MLIR原理与应用技术杂谈
参考文献链接
https://mp.weixin.qq.com/s/4pD00N9HnPiIYUOGSnSuIw
https://mp.weixin.qq.com/s/s5_tA28L94arLdm5UijkZg
https://mp.weixin.qq.com/s/sgZCbWnCQEO8C8gXv7wV6Q
MLIR基础
最近开始做一些MLIR的工作,所以开始学习MLIR的知识。这篇笔记是对MLIR的初步印象,并不深入,适合想初步了解MLIR是什么的同学阅读,后面会继续分享MLIR的一些项目。这里要大力感谢中科院的法斯特豪斯(知乎ID)同学先前的一些分享,给了我入门MLIR的方向。
IR即中间表示(Intermediate Representation),可以看作是一种中介的数据格式,便于模型在框架间转换。在深度学习中可以表示计算图的数据结构就可以称作一种IR,例如ONNX,TorchScript,TVM Relay等等。这里举几个例子介绍一下:
首先,ONNX是微软和FaceBook提出的一种IR,他持有了一套标准化算子格式。无论你使用哪种深度学习框架(Pytorch,TensorFlow,OneFlow)都可以将计算图转换成ONNX进行存储。然后各个部署框架只需要支持ONNX模型格式就可以简单的部署各个框架训练的模型了,解决了各个框架之间模型互转的复杂问题。
但ONNX设计没有考虑到一个问题,那就是各个框架的算子功能和实现并不是统一的。ONNX要支持所有框架所有版本的算子实现是不现实的,目前ONNX的算子版本已经有10代以上,这让用户非常痛苦。IR可以类比为计算机架构的指令集,但我们是肯定不能接受指令集频繁改动的。另外ONNX有一些控制流的算子如If,但支持得也很有限。
其次,TorchScript是Pytorch推出的一种IR,它是用来解决动态图模式执行代码速度太慢的问题。因为动态图模式在每次执行计算时都需要重新构造计算图(define by run),使得性能和可移植性都比较差。为了解决这个问题,Pytorch引入了即时编译(JIT)技术即TorchScript来解决这一问题。Pytorch早在1.0版本就引入了JIT技术并开放了C++ API,用户之后就可以使用Python编写的动态图代码训练模型然后利用JIT将模型(nn.Module)转换为语言无关的模型(TorchScript),使得C++ API可以方便的调用。并且TorchScript也很好的支持了控制流,即用户在Python层写的控制流可以在TorchScript模型中保存下来,是Pytorch主推的IR。
最后,Relay IR是一个函数式、可微的、静态的、针对机器学习的领域定制编程语言。Relay IR解决了普通DL框架不支持control flow(或者要借用python 的control flow,典型的比如TorchScript)以及dynamic shape的特点,使用lambda calculus作为基准IR。
Relay IR可以看成一门编程语言,在灵活性上比ONNX更强。但Relay IR并不是一个独立的IR,它和TVM相互耦合,这使得用户想使用Relay IR就需要基于TVM进行开发,这对一些用户来说是不可接受的。
这几个例子就是想要说明,深度学习中的IR只是一个深度学习框架,公司甚至是一个人定义的一种中介数据格式,它可以表示深度学习中的模型(由算子和数据构成)那么这种格式就是IR。
目前深度学习领域的IR数量众多,很难有一个IR可以统一其它的IR,这种百花齐放的局面就造成了一些困境。我认为中科院的法斯特豪斯同学B站视频举的例子非常好,建议大家去看一下。这里说下我的理解,以TensorFlow Graph为例,它可以直接被转换到TensorRT的IR,nGraph IR,CoreML IR,TensorFlow Lite IR来直接进行部署。或者TensorFlow Graph可以被转为XLA HLO,然后用XLA编译器来对其进行Graph级别的优化得到优化后的XLA HLO,这个XLA HLO被喂给XLA编译器的后端进行硬件绑定式优化和Codegen。在这个过程中主要存在两个问题。
• 第一,IR的数量太多,开源要维护这么多套IR,每种IR都有自己的图优化Pass,这些Pass可能实现的功能是一样的,但无法在两种不同的IR中直接迁移。假设深度学习模型对应的DAG一共有10种图层优化Pass,要是为每种IR都实现10种图层优化Pass,那工作量是巨大的。
• 第二,如果出现了一种新的IR,开发者想把另外一种IR的图层优化Pass迁移过来,但由于这两种IR语法表示完全不同,除了借鉴优化Pass的思路之外,就丝毫不能从另外一种IR的Pass实现受益了,即互相迁移的难度比较大。此外,如果你想为一个IR添加一个Pass,难度也是不小的。举个例子你可以尝试为onnx添加一个图优化Pass,会发现这并不是一件简单的事,甚至需要我们去较为完整的学习ONNX源码。
