Invertible Image Signal Processing

[pdf]
目录
Abstract
Unprocessed RAW data is a highly valuable image format for image editing and computer vision. However, since the file size of RAW data is huge, most users can only get access to processed and compressed sRGB images.
To bridge this gap, we design an Invertible Image Signal Processing (InvISP) pipeline, which not only enables rendering visually appealing sRGB images but also allows recovering nearly perfect RAW data. Due to our framework’s inherent reversibility, we can reconstruct realistic RAW data instead of synthesizing RAW data from sRGB images without any memory overhead. We also integrate a differentiable JPEG compression simulator that empowers our framework to reconstruct RAW data from JPEG images.
Extensive quantitative and qualitative experiments on two DSLR demonstrate that our method obtains much higher quality in both rendered sRGB images and reconstructed RAW data than alternative methods.
未经处理的 RAW 数据对于图像编辑和计算机视觉来说是一种非常有价值的图像格式。然而,由于RAW 数据的文件大小巨大,大多数用户只能访问经过处理和压缩的 sRGB 图像。为了弥补这一差距,本文设计了一个可逆图像信号处理 (InvISP) pipline,它不仅能够渲染视觉上吸引人的 sRGB 图像,而且还允许恢复近乎完美的 RAW 数据。由于本文的框架固有的可逆性,可以重构真实的RAW 数据,而不是从 sRGB 图像合成 RAW 数据,而不需要任何内存开销。本文还集成了一个可微分的 JPEG 压缩模拟器,使我们的框架能够从 JPEG 图像重建 RAW 数据。在两台单反相机上进行的大量定量和定性实验表明,与其他方法相比,本文的方法在 sRGB 图像和 RAW 数据重建中都获得了更高的质量。
Introduction
Professional photographers can choose to process RAW images by themselves instead of RGB images to produce images with better visual effects as the RAW data captures unprocessed scene irradiance at each in 12-14 bits by a camera. Due to its linear relationship with scene irradiance, raw sensor data is also a better choice than RGB images for many image editing and computer vision tasks, such as photometric stereo, intrinsic image decomposition, image denoising, reflection removal, and image super resolution [4, 7, 27, 16, 30, 39, 40, 45]. However, accessing RAW images can be quite hard due to their memory-demanding property: RAW images may be discarded during the process of data storing, transferring, and sharing. In this paper, we are interested in the question: can users get access to the real RAW data without explicitly storing it?
研究背景:
专业摄影师可以选择自己处理 RAW 图像,而不是 RGB 图像,以产生更好的视觉效果的图像,因为 RAW 数据通过相机捕获每个未经处理的 12-14 bits 场景 irradiance。由于其线性关系与场景照度,许多图像编辑的和计算机视觉任务中,与 RGB 图像相比,原始传感器 RAW 数据是一个更好的选择,如光度立体,内在形象分解,图像去噪,反射去除,图像超分辨率。但是,由于 RAW 映像的内存需求特性,访问 RAW 映像非常困难: 在数据存储、传输和共享过程中,RAW 映像可能会被丢弃。本文感兴趣的问题是:用户是否可以在不显式存储的情况下访问真实的 RAW 数据?
Due to the great advantages of RAW images, there have been many approaches to provide the mapping from sRGB images to their RAW counterparts [2, 7, 29, 31, 36, 44]. Nguyen et al. [31] suggest explicitly storing the parameters of sRGB-RAW mapping functions into the JPEG metadata for the prospective RAW reconstruction. Brooks et al. [7] use the prior information of the cameras (e.g., color correction matrices and digital gains) to reverse the ISP step-by-step. Another line of work [29, 36, 44] follows the inverse order of ISP and proposes learning-based methods to synthesize RAW data from sRGB images. However, these methods still rely on the underlying lossy in-camera ISP pipeline, and the recovered RAW images are inaccurate and may be different from the original ones.
