本文作者:钟荣荣 Presto TSC member/Commiter
将Alluxio与Presto结合运行在社区中越来越流行,使用固态硬盘或内存来缓存热数据集,能够实现近Presto worker的数据本地行,从而避免了远程读取数据导致的高延迟。Presto支持基于哈希的软亲和调度(soft affinity scheduling),这样整个集群中相同数据只缓存一、两个副本,更多的热数据能被缓存到本地,提高缓存效率。现有哈希算法在集群规模发生变化时效果并不理想。针对这一问题,本文介绍了一种可用于软亲和调度的新哈希算法——一致性哈希(consistent hashing)。
软亲和调度
Presto使用一种叫做软亲和调度(soft affinity scheduling)的调度策略,将一个分片(split, 最小的数据处理单位)调度到同一个Presto worker(首选节点)上。分片和Presto worker之间的映射关系是由分片上的哈希函数计算出来的,确保同一个分片总是被散列到同一个worker上。
在第一次处理分片时,数据将被缓存在首选worker节点上。当后续的查询处理同一分片时,这些请求将再次被调度到同一个worker节点上。此时,由于数据已经缓存在本地,不需要再远程读取数据。
为了提高负载均衡,更好地处理worker节点响应不稳定的问题,会选择两个首选节点。如果第一个节点繁忙或没有响应,则会使用第二个节点。数据可能会被物理缓存到两个worker节点上。
关于软亲和调度的更多信息,请查看“通过 Alluxio 数据缓存降低Presto延迟”(https://prestodb.io/blog/2020/06/16/alluxio-datacaching#soft-affinity-scheduling)
哈希算法
软亲和调度依靠哈希算法来计算分片和worker节点之间的映射关系。原先使用的是取模函数:
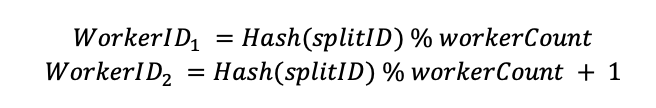
该哈希策略很简单,而且在集群稳定、worker节点没有变化的情况下效果很好。但是,如果某个worker节点暂时不可用或者掉线,worker节点的数量可能会发生变化,分片到worker节点的映射将全部需要重新分配,导致缓存命中率大幅下降。如果出现问题的worker稍后重新上线,则需要再次重新分配。
针对这个问题,Presto在通过取模计算出哪个worker分配给特定分片时,会对worker总数取模,而不是正在运行的worker数量。然而,这只能缓解worker节点临时掉线造成的重新分配问题。有时候因为工作负载的波动,增加/删除worker是合理操作。在这些情况下,是否可能保持合理的缓存命中率而无需进行大规模的重新分配?
我们的解决方案是一致性哈希算法。
一致性哈希
一致性哈希由David Karger在1997年第一次提出,是一种将网络访问请求分发到一组数量时常发生变化的网络服务器的分配算法。该技术被广泛用于负载均衡、分布式哈希表等。
一致性哈希的工作原理
比如,将哈希输出范围[0, MAX_VALUE]映射到一个圆环上(将MAX_VALUE连接到0)。为了说明一致性哈希的工作原理,我们假设一个Presto集群由3个Presto worker节点组成,其中有10个分片被反复查询。
首先,worker节点被散列到哈希环上。每个分片都被分配给哈希环上与该分片的哈希值相邻的worker(注:这里“相邻”定义为从分片哈希值所在位置,按顺时针方向找到的第一个worker节点)。
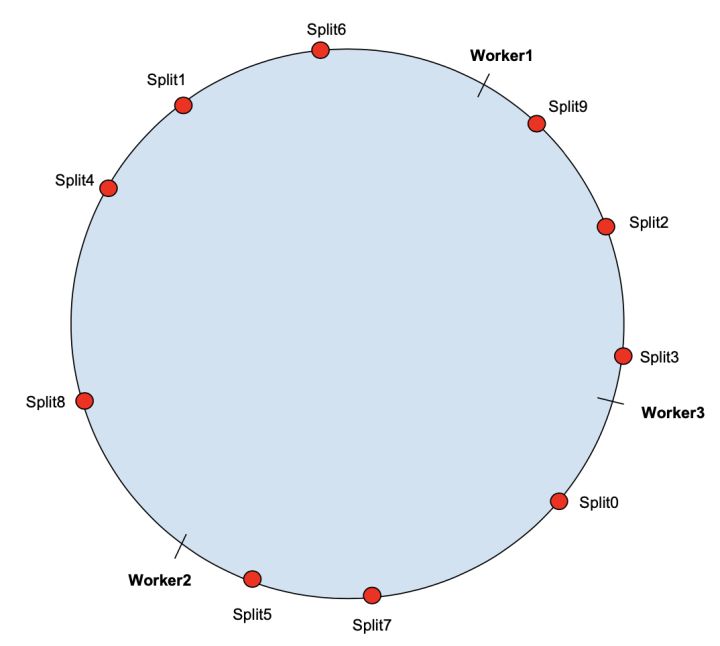
上述情况下,分片的分配如下:

删除一个worker
现在,如果worker2由于某种原因下线,那么根据算法,分片0、5和7将被调度到对应下一个哈希值的worker,也就是worker1上。

只有被分配到到已下线worker(在这里是worker2)的分片需要重新确定分配到哪个worker。其他数据不受影响。如果 worker32 稍后上线,分片 0、5 和 7 将会被重新分配到 worker2,不会影响其他worker的命中率。
增加一个worker
如果工作负载增加,需要在集群中增加另一个worker节点——worker4, worker4的哈希值在哈希环上的位置情况如下图所示:

