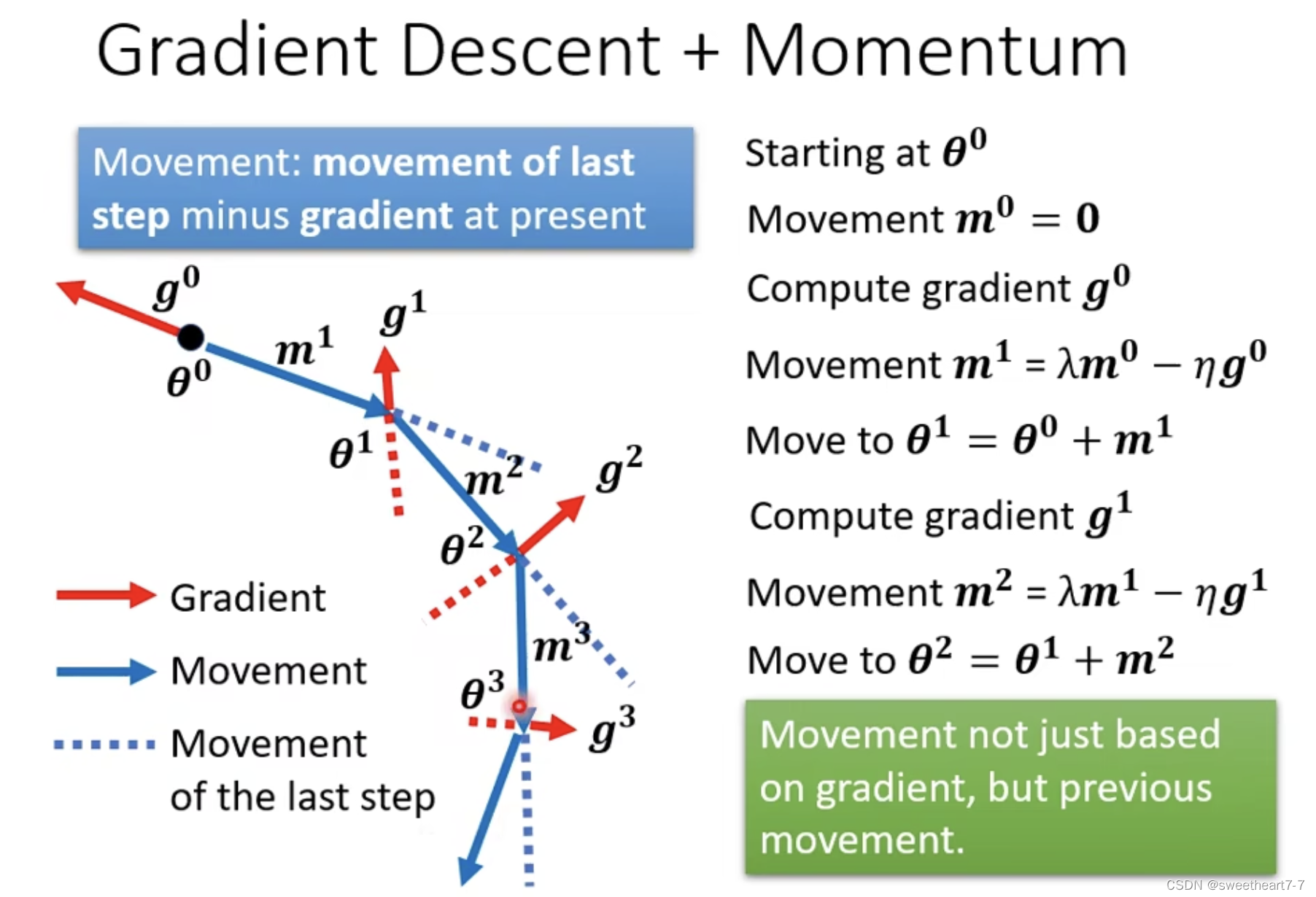
而 momentum 就是之前所有的前进方向的和。

自动调整学习率 (Learning Rate)
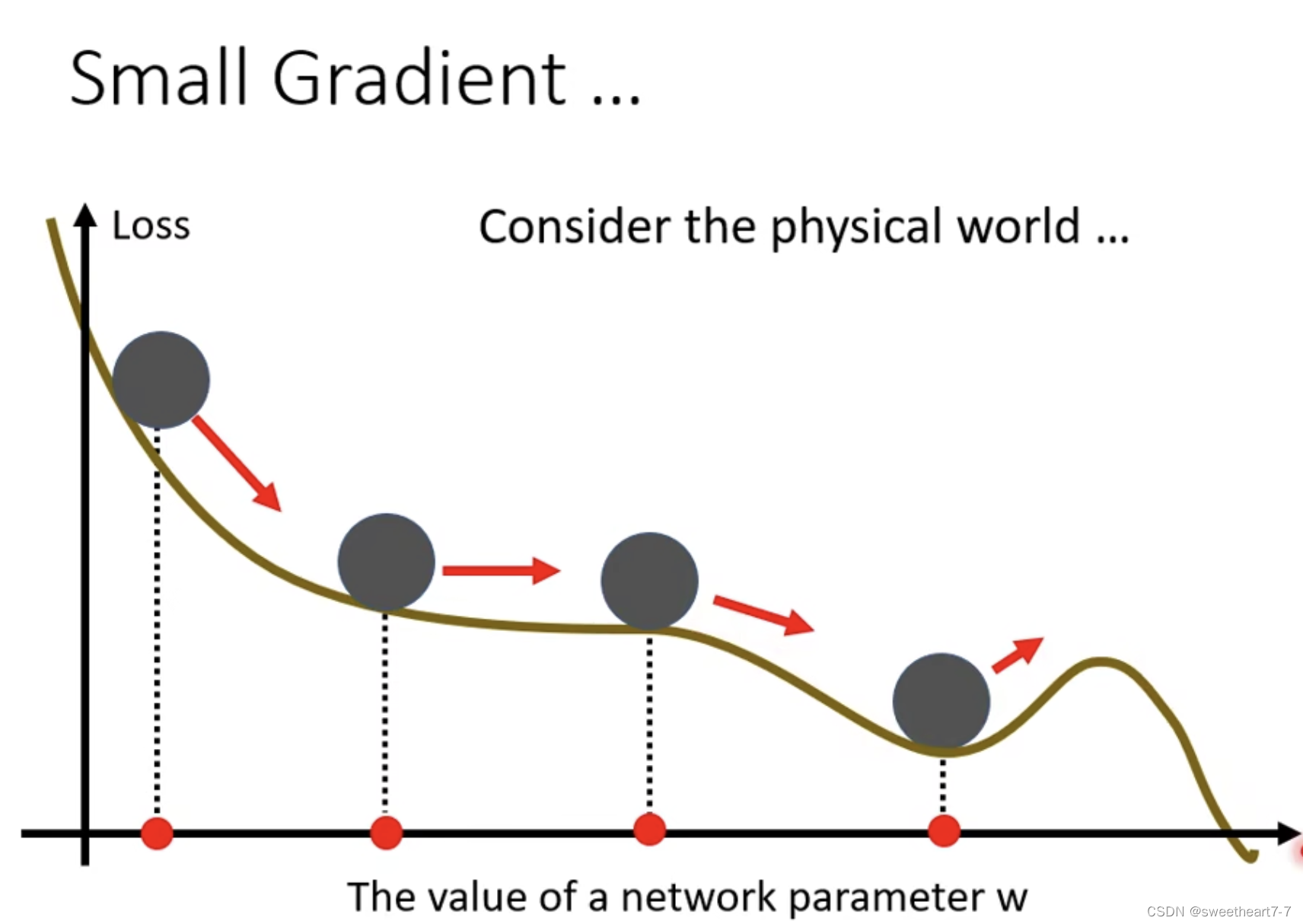
当 Loss 不下降的时候,不一定卡到 critical point 处(很难走到 critical point)。