现有方法不足:
由于 RAW 图像的巨大优势,已经有许多方法提供从 sRGB 图像到其 RAW 副本的映射。Nguyen等人提出显式地将 sRGB-RAW 映射函数的参数存储到 JPEG 元数据中,以便于预期的 RAW 重构。Brooks 等人利用相机的先验信息 (例如,色彩校正矩阵和数字增益) 逐步反转 ISP。另一条工作遵循 ISP 的逆顺序,提出了基于学习的方法从 sRGB 图像合成 RAW 数据。然而,这些方法仍然依赖于底层的有损相机内 ISP pipeline,恢复的 RAW 图像是不准确的,可能与原始图像不同。
In this work, we propose a novel and effective learned solution by redesigning the camera image signal processing pipeline as an invertible one, which can be aptly called Invertible ISP (InvISP). Our learning-based InvISP enables rendering visually appealing RGB images in the forward process, and recovering nearly perfect quality raw sensor data from compressed RGB images through the inverse process. Our reconstructed RAW data is nearly identical with real RAW data and enables computer vision applications, such as image retouching and HDR reconstruction, as shown in Figure 1.
本工作提出了一种新的有效的学习解决方案,将摄像机图像信号处理管道重新设计为一个可逆的 pipline,称之为可逆 ISP (InvISP)。基于学习的 InvISP 能够在前向处理中呈现视觉上吸引人的RGB 图像,并通过反向处理从压缩的 RGB 图像中恢复几乎完美质量的原始传感器数据。重建的RAW 数据与真实的 RAW 数据几乎相同,可以实现计算机视觉应用,如图像修饰和 HDR 重建,如图 1 所示。

Designing an invertible ISP is not a trivial task for at least three reasons. First, some steps in the traditional ISP, such as denoising, tone mapping, and quantization, can lead to inevitable information lost from wide-range (12-bit or 14-bit) raw sensor data to 8-bit RGB images. Second, the invertible ISP should not produce visual artifacts such as halo and ghosting artifacts [18]. To render visually appealing sRGB images, denoising, demosaicing, color correction, white balance gain, tone mapping, and color enhancement must be designed carefully in ISP. Third, modern digital cameras store RGB images in the JPEG format, where the lossy compression process makes reconstructing highquality RAW data highly challenging.
设计一个可逆 ISP 不是一项简单的任务,至少有三个原因。首先,传统 ISP 中的一些步骤,如去噪、色调映射和量化,会不可避免地导致从宽范围 (12位或14位) 原始传感器数据到 8 位 RGB 图像的信息丢失。第二,可逆 ISP 不应该产生像光晕和重影伪影这样的视觉伪影。为了呈现视觉上吸引人的 sRGB 图像,去噪、消色、色彩校正、白平衡增益、色调映射和色彩增强必须在 ISP 中仔细设计。第三,现代数码相机以 JPEG 格式存储 RGB 图像,有损压缩过程使得重建高质量的RAW 数据非常具有挑战性。
To overcome these challenges, we take advantage of the inherent reversibility of normalizing-flow-based models [12, 25] and design both the RAW-to-RGB and RGBto-RAW mapping in our invertible ISP with one single invertible neural network. We deeply analyze the properties of traditional ISP and design specific modules that can not only well approximate the camera ISP but also reconstruct almost identical RAW data with the camera RAW data. Specifically, we design our model with the composition of a stack of affine coupling layers and utilize the invertible 1 × 1 convolution as the learnable permutation function between the coupling layers. Besides, to empower our model to recover realistic RAW data from JPEG images, we integrate a differentiable JPEG simulator into our invertible neural network. We leverage the idea from Fourier transformation to replace the non-differentiable quantization step in JPEG compression. Thus, our end-to-end InvISP framework bypasses traditional ISP modules and minimizes the information loss for the RAW data and RGB image conversion. We bidirectionally train our network to optimize the RGB and RAW reconstruction process jointly. We experimentally prove that our framework can recover much better RAW data than state-of-the-art baselines without sacrificing the RGB reconstruction performance.
