背景介绍
本人有幸在游戏公司和传统的生物制药行业呆过,游戏公司涉及到用户身份的唯一认证的问题,而传统的生物制药公司涉及到多个系统,因为系统过多,希望使用一个统一的用户管理中心,为此本人设计一套sso系统平台结构,不涉及公司机密,因为该架构在我所接触的公司中并未实际使用,如果设计有缺陷,欢迎指正。
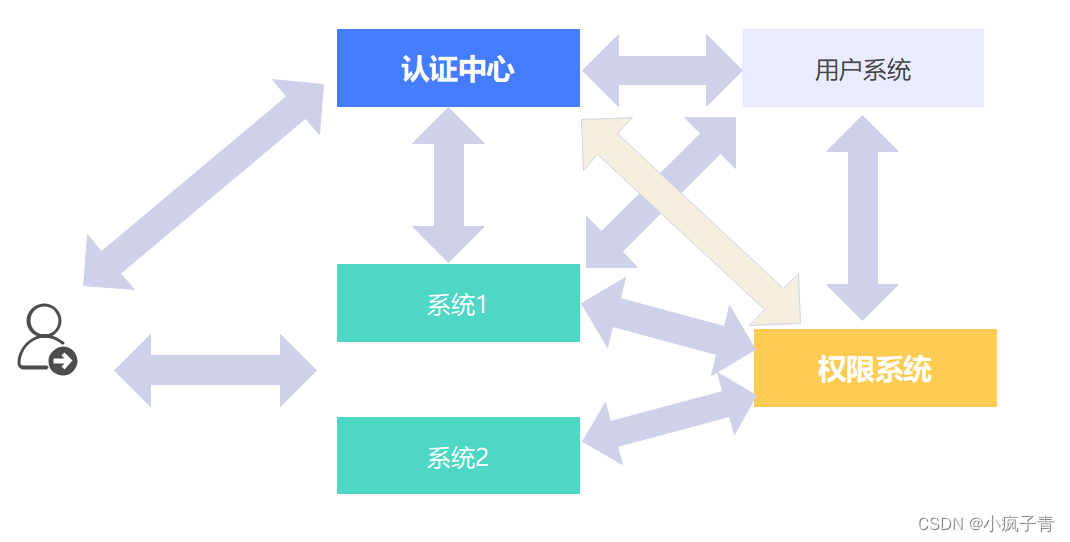
以下为架构逻辑图。
时序图如下:

逻辑和时序说明
1.当用户请求访问页面A的时候,实际上默认页面首先会往系统A后台发送登录的请求,登录请求接口会获取浏览器缓存:到认证中心票据和A系统对用户生成的token,显然第一次登录这两数据都是不存在的,则会触发页面跳转功能,跳转至认证中心的默认登录页面;
2.这时候用户输入登录的账号和密码传到认证中心,认账中心再将数据加密发送给用户系统,用户系统解密出数据,再使用自己的加密策略和数据库里用户的加密数据进行,比对通过则返回加密的通过结果;
3.这时候认证中心对接受到的信息进行解密验证,再将生成的票据信息传送为系统A,系统A解析接口收到的数据,将票据和自生成的token一并发送到A系统的页面上;
4.A系统页面触发往后台的请求接口,后台发送请求至权限中心进行权限,权限中心返回系统权限列表,后台进行接口权限验证,返回给前端对应的数据;
5.当用户试图访问系统B,系统B会尝试从缓存中获取到票据和系统B的token,当前缓存中没有系统B的token,则系统B会直接带着票据进行加密请求认证中心,认证中心验证票据的合法性,如果合法则加密返回响应给系统B,系统B跳转至信息页面并将系统B的token信息缓存到本地。
安全性的分析
1.接口调用双方都要防止伪造的问题
拿认证中心和系统A进行说明,如果仅使用系统A通过票据到认证中心认证是否合法性,那么“伪造DNS响应”则可以绕开认证中心,从而获得系统A的token,因此双方接口请求和响应均需要进行加密认证;
系统性能分析
1.权限系统可以使用redis缓存放置权限相关的信息,可以使用多系统共用同一层级redis的方式来分压;
2.用户系统对于单个用户的查询也可以使用redis缓存来缓存用户数据,但是对于复杂的用户筛选查询可能需要提供合理的设计,用户系统可能会面对较大的访问压力;
系统内置相关的表:
1.用户系统存放两类用户表,一类为单纯的用户表,同一个用户在平台里只有一个验证,身份统一,另一类为后台用户表,该表里的用户实际上是从用用户表派生过来,是针对不同的管理后台设定的,表中有用户id、系统id,还有一个系统密钥配置表usesys_sys_key,存放不同系统和用户系统之间进行通讯的加密密钥,config_center表、config_control;
2.认证中心:该系统主要是作为sso统一认证的关键节点,节点表仅有系统密钥配置表center_sys_key、config_control和config_user表;