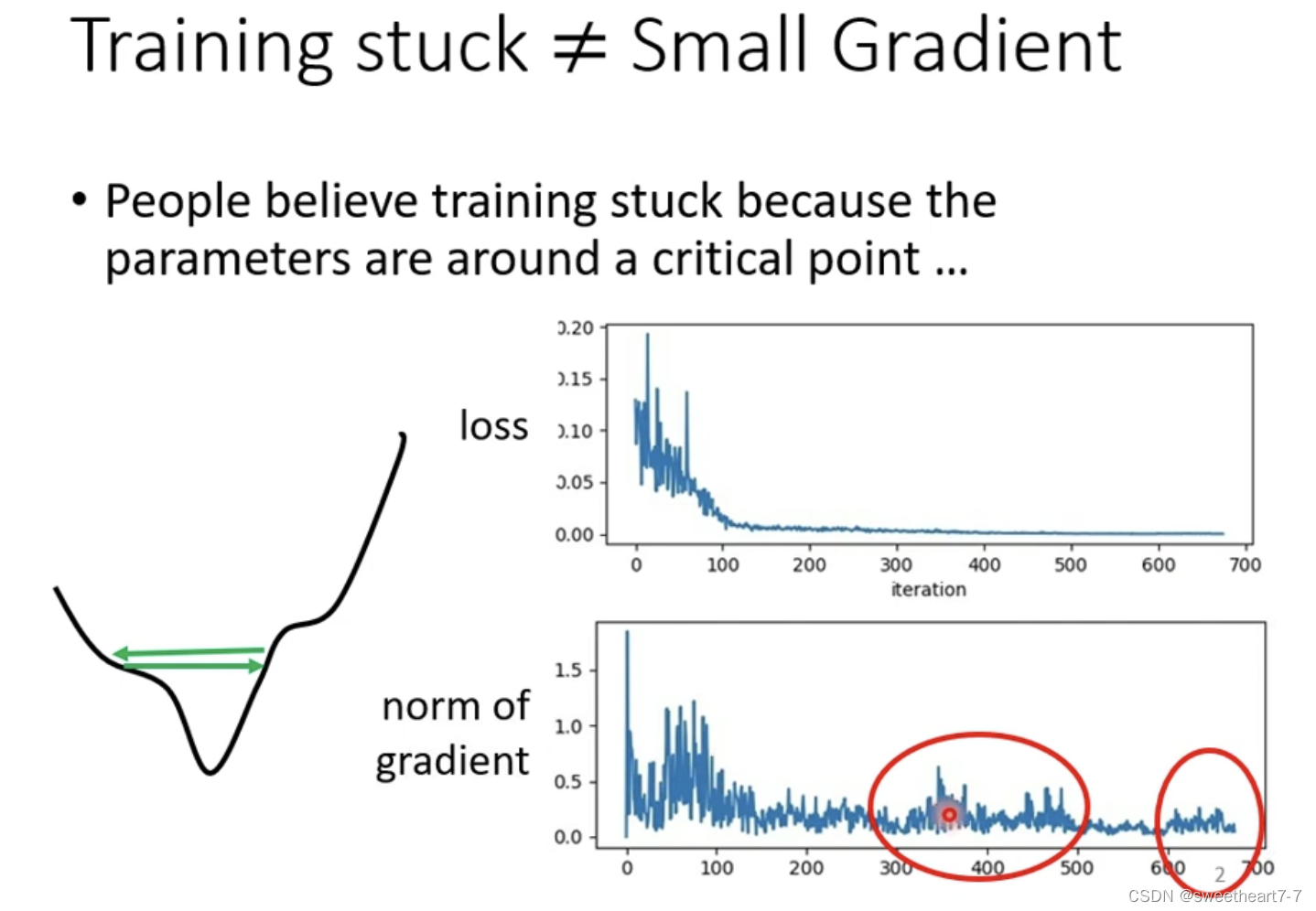
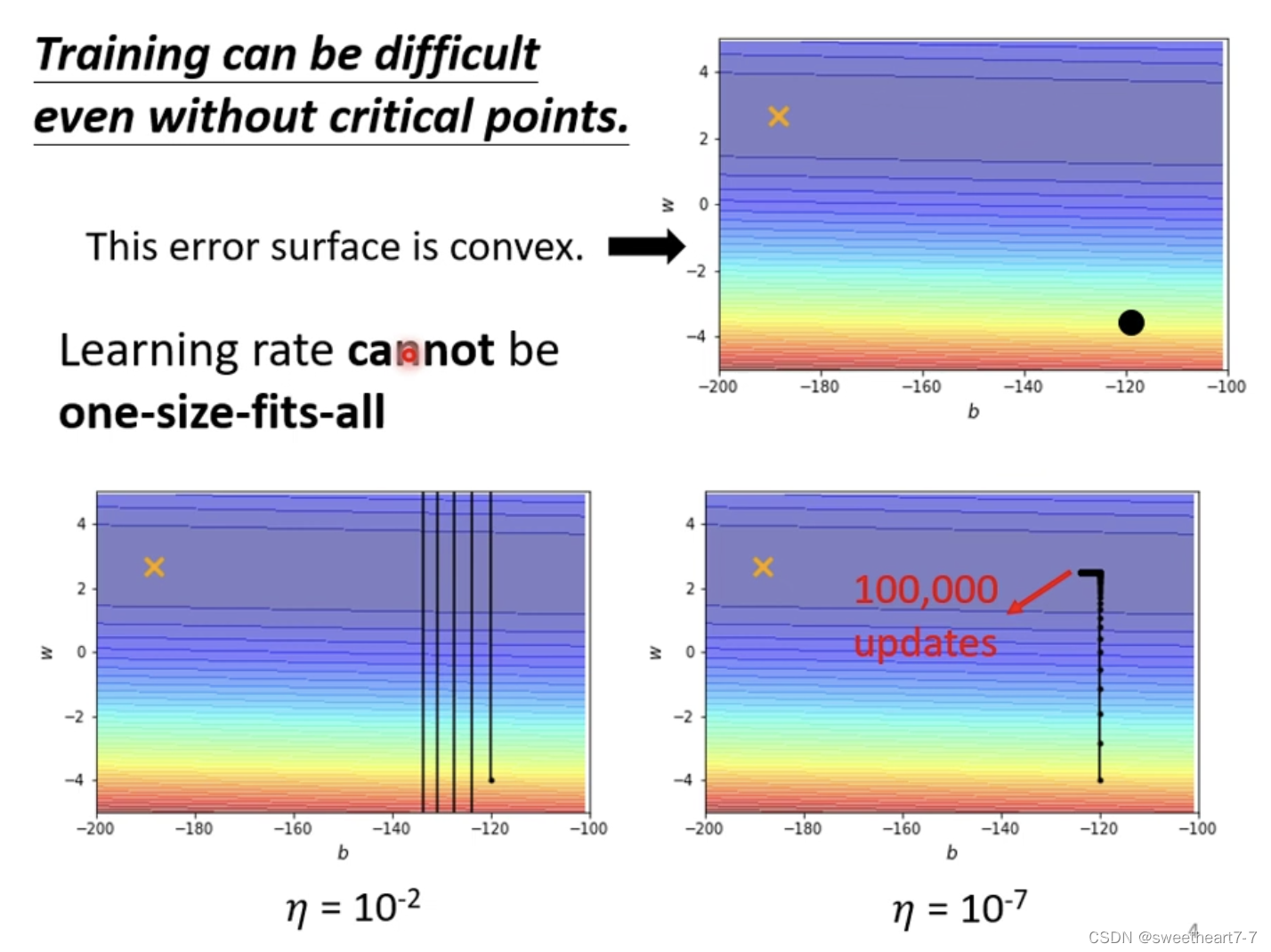
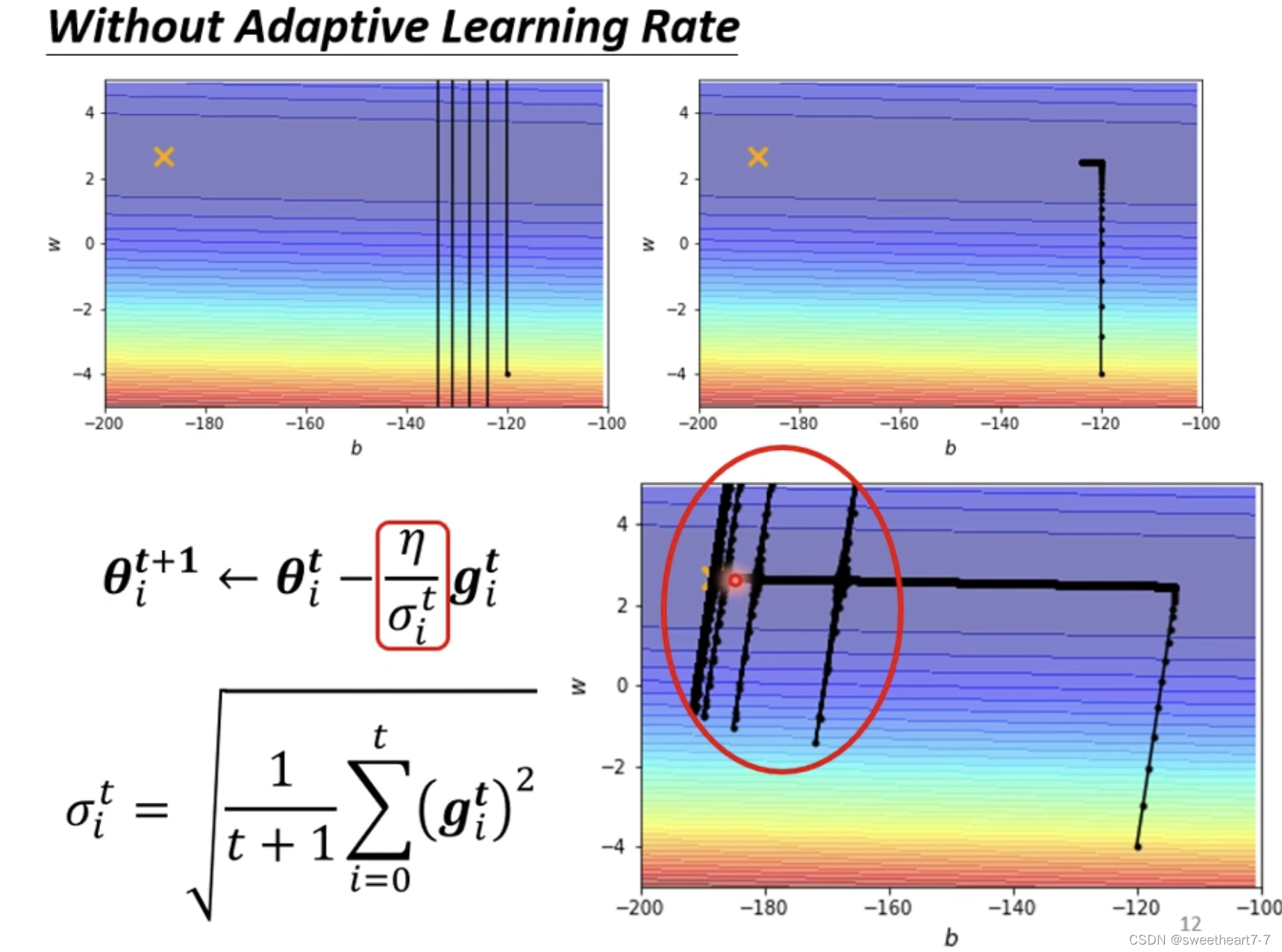
当 learning rate 为定植时,可能会出现上图两个问题(震荡 与 先正常然后走的特别慢)