为了克服这些挑战,本文利用了基于标准化流模型的固有可逆性,并在提出的可逆 ISP 中使用一个可逆神经网络设计了 RAW 到 RGB 和 RGB 到 RAW 的映射。本文深入分析了传统 ISP 的特性,设计了特定的模块,不仅可以很好地逼近相机 ISP,而且可以与相机 RAW 数据重建几乎相同的 RAW 数据。具体来说:
设计的模型由一叠仿射耦合层组成,并利用可逆的 1 × 1 卷积作为耦合层之间的可学习排列函数;
此外,为了使模型能够从 JPEG 图像中恢复真实的 RAW 数据,在可逆神经网络中集成了一个可微分的 JPEG 模拟器;
利用傅立叶变换的思想来代替 JPEG 压缩中的不可微量化步骤。
因此,本文端到端的 InvISP 框架绕过了传统的 ISP 模块,最大限度地减少了 RAW 数据和 RGB 图像转换的信息损失。本文双向训练网络,共同优化 RGB 和 RAW 重建过程。实验证明,本文的框架可以在不牺牲 RGB 重建性能的情况下恢复比 state-of-the-art baselines 更好的 RAW 数据。
To the best of our knowledge, our framework is the first attempt for RAW data reconstruction from the perspective of redesigning the camera ISP as an invertible one. Our method can address the information loss issue in ISP modules and is robust to the JPEG compression step. We demonstrate the effectiveness of our method on two DSLR cameras and show that our method outperforms state-ofthe-art baselines to a large extent. Moreover, we also exhibit potential applications through RAW data compression, image retouching, and HDR reconstruction.
本文的框架是从将相机 ISP 重新设计为可逆的角度对 RAW 数据重建进行的第一次尝试。本文的方法可以解决 ISP 模块中的信息丢失问题,并且对 JPEG 压缩步骤具有鲁棒性。本文在两个单反相机上证明了方法的有效性,并表明本文的方法方法在很大程度上优于 state-of-the-art baselines。此外,本文还展示了 RAW 数据压缩、图像修饰和 HDR 重建的潜在应用。
Traditional ISP Analysis
Modern digital cameras apply a series of operations, which form the image signal processing pipeline (ISP), to render RAW data to human-readable RGB images. These operations include white balance, demosaicing, denoising, color space transformation, tone mapping, and others [24]. Traditionally, every step of an ISP needs labor-intensive tuning for specific cameras, and inverting the traditional ISP steps is quite challenging. In this section, we analyze the existing modules with information loss in the traditional ISP. We show that the lossy steps in traditional ISP restrict the RAW reconstruction performance of a series of works [31, 7, 44] that aim at synthesizing RAW from sRGB images. Different from previous works, we re-design the ISP into an end-to-end invertible one that can bypass the traditional modules to minimize information loss during the RAW data and JPEG image conversion, which further enables recovering high-quality RAW data.
现代数码相机采用一系列操作,形成图像信号处理 pipeline (ISP),将 RAW 数据渲染为人类可读的 RGB 图像。这些操作包括白平衡、消色、去噪、颜色空间变换、色调映射等 [24]。传统上,ISP 的每一步都需要为特定的摄像机进行密集的调整,而反转传统 ISP 的步骤是相当具有挑战性的。
本节分析了传统 ISP 中存在的信息丢失模块。作者表明,传统 ISP 中的有损步骤限制了一系列旨在从 sRGB 图像合成 RAW 的重构性能。与以往的工作不同,本文将 ISP 重新设计为端到端可逆ISP,可以绕过传统的模块,最大限度地减少 RAW 数据和 JPEG 图像转换过程中的信息损失,进一步实现高质量 RAW 数据的恢复。
Quantization and tone mapping
Some ISP steps like demosaicing and gamma compression may involve float-point operations, and thus quantization is inevitable to transform the data into the integer type. For instance, the rounding function can bring (−0.5, 0.5) intensity error to a pixel in theory. In the context of ISP, however, the tone mapping step can enlarge the intensity error much greater than ±0.5. The tone mapping curve is usually designed as S-curve that compresses the high-intensity value and low-intensity value more than mid-intensity values [37, 5]. As illustrated in Figure 2, for a 14-bit raw image, gamma compression makes pixel intensity at [16313, 16383] all be rounded to the max intensity 255 after normalized to (0, 255). This step may cause a 0.004 RMSE error at this single pixel. Thus, it is challenging for existing works [31, 7, 44] to directly synthesize the 14-bit RAW data from its 8-bit sRGB counterparts, especially at the over-exposed regions. We show the comparison of our recovered RAW with previous works in Figure 5. Our method can preserve much more detail of RAW data, even at high-intensity pixels.


