本文转载自:计算机视觉SLAM “本文提出了一种新颖的用于局部图像特征匹配的方法。代替了传统的顺序执行图像特征检测,描述和匹配的步骤,本文提出首先在粗粒度上建立逐像素的密集匹配,然后在精粒度上完善精修匹配的算法。与使用cost volume搜索对应关系的稠密匹配方法相比,本文使用了Transformers中的使用自我和交叉注意力层(self and cross attention layers)来获取两个图像的特征描述符。Transformers提供的全局感受野使本文的方法能够在低纹理区域产生密集匹配(通常情况下在低纹理区域,特征检测器通常难以产生可重复的特征点)。在室内和室外数据集上进行的实验表明,LoFTR在很大程度上优于现有技术。
”

弱纹理条件与CVPR 2020的SuperGlue特征匹配对比:(上)LoFTR, (下)SuperGlue
LoFTR: Detector-Free Local Feature Matching with Transformers

本文作者来自浙大以及商汤科技,代码开源
论文:https://arxiv.org/abs/2104.00680
代码:https://github.com/zju3dv/LoFTR
项目地址: https://zju3dv.github.io/loftr
框架

LoFTR由四个部分组成:
局部特征提取网络从图像 以及 中提取粗略特征图 和 ,以及精细的特征图 和 。
将粗略特征图展平为一维向量,并添加位置编码;然后,将其喂给Local Feature TRansformer (LoFTR) 模块进行处理,得到 个self-attention 和 cross-attention层。
可微分匹配层用于匹配上述变换后的特征,最终得到置信矩阵 。根据置信度阈值和相互邻近标准选择匹配项,得到粗略的匹配预测 。
对于每个选定的粗略预测 ,我们会从精细特征图中裁剪出具有大小为 的局部窗口。粗匹配将在此局部窗口内进行细化为并达到亚像素匹配级别,作为最终的匹配预测。
实验
1. 弱纹理匹配效果
2. 与SuperGlue对比

3. 定量比较

HPatches上位姿解算AUC对比

室内ScanNet数据集上位姿解算AUC对比

室外MegaDepth数据集上位姿解算AUC对比

室外Aachen Day-Night数据集上视觉定位召回率对比
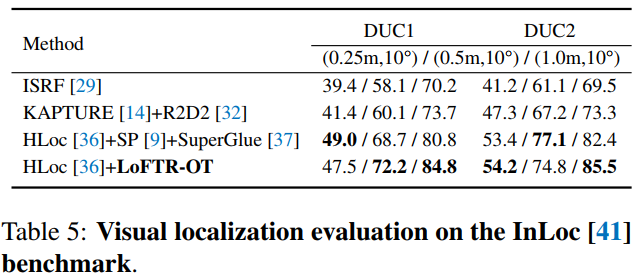
室内InLoc数据集上视觉定位召回率对比
4. 可视化

总结
本文提出了一种基于Transformers的无需特征提取的特征匹配器,提出的LoFTR利用self/cross attention层实现了将局部特征转换为与上下文和位置有关的量,这使得匹配器在稀疏纹理也能得到匹配。在实验部分,可以看到LoFTR能够分别在特征提取/位姿估计以及视觉定位任务中取得相当好的结果。
上述论文PDF和代码下载
后台回复:LoFTR,即可下载论文PDF和代码
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的两篇Transformer综述PDF
CVer-Transformer交流群成立
扫码添加CVer助手,可申请加入CVer-Transformer 微信交流群,方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加小助手微信,进交流群
▲点击上方卡片,关注CVer公众号
整理不易,请给CVer点赞和在看![]()