文章目录
各位小伙伴大家好,我是小曾哥,这篇文章算是之前写的存货,主要内容是关于主动学习在生成式对抗网络这个方向的三篇文章,还是很有启发的,希望能够对大家有所帮助,现在分享给大家!
Generative Adversarial Active Learning–生成性对抗性主动学习
第一篇用以GAN为代表的生成式方法来做Active Learning的文章,比较有开创性,
Abstract
提出了一种新的基于产生式对抗网络(GAN)的主动查询合成学习方法。
与常规的主动学习不同,该算法自适应地合成训练实例进行查询,提高了学习速度。
在某些情况下,该算法的性能优于传统的基于池的方法。
Introduction
GAN(生成性对抗网络)
GAN的想法很简单:以假乱真
涉及两个“对手”:Generator(生成者)—伪造者、Discriminator(判别者)—警察
伪造者总想着制造出能够以假乱真的钞票,而警察则试图用更先进的技术甄别真假钞票。两者在博弈过程中不断升级自己的技术。
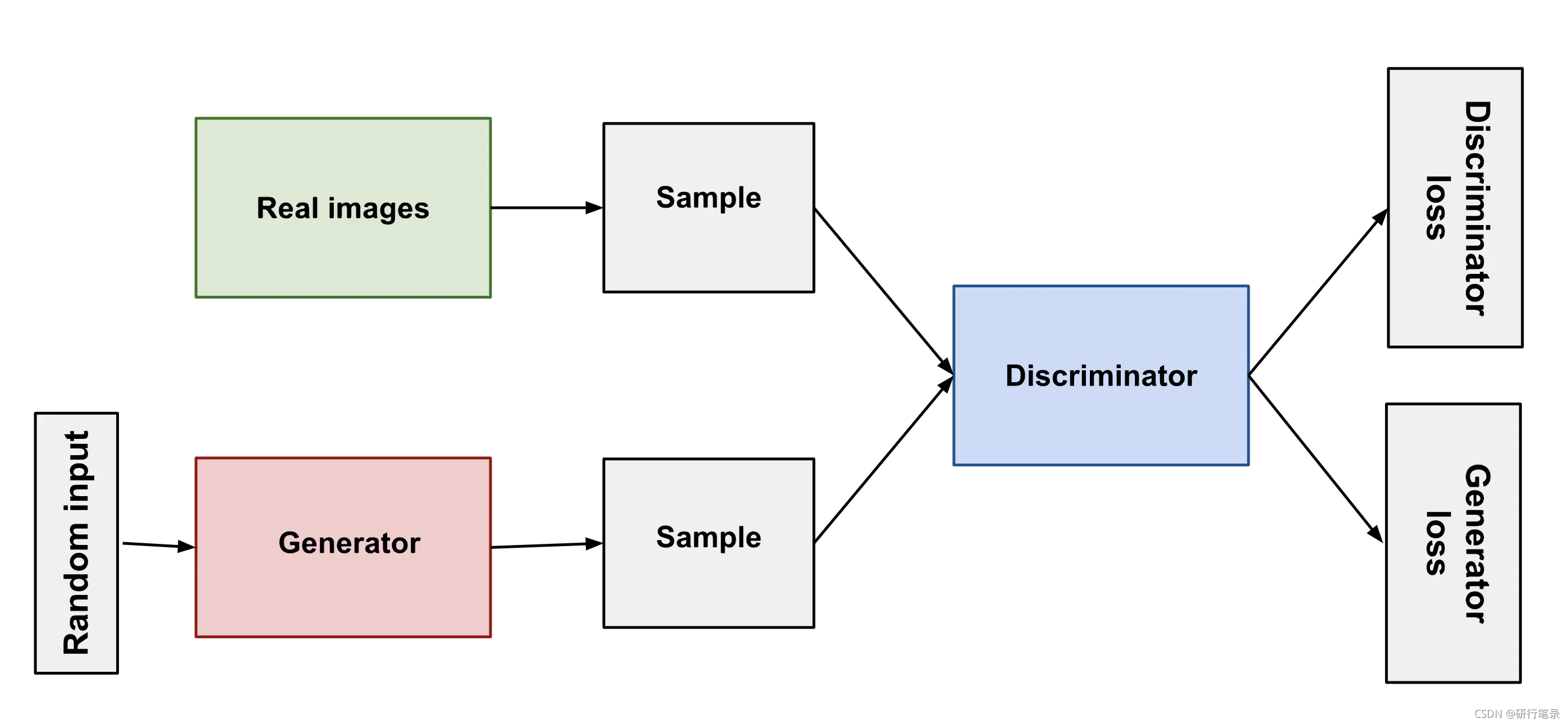
通过寻找两人对抗性博弈的纳什均衡来训练一个生成性模型。【即存在一组策略(g, d),如果Generator不选择策略g,那么对于Discriminator来说,总存在一种策略使得Generator输得更惨】
它在复杂领域中生成样本的能力为主动学习者提供了按需合成训练样本的新可能性,而不是依赖于从给定池中选择要查询的实例。
生成器G和鉴别器D之间的下面的两人极小极大博弈
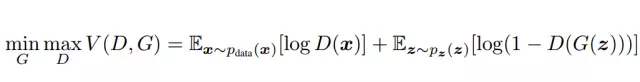
其中真实数据的 × \times × 服从 P data P_{\text {data }} Pdata 分布, P z ( z ) P_{z}(z) Pz(z) 是噪声z的分布。 G ( z ) G(\mathrm{z}) G(z) 将z映射到数据空间去拟合真实图像的分布,而 D ( x ) (\mathrm{x}) (x) 得到真实数据的概率。 为了更好的学习到生成器在数据 x x x 上的分布P,训练时自然使D判断x是从P中取出的期望E最大化, 同时最小化伪造的概率 log ( 1 − \log (1- log(1− D ( G ( z ) ) ) D(G(z))) D(G(z))) 而训练了 G \mathrm{G}_{\mathrm{}} G
主动学习
主动学习算法通常从池中策略性地选择训练样本,以最大化训练分类器的准确性。这些算法的目标是降低标签的复杂度。
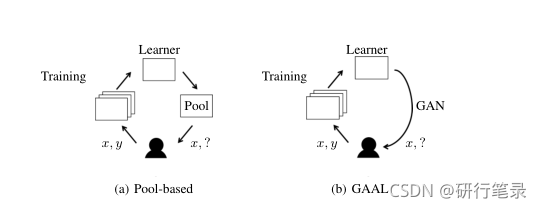
(A)基于池的主动学习情景。学习者从给定的未标记池中选择样本进行查询。
(B)Gaal算法。学习者使用GAN合成样本以供查询
Contribute
- 是第一个使用深度生成模式的主动学习框架
- 虽然我们并不认为我们的方法在准确率方面总是优于以前的活跃学习者,但在某些情况下,它产生的分类性能是完全监督学习方案无法达到的。
- 这是第一次报道主动学习综合在图像分类中的数值结果,该框架可能会启发未来GAN在主动学习中的应用。
- 与基于池的方法相比,我们的方法的性能更具竞争力。
Generative Adversarial Active Learning
介绍我们的主动学习方法,我们称之为生成性对抗性主动学习(GAAL)。它将查询合成与不确定性抽样原则相结合。
min z ∥ W ⊤ ϕ ( G ( z ) ) + b ∥ ( 3 ) \min _{z}\left\|W^{\top} \phi(G(z))+b\right\|(3) zmin∥∥W⊤ϕ(G(z))+b∥∥(3)

1、通过求解 (2) 在所有未标记数据上训练 generator G
