随机梯度下降在机器学习应用中被广泛使用。与反向传播相结合,它在神经网络训练应用中占主导地位。
在本文中,我们将一起学习:
梯度下降和随机梯度下降算法如何工作
如何应用梯度下降和随机梯度下降来最小化机器学习中的损失函数
什么是学习率,为什么它很重要,以及它如何影响结果
如何编写自己的随机梯度下降的函数
基本梯度下降算法
梯度下降算法是一种数学优化的近似和迭代方法。我们可以用它来逼近任何可微分函数的最小值。
虽然梯度下降有时会卡在局部最小值或鞍点,而不是找到全局最小值,但它被广泛应用于实践中。通常在数据科学和机器学习方法内部应用梯度下降来优化模型参数。例如,神经网络用梯度下降法寻找权重和偏差。
损失函数:优化的目标
损失函数,或成本函数,是指通过改变决策变量来实现最小化(或最大化)的函数。 通常被许多机器学习方法在其内部用于解决优化问题。它们一般通过调整模型参数(如神经网络的权重和偏差,随机森林或梯度提升的决策规则,等等),使实际输出和预测输出之间的差异最小。
在回归问题中,通常有输入变量的向量 和实际输出 。我们想找到一个模型,将 映射到预测响应 ,使 尽可能地接近于 。例如,我们可能想预测一个输出,如一个人的工资,给定的输入是这个人在公司的年数或教育水平。
在一个分类问题中,输出 是分类的,通常是0或1。例如,我们试图预测一封电子邮件是否是垃圾邮件。在二进制输出的情况下,最小化交叉熵函数是很方便的,它也取决于实际输出 和相应的预测 。
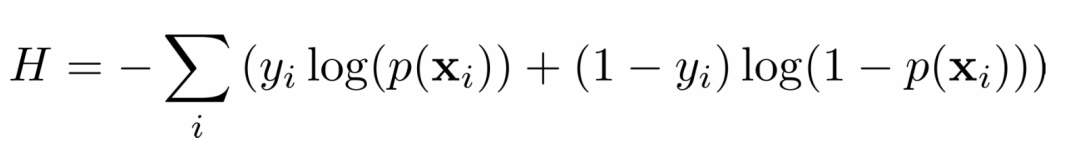
在经常用于解决分类问题的逻辑回归中,函数 和 定义如下。
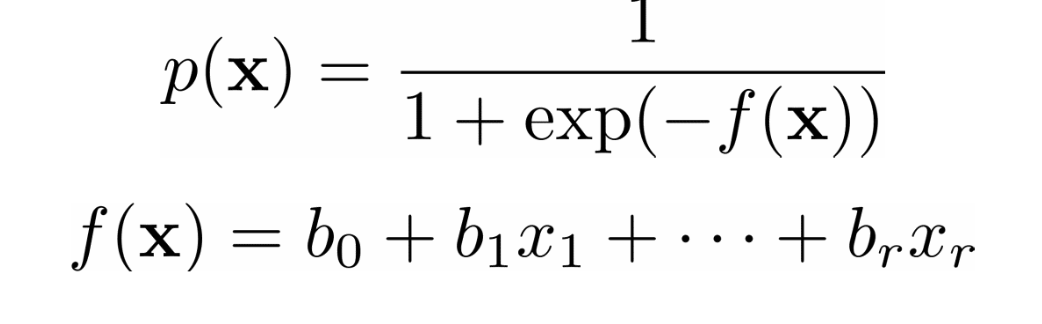
同样,我们需要找到权重 ,但这次它们应该使交叉熵函数最小。
函数的梯度:微积分
在微积分中,一个函数的导数表示在修改其参数(或参数)时,一个值的变化程度。导数对优化很重要,尤其零导数可能表示一个最小、最大或鞍点。
几个独立变量的函数 的梯度 用 来表示,定义为 相对于每个独立变量的偏导数的向量函数: ,符号 被称为nabla
一个函数 在某一点上的非零值,定义了 的最快增长方向和速度。当使用梯度下降时,我们对成本函数的最快下降方向感兴趣。这个方向是由负梯度,即 决定的。
梯度下降背后的思想
为了理解梯度下降算法,想象一滴水从碗边滑下,或者一个球从山上滚下。水滴和球倾向于沿着最快的下降方向移动,直到它们到达底部。随着时间的推移,它们会因收到引力获得加速度而加速下落。
梯度下降的思想是类似的:从一个任意选择的点或向量 的位置开始,并向成本函数下降最快的方向反复移动。如前所述,这是负梯度向量的方向,即 。
一旦我们有了一个随机的起点 ,就更新它,或者把它移到负梯度方向的新位置:,其中 (发音为 "ee-tah")是一个小正数值,称为学习率。
学习率决定了更新或移动的步骤有多大。这是一个非常重要的参数。如果 太小,那么算法可能收敛得很慢。大的 值也会导致收敛问题或使算法发散。
基本梯度下降的实现
现在我们知道了基本的梯度下降是如何工作的,我们可以用Python实现它。我们将只使用数据科学计算包 NumPy 来实现,该方法能够帮助我们在仅使用几行代码就能处理数组(或向量),且性能也非常棒。
这是一个梯度下降算法的基本实现:它从一个任意的点开始,向最小值迭代移动,并返回一个有望达到或接近最小值的点。
def gradient_descent(gradient, start, learn_rate, n_iter):
vector = start
for _ in range(n_iter):
diff = -learn_rate * gradient(vector)
vector += diff
return vectorgradient_descent()需要四个参数。
gradient 是一个函数或任何 Python 可调用对象,它接收一个向量并返回最小化目标的函数的梯度。
start 是算法开始搜索的点,以序列(元组、列表、NumPy数组等)或标量(在一维问题中)的形式给出。
learn_rate 是控制向量更新幅度的学习率。
n_iter 是迭代的次数。
这个函数所做的正是上面所描述的:它需要一个起点(第2行),根据学习率和梯度值迭代更新(第3至5行),最后返回最后发现的位置。
在我们应用gradient_descent()之前,我们可以添加另一个终止标准。
import numpy as np
def gradient_descent(
gradient, start, learn_rate, n_iter=50, tolerance=1e-06
):
vector = start
for _ in range(n_iter):
diff = -learn_rate * gradient(vector)
if np.all(np.abs(diff) <= tolerance):
