根据公司业务需求,项目需要读写分离,所以记录下读写分离的过程。
分为两个部分:
1.项目的读写分离。
2.mysql数据库的主从复制点此查看。
本篇使用的依赖包为sharding-jdbc-spring-boot-starter,也有考虑直接用dynamic-datasource-spring-boot-starter,但是需要在程序中显式的声明所指定的数据源,并且在从库>=2 的时候需要自己写算法进行读库的选择。而sharding-jdbc支持读库的负载均衡策略,sharding会根据语句的关键字来決定是读操作还是写操作
Insert选择主库
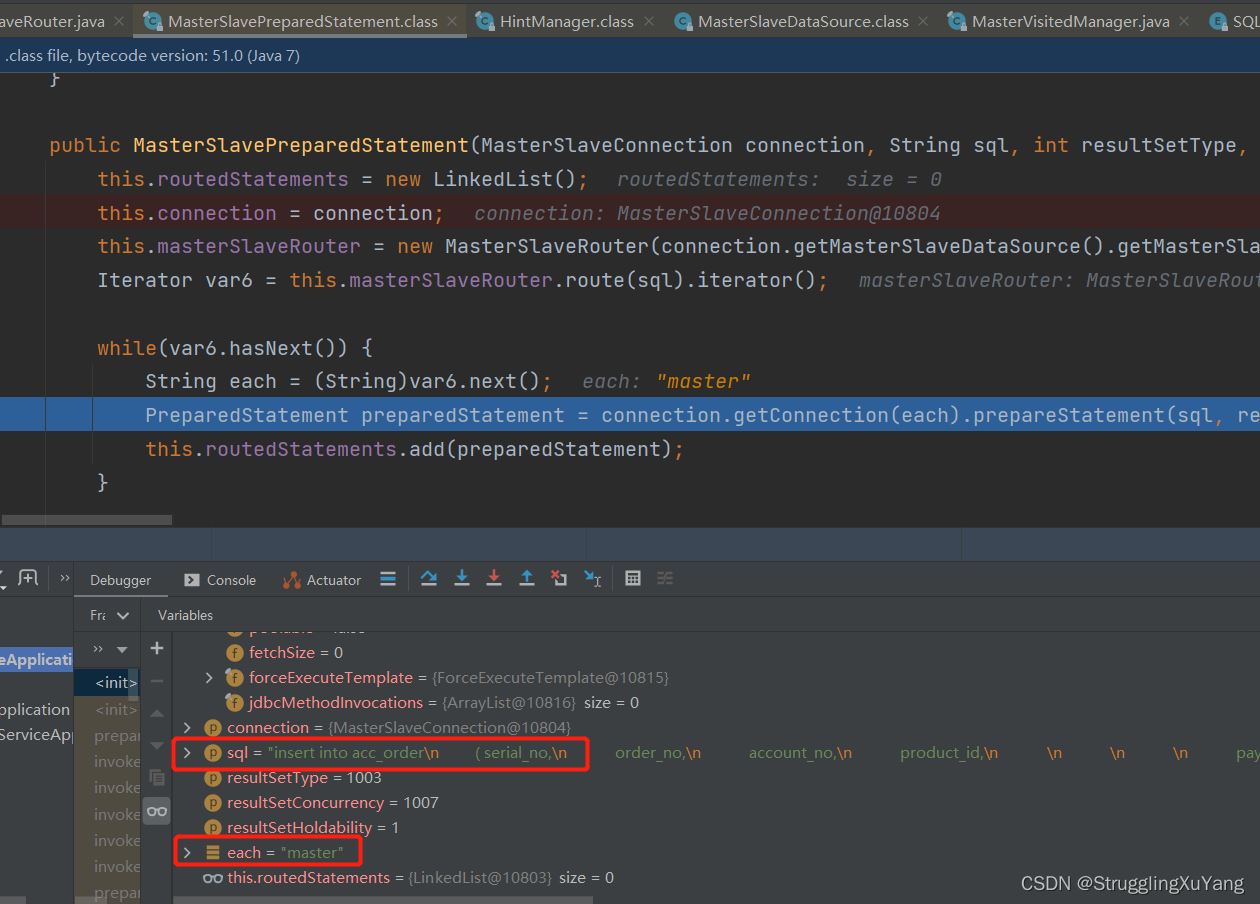
Select选择从库2(由于设置的了轮询,所以下一次就是从库1)
1.项目引入依赖