2、通过随机选择一小部分数据来初始化标记的训练数据集S
3、根据当前的学习器通过降低梯度来求解优化问题(3)
4、使用解{z1, z2, . . .}and G 生成用于查询的实例
5、通过专家给G(z)进行标注
6、将标记数据添加到训练数据集中并重新训练学习器,更新 W,b

(A)支持向量机主动算法选择最接近边界的实例来查询先知。
(B)GAAL算法合成对当前学习者有用的实例。对于学习者来说,合成的实例可能比现有池中的其他实例更具信息量。
优化问题的解G(Z)在被标记之后,将被用作下一次迭代的新的训练数据。
在训练GAN时候,优化问题(3)是非凸的,可能有许多局部极小值。一个典型的目标是找到良好的局部极小值,而不是全局极小值。我们使用带动量的梯度下降算法来解决这个问题。
Variational Adversarial Active Learning(变分对抗式主动学习)
Abstract
我们描述了一种基于池的半监督主动学习算法,该算法以对抗的方式隐式学习这种采样机制。与传统的主动学习算法不同,我们的方法是任务无关的,我们的方法使用一个变分自动编码器(VAE)和一个经过训练的对抗性网络来识别未标记和标记数据,从而学习一个潜在空间。
VAE最小最大博弈:当VAE试图欺骗敌对网络预测所有数据点都来自标记池时,敌对网络学习如何区分潜在空间中的不同点。
Introduction
深度学习的问题:计算机方法的成功很大程度上依赖于大量的带注释的训练示例,示例的标注成本可能过高,或者无法大规模获得。
主动学习的目的:旨在以增量方式选择样本进行注释,从而在低标记成本的情况下获得高分类性能。
VAE因其生成特性以及学习丰富潜在空间的能力而受到了广泛的研究和重视
我们的方法,变分对抗式主动学习(VAAL),从未标记池中选择在VAE学习的潜在空间中完全不同的标记实例,以最大限度地提高在新标记数据上学习的表示性能。
VAE和鉴别器被构建为一个两人mini-max游戏,以便训练VAE学习一个特征空间,从而使对抗网络预测所有数据点,包括标记集和未标记集,当鉴别器网络学习如何区分它们时,它们来自标记池。
[我们认为VAAL通过学习表征和不确定性来实现这一点,从而使它们在独立于主流任务的情况下相互有利,从而产生更好的主动学习表现]
Framework
VAE补充内容: 变分自编码器的定义:训练时加入正则化防止过拟合,保证隐层空间具有足够的能力进行生成过程的自编码器。所以对自编码器进行了一些轻微的修改:编码过程将输入数据编码成分布而不是一些点。
VAE训练过程:1.将数据编码成分布;2.再从隐层分布中采样数据点;3.解码还原数据并计算重构损失;4.将重构损失反向传播。
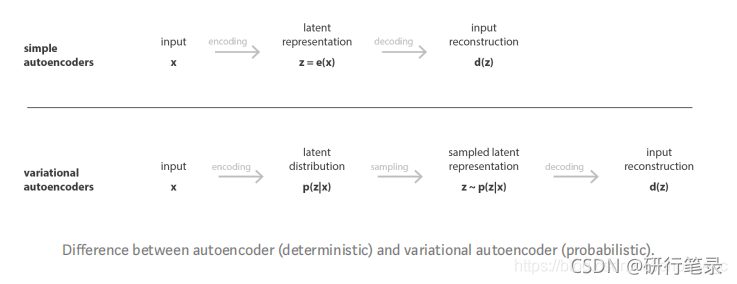
转换表征学习
使用β-变分自动编码器进行表示学习,其中编码器使用高斯先验学习底层分布的低维空间,解码器重建输入数据。为了捕获在标记池上学习的表示中缺少的特征,我们可以使用未标记的数据并执行转换学习。【标记和未标记数据相关的潜在特征的混合】
VAE 的目标函数为最小化给定样本边际似然概率的变分下界:
L V A E trd = E [ log p θ ( x L ∣ z L ) ] − β D K L ( q ϕ ( z L ∣ x L ) ∥ p ( z ) ) + E [ log p θ ( x U ∣ z U ) ] − β D K L ( q ϕ ( z U ∣ x U ) ∥ p ( z ) ) ( 1 ) \begin{aligned} \mathcal{L}_{\mathrm{VAE}}^{\operatorname{trd}}=& \mathbb{E}\left[\log p_{\theta}\left(x_{L} \mid z_{L}\right)\right]-\beta \mathrm{D}_{\mathrm{KL}}\left(q_{\phi}\left(z_{L} \mid x_{L}\right) \| p(z)\right) \\ &+\mathbb{E}\left[\log p_{\theta}\left(x_{U} \mid z_{U}\right)\right]-\beta \mathrm{D}_{\mathrm{KL}}\left(q_{\phi}\left(z_{U} \mid x_{U}\right) \| p(z)\right) \end{aligned} (1) LVAEtrd=E[logpθ(xL∣zL)]−βDKL(qϕ(zL∣xL)∥p(z))+E[logpθ(xU∣zU)]−βDKL(qϕ(zU∣xU)∥p(z))(1)其中qφ和pθ分别是由φ和θ参数化的编码器和解码器。p(z)是作为单位高斯选择的先验值,β是优化问题的拉格朗日参数
对抗性表征学习
由VAE学习的表示是与标记和未标记数据相关的潜在特征的混合
理想代理:具有一个完美的采样策略,能够将最具信息性的未标记数据发送到oracle
为我们的采样策略训练一个对抗性网络(以学习如何区分潜在空间中的编码特征)
(这种对抗性网络类似于GANs中的鉴别器,它们的作用是区分生成器创建的假图像和真图像)
本文的抽样策略为训练一个对抗性网络,以学习如何区分隐藏空间中不同类别数据的编码特征。训练对抗网络,将潜在表示映射为二进制标签:如果样本数据为已标注,则为 1,否则为 0。
关键是VAE和对抗性网络是以对抗性的方式一起学习的,当VAE以相似的概率分布qφ(zl|xl)和qφ(zu|xu)将已标记数据和未标记数据映射到相同的潜在空间中时,它欺骗鉴别器将所有输入分类为已标记数据。另一方面,鉴别器试图有效地估计数据来自未标记数据的概率。
可以将VAE的对抗性角色的目标函数表示为二元交叉熵损失,如下所示
L V A E a d v = − E [ log ( D ( q ϕ ( z L ∣ x L ) ) ) ] − E [ log ( D ( q ϕ ( z U ∣ x U ) ) ) ] ( 2 ) \mathcal{L}_{\mathrm{VAE}}^{a d v}=-\mathbb{E}\left[\log \left(D\left(q_{\phi}\left(z_{L} \mid x_{L}\right)\right)\right)\right]-\mathbb{E}\left[\log \left(D\left(q_{\phi}\left(z_{U} \mid x_{U}\right)\right)\right)\right] (2) LVAEadv=−E[log(D(qϕ(zL∣xL)))]−E[log(D(qϕ(zU∣xU)))](2)
训练鉴别器的目标函数也如下所示
L D = − E [ log ( D ( q ϕ ( z L ∣ x L ) ) ) ] − E [ log ( 1 − D ( q ϕ ( z U ∣ x U ) ) ) ] ( 3 ) \mathcal{L}_{D}=-\mathbb{E}\left[\log \left(D\left(q_{\phi}\left(z_{L} \mid x_{L}\right)\right)\right)\right]-\mathbb{E}\left[\log \left(1-D\left(q_{\phi}\left(z_{U} \mid x_{U}\right)\right)\right)\right] (3) LD=−E[log(D(qϕ(zL∣xL)))]−E[log(1−D(qϕ(zU∣xU)))](3)