break
vector += diff
return vector我们现在有了额外的参数tolerance(第4行),它指定了每个迭代中允许的最小移动量。我们还定义了 tolerance 和 n_iter 的默认值,所以我们不必在每次调用gradient_descent()时指定它们。
第9行和第10行使gradient_descent()在达到n_iter之前停止迭代并返回结果;如果当前迭代中的向量更新小于或等于容忍度也同样停止迭代并返回结果,这经常发生在最小值附近,那里的梯度通常非常小。有时它也可能发生在局部最小值或鞍点附近,此时就容易陷入局部最小值。
第9行使用方便的NumPy函数numpy.all()[1]和numpy.abs()[2],在一条语句中比较diff和tolerance的绝对值。
现在有了gradient_descent()的第一个版本,下面测试该函数:从一个小例子开始,找到函数 ² 的最小值。
这个函数只有一个自变量(),其梯度是导数 。它是一个可微调的凸函数[3],用分析方法找到它的最小值是很直接的。然而在实践中,很难分析函数的微分,甚至是不可能的,一般使用数值方法[4]来近似。
只需要一条语句来测试梯度下降。
>>> gradient_descent(
... gradient=lambda v: 2 * v, start=10.0, learn_rate=0.2
... )
2.210739197207331e-06使用 lambda 函数 lambda v: 2 * v来提供 ² 的梯度。设置初始值为10.0,学习率设为0.2。得到的结果非常接近于零,可以认为这就是正确的最小值。
下图显示了解决方案在迭代中的运动轨迹。
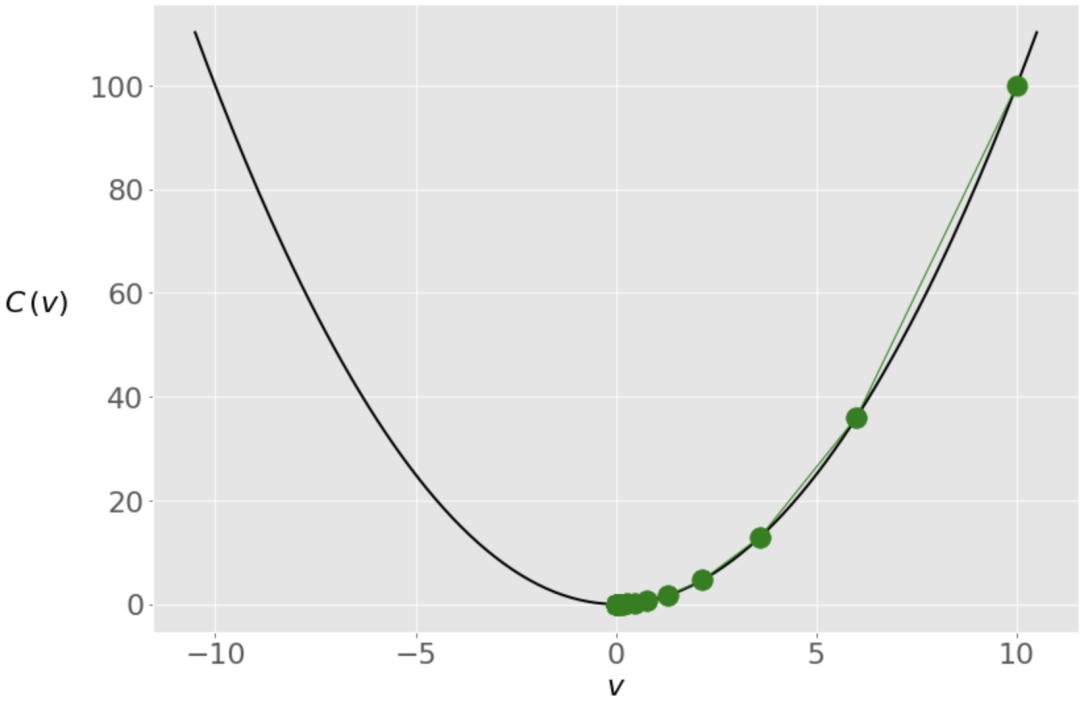
我们从最右边的绿点()开始,向最小值()移动。开始时,梯度(和斜率)的值较高,更新量较大。当接近最小值时,梯度变得更低,接近于0。
学习率的影响
学习率是算法的一个非常重要的参数。不同的学习率值会显著影响梯度下降的行为。继续沿用前面的例子,设置学习率不是0.2,而是0.8。
>>> gradient_descent(
... gradient=lambda v: 2 * v, start=10.0, learn_rate=0.2
... )
2.210739197207331e-06结果会得到另一个非常接近零的值,但在算法的内部行为表现是不同的。如下图所示,是 的值在迭代中发生的情况。
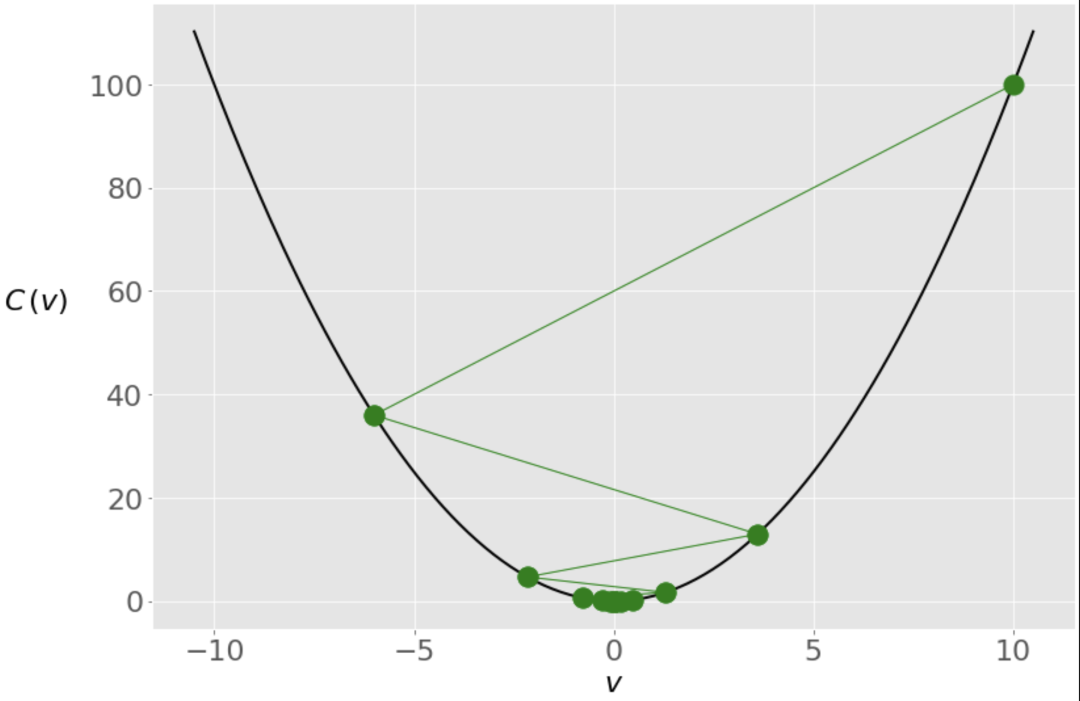
在这种情况下,同样初始值设置为 ,但由于学习率很高,我们得到的 的变化很大,传递到最佳状态的另一边,变成了-6。它在接近零点之前又过了几次。
小的学习率会导致非常缓慢的收敛。如果迭代次数有限,那么算法可能会在找到最小值之前返回。否则,整个过程可能需要大量的时间。为了说明这一点,我们设置一个小得多的学习率0.005,再次运行gradient_descent()。
>>> gradient_descent(
... gradient=lambda v: 2 * v, start=10.0, learn_rate=0.005
... )
6.050060671375367现在的结果是6.05,远远没有达到真正的最小值0。由于小的学习率,向量的变化非常小。
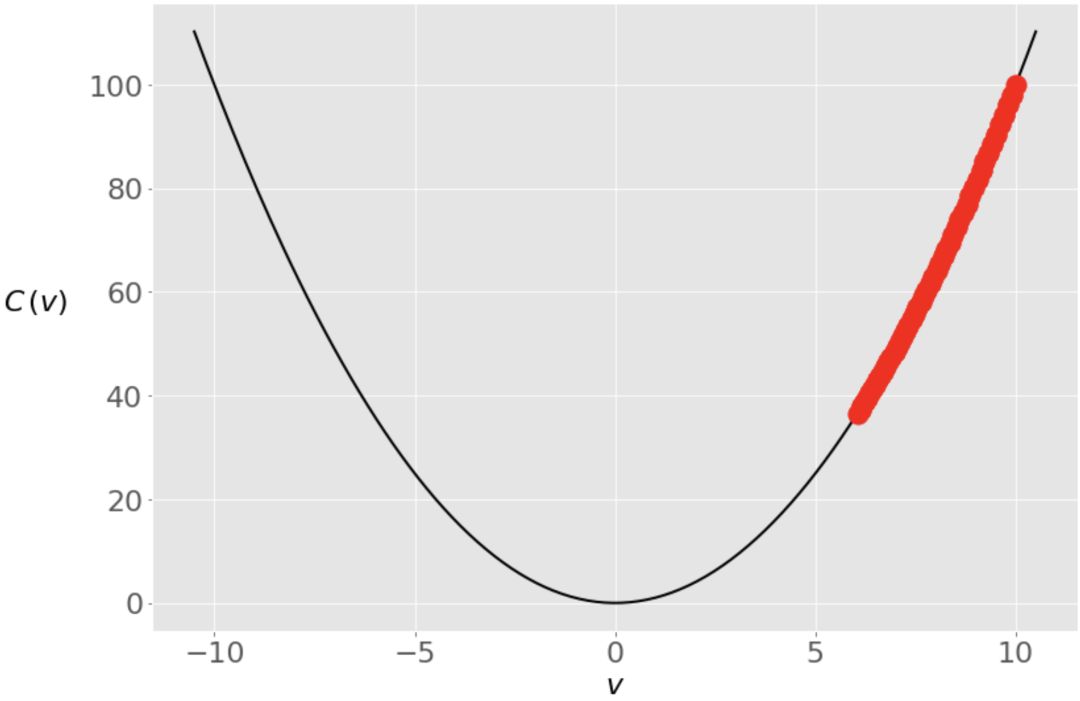
搜索过程和以前一样从 开始,但在五十次迭代中不可能达到零。然而,一百次迭代后,误差会小得多,一千次迭代后就会非常接近于零。
>>> gradient_descent(
... gradient=lambda v: 2 * v, start=10.0, learn_rate=0.005,
... n_iter=100
... )
3.660323412732294
>>> gradient_descent(
... gradient=lambda v: 2 * v, start=10.0, learn_rate=0.005,
... n_iter=1000
... )
0.0004317124741065828
>>> gradient_descent(
... gradient=lambda v: 2 * v, start=10.0, learn_rate=0.005,
... n_iter=2000
... )
9.952518849647663e-05非凸函数可能存在局部最小值或鞍点,算法可能会陷入局部最小值而被困住。这种情况下,我们对学习率或起点的选择可以使我们找到局部最小值和找到全局最小值之间的区别。
考虑函数 。它的全局最小点在 ,局部最小点在 。这个函数的梯度是 。让我们看看gradient_descent()在这里如何工作。