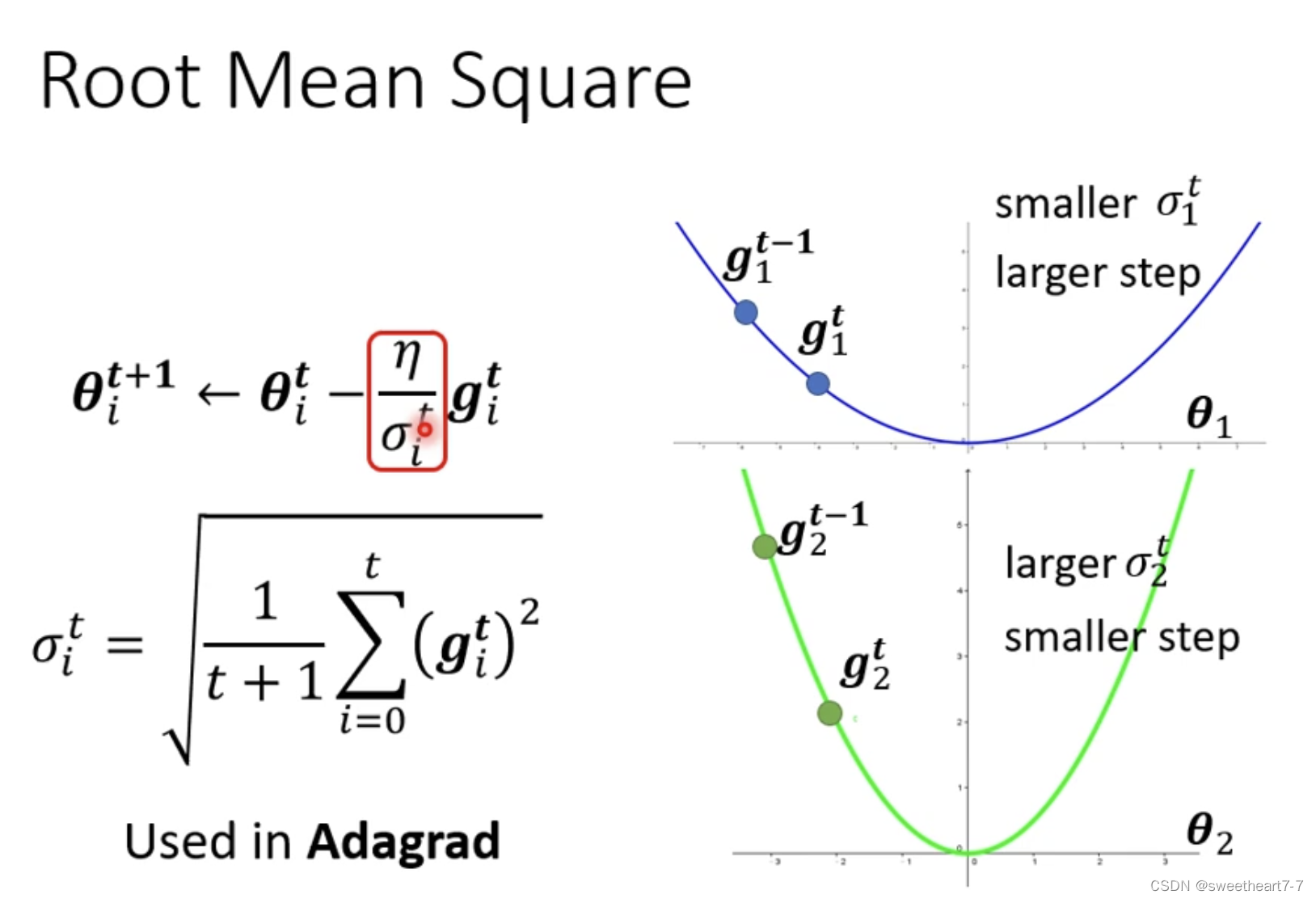
我们要改一下 gradient descend 的式子,使得其在陡峭的地方 learning rate 小,平缓的地方 learning rate 大。
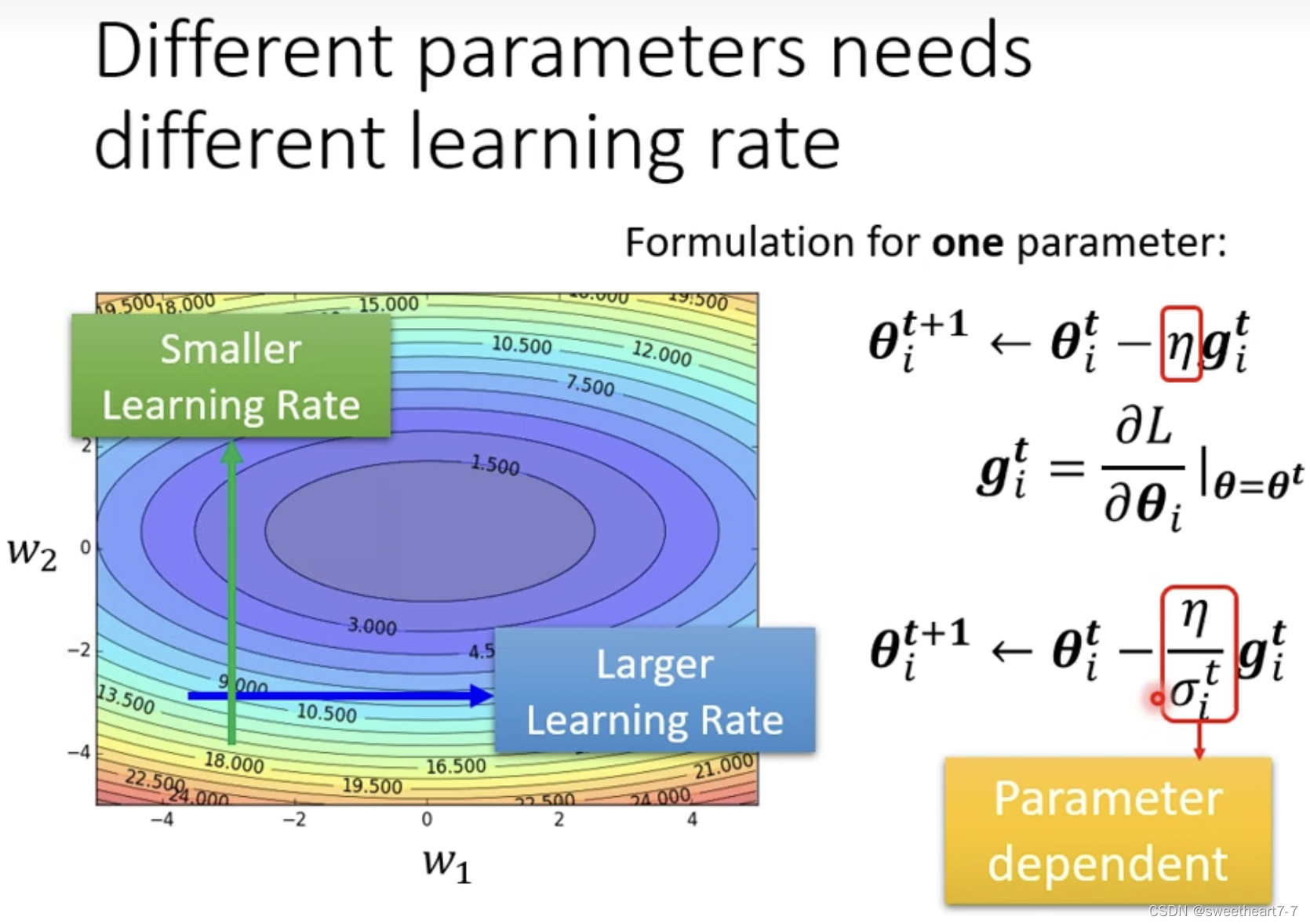