通过将公式和公式相结合。(1)和等式(Eq.。(2)我们得到了V-AAL中V-AE的完整目标函数如下 L V A E = λ 1 L V A E t r d + λ 2 L V A E a d v \mathcal{L}_{\mathrm{VAE}}=\lambda_{1} \mathcal{L}_{\mathrm{VAE}}^{t r d}+\lambda_{2} \mathcal{L}_{\mathrm{VAE}}^{a d v} LVAE=λ1LVAEtrd+λ2LVAEadv
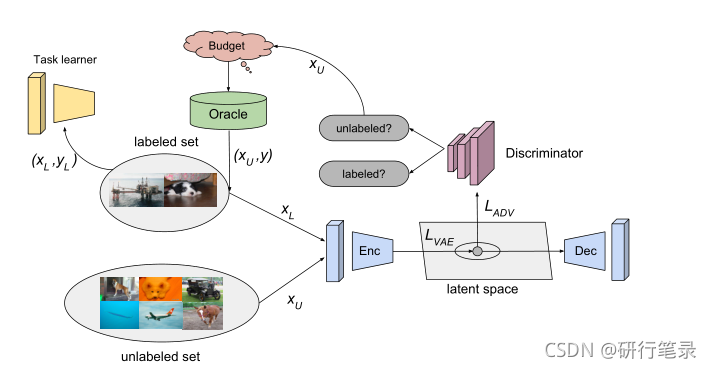
我们的模型(VAAL)使用基于重构和对抗性损失优化的VAE来学习标签数据在潜在空间中的分布。二元对抗性分类器(鉴别器)预测未标记的示例,并将它们发送到先知进行注释。VAE被训练来欺骗对手网络,使其相信所有的样本都来自标记的数据,而鉴别器被训练来区分标记的样本和未标记的样本。样本选择与我们为其标记数据输入的主流任务完全分开,这使得我们的方法是不可知的

采样策略和噪声
一个理想的Oracle,它总是为活动的学习者提供正确的标签,以及一个嘈杂的Oracle,它不可逆地为某些特定的类提供错误的标签。
我们使用与鉴别器预测相关的概率作为分数,收集每批预测为“未标记”且置信度最低的样本数量,以发送给oracle。请注意,概率越接近零,它来自未标记池的可能性就越大。
假如说要挑选b个高质量样本给人工标注,所用依据是鉴别器的预测分数(挑选b个最低的自信度,D判断出来越小的,越可能是未标记池中的数据)

Task-Aware Variational Adversarial Active Learning(任务感知变分对抗式主动学习)
Abstract
目前优缺点:最近探索的两个有希望的主动学习方向是基于数据分布的方法来选择远离当前标记池的数据点(VAAL),以及基于任务模型视角的模型不确定性方法(Learn_loss)。不幸的是,前者没有利用任务的结构,后者似乎没有很好地利用总体数据分布。
提出了同时利用数据分布和模型不确定性方法的方法,通过将损失预测建模为ranker,将学习损失预测模块和RankCGAN概念结合到VAAL中,利用考虑了标记池和未标记池的数据分布的变分对抗式主动学习(VAAL),证明了在各种平衡和不平衡的基准数据集上,我们提出的方法优于目前最先进的主动学习方法。
Introduction
我们回顾了两种最新的主动学习方法,即学习损失法(Yoo& Kweon,2019)和变分对抗式主动学习法(VAAL)(Sinha等人,2019),并研究了主动学习方法,以利用这两种方法的优点。虽然VAAL以任务无关的方式利用标记和未标记数据集的特征结构,而不需要任务学习者提供任何信息(Sinha等人,2019),但学习损失是利用损失预测模块预测未标记数据的任务学习者损失。我们提出使用RankCGAN(Saquil et al.,2018)的概念,将预测损失的任务相关信息纳入V AAL,以便V AAL的全局数据结构和学习损失的局部任务相关信息都可用于选择样本进行注释。
Contribute
1、重新审视学习损失工作/VAAL工作,提出新8的主动学习方法,称为任务感知VAAL(TA-V AAL),以利用标记/未标记数据集的全局数据结构以及损失预测模块的局部任务感知信息,实现深度神经网络的主动学习
2、在平衡数据集和非平衡数据集上对所提出的方法进行了广泛的实证分析,不仅使用了性能指标,还使用了所提出的主动抽样方法的信息论指标,显示了其最先进的性能以及可靠的主动抽样结果。
Related work
有许多关于主动学习以选择信息量最大的数据点的工作,我们将其分为两种不同的方法:基于模型确定性的方法和基于数据分布的方法。
前者具有不受未标记数据影响的样本选择规则,但仅将这些规则应用于未标记数据,而后者利用标记和未标记数据建立(或训练)样本选择规则(或深度神经网络)