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC1</version>
</dependency>
2.yml配置
共有三台机器,
主库一台(127.0.0.1)
从库两台(192.168.1.5 192.168.1.6)
spring:
shardingsphere:
props:
sql:
show: false
sharding:
default-data-source-name: master
masterslave:
name: ms
master-data-source-name: master
slave-data-source-names: slave1,slave2
#配置slave节点的负载均衡均衡策略,采用轮询机制
load-balance-algorithm-type: round_robin
datasource:
names: master,slave1,slave2
master:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/life_account_db?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai
username: root
password: root
maxPoolSize: 100
minPoolSize: 5
slave1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.1.5:3306/life_account_db?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai
username: test
password: Houxuyang123!@#
maxPoolSize: 100
minPoolSize: 5
slave2:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.1.6:3306/life_account_db?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai
username: test
password: Houxuyang123!@#
maxPoolSize: 100
minPoolSize: 5
3.启动

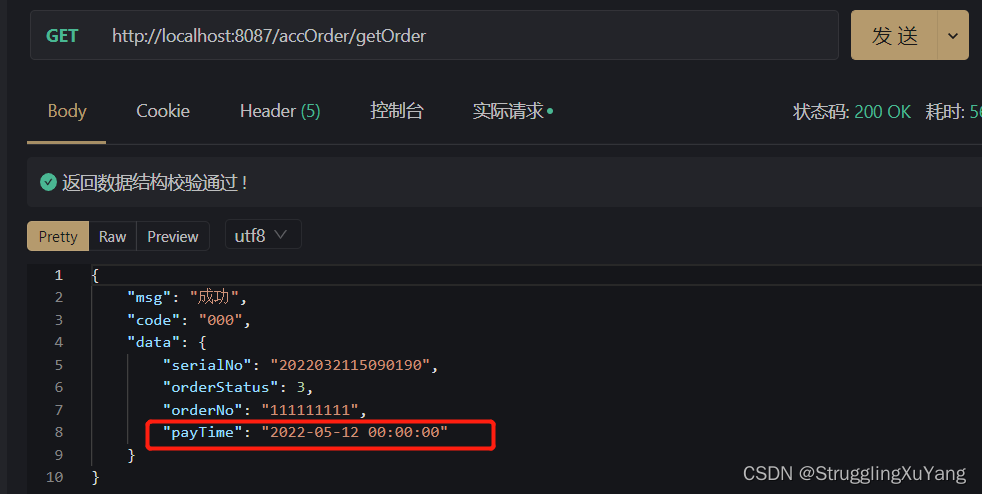
4.测试