一些 ISP 步骤 (如demosaicing 和 gamma compression) 可能涉及浮点运算,因此,为了将数据转换为整数类型,量化是不可避免的。例如,舍入函数理论上可以给像素带来 (−0.5,0.5) 强度误差。然而,在 ISP 环境下,tone mapping 步长可使强度误差的放大幅度远远大于 ±0.5。tone mapping 曲线通常设计为 s 曲线,高强度值和低强度值比中强度值压缩更多。如图 2 所示,对于14 位原始图像,gamma 压缩使 [16313,16383] 的像素强度在归一化为 (0,255) 后都四舍五入到最大强度 255。这一步可能会在这个单一像素上造成 0.004 RMSE 误差。因此,对于现有的工作[31,7,44] 来说,直接从 8 位 sRGB 对应数据合成 14 位 RAW 数据是一项挑战,特别是在过曝光区域。我们在图 5 中展示了恢复的 RAW 与以前的工作的比较。我们的方法可以保留更多的 RAW 数据的细节,甚至在高强度像素。
Out-of-range value clipping
Value clipping is a common step to normalize the raw value within a reasonable range, which may happen after color space transformation, demosaicing, denoising, and tone mapping [1, 15, 34, 14]. Most commonly used value clipping operation is like min(max(x, 0), 1), which will discard the out-of-range pixels at over- and under-exposed regions. Note that this restricts the image capacity for further adjustment. Moreover, traditional ISPs are manually tuned in isolation by experts, which accumulates the clip error among ISP steps to bring further information lost. Our end-to-end pipeline jointly optimizes all the ISP steps and alleviates the clip error accumulation problem to recover more realistic RAW images.
值裁剪 Value clipping 是将原始值在合理范围内归一化的常见步骤,可能发生在色彩空间变换、demosaicing、去噪 和 tone mapping 之后。最常用的 Value clipping 操作是 min(max(x, 0), 1),这将丢弃过度和不足曝光区域的超出范围的像素。注意,这限制了进一步调整时的图像容量。此外,传统的 ISP 是由专家单独手动调优的,这就积累了 ISP 步骤之间的 clip 误差,导致进一步的信息丢失。我们的端到端管道联合优化了所有 ISP 步骤,缓解了clip 误差积累问题,以恢复更真实的 RAW 图像。
JPEG compression
Modern digital cameras store RGB images in JPEG format, whose information loss further brings challenges to RAW image reconstruction. JPEG encoding pipeline consists of four main steps: color space transformation, discrete cosine transformation (DCT), quantization, and entropy encoding [33]. In reality, quantization is the only lossy and non-differentiable step in JPEG compression. Note that the JPEG information loss is quite hard to reverse. Thus we take a compromised step by integrating the JPEG compression procedure into our network optimization process to alleviate the information loss. To achieve this, we design a differentiable JPEG simulator by carefully simulating the JPEG compression procedure and replacing the quantization step with differentiable Fourier transformations.
现代数码相机以 JPEG 格式存储 RGB 图像,其信息丢失进一步给 RAW 图像重建带来挑战。JPEG 编码流水线由四个主要步骤组成:颜色空间变换、离散余弦变换 (DCT)、量化和熵编码。实际上,量化是 JPEG 压缩中唯一有损且不可微的步骤。请注意,JPEG 信息的丢失很难逆转。因此,我们采取了折衷的步骤,将 JPEG 压缩过程集成到我们的网络优化过程中,以减轻信息损失。为此,我们设计了一个可微 JPEG 模拟器,精细地模拟 JPEG 压缩过程,并用可微傅里叶变换代替量化步骤。
Method
1. Invertible Image Signal Processing (InvISP)
We denote the RAW data space as X and sRGB data space as Y. Our goal is to find the invertible and bijective function which can map the data point from RAW data space to sRGB data space, denoted as f : X → Y. To achieve this, classical neural networks need two separate networks to approximate X → Y and Y → X mappings respectively, which leads to inaccurate bijective mapping and may accumulate the error of one mapping into the other. We take an alternative method and use the affine coupling layers in [12, 25] to enable invertibility of one single network. We design our invertible ISP with the compostition of a stack of invertible and tractable bijective functions
, i.e.