基于模型不确定性的深度神经网络主动学习的研究主要有:
1、BALD被扩展以适应具有贝叶斯神经网络和蒙特卡罗辍学的深层神经网络;提出了两步方法,通过使用bootstrapping选择k个最不确定的样本,然后使用贪婪方法找到样本中最具代表性的子集。
2、贝叶斯生成性主动深度学习是一种利用已标记数据和已标记假数据(从深度生成模型生成的图像)来训练分类器(任务学习器)和真假图像鉴别器的方法
3、提出的主动学习损失方法将“损失预测模块”附加到任务学习器上,并训练损失预测模块来预测未标记数据样本的目标损失。在学习损失方法中,预测损失作为模型不确定性的替代,并从中间层的特征信息中获得。
4、基于数据分布的方法同时利用已标记数据和未标记数据来形成样本选择规则,使得选择的样本远离已标记数据的分布,并具有最具代表性的未标记池信息。【对未标记数据进行聚类可以帮助从集群中选择样本,以便它们来自不同的集群,而不是来自一个或少数集群】
5、核心集方法是利用训练好的卷积神经网络模型的中间特征信息来最小化已标记数据点和未标记数据池之间的距离。
6、提出了变分自动编码器(VAE)的训练方法,它既能捕捉标记数据和未标记数据的表示信息,又能利用训练好的VAE编码器的潜在空间中的信息,采用对抗性学习来区分标记数据和标记数据。
我们的工作属于基于数据分发的方法,这是VAAL的一个扩展,将任务相关信息合并到VAE框架中。我们提出的框架可以同时适应全局数据分布结构和局部任务相关信息,从而获得高性能和可靠性。
Background
Learning loss for active learning
提出的损失预测模块来预测未标记数据池XU中的损失值ˆLu ;损失预测模块hloss由全局平均汇聚、完全连接层和REU预测L、地面真实目标损失组成;
使用两个样本点之间的排序作为另一个损失函数。
− 2 B ∑ i = 1 B / 2 ( max ( 0 , − I i ⋅ ( l ^ i − l ^ j ) + ϵ ) ) with I i = { + 1 if l i > l j − 1 otherwise \begin{gathered} -\frac{2}{B} \sum_{i=1}^{B / 2}\left(\max \left(0,-I_{i} \cdot\left(\hat{l}_{i}-\hat{l}_{j}\right)+\epsilon\right)\right) \\ \text { with } I_{i}= \begin{cases}+1 & \text { if } l_{i}>l_{j} \\ -1 & \text { otherwise }\end{cases} \end{gathered} −B2i=1∑B/2(max(0,−Ii⋅(l^i−l^j)+ϵ)) with Ii={
+1−1 if li>lj otherwise
学习损失只利用已标记数据来训练损失预测模块,并将其应用于未标记数据,以选择具有相当高预测损失的样本。
VAAL
VAAL首先用标记数据集和未标记数据集训练VAE,以学习这两个数据集的表示,而不使用任何关于任务学习器T的信息来执行转导学习。然后,将用于确定已标记/未标记数据的鉴别器连接到VAE的潜在空间,然后以对抗的方式联合训练VAE和鉴别器。
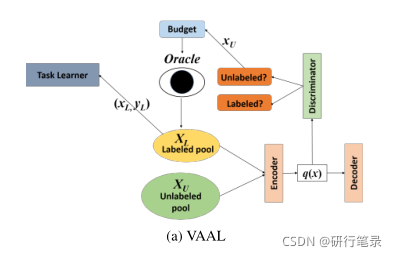
VAE将已标记数据池和未标记数据池都编码到相同的潜在空间中,并且将训练鉴别器来预测潜在空间中的点属于未标记数据池的概率。
VAAL是任务不可知的主动学习者,所提出的有标签/无标签样本的鉴别器似乎可以很好地替代任务型学习者。然而,我们推测,直接的任务相关信息可能有助于进一步提高主动学习的整体绩效。
Method
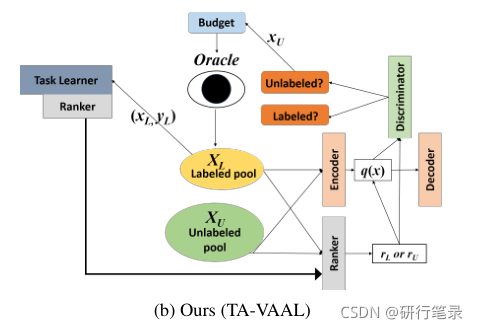