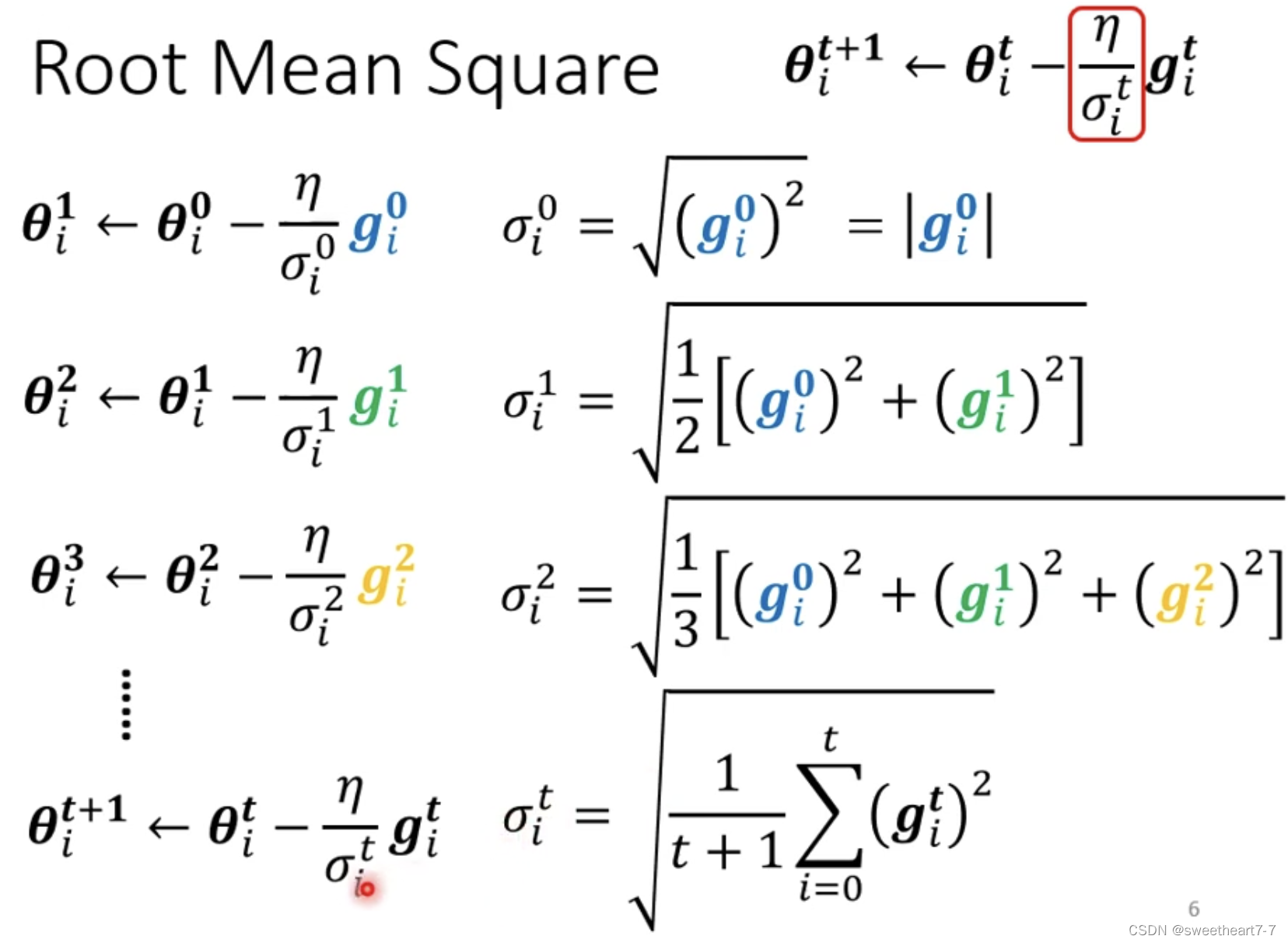
Adagrad
相当于 如果 grident 大的话,σ 就大,σ 大的话,learning rate 就小了。
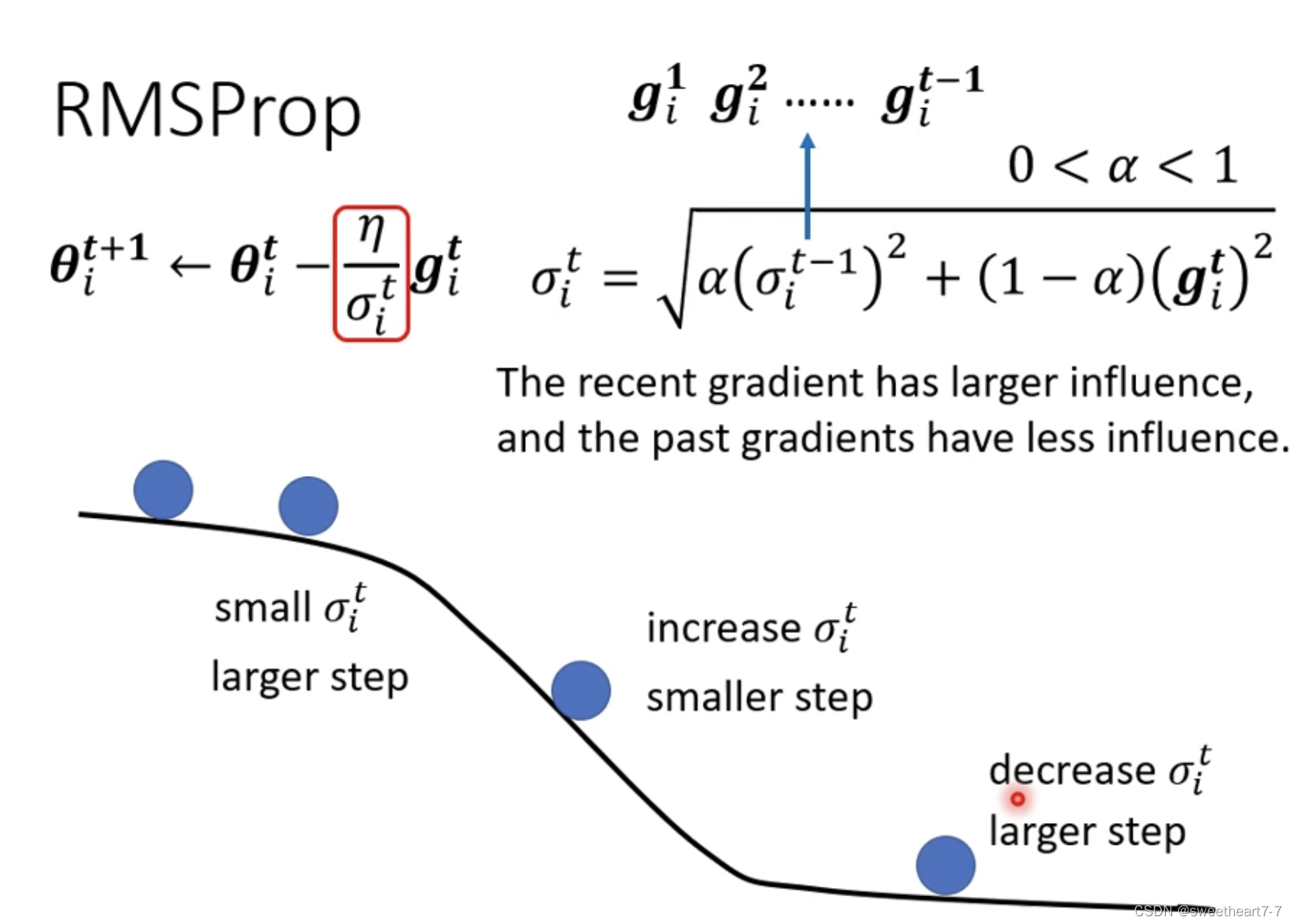
RMSProp