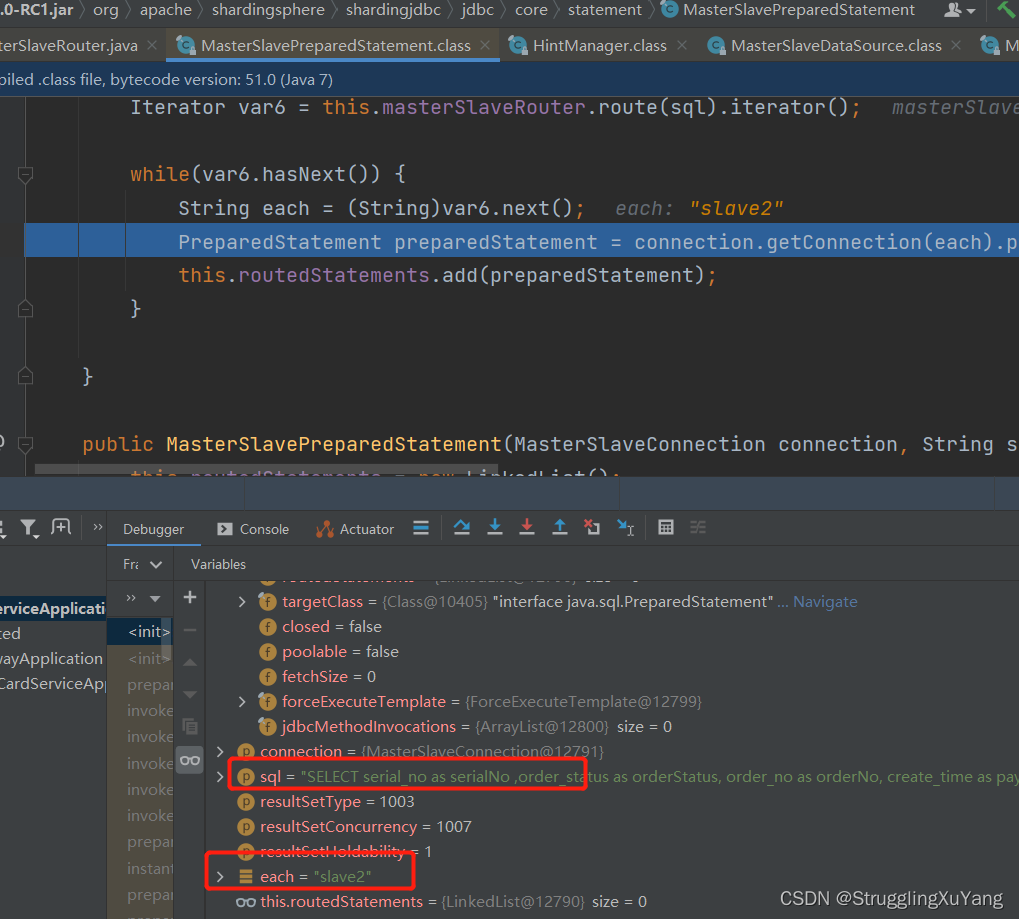
第一次读数据(从库1)
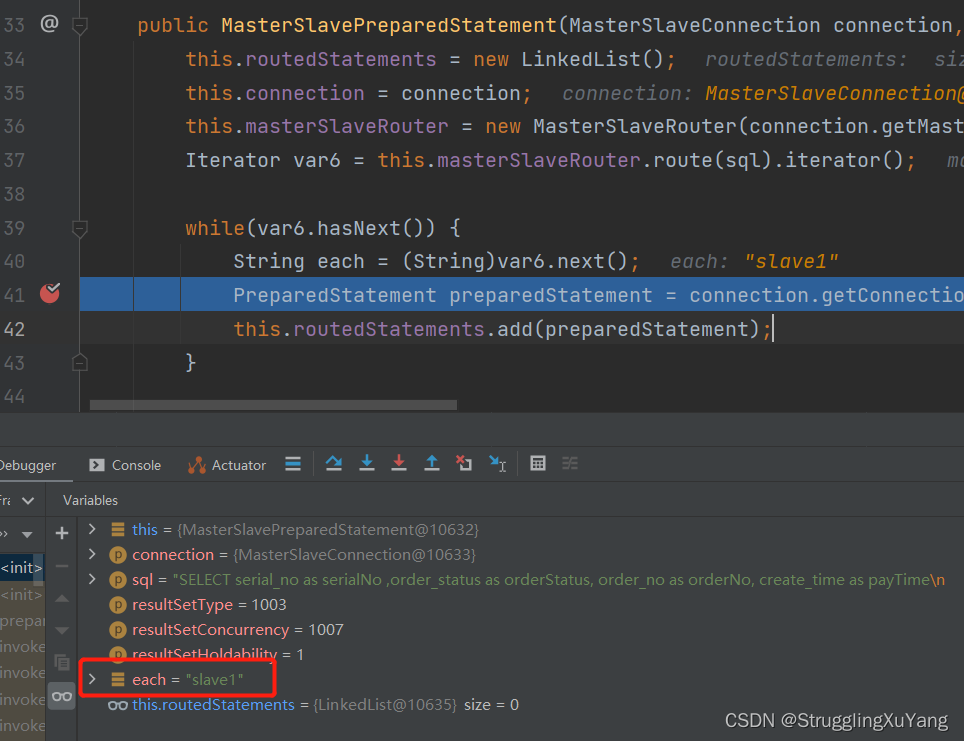
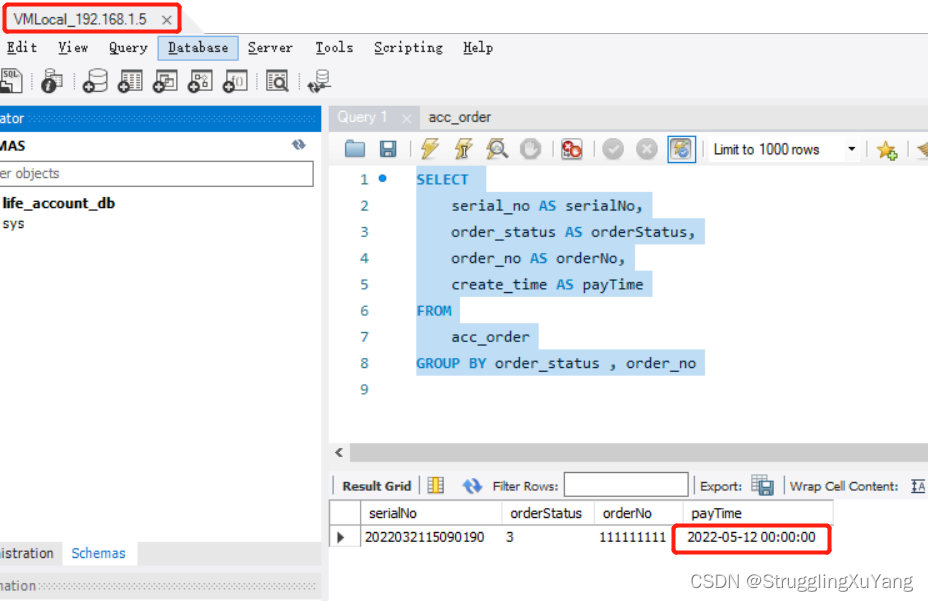
第二次读数据(从库2)
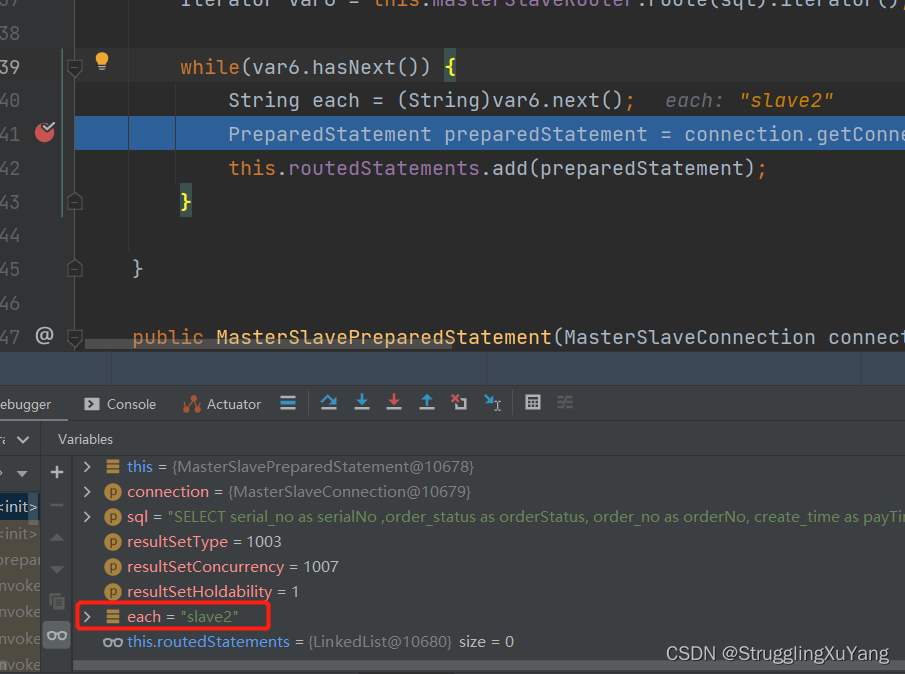
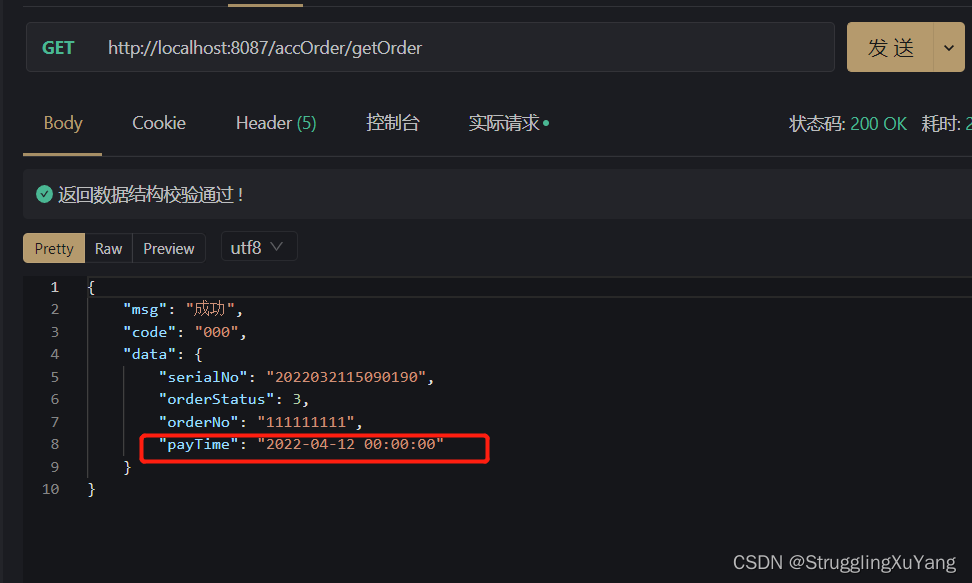
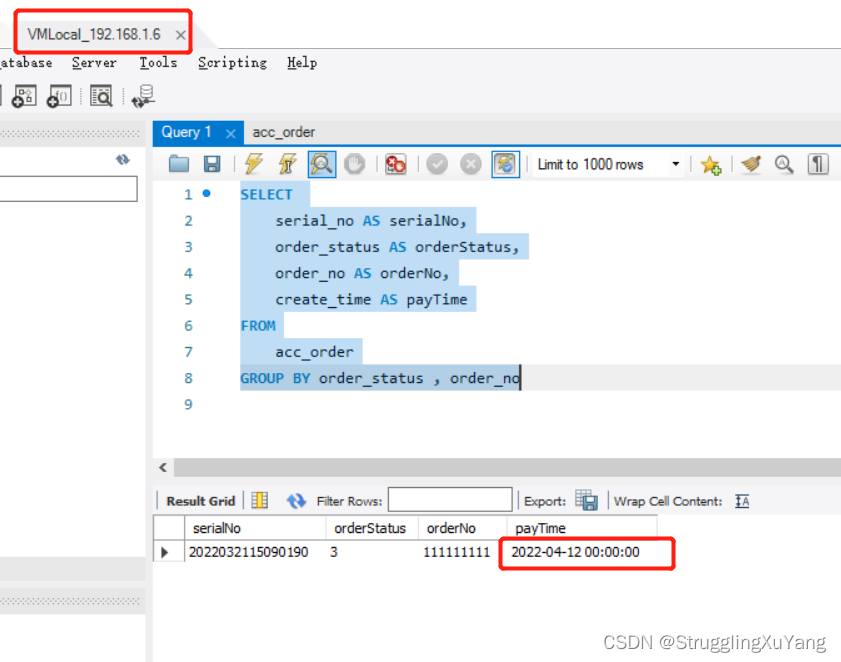
主库写
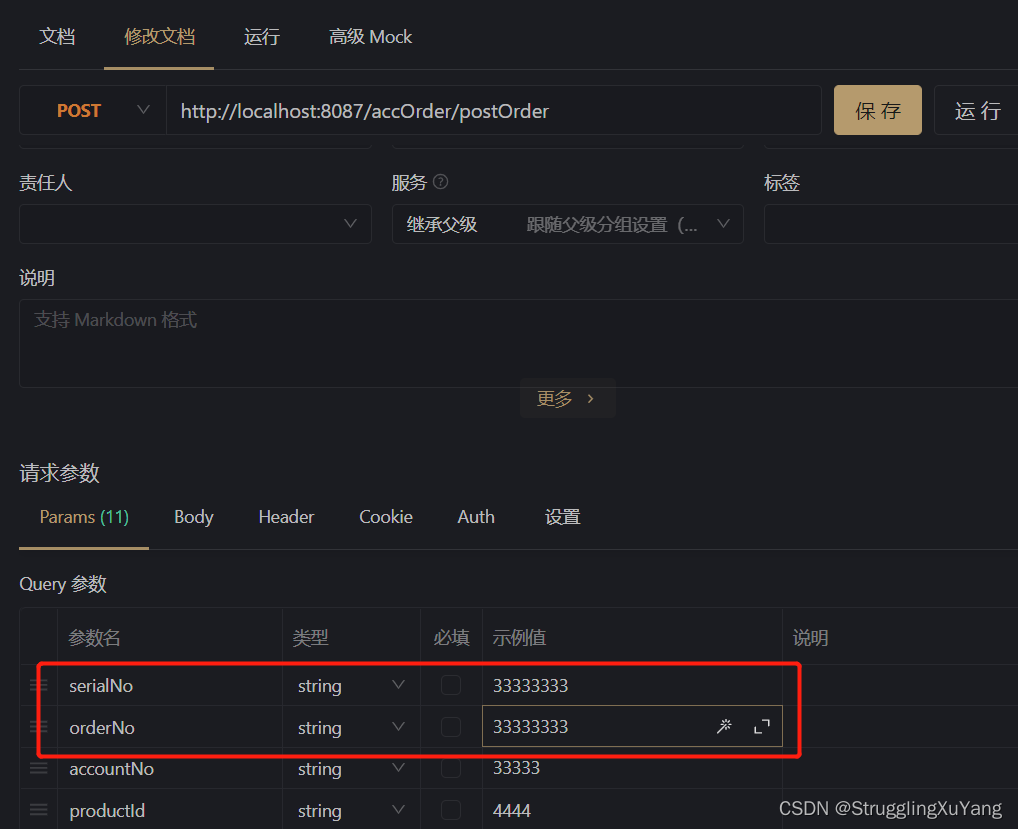

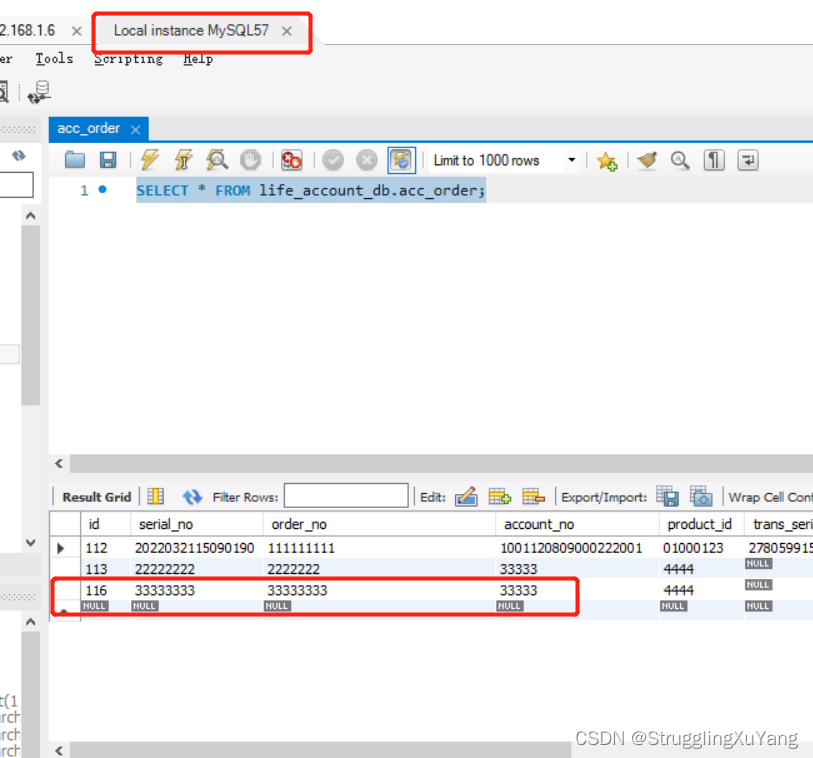
项目读写分离基本实现。