Ranking conditional GANs in VAAL
生成性对抗网络(GAN)由生成器G和鉴别器D(GoodFloor等人,2014)组成,已被应用于各种任务,如图像样式转换、图像超分辨率和图像编辑。
生成器G将潜在变量∼pz作为输入以生成样本dataG(Z),并且被训练来愚弄鉴别器D,而鉴别器D(X)被训练以辨别输入数据轴是真的(orx∼pdata)还是假的(org(Z),z∼pz)。
极小极大对策的目标函数可以表示为:
min G max D E x ∼ p data [ log D ( x ) ] + E z ∼ p z [ log ( 1 − D ( G ( z ) ) ] \begin{aligned} \min _{G} & \max _{D} \mathbb{E}_{x \sim p_{\text {data }}}[\log D(x)] \\ &+\mathbb{E}_{z \sim p_{z}}[\log (1-D(G(z))] \end{aligned} GminDmaxEx∼pdata [logD(x)]+Ez∼pz[log(1−D(G(z))]
潜变量z是从正态分布N(0,1)或均匀分布U(−,1)等概率分布中随机抽取的。
为了控制潜在空间的分布,条件GAN被提出在生成器G和鉴别器D中都引入附加的潜变量r
min G max D E r , x ∼ p data [ log ( D ( r , x ) ] + E r , z ∼ p z [ log ( 1 − D ( r , G ( r , z ) ) ] \begin{aligned} \min _{G} \max _{D} \mathbb{E}_{r, x \sim p_{\text {data }}}[\log (D(r, x)]+\mathbb{E}_{r, z \sim p_{z}}[\log (1-D(r, G(r, z))] \end{aligned} GminDmaxEr,x∼pdata [log(D(r,x)]+Er,z∼pz[log(1−D(r,G(r,z))]
RankCGAN将“Ranker”纳入CGAN,以便它产生排名属性,以提供对包含r的潜在子空间的主观控制,通过使用一个或多个主观属性,可以通过排序信息来控制生成模型。
RankCGAN框架通过输入具有损失预测模块的任务学习者关于预测损失的排序信息,控制损失预测的潜在子空间,从而重塑整个潜在空间。这种结构将允许在总体潜在空间中反映标记数据集和未标记数据集的全局数据结构,并在总体潜在空间中控制损失预测潜伏子空间。
作为任务学习者损失预测模块的排名器(Ranker)
RankCGAN是连接VAAL和学习损失的一种方法。“Ranker”概念在几个方面类似于主动学习学习损失中的损失预测模块(Y oo& Kweon,2019),其中之一是他们的训练损失排名。他们不是直接预测损失或价值本身,而是预测损失或价值的增长。
我们建议用(Saquil等人,2018年)的lossLR(ˆlP,lP)排名修改主动学习的原始学习损失。
− 2 B ∑ i = 1 B / 2 ( I i log [ sig ( l ^ i − l ^ j ) ] + ( 1 − I i ) log [ 1 − sig ( l ^ i − l ^ j ) ] ) with I i = { 1 if l i > l j 0 otherwise \begin{gathered} -\frac{2}{B} \sum_{i=1}^{B / 2}\left(I_{i} \log \left[\operatorname{sig}\left(\hat{l}_{i}-\hat{l}_{j}\right)\right]\right. \\ \left.