引入 α 来表示 新算出来的 grident 所占的比重。
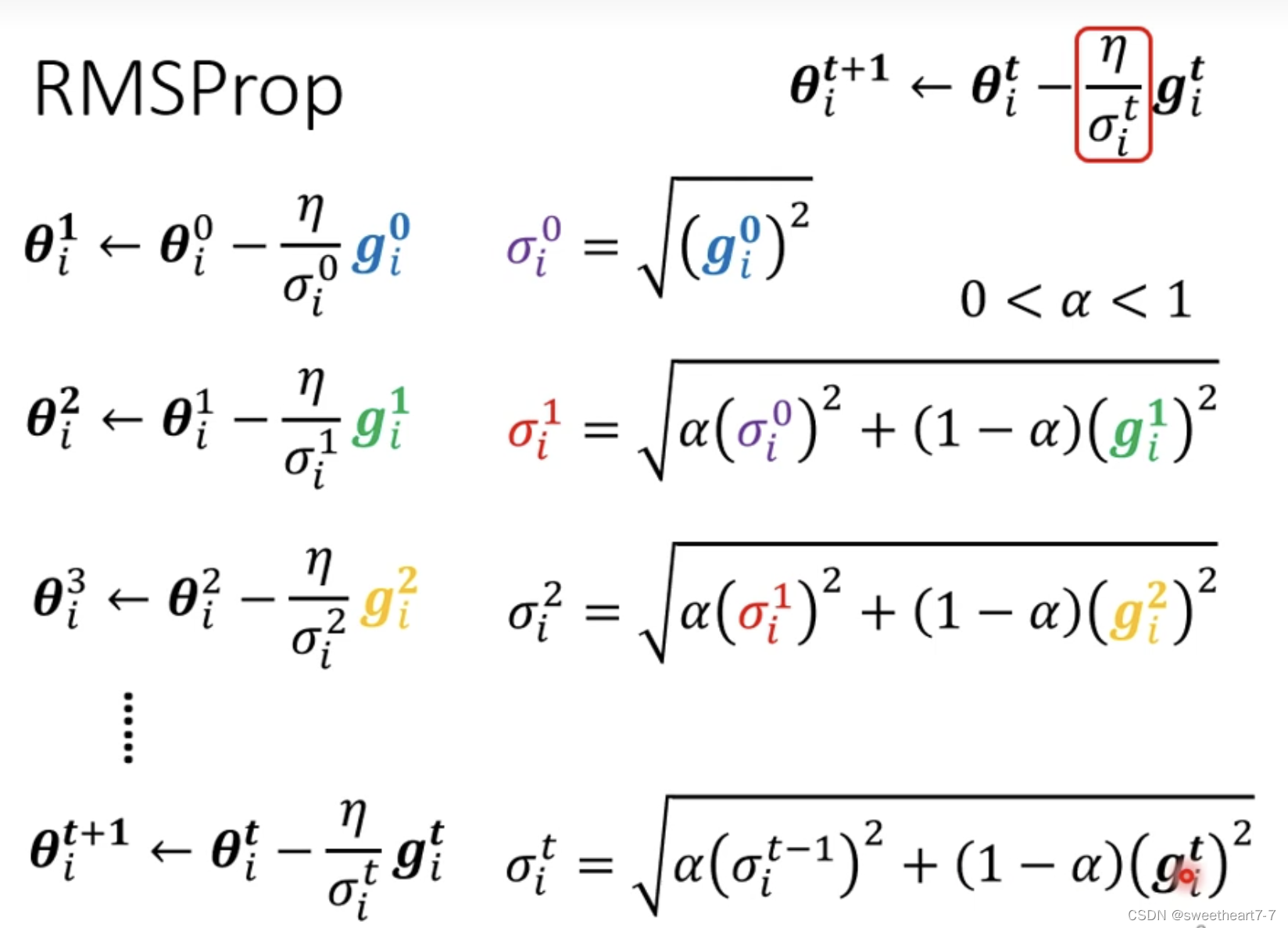
Adam: RMSProp + Momentum

引入 Adagrad
η 设置为一个随时间变化的函数,随时间的增加 η (learning rate) 越来越小。
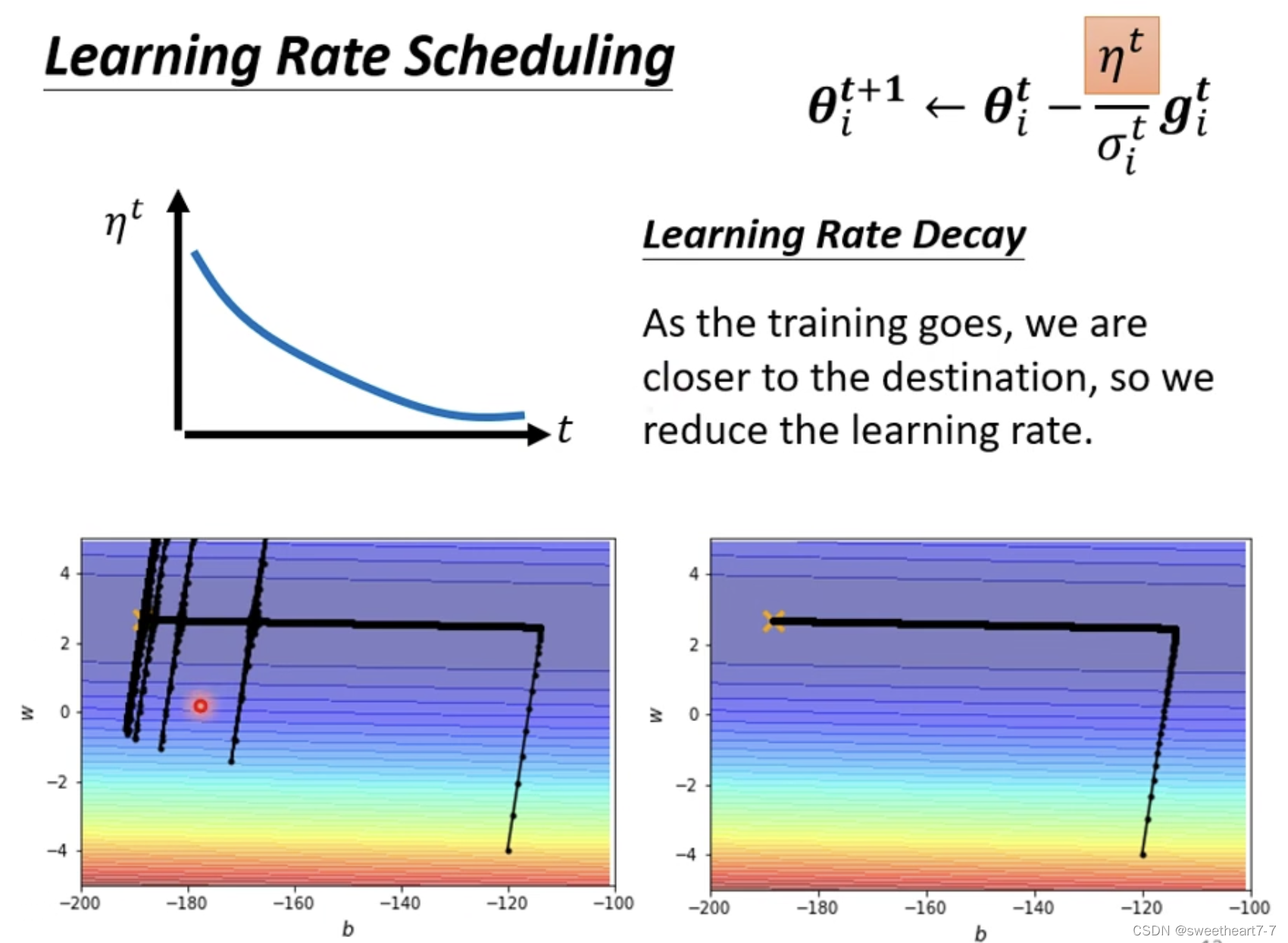