. For a given observed data sample x, we can derive the transformation to target data sample y through
我们将 RAW 数据空间表示为 X, sRGB 数据空间表示为 Y。本文的目标是找到一个可以将数据点从 RAW 数据空间映射到 sRGB 数据空间的可逆双射函数,记为 f : X → Y。为了达到这一目的,经典神经网络需要两个独立的网络分别逼近 X→Y 和 Y→X 映射,这就导致了不准确的双目标映射,可能会将一个映射的误差累积到另一个映射上。
本文采用了另一种方法,利用 [12,25] 中的仿射耦合层 (affine coupling layers) 来实现单个网络的可逆性。设计的可逆 ISP 由堆叠的可逆和易于处理的双射函数 组成,即
。对于给定的观测数据样本 x,我们可以通过推导到目标数据样本 y 的变换 (1) 和 (2)。

The bijective model
is implemented through affine coupling layers. In each affine coupling layer, given a D dimensional input m and d < D, the output n is calculated as
where s and t represent scale and translation functions from
, and ⊙ is the Hadamard product. Note that the scale and translation functions are not necessarily invertible, and thus we realize them by neural networks.
双目标模型 通过仿射耦合层实现。在每个仿射耦合层中,给定 D 维输入 m 且 d < D,则输出 n计算为 (3) 和 (4)。其中 s 和 t 表示
的尺度和平移函数,⊙ 为 Hadamard 积。注意尺度函数和平移函数不一定是可逆的,因此我们用神经网络实现它们。
As stated in [12], the coupling layer leaves some input channels unchanged, which greatly restricts the representation learning power of this architecture. To alleviate this problem, we firstly enhance [42] the coupling layer (3) by
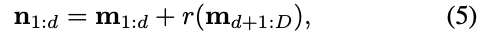
where r can be arbitrary function from
. The inverse step is easily obtained by
Next, we utilize the invertible 1 × 1 convolution proposed in [25] as the learnable permutation function to reverse the order of channels for the next affine coupling layer.
如 [12] 所述,耦合层保留了一些输入通道不变,这极大地限制了该体系结构的表示学习能力。为了缓解这个问题,我们首先通过 (5) 式增强耦合层 (3),其中 r 可以是 的任意函数。逆步长是很容易通过 (6) 和 (7) 得到。
接下来,我们利用 [25] 中提出的可逆 1 × 1 卷积作为可学习的排列函数来反转下一个仿射耦合层的通道顺序。
We remove the spatial checkerboard mask as it brings no evident performance improvement [25]. We follow the implementation of [10] and disable batch normalization [23] and weight normalization used in [12]. For our image-toimage translation task, we directly learn the RAW-to-RGB mapping without explicitly modeling the latent distribution to stabilize the training process.
我们删除了空间棋盘 mask,因为它没有带来明显的性能改进 [25]。我们遵循 [10] 的实现,禁用 [12]中使用的批处理归一化 [23] 和权重归一化。对于我们的图像到图像的翻译任务,直接学习 RAW 到RGB 映射,而不明确建模潜在分布以稳定训练过程。
Note that the input size of invertible neural networks must be identical to the output size. Thus, we take the bilinear demosaiced RAW data as input, which will not destroy the RAW data quality, and reversing the bilinear demosaicing is trivial [7]. For the affine coupling layer, we split the input into two parts. We note that although three-channel input cannot be split evenly, the invertible 1 × 1 convolution ensures that unchanged components are updated in the next invertible block. Thus R, G, and B channels are still treated equally. We also do an online gamma correction (i.e. without storing on disk) to RAW data to compress the dynamic range for faster convergence speed.