>>> gradient_descent(
... gradient=lambda v: 4 * v**3 - 10 * v - 3, start=0,
... learn_rate=0.2
... )
-1.4207567437458342这次我们从零开始,算法在局部最小值附近结束。下面是在引擎盖下发生的事情。
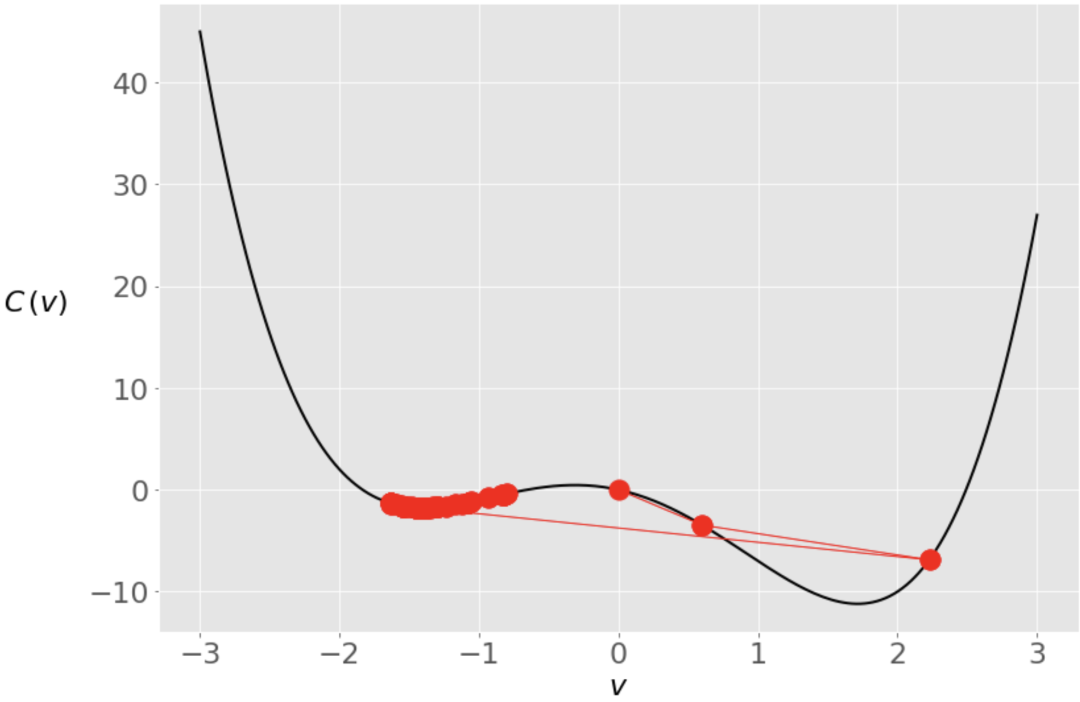
在前两次迭代中,我们的向量是向全局最小值移动的,但后来它越过了对面,一直被困在局部最小值中。我们可以用一个较小的学习率来防止这种情况。
>>> gradient_descent(
... gradient=lambda v: 4 * v**3 - 10 * v - 3, start=0,
... learn_rate=0.1
... )
1.285401330315467当我们把学习率从0.2降到0.1时,得到一个非常接近全局最小值的解决方案。这一次,避免了跳到另一边的情况。其实,梯度下降是一种近似的方法。
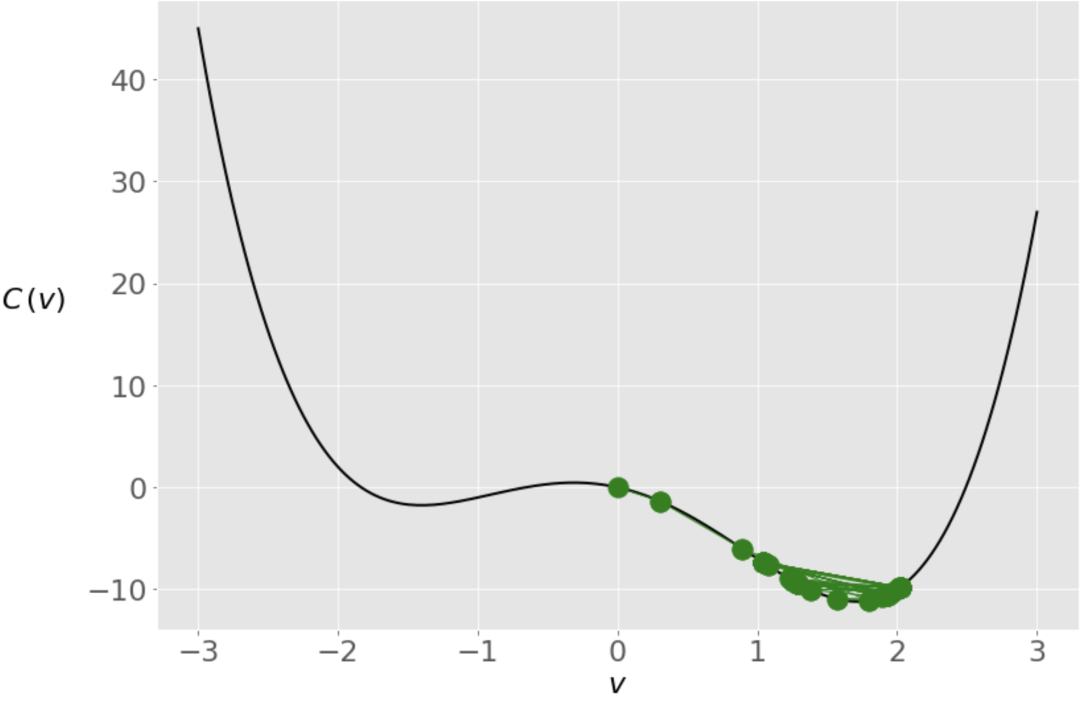
较低的学习率可以防止向量出现大的跳跃,在这种情况下,向量仍然比较接近全局最优。
调整学习率是很棘手的,我们不可能事先知道最佳值。有许多技术和启发式方法试图帮助解决这个问题。机器学习工程师们经常在模型选择和评估期间调整学习率。
除了学习率,初始值通常也会对解决方案产生很大影响,特别是对于非凸函数。
梯度下降算法的应用
在本节中,一起学习两个使用梯度下降的例子。我们还会了解到它可以用于现实生活中的机器学习问题,如线性回归。在第二个例子中,我们需要修改 gradient_descent() 的代码,因为我们需要观察到的数据来计算梯度。
例一
首先,我们要将 gradient_descent() 应用于另一个一维问题。以函数 为例。这个函数的梯度是 。根据这些信息,我们可以找到它的最小值。
>>> gradient_descent(
... gradient=lambda v: 1 - 1 / v, start=2.5, learn_rate=0.5
... )
1.0000011077232125通过传入合适的参数集,gradient_descent() 正确地计算出该函数的最小值为 。我们可以用其他的学习率和起点的值来尝试。
我们也可以对多个变量的函数使用 gradient_descent()。应用是一样的,但是我们需要提供梯度和起始点作为向量或数组。例如,我们可以找到具有梯度向量() 的函数 的最小值。
>>> gradient_descent(
... gradient=lambda v: np.array([2 * v[0], 4 * v[1]**3]),
... start=np.array([1.0, 1.0]), learn_rate=0.2, tolerance=1e-08
... )
array([8.08281277e-12, 9.75207120e-02])在这种情况下,我们的梯度函数的起始值是一个数组,也返回一个数组结果。该结果值几乎等于零,所以我们可以说gradient_descent()正确地发现这个函数的最小值是在 。
普通最小二乘法
相信大家都学习过线性回归和普通最小二乘法[5],从输入 ₁,,ᵣ 到输出 ,定义了一个线性函数 ₀₁ᵣᵣ,使它尽可能地接近于 。
这其实就是一个优化问题,要找到权重值 ₀₁ᵣ,使残差平方值之和 或平均平方误差 最小。这里 是观测值的总数,
其实我们也可以使用成本函数 ,这在数学上比SSR或MSE更方便。
线性回归的最基本形式是简单线性回归。它只有一组输入 和两个权重 ₀ 和 ₁,回归线的方程是 ₀₁。尽管 ₀ 和 ₁ 的最佳值可以用分析法计算[6],但我们这里使用梯度下降法来确定结果。
首先,需要通过微积分来找到成本函数的梯度 ᵢᵢ₀₁ᵢ²。由于有两个决策变量 ₀ 和 ₁,所以梯度 是一个有两个分量的向量。
1.₀ᵢ₀₁ᵢᵢ₀₁ᵢᵢ
2. ₁ᵢ₀ᵢᵢᵢ₀ᵢᵢᵢ
我们需要 和 的值来计算这个成本函数的梯度,梯度函数不仅有 ₀ 和 ₁,还有 和 作为输入。
def ssr_gradient(x, y, b):
res = b[0] + b[1] * x - y
return res.mean(), (res * x).mean()
# .mean() is a method of np.ndarrayssr_gradient() 接收包含观测输入和输出的数组 和 ,以及保存决策变量 ₀ 和 ₁ 当前值的数组 。该函数首先计算每个观察值的残差数组(res),然后返回 ₀ 和 ₁ 的一对值。
这里使用NumPy方法ndarray.mean()对传递的NumPy数组参数求均值。
gradient_descent()需要两个小调整:
1. 在第4行添加 和 作为gradient_descent()的参数。