Warm up (黑科技)

momentus 是为了增加历史运动的惯性,RMS 是为了缓和步伐的大小,变得更平缓

损失函数 (Loss)
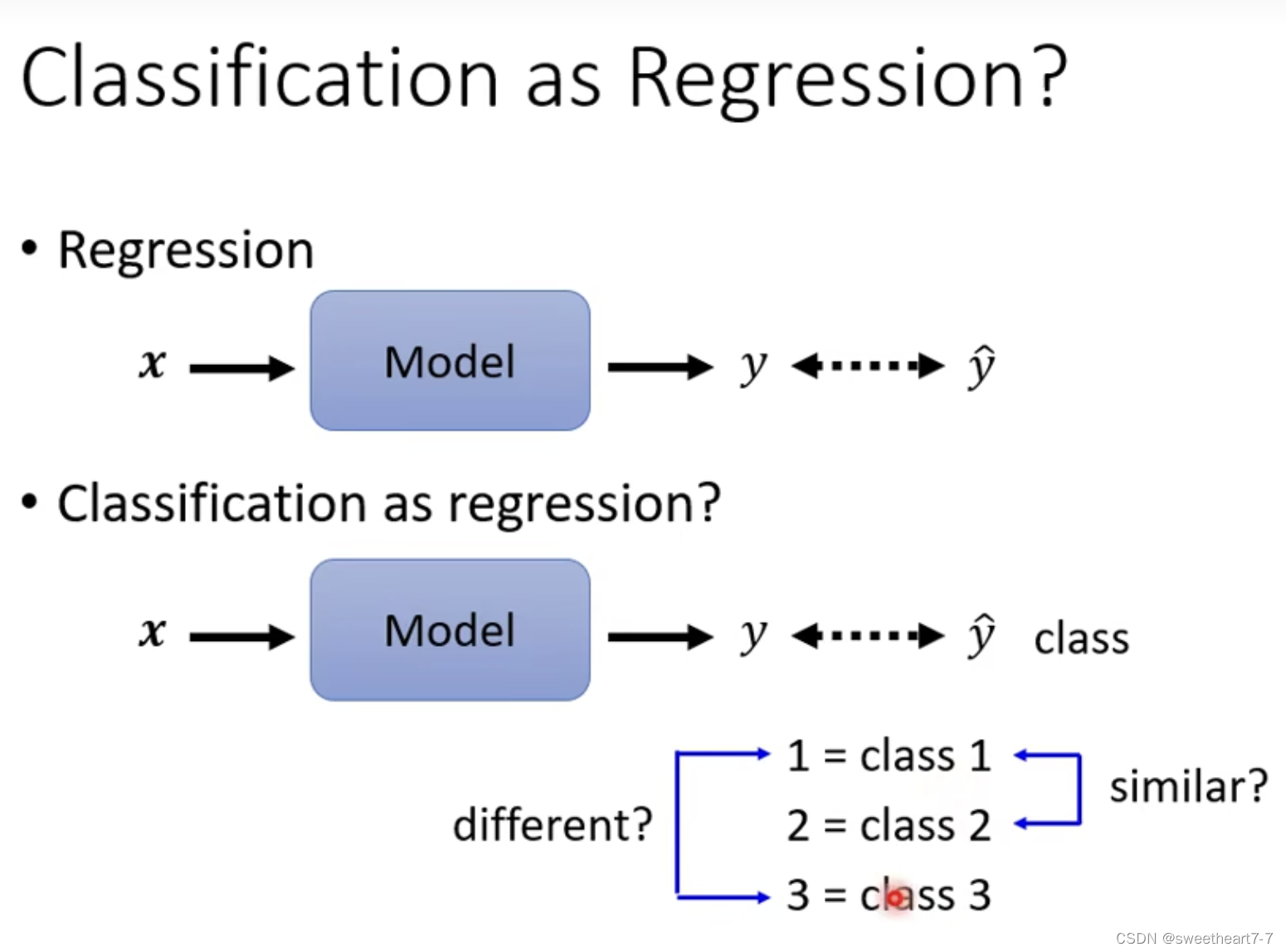
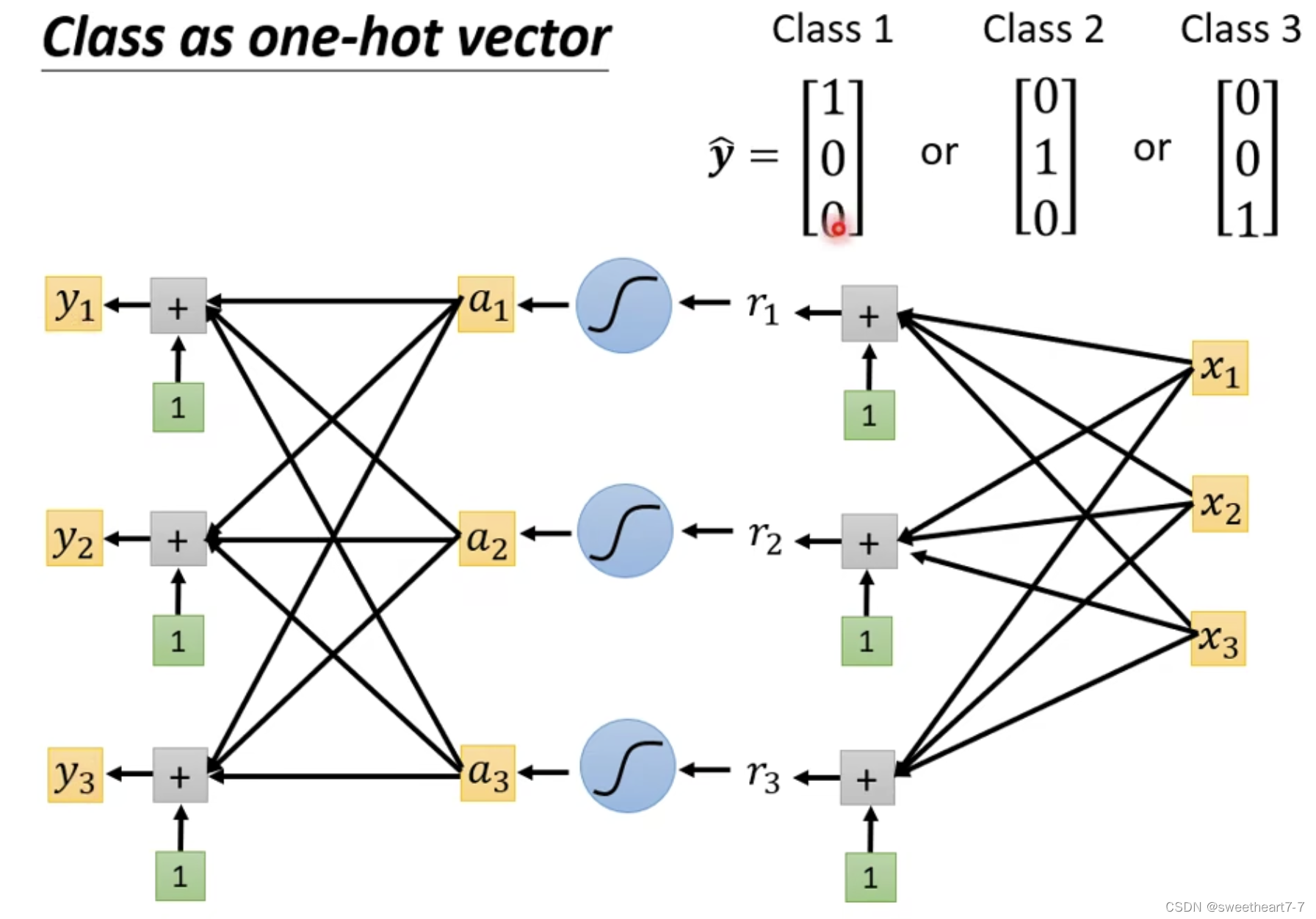