在这种情况下,分片8将落入worker4的区间,所有其他分片的分配不受影响,因此这些分片的缓存命中率不会受到影响。重新分配的结果如下:

虚拟节点
从上面可以看出,一致性哈希可以保证在节点变化的情况下,平均只有

的分片需要被重新分配。然而,由于worker分布缺乏随机性,分片可能不会均匀地分布在所有worker节点上。针对这一问题,我们引入了“虚拟节点 ”的概念。虚拟节点能够在某个节点断开连接时将它的负载重新分配给多个节点,从而减少因集群不稳定而造成的负载波动。
将每个物理worker节点映射成多个虚拟节点。这样虚拟节点便替代原先的物理节点,位于哈希环上。随后,每个分片将首先被分配到相邻(顺时针方向最邻近)的虚拟节点,再路由到虚拟节点映射的物理节点。下图的示例是一种可能出现的情况,即每个物理worker节点都对应3个虚拟节点。
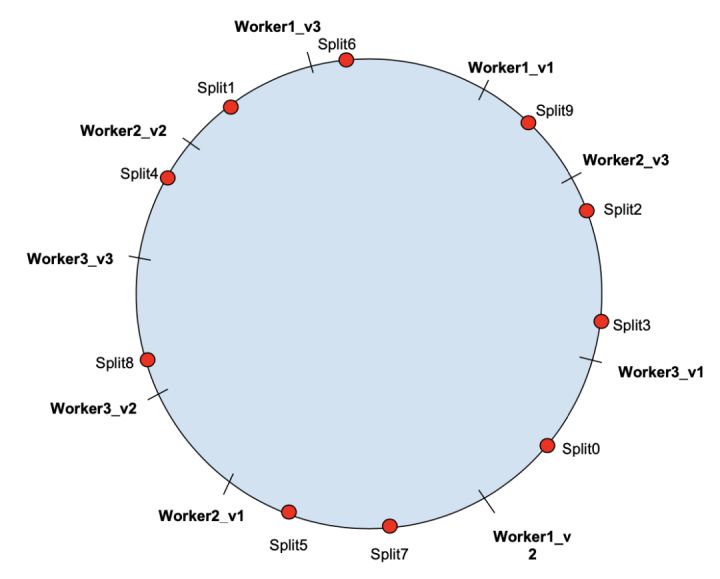
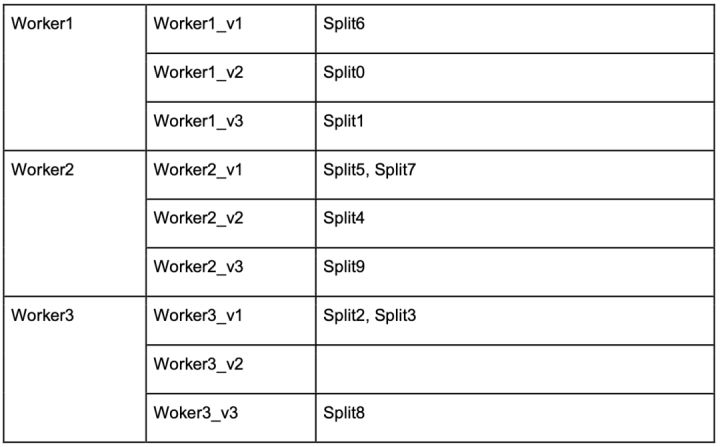
随着哈希环上节点数量的增加,哈希空间将被分割地更均匀。
在一个物理节点宕机的情况下,与该物理节点相对应的所有虚拟节点都将被重新散列。这里不是所有的分片都被重新分配到同一个节点上,而是会分配到多个虚拟节点,从而映射到多个物理节点上,以达到更好的负载均衡。
如下图所示,当删除worker3时,分片2和3将被重新散列到worker2,而分片8被重新散列到worker1。


如何在Presto中使用一致性哈希?
这是我们最近贡献给Presto的一个实验性功能。如果有意向进行测试或合作,请联系我们。
使用该功能前,请先根据指南(https://prestodb.io/docs/current/cache/alluxio.html)或教程(https://docs.alluxio.io/os/user/stable/en/compute/Presto.html)启用Presto的缓存。确保你选择SOFT_AFFINITY作为调度策略的配置项。在/catalog/hive.properties文件中,添加hive.node-selection-strategy=SOFT_AFFINITY。
需要通过在config.properties中添加node-scheduler.node-selection-hash-strategy=CONSISTENT_HASHING来启用一致性哈希。
结论
如上所述,当增加或删除节点时,一致性哈希可以使工作负载重新分配所产生的的影响降到最低。当集群的worker节点发生变化时,基于一致性哈希算法进行工作负载在worker节点间的分配,可以尽量降低对现有节点上缓存命中率的影响。因此,在Presto集群规模按照工作负载的需要扩缩容的场景下,或者部署环境中的硬件设备不完全受控而导致worker节点可能随时被重新分配和调整的场景下,一致性哈希策略都会成为一种更好的选择。
在Alluxio社区,我们一直在不断改进Alluxio和各类计算引擎(例如文中的Presto)在功能性和可用性方面的集成。随着在Presto调度中引入一致性哈希,Alluxio可以利用Presto的软亲和特性,实现更好的数据本地性和缓存效率,最终提高处理性能并降低成本。我们将持续致对整个数据生态圈进行贡献,不断改进和优化我们的产品。