+\left(1-I_{i}\right) \log \left[1-\operatorname{sig}\left(\hat{l}_{i}-\hat{l}_{j}\right)\right]\right) \\ \text { with } I_{i}= \begin{cases}1 & \text { if } l_{i}>l_{j} \\ 0 & \text { otherwise }\end{cases} \end{gathered} −B2i=1∑B/2(Iilog[sig(l^i−l^j)]+(1−Ii)log[1−sig(l^i−l^j)]) with Ii={
10 if li>lj otherwise
具有Ranker Ris的任务学习者的总损失函数表示为
L T ( y ^ L , y L ) + η L R ( R ( x P ) , l P ) L_{T}\left(\hat{y}_{L}, y_{L}\right)+\eta L_{R}\left(R\left(x_{P}\right), l_{P}\right) LT(y^L,yL)+ηLR(R(xP),lP)
Task-aware variational adversarial active learning
我们提出了我们的任务感知VAAL,它将条件VAE与秩变量(预测损失或真实损失)相结合,并将任务学习者与Ranker相结合,通过将Ranker输出反馈到条件VAE中的秩变量中来产生损失秩信息,如图1b所示。我们提出的方法通过使用条件GAN(RankCGAN),紧密地连接了基于模型不确定性的方法和基于数据分布的方法,因此关于数据分布的信息可以解释模型不确定性信息(预测损失)。我们认为,与仅使用标记数据训练的典型模型不确定性方法相比,我们提出的方法将具有使用更多数据(未标记数据)的优势。
为了通过排名(Ranker的输出)以条件对抗的方式训练条件VAE,条件VAE的目标函数LtransVAE用于学习特征标记池和未标记池的可以重新表述为
E [ log p θ ( x L ∣ z L , r L ) ] − λ K L ( q θ ( z L ∣ x L ) ∥ p ( z ) ) + E [ log p θ ( x U ∣ z U , r U ) ] − λ K L ( q θ ( z U ∣ x U ) ∥ p ( z ) ) \begin{aligned} &\mathbb{E}\left[\log p_{\theta}\left(x_{L} \mid z_{L}, r_{L}\right)\right]-\lambda K L\left(q_{\theta}\left(z_{L} \mid x_{L}\right) \| p(z)\right)+ \\ &\quad \mathbb{E}\left[\log p_{\theta}\left(x_{U} \mid z_{U}, r_{U}\right)\right]-\lambda K L\left(q_{\theta}\left(z_{U} \mid x_{U}\right) \| p(z)\right) \end{aligned} E[logpθ(xL∣zL,rL)]−λKL(qθ(zL∣xL)∥p(z))+E[logpθ(xU∣zU,rU)]−λKL(qθ(zU∣xU)∥p(z))
其中qθ和pθ是被θ参数化的V AE的编码器和解码器,rL和rU分别是有标记的和未标记的数据点的排序器的输出,p(Z)是高斯分布,λ是超参数,KL(·)是Kullback-Leibler距离,并且使用再参数化技术进行训练。用于训练VAE的另一个损失函数是通过表示已标记和未标记池的相同概率分布来欺骗二元鉴别器D的对抗性损失。条件对抗性损失的目标函数为