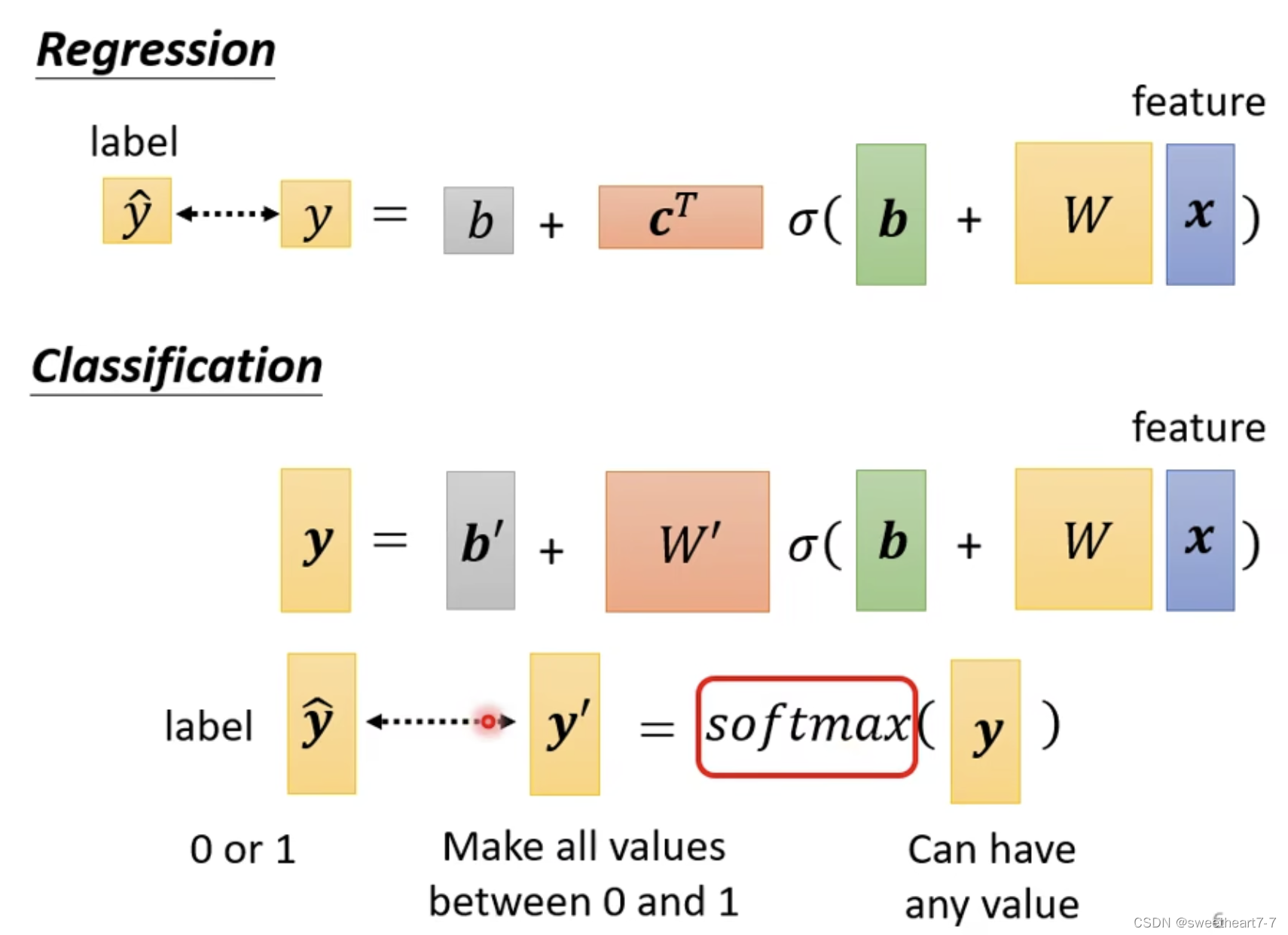
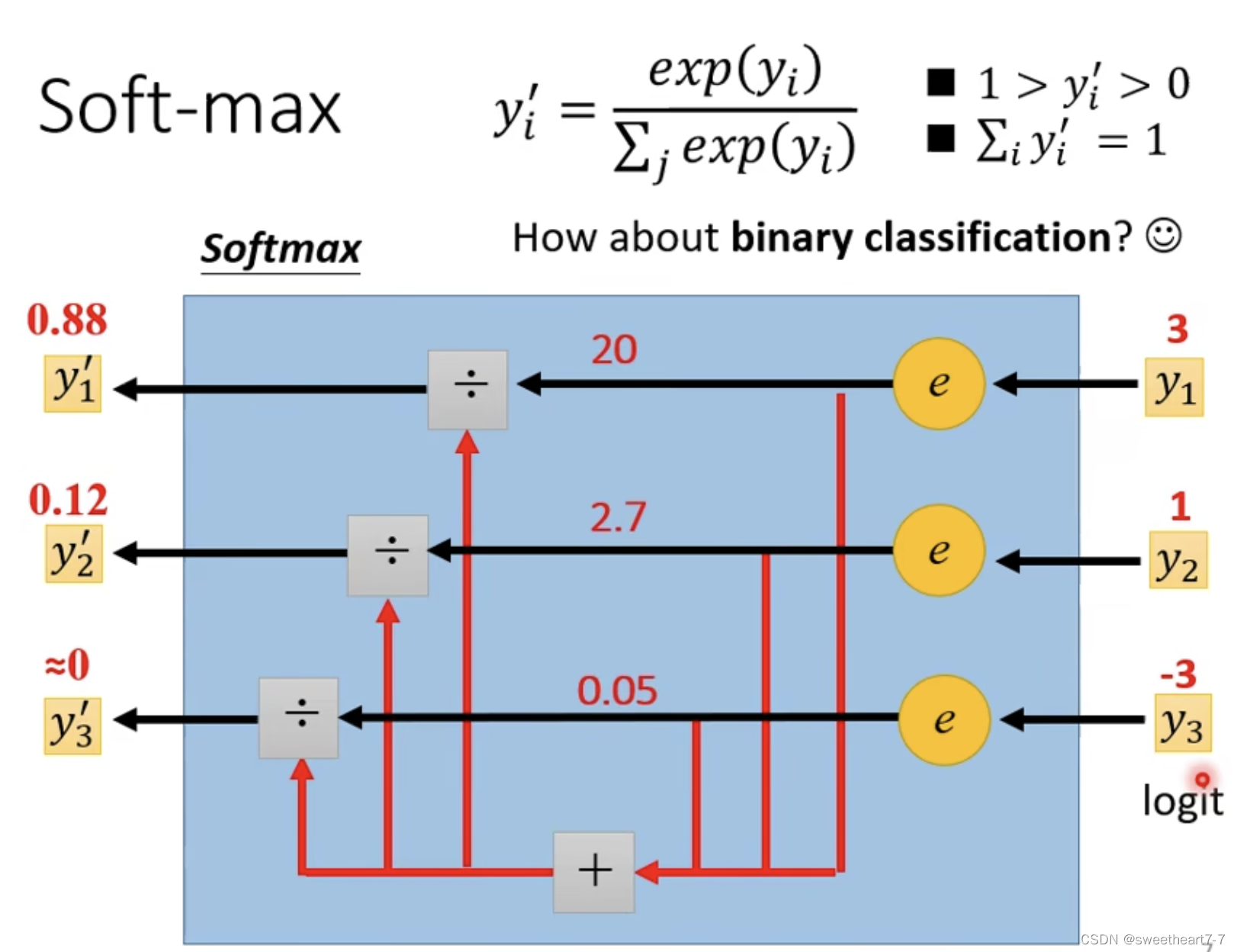
当只有两个 class 时,一般采用 sigmoid ( 此时 sigmoid 跟 softmax 的作用等价),而两个以上则用 softmax。