5.中间所遇到的问题
mysql查询问题
Expression #1 of SELECT list is not in GROUP BY clause and contains nonaggregated column 'life_account_db.acc_order.serial_no' which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by
原因:
没有遵循原则的sql会被认为是不合法的sql
1.order by后面的列必须是在select后面存在的
2.select、having或order by后面存在的非聚合列必须全部在group by中存在
解决方法:
修改配置文件:vim /etc/my.cnf
添加:sql_mode=STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION
重启mysql:systemctl restart mysqld
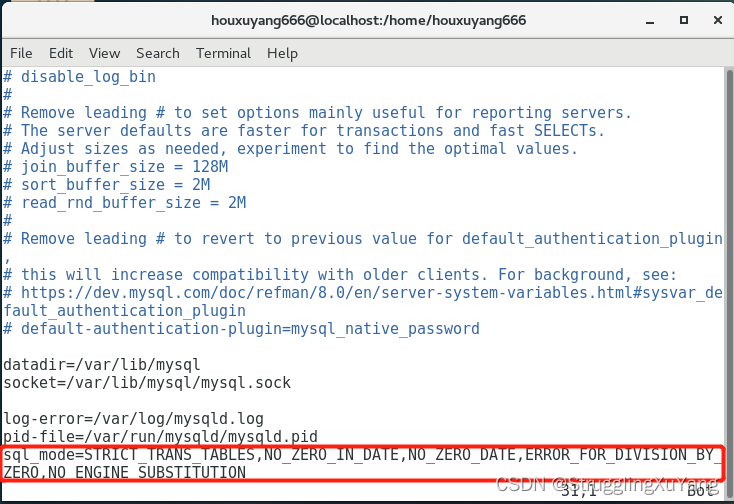
:wq
先自我介绍一下,小编13年上师交大毕业,曾经在小公司待过,去过华为OPPO等大厂,18年进入阿里,直到现在。深知大多数初中级java工程师,想要升技能,往往是需要自己摸索成长或是报班学习,但对于培训机构动则近万元的学费,着实压力不小。自己不成体系的自学效率很低又漫长,而且容易碰到天花板技术停止不前。因此我收集了一份《java开发全套学习资料》送给大家,初衷也很简单,就是希望帮助到想自学又不知道该从何学起的朋友,同时减轻大家的负担。添加下方名片,即可获取全套学习资料哦