L V A E a d v = − E [ log D ( r L , q θ ( z L ∣ x L ) ] − E [ log ( D ( r U , q θ ( z U ∣ x U ) ] \begin{aligned} L_{V A E}^{a d v}=&-\mathbb{E}\left[\log D\left(r_{L}, q_{\theta}\left(z_{L} \mid x_{L}\right)\right]\right.\\ &-\mathbb{E}\left[\operatorname { l o g } \left(D\left(r_{U}, q_{\theta}\left(z_{U} \mid x_{U}\right)\right]\right.\right. \end{aligned} LVAEadv=−E[logD(rL,qθ(zL∣xL)]−E[log(D(rU,qθ(zU∣xU)]
训练鉴别器D的损失设计如下:
L D = − E [ log D ( r L , q θ ( z L ∣ x L ) ] − E [ log ( 1 − D ( r U , q θ ( z U ∣ x U ) ] \begin{aligned} &L_{D}=-\mathbb{E}\left[\log D\left(r_{L}, q_{\theta}\left(z_{L} \mid x_{L}\right)\right]\right. \\ &\quad-\mathbb{E}\left[\operatorname { l o g } \left(1-D\left(r_{U}, q_{\theta}\left(z_{U} \mid x_{U}\right)\right]\right.\right. \end{aligned} LD=−E[logD(rL,qθ(zL∣xL)]−E[log(1−D(rU,qθ(zU∣xU)]
将通过执行以下操作来选择要标记的数据点
( x 1 † , … , x b † ) = argmin ( x 1 , … , x b ) ⊂ X U D ( r U , q θ ( z U ∣ x U ) ) \left(x_{1}^{\dagger}, \ldots, x_{b}^{\dagger}\right)=\underset{\left(x_{1}, \ldots, x_{b}\right) \subset X_{U}}{\operatorname{argmin}} D\left(r_{U}, q_{\theta}\left(z_{U} \mid x_{U}\right)\right) (x1†,…,xb†)=(x1,…,xb)⊂XUargminD(rU,qθ(zU∣xU))
Vaal[115]提出了一种主动学习算法,它以对抗性的方式隐式学习这种采样机制。该方法将变分自动编码器(VAE)与对抗性网络相结合,并对其进行训练以区分未标记数据和已标记数据。玩VAE和对抗性网络之间的最小-最大博弈。当VAE试图欺骗对抗性网络预测所有数据点都来自标签池时,对抗性网络学习如何区分潜在空间中的不同之处。
TAVAAL[116]是另一种混合不确定性学习方法。它同时利用了数据分布和模型不确定性方法。与Vaal类似,它还考虑了已标记池和未标记池的数据分布。TAVAAL将学习损失预测模块和RankCGAN[118]概念结合到Vaal中,将损失预测建模为一个排名器。实验表明,TAVAAL在各种平衡和不平衡基准数据集上具有一定的优势。
预测器中的损失也可以视为一种不确定性。在主动学习的损失学习(LLAL)[21]中,作者提出了一种新的主动学习方法,该方法简单,但对深度预测的任务不可知。它将一个名为“损失预测模块”的小参数模块附加到选择器上,并学习它来预测未标记输入的预测损失。然后,该选择器可以建议预测模型可能产生错误预测的数据。