2. 向梯度函数提供 和 ,并确保我们在第8行将梯度元组转换为NumPy数组。
以下是gradient_descent()在这些变化后的样子。
import numpy as np
def gradient_descent(
gradient, x, y, start, learn_rate=0.1, n_iter=50, tolerance=1e-06
):
vector = start
for _ in range(n_iter):
diff = -learn_rate * np.array(gradient(x, y, vector))
if np.all(np.abs(diff) <= tolerance):
break
vector += diff
return vectorgradient_descent()现在接受输入 和输出 ,并计算梯度。将gradient(x, y, vector)的输出转换为NumPy数组使梯度元素与学习率相乘,这对于单变量函数可以参略。
现在得到新的 gradient_descent() 来寻找一些任意的x和y的值的回归线。
>>> x = np.array([5, 15, 25, 35, 45, 55])
>>> y = np.array([5, 20, 14, 32, 22, 38])
>>> gradient_descent(
... ssr_gradient, x, y, start=[0.5, 0.5], learn_rate=0.0008,
... n_iter=100_000
... )
array([5.62822349, 0.54012867])结果是一个有两个数值的数组,对应于决策变量: 和 。最佳回归线是 。和前面的例子一样,这个结果在很大程度上取决于学习率。如果学习率太低或太高,可能不会得到这么好的结果。
虽然这个例子并不完全是随机的,但我们得到的结果与scikit-learn的线性回归器几乎一样。我们可视化该回归线的数据和回归结果。
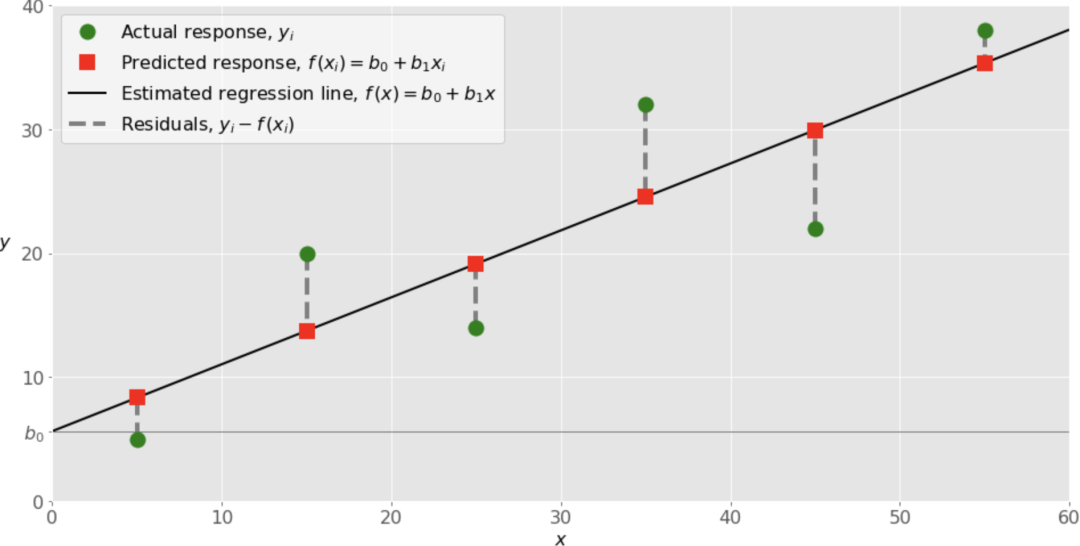
代码改进
我们可以在不修改其核心功能的情况下,使 gradient_descent() 更强大、更全面、更美观。
import numpy as np
def gradient_descent(
gradient, x, y, start, learn_rate=0.1, n_iter=50, tolerance=1e-06,
dtype="float64"
):
# 检查梯度是否可调用
if not callable(gradient):
raise TypeError("'gradient' must be callable")
# 设置NumPy数组的数据类型
dtype_ = np.dtype(dtype)
# 将x和y转换为NumPy数组
x, y = np.array(x, dtype=dtype_), np.array(y, dtype=dtype_)
if x.shape[0] != y.shape[0]:
raise ValueError("'x' and 'y' lengths do not match")
# 设置变量初始值
vector = np.array(start, dtype=dtype_)
# 设置并检查学习率
learn_rate = np.array(learn_rate, dtype=dtype_)
if np.any(learn_rate <= 0):
raise ValueError("'learn_rate' must be greater than zero")
# 设置并检查最大的迭代次数
n_iter = int(n_iter)
if n_iter <= 0:
raise ValueError("'n_iter' must be greater than zero")
# 设置并检查公差
tolerance = np.array(tolerance, dtype=dtype_)
if np.any(tolerance <= 0):
raise ValueError("'tolerance' must be greater than zero")
# 执行梯度下降循环
for _ in range(n_iter):
# 重新计算差异
diff = -learn_rate * np.array(gradient(x, y, vector), dtype_)
# 检查绝对差异是否足够小
if np.all(np.abs(diff) <= tolerance):
break
# 更新变量的值
vector += diff
return vector if vector.shape else vector.item()gradient_descent() 现在接受一个额外的dtype参数,用来定义函数内部NumPy数组的数据类型。