3.权限系统:存放权限相关的表,config_user表,config_center表,control_sys_key;
4.系统A:业务表以及密钥相关的配置表config_user表,config_center表、config_control;
劣势分析:
该设计涉及到三个中心端,交互逻辑偏复杂,后续会寻找更好的设计方案。
过渡期建议
因为本人所在的好几个公司都为系统相对不完善的小公司,开发人员比较少,一下子分太多系统反而不利于业务的扩展,首先系统之间的接口交互需要花费时间,其次部署多应用也会耗费更多的系统资源以及增加运维成本,其实很多公司前期单体应用完全可以解决问题,但是本人对系统分包有一些建议,这些建议的目的也是为了让系统能够往架构上发展,实现设计的复用。
1.首先maven的分module功能推荐一定要使用,而且在创建单体架构的时候一定要好好考虑分module,本人给的建议包括:
(1)为当前系统创建一个大的module,在module里面再创建当前项目pojo的module,当前项目mapper的module,service和controlle可以放在一个module(里面也可以放置跟缓存相关的mapper),为什么建议这么划分,因为一个系统其实是可能涉及到多个端的,例如一般的用户端,也有可能会涉及到管理后端,这时候就可以将pojo和mapper引入到管理后端的module里了,可以直接以jar的方式打包使用,同时我们知道项目是可以进行多数据源连接的,引入mappr只要做数据源的配置就可以直接调用了,即需要使用的系统做相应的配置就可以直接使用的。那么为什么要将缓存相关的mapper、service和controller放置在一起,就我目前实践的经验看,service和controller都是配套一起使用的,service复用的情况有点少,而且模块划分太细对前期代码的调试也算是一个能耗。
(2)提取公共的common包,这里只放置会用到的公共部分;
(3)对于表的设计一定要基于领域进行设计,即在设计之前一定要好好的调查当前市场情况,之后再结合公司目前的发展情况设计表,领域设计的太大会增大代码工作量,尽量选择一种工作量少、易于扩展又适应目前场景的表格设计;
(4)对于技术选型不建议一下子就各种技术的使用,是需要考虑目前企业的状态、开发人员的水平以及是否容易部署和维护,如果一下子选择小众的技术那么开发人员需要花费学习成本,公司也会面临着试错,同时也会增加招人的成本,如果确实是技术前言技术,也建议好好考虑;
(5)接下来还要考虑系统以后的架构发展方向,因此对于表的设计是要考虑是否进行分库设计,我的建议是将用户表、权限关系表、业务表以及日志表分开创建,可能有人会担心事务不一致的问题,实际上这几类表之间的业务关联并不强,可以尝试在确实涉及到业务问题的地方添加代码进行处理,这样设计的好处是当用户访问量变大的时候,可以将表放到不同的服务器上来提高性能;
对于表的系统之间的唯一标识建议使用雪花算法生成;