import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
from sklearn import datasets
iris = datasets.load_iris() #载入鸢尾花 数据集,存入变量iris中(数据结构可理解为字典)
iris.keys()
#Number of Instances: 150 (50 in each of three classes)
#Number of Attributes: 4 numeric, predictive attributes and the class
#Attribute Information:
# - sepal length in cm
# - sepal width in cm
# - petal length in cm
# - petal width in cm
# Class Information:
# - Iris-Setosa
# - Iris-Versicolour
# - Iris-Virginica
iris.data #查看iris 中的数据
iris.data.shape
# (150,4)data 形状 ,即Number of Instances: 150 (50 in each of three classes),每个样本都有4个特征
iris.feature_names #查看数据集特征的名称
iris.target #查看数据集的标签(0,1,2)(因为该数据集中总共分三类鸢尾花),与样本一一对应,iris.target.shape 为(150,)
#将数据可视化(由于总共有四个特征,故我们先取出前两种特征,画二维图,大致的看一下数据)
X = iris.data[:,:2]
plt.scatter(X[:,0],X[:,1]) #两个特征之间没什么现行关系,故用散点图
plt.show()
#上图中不能很好的看出,哪个点属于哪一类鸢尾花,故设置,不同类别的鸢尾花显示不同的颜色
y = iris.target
plt.scatter(X[y==0,0],X[y==0,1],color = 'r',marker='o')
plt.scatter(X[y==1,0],X[y==1,1],color = 'b',marker='*')
plt.scatter(X[y==2,0],X[y==2,1],color = 'g',marker='+')
plt.show()
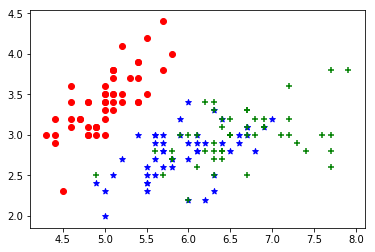
#这样图就清晰多了,但是第二类和第三类好像还混合在一起,别担心,我们还有后两个特征没有使用
Y = iris.data[:,2:]
plt.scatter(Y[y==0,0],Y[y==0,1],color = 'r',marker='o')
plt.scatter(Y[y==1,0],Y[y==1,1],color = 'b',marker='*')
plt.scatter(Y[y==2,0],Y[y==2,1],color = 'g',marker='+')
plt.show()
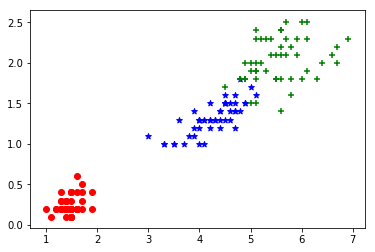
#这样,我们就可以大致的对数据有一个认识,后两个特征对数据的分类更重要。
import matplotlib as mpl
import matplotlib.pyplot as plt
from sklearn import datasets
iris = datasets.load_iris() #载入鸢尾花 数据集,存入变量iris中(数据结构可理解为字典)
iris.keys()
dict_keys(['data', 'target', 'target_names', 'DESCR', 'feature_names'])
iris.DESCR #可以查看一些数据的信息#Number of Instances: 150 (50 in each of three classes)
#Number of Attributes: 4 numeric, predictive attributes and the class
#Attribute Information:
# - sepal length in cm
# - sepal width in cm
# - petal length in cm
# - petal width in cm
# Class Information:
# - Iris-Setosa
# - Iris-Versicolour
# - Iris-Virginica
iris.data #查看iris 中的数据
iris.data.shape
# (150,4)data 形状 ,即Number of Instances: 150 (50 in each of three classes),每个样本都有4个特征
iris.feature_names #查看数据集特征的名称
iris.target #查看数据集的标签(0,1,2)(因为该数据集中总共分三类鸢尾花),与样本一一对应,iris.target.shape 为(150,)
iris.target_names #标签的名称或实际意思(鸢尾花的不同种类,'setosa', 'versicolor', 'virginica')
X = iris.data[:,:2]
plt.scatter(X[:,0],X[:,1]) #两个特征之间没什么现行关系,故用散点图
plt.show()
#上图中不能很好的看出,哪个点属于哪一类鸢尾花,故设置,不同类别的鸢尾花显示不同的颜色
y = iris.target
plt.scatter(X[y==0,0],X[y==0,1],color = 'r',marker='o')
plt.scatter(X[y==1,0],X[y==1,1],color = 'b',marker='*')
plt.scatter(X[y==2,0],X[y==2,1],color = 'g',marker='+')
plt.show()
#这样图就清晰多了,但是第二类和第三类好像还混合在一起,别担心,我们还有后两个特征没有使用
Y = iris.data[:,2:]
plt.scatter(Y[y==0,0],Y[y==0,1],color = 'r',marker='o')
plt.scatter(Y[y==1,0],Y[y==1,1],color = 'b',marker='*')
plt.scatter(Y[y==2,0],Y[y==2,1],color = 'g',marker='+')
plt.show()
#这样,我们就可以大致的对数据有一个认识,后两个特征对数据的分类更重要。