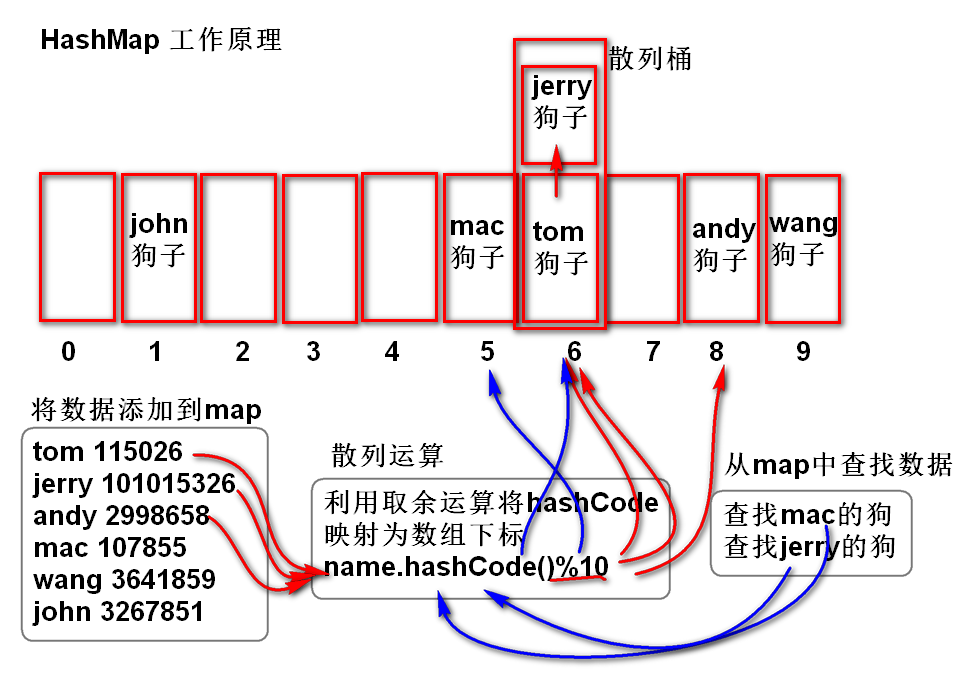
## HashMap 的工作原理
1. HashMap内部利用数组存储数据。
2. 根据key的hashCode值计算出数组的下标位置,进行添加或者查询数据。
- 根据hashCode计算出数组的下标位置的算法称为“散列算法”
3. 数组下标位置会重复,重复时候利用链表存储重复元素
- 这个链表称为 “散列桶”
4. 添加和查询时候如果有散列桶,则根据equals方法逐个比较找到位置。
> 由于利用hashCode直接定位到数组的存储位置,无需依次查找,所以HashMap具有极高查找性能。
影响HashMap的查找性能因素:
1. 如果数据多,而数组容量少,大量数据重复的存储在散列桶中,造成在散列桶中进程大量的顺序查找,性能差。
- 解决办法是提供更多数组容量,减少散列桶中重复的数据。
- 如果保持 元素的总数和数组容量的比值少于 75% 时候,出现重复位置的情况少于3个!
- HashMap中默认的“加载因子” 就是75%, HashMap中添加元素时候,HashMap始终会保持元素和数组容量的比值小于75%,如果超过75%则进行数组扩容“重新散列”
2. hashCode 方法
- Java 在 Object类上定义了hashCode方法,用于支持HashMap中的算法。
- 作为key的类型必须很好的实现 hashCode方法,否则会影响HashMap性能
- 当两个对象 equals方法比较结果为true时候,他们的hashCode相同
- 当两个对象 equals方法比较结果为false时候,他们的hashCode近可能不同!
3. equals 方法
- HashMap添加或查找时候,先根据hashCode计算数组下标位置,然后在利用equals比较key对象是否相同。
- 如果key的hashCode和equals方法不"一致", 会造成HashMap工作异常!可能重复添加或者查找不到数据。
> 建议:一定成对重写key的equals方法和hashCode方法。
> java 中的 API String,Integer 等都成对的重写了equals和hashCode。
4. 创建HashMap的性能优化参数
- new HashMap(数组容量,加载因子)
- 默认 new HashMap() 等价于 new HashMap(16, 0.75f)
- 在添加到12个元素以后进行扩容。
- 如果事先可以预测添加到HashMap中数量,则可以声明足够的大的容量,避免反复扩容浪费时间。
- 如果有 1000 条数据需要添加到HashMap,则new HashMap(1500)
1. HashMap内部利用数组存储数据。
2. 根据key的hashCode值计算出数组的下标位置,进行添加或者查询数据。
- 根据hashCode计算出数组的下标位置的算法称为“散列算法”
3. 数组下标位置会重复,重复时候利用链表存储重复元素
- 这个链表称为 “散列桶”
4. 添加和查询时候如果有散列桶,则根据equals方法逐个比较找到位置。
> 由于利用hashCode直接定位到数组的存储位置,无需依次查找,所以HashMap具有极高查找性能。
影响HashMap的查找性能因素:
1. 如果数据多,而数组容量少,大量数据重复的存储在散列桶中,造成在散列桶中进程大量的顺序查找,性能差。
- 解决办法是提供更多数组容量,减少散列桶中重复的数据。
- 如果保持 元素的总数和数组容量的比值少于 75% 时候,出现重复位置的情况少于3个!
- HashMap中默认的“加载因子” 就是75%, HashMap中添加元素时候,HashMap始终会保持元素和数组容量的比值小于75%,如果超过75%则进行数组扩容“重新散列”
2. hashCode 方法
- Java 在 Object类上定义了hashCode方法,用于支持HashMap中的算法。
- 作为key的类型必须很好的实现 hashCode方法,否则会影响HashMap性能
- 当两个对象 equals方法比较结果为true时候,他们的hashCode相同
- 当两个对象 equals方法比较结果为false时候,他们的hashCode近可能不同!
3. equals 方法
- HashMap添加或查找时候,先根据hashCode计算数组下标位置,然后在利用equals比较key对象是否相同。
- 如果key的hashCode和equals方法不"一致", 会造成HashMap工作异常!可能重复添加或者查找不到数据。
> 建议:一定成对重写key的equals方法和hashCode方法。
> java 中的 API String,Integer 等都成对的重写了equals和hashCode。
4. 创建HashMap的性能优化参数
- new HashMap(数组容量,加载因子)
- 默认 new HashMap() 等价于 new HashMap(16, 0.75f)
- 在添加到12个元素以后进行扩容。
- 如果事先可以预测添加到HashMap中数量,则可以声明足够的大的容量,避免反复扩容浪费时间。
- 如果有 1000 条数据需要添加到HashMap,则new HashMap(1500)