在大多数应用中,我们不会注意到32位和64位浮点数之间的区别,但当我们处理大数据集时,这可能会大大影响内存的使用,甚至可能影响处理速度。例如,尽管NumPy默认使用64位浮点数,但TensorFlow经常使用32位浮点数。
除了考虑数据类型外,上面的代码还引入了一些与类型检查和确保使用NumPy能力有关的修改。
首先检查gradient是否是一个Python可调用的对象,以及它是否可以作为一个函数使用。如果不是,那么这个函数将引发一个TypeError。
设置numpy.dtype[7]的一个实例,用作整个函数中所有数组的数据类型。
接收参数 和 并产生具有所需数据类型的NumPy数组。参数x和y可以是列表、元组、数组或其他序列。
然后比较 和 的大小,以此确定两个数组有相同数量的观察值。如果它们不一样,那么该函数将引发一个ValueError。
将参数
start转换为NumPy数组。这是一个有趣的技巧:如果start是一个Python标量,那么它将被转换为一个相应的NumPy对象。如果传递一个序列,那么它将变成一个具有相同元素数的普通NumPy数组。对学习率做同样的事情。这使我们能够通过向
gradient_descent()传递一个列表、元组或NumPy数组,为每个决策变量指定不同的学习率。检查学习率值(或所有变量的值)是否大于零。
同样设置
n_iter和tolerance并检查它们是否大于0。从for 循环开始,与之前的内容几乎相同。唯一的区别是计算差异时的梯度数组的类型。
如果我们有几个决策变量,最后会方便地返回结果数组;如果我们有一个单一的变量,则返回一个Python标量。
此时,我们的 gradient_descent() 现在已经完成了。接下来我们学习随机梯度下降算法的具体实现方法。
随机梯度下降算法
随机梯度下降算法是对梯度下降的一种修改。在随机梯度下降中,我们只用随机的一小部分观测值而不是所有的观测值来计算梯度。在某些情况下,这种方法可以减少计算时间。
Online随机梯度下降是随机梯度下降的一个变种,它对每个观察的成本函数的梯度进行估计,并相应地更新决策变量。这有助于找到全局最小值,特别是当目标函数是凸的时候。
Batch随机梯度下降法介于普通梯度下降法和Online方法之间。梯度的计算和决策变量的更新是通过所有观测数据的子集进行的,称为**minibatches** 小批量。这种变体在训练神经网络方面非常流行。
我们可以把Online算法想象成一种特殊的批处理算法,其中每个 minibatch 只有一个观测值。经典梯度下降是另一种特殊情况,其中只有一个批次包含所有观测值。
随机梯度下降中的最小batch
与普通梯度下降法一样,随机梯度下降法从决策变量的初始向量开始,通过几次迭代进行更新。两者的区别在于迭代过程中发生了什么。
随机梯度下降法将观测数据集随机划分为
minibatches。对于每一个
minibatch,计算梯度,移动向量。一旦用完所有的
minibatch,我们就说这个迭代(epoch),已经结束,并开始下一个迭代。
这个算法会随机选择 minibatch 的观察值,我们可以用随机数生成器来模拟这种随机(或伪随机)行为。Python有内置的ramdom模块,而NumPy有自己的随机生成器。当使用数组时,后者更方便。
创建一个名为sgd()的新函数,它与gradient_descent()非常相似,但使用随机选择的 minibatches 来沿着搜索空间移动。
上下滑动查看更多源码import numpy as np
def sgd(
gradient, x, y, start, learn_rate=0.1, batch_size=1, n_iter=50,
tolerance=1e-06, dtype="float64", random_state=None
):
# 检查梯度是否可调用
if not callable(gradient):
raise TypeError("'gradient' must be callable")
# 设置NumPy数组的数据类型
dtype_ = np.dtype(dtype)
# 将x和y转换为NumPy数组
x, y = np.array(x, dtype=dtype_), np.array(y, dtype=dtype_)
n_obs = x.shape[0]
if n_obs != y.shape[0]:
raise ValueError("'x' and 'y' lengths do not match")
xy = np.c_[x.reshape(n_obs, -1), y.reshape(n_obs, 1)]
# 初始化随机数发生器
seed = None if random_state is None else int(random_state)