minimizing cross-entropy 就相当于 maximizing linklihood
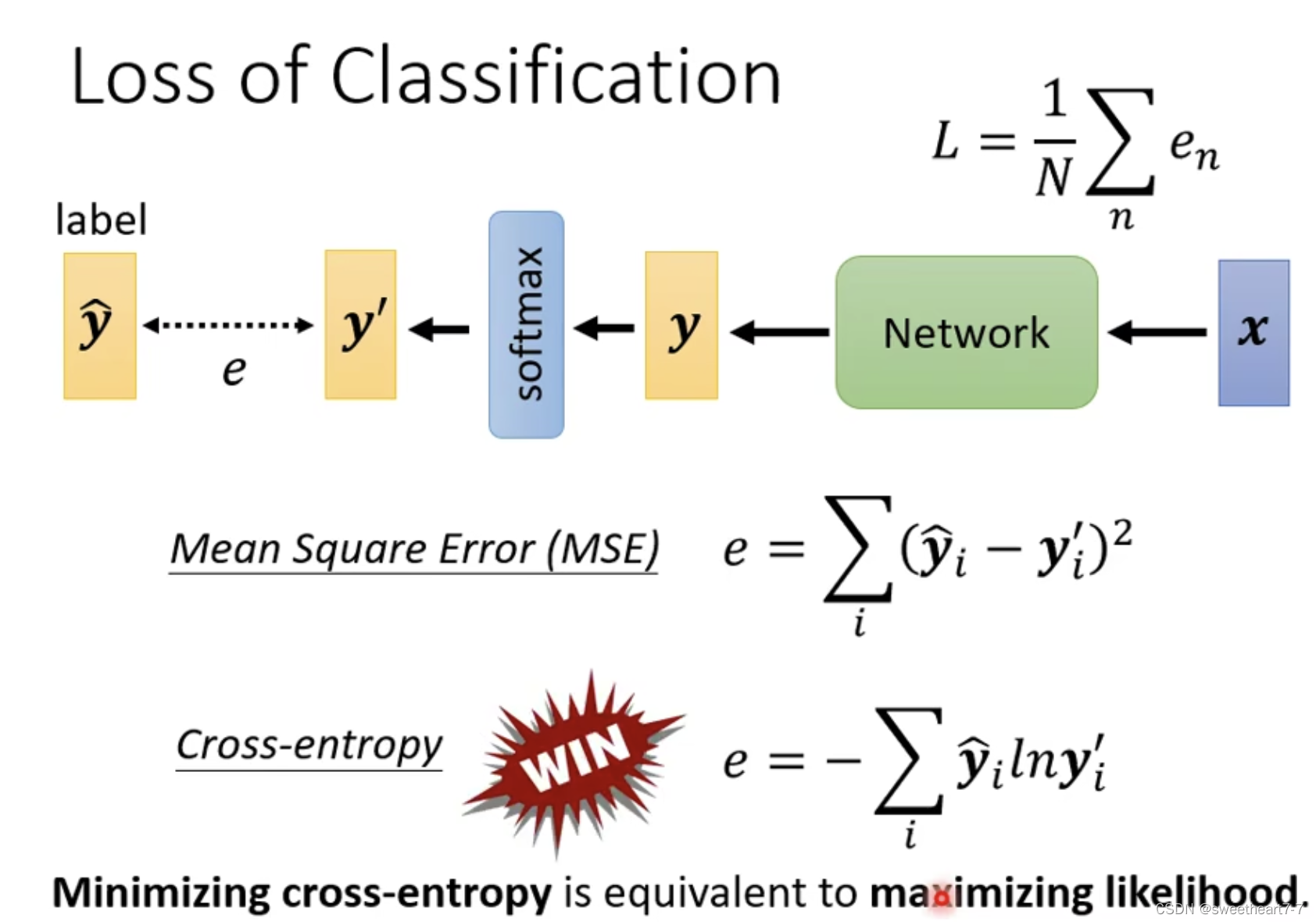
用 Mean Square 处理 classify 问题,可能会卡住在 critical point。
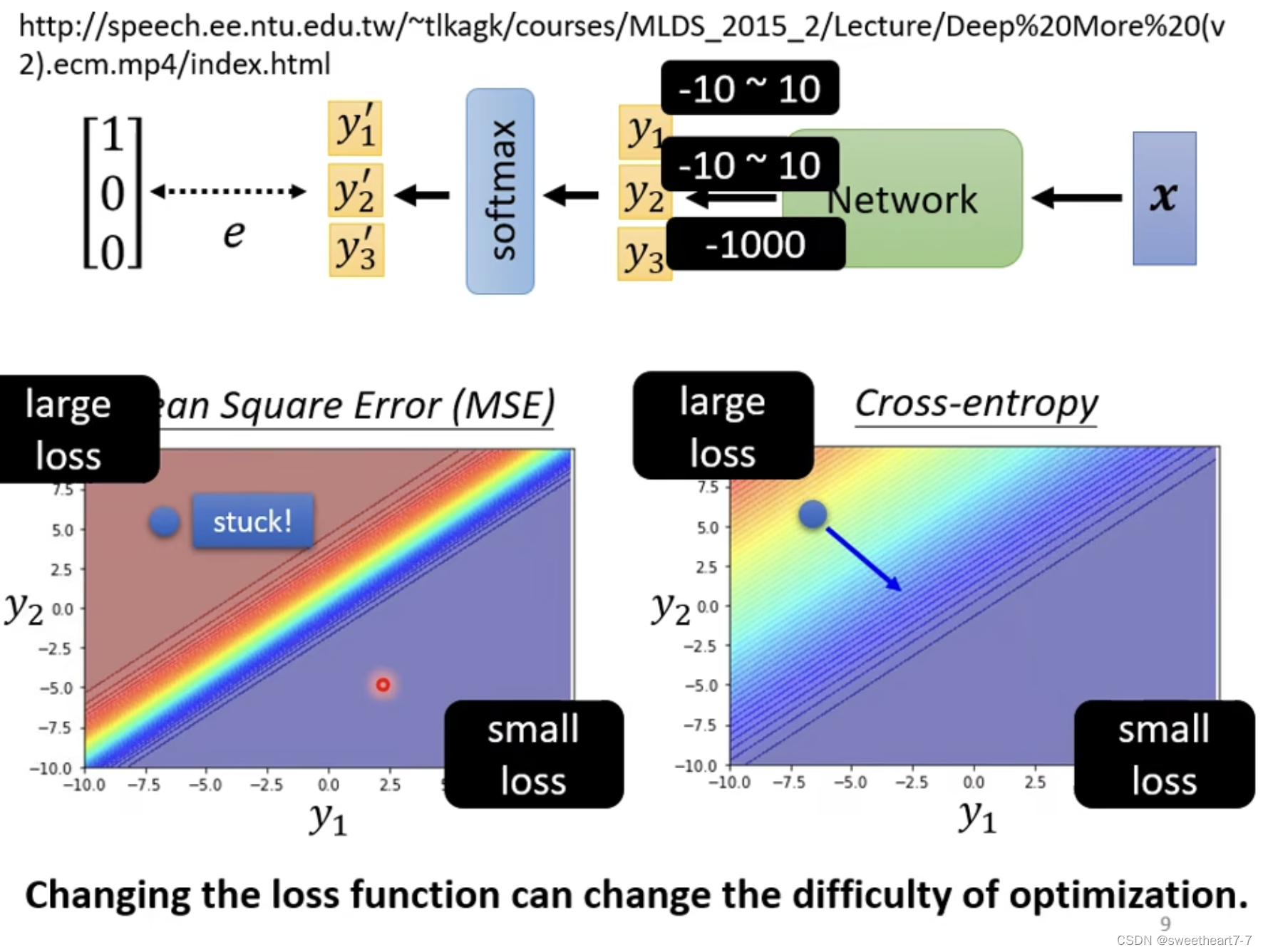
·