注意,可逆神经网络的输入大小必须与输出大小相同。因此,我们将双线性 demosaicing RAW 数据作为输入,这不会破坏 RAW 数据的质量,反转双线性 demosaicing 是微不足道的 [7]。对于仿射耦合层,将输入分成两部分。注意到,尽管三通道输入不能被均匀分割,但可逆的 1 × 1 卷积可以确保不变的组件在下一个可逆块中被更新。因此,R、G 和 B 通道仍然被平等对待。本文还对RAW 数据进行 online gamma 校正 (即不存储在磁盘上),以压缩动态范围以提高收敛速度。
The forward pass of our InvISP produces the sRGB images, and the reverse pass aims at recovering realistic RAW data. We conduct bi-directional training with L1 loss to optimize our framework.
where λ is the hyper-parameter used to balance the accuracy between RGB and RAW reconstruction. We set λ to 1 in our main experiments.
InvISP 的前向传递产生 sRGB 图像,反向传递旨在恢复真实的 RAW 数据。采用 L1 损失的双向训练来优化框架。平衡 RGB 和 RAW 重建精度的超参数 λ 设为 1。
2. Differentiable JPEG Simulator
Our goal is to train a robust invertible ISP that can tolerate the distortion by JPEG compression to recover accurate RAW. However, the JPEG compression algorithm is not differentiable, which can not be directly integrated into our end-to-end framework. Thus, we propose a differentiable JPEG simulator to enable our network robust to the JPEG compression through the optimization process. Since entropy encoding is lossless and goes after quantization, we skip this step and only simulate color space transformation, DCT, and quantization steps.
我们的目标是训练一个 robust 可逆 ISP,能够容忍 JPEG 压缩的失真,以恢复准确的 RAW。但是JPEG 压缩算法是不可微的,不能直接集成到我们的端到端框架中。因此,我们提出了一个可微分的 JPEG 模拟器,使我们的网络通过优化过程实现 robust JPEG 压缩。由于熵编码是无损的,并且是在量化之后进行的,所以我们跳过这一步,只模拟颜色空间变换、DCT 和量化步骤。
To simulate the DCT process, we compute the DCT coefficients and split the input into 8 × 8 blocks. Then each block is multiplied by DCT coefficients to get the DCT map. In JPEG compression, the DCT map is divided by quantization tables and rounding to the integer type. Since the rounding function is not differentiable, we design a differentiable rounding function base on the Fourier series, which can be defined as:
where I is the input map after divided by quantization tables in JPEG compression, and K is used for the tradeoff between approximation accuracy and computation efficiency. As K increases, the simulation function is closer to the real round function, but the running time will also increase. We empirically set K to 10. The rounding process is illustrated in Figure 4.


为了模拟 DCT 过程,我们计算 DCT 系数,并将输入分成 8 × 8 块。然后每个块乘以 DCT 系数得到 DCT 映射。在 JPEG 压缩中,DCT 映射被量化表分割并舍入为整数类型。由于舍入函数不可微,我们在傅里叶级数的基础上设计了一个可微的舍入函数,其定义为 (9)。
其中 I 为 JPEG 压缩中经过量化表的分割后的输入映射,K 用于在逼近精度和计算效率之间进行权衡。随着 K 的增加,仿真函数更接近真实的圆函数,但运行时间也会增加。我们根据经验把 K 设为 10。舍入过程如图 4 所示。
In the decoding phase of JPEG compression, I is multiplied by the quantization table. The inverse DCT and color space transformation are then applied to reconstruct the simulated JPEG images.
在 JPEG 压缩解码阶段,I 乘以量化表。然后应用 DCT 反变换和颜色空间变换重建仿真 JPEG 图像。
Discussion
Differentiable rounding function is widely used in network quantization research. To fairly prove the effectiveness of our proposed rounding function, we also compare with the rounding function in [17], as shown in Table 1. Our method can achieve a better balance between RGB rendering and RAW reconstruction.

可微舍入函数在网络量化研究中得到了广泛的应用。为了充分证明我们所提出的舍入函数的有效性,我们还与 [17] 中的舍入函数进行了比较,如表 1 所示。我们的方法可以在 RGB 绘制和 RAW重建之间实现更好的平衡。