rng = np.random.default_rng(seed=seed)
# 初始化变量的值
vector = np.array(start, dtype=dtype_)
# 设置并检查学习率
learn_rate = np.array(learn_rate, dtype=dtype_)
if np.any(learn_rate <= 0):
raise ValueError("'learn_rate' must be greater than zero")
# 设置并检查迷我们批的大小
batch_size = int(batch_size)
if not 0 < batch_size <= n_obs:
raise ValueError(
"'batch_size' must be greater than zero and less than "
"or equal to the number of observations"
)
# 设置并检查最大的迭代次数
n_iter = int(n_iter)
if n_iter <= 0:
raise ValueError("'n_iter' must be greater than zero")
# 设置并检查公差
tolerance = np.array(tolerance, dtype=dtype_)
if np.any(tolerance <= 0):
raise ValueError("'tolerance' must be greater than zero")
# 执行梯度下降循环
for _ in range(n_iter):
# 打乱 x 和 y
rng.shuffle(xy)
# 执行小批量移动
for start in range(0, n_obs, batch_size):
stop = start + batch_size
x_batch, y_batch = xy[start:stop, :-1], xy[start:stop, -1:]
# 重新计算差异
grad = np.array(gradient(x_batch, y_batch, vector), dtype_)
diff = -learn_rate * grad
# 检查绝对差异是否足够小
if np.all(np.abs(diff) <= tolerance):
break
# 更新变量的值
vector += diff
return vector if vector.shape else vector.item()我们在这里有一个新的参数 batch_size,可以指定每个minibatch中的观察值的数量。这是随机梯度下降法的一个重要参数,可以显著影响性能,并确保batch_size 是一个正整数,且不大于观察值的总数。
另一个新参数是 random_state。它定义了随机数发生器的种子。该种子在后面被用作 default_rng() 的参数,它创建了一个Generator的实例。
如果为 random_state 传递参数 None,那么随机数生成器每次实例化时都会返回不同的数字。如果我们想让生成器的每个实例表现得完全一样,那么需要指定随机数种子——最简单的方法是提供一个任意的整数。
用x.shape[0]推断出观察值的数量。如果 是一个一维数组,那么这就是它的大小。如果 有两个维度,那么.shape[0]是行的数量。
使用.reshape()来确保 和 都成为具有n_obs行的二维数组,并且 正好有一列。numpy.c_[]方便地将 和 的列连接成一个数组 。这是使数据适合随机选择的一种方法。
最后,实现了随机梯度下降的for循环,它与gradient_descent()不同。我们使用随机数生成器和它的方法.shuffle()来清洗观察值。这是随机选择minibatches的方法之一。
内层for循环对每个minibatch都是重复执行的。与普通梯度下降法的主要区别,是梯度针对minibatch的观测值(x_batch和y_batch)而不是针对所有观测值( 和 )计算的。
x_batch成为xy的一部分,包含了当前minibatch的行(从开始到结束)和对应于 的列。
现在我测试随机梯度下降的实现。
>>> sgd(
... ssr_gradient, x, y, start=[0.5, 0.5], learn_rate=0.0008,
... batch_size=3, n_iter=100_000, random_state=0
... )
array([5.63093736, 0.53982921])其结果与用gradient_descent()得到的几乎一样。如果省略 random_state 或者使用 None,那么我们每次运行sgd()都会得到一些不同的结果,因为随机数生成器会对xy进行不同的打乱。
随机梯度下降法中的动量
我们知道,学习率会对梯度下降的结果产生重大影响。我们可以使用几种不同的策略来适应算法执行过程中的学习率,也可以在算法中应用动量(Momentum)。
可以使用动量来纠正学习率的影响,这个想法是记住矢量的前一次更新,并在计算下一次更新时应用它。不会完全沿着负梯度的方向移动向量,但也倾向于保持之前移动的方向和幅度。
被称为衰变率或衰变因子的参数定义了先前更新的贡献有多大。为了包括动量和衰减率,我们可以修改sgd(),增加参数decay_rate,用它来计算矢量更新的方向和幅度(diff)。
上下滑动查看更多源码import numpy as np
def sgd(
gradient, x, y, start, learn_rate=0.1,
decay_rate=0.0, batch_size=1, n_iter=50,
tolerance=1e-06, dtype="float64", random_state=None
):
# 检查梯度是否可调用
if not callable(gradient):
raise TypeError("'gradient' must be callable")
# 设置NumPy数组的数据类型
dtype_ = np.dtype(dtype)
# 将x和y转换为NumPy数组
x, y = np.array(x, dtype=dtype_), np.array(y, dtype=dtype_)
n_obs = x.shape[0]
if n_obs != y.shape[0]:
raise ValueError("'x' and 'y' lengths do not match")
xy = np.c_[x.reshape(n_obs, -1), y.reshape(n_obs, 1)]
# 初始化随机数发生器
seed = None if random_state is None else int(random_state)
rng = np.random.default_rng(seed=seed)
# 初始化变量的值
vector = np.array(start, dtype=dtype_)
# 设置并检查学习率
learn_rate = np.array(learn_rate, dtype=dtype_)
if np.any(learn_rate <= 0):
raise ValueError("'learn_rate' must be greater than zero")
# update
# 设置和检查衰减率
decay_rate = np.array(decay_rate, dtype=dtype_)
if np.any(decay_rate < 0) or np.any(decay_rate > 1):
raise ValueError("'decay_rate' must be between zero and one")
# 设置并检查迷我们批的大小
batch_size = int(batch_size)
if not 0 < batch_size <= n_obs:
raise ValueError(
"'batch_size' must be greater than zero and less than "
"or equal to the number of observations"
)
# 设置并检查最大的迭代次数
n_iter = int(n_iter)
if n_iter <= 0:
raise ValueError("'n_iter' must be greater than zero")
# 设置并检查公差
tolerance = np.array(tolerance, dtype=dtype_)
if np.any(tolerance <= 0):
raise ValueError("'tolerance' must be greater than zero")
# 将第一次迭代的差值设置为零
diff = 0
# 执行梯度下降循环
for _ in range(n_iter):
# 打乱 x 和 y
rng.shuffle(xy)
# 执行小批量移动
for start in range(0, n_obs, batch_size):
stop = start + batch_size
x_batch, y_batch = xy[start:stop, :-1], xy[start:stop, -1:]
# 重新计算差异
grad = np.array(gradient(x_batch, y_batch, vector), dtype_)
# diff = -learn_rate * grad
diff = decay_rate * diff - learn_rate * grad
# 检查绝对差异是否足够小
if np.all(np.abs(diff) <= tolerance):
break
# 更新变量的值
vector += diff
return vector if vector.shape else vector.item()这里,在参数行添加了decay_rate参数,在第34行将其转换成所需类型的NumPy数组,并在第35和36行检查其是否在0和1之间。在第57行,我们在迭代开始前初始化diff,以确保它在第一次迭代时可用。
最重要的变化发生在第71行,用学习率和梯度重新计算diff,但也加入了decay_rate 和diff的旧值的乘积。现在diff有两个组成部分。
decay_rate * diff是指momentum,或者说是前一个动作的影响。**
-learn_rate * grad**是当前梯度的影响。
衰减率和学习率作为权重,定义了两者的贡献度。
随机启动值
相对于普通梯度下降,初始值对于随机梯度下降来说往往不是那么重要。并且,如果每次都需要手动设置,这其实是没有必要的,想象一下,如果我们需要手动初始化一个有数千个偏置和权重的神经网络的值,太麻烦了!
在实践中,我们可以使用随机数发生器来获得它们,并从一些小的任意值开始。
我们更新函数 sgd()。
def sgd(
gradient, x, y, n_vars=None, start=None, learn_rate=0.1,
decay_rate=0.0, batch_size=1, n_iter=50, tolerance=1e-06,
dtype="float64", random_state=None
):
# 初始化变量值
vector = (
rng.normal(size=int(n_vars)).astype(dtype_)
if start is None else
np.array(start, dtype=dtype_)
)
# 其余不变这里添加了新的参数 n_vars,定义了问题中决策变量的数量。参数start是可选的,其默认值为None,并且初始化了决策变量的起始值。
如果提供了一个除无以外的起始值,那么它将被用于起始值。
如果设置
start是None,那么我们的随机数生成器就会使用标准正态分布和NumPy.normal()[8]方法创建起始值。
试试sgd():
>>> sgd(
... ssr_gradient, x, y, n_vars=2, learn_rate=0.0001,
... decay_rate=0.8, batch_size=3, n_iter=100_000, random_state=0
... )
array([5.63014443, 0.53901017])又得到了类似的结果。
现在我们已经学会了如何编写实现梯度下降和随机梯度下降的函数。上面的代码可以变得更加健壮和精炼。另外,我们还可以在一些著名的机器学习库中找到这些方法的不同实现。
总结
我们现在知道什么是梯度下降和随机梯度下降算法,以及它们如何工作,它们在人工神经网络的应用中被广泛使用。
现在我们已经学会了:
如何为梯度下降和随机梯度下降编写自己的函数
如何应用我们的函数来解决优化问题
梯度下降的主要特点和概念是什么,如学习率或动力,以及它的局限性
我们已经使用梯度下降和随机梯度下降来寻找几个函数的最小值,并在一个线性回归问题中拟合回归线。
参考资料
[1]
numpy.all(): https://numpy.org/doc/stable/reference/generated/numpy.all.html
[2]numpy.abs(): https://numpy.org/doc/stable/reference/generated/numpy.absolute.html
[3]凸函数: https://en.wikipedia.org/wiki/Convex_function
[4]数值方法: https://en.wikipedia.org/wiki/Numerical_method
[5]普通最小二乘法: https://en.wikipedia.org/wiki/Ordinary_least_squares
[6]分析法计算: https://en.wikipedia.org/wiki/Ordinary_least_squares#Simple_linear_regression_model
[7]numpy.dtype: https://numpy.org/doc/stable/reference/generated/numpy.dtype.html
[8]NumPy.normal(): https://numpy.org/doc/stable/reference/random/generated/numpy.random.Generator.normal.html