• 第三,在上面的例子中优化后的XLA HLO直接被喂给XLA编译器后端产生LLVM IR然后Codegen,这个跨度是非常大的。这里怎么理解呢?我想到了一个例子。以优化GEMM来看,我们第一天学会三重for循环写一个naive的矩阵乘程序,然后第二天你就要求我用汇编做一个优化程度比较高的矩阵乘法程序?那我肯定是一脸懵逼的,只能git clone了,当然是学不会的。但如果你缓和一些,让我第二天去了解并行,第三天去了解分块,再给几天学习一下SIMD,再给几个月学习下汇编,没准一年下来我就可以真正的用汇编优化一个矩阵乘法了。所以跨度太大最大的问题在于,我们这种新手玩家很难参与。我之前分享过TVM的Codegen流程,虽然看起来理清了Codegen的调用链,但让我现在自己去实现一个完整的Codegen流程,那我是很难做到的。【从零开始学深度学习编译器】九,TVM的CodeGen流程
针对上面的问题,MLIR(Multi-Level Intermediate Representation)被提出。MLIR是由LLVM团队开发和维护的一套编译器基础设施,它强调工具链的可重用性和可扩展性。
针对第一个问题和第二个问题,造成这些深度学习领域IR的优化Pass不能统一的原因就是因为它们没有一个统一的表示,互转的难度高。因此MLIR提出了Dialect,我们可以将其理解为各种IR需要学习的语言,一旦某种IR学会这种语言,就可以基于这种语言将其重写为MLIR。Dialect将所有IR都放在了同一个命名空间里面,分别对每个IR定义对应的产生式以及绑定对应的操作,从而生成MLIR模型。关于Dialect我们后面会细讲,这篇文章先提一下,它是MLIR的核心组件之一。
针对第三个问题,怎么解决IR跨度大的问题?MLIR通过Dialect抽象出了多种不同级别的MLIR,下面展示官方提供的一些MLIR IR抽象,我们可以看到Dialect是对某一类IR或者一些数据结构相关操作进行抽象,比如llvm dialect就是对LLVM IR的抽象,tensor dialect就是对Tensor这种数据结构和操作进行抽象:
官网提供的MLIR Dialect
除了这些,各种深度学习框架都在接入MLIR,比如TensorFlow,Pytorch,OneFlow以及ONNX等等,大家都能在github找到对应工程。
抽象了多个级别的IR好处是什么呢?
对于一个源程序,首先经过语法树分析,然后通过Dialect将其下降为MLIR表达式,再经MLIR分析器得到目标程序。注意这个目标程序不一定是可运行的程序。比如假设第一次的目标程序是C语言程序,那么它可以作为下一次编译流程的源程序,通过Dialect下降为LLVM MLIR。这个LLVM MLIR即可以被MLIR中的JIT执行,也可以通过Dialect继续下降,下降到三地址码IR对应的MLIR,再被MLIR分析器解析获得可执行的机器码。
因此MLIR这个多级别的下降过程就类似于我们刚才介绍的可以渐进式学习,解决了IR到之间跨度太大的问题。比如我们不熟悉LLVM IR之后的层次,没有关系,我们交给LLVM编译器,我们去完成前面那部分的Dialect实现就可以了。
MLIR编译框架
AI领域专用芯片的演进极大地促进了架构探索(指架构定义及性能分析)的发展,先后出现了众多的分析方法,这些分析方法针对AI计算过程中关键算子以及网络模型进行建模分析,从PPA(Power-Performance-Area)三个角度评估硬件性能。与此同时,伴随着AI编译框架的发展,尤其受益于MLIR编译器框架的可复用及可扩展性(详见MLIR多层编译框架实现全同态加密的讨论),将这些分析方法融入到MLIR框架中也变得十分可能,从而使用编译器对硬件架构进行探索。
架构分析中关注三个方面的表达,分别是计算架构(Computation Element),存储结构(Memory Hierarchy )和互联结构(Interconnect)。对硬件架构进行性能分析时,数据流是搭建分析方法的基础,根据数据流的表达,将workload的计算过程映射到硬件架构的三类实现中。在学术研究中,Eyeriss [1]是较早将数据流引入到AI芯片的性能分析中,根据定义,AI的数据流可以分为三类,输出静止(Output Stationary),权重静止(Weight Stationary)和行静止(Row Stationary)。随后的研究中,MAGNet[2]将其扩种为更多的描述方式,如图1所示,但还是围绕OS,WS和RS展开。根据数据流的划分,AI架构既可以分为这三类,比如NVDLA属于WS,Shi-dinanao属于OS,Eyeriss属于RS。相同的数据流架构可以采用类似的方法进行分析。

图1 不同数据流对应的for-loop表示[2]
围绕数据流表示和硬件映射的表达上,可以归为三类,分别是以计算为中心 (computation-centric)的Timeloop[3], 以数据流为中心(data-centric)的MAESTRO[4]和以关系为中心(relation-centric)的TENET[5]。以计算为中心的表示方法关注的是for-loop表达在时间维度上映射到硬件架构;以数据流为中心的表达关注的是数据映射(data mapping)和复用(reuse);以关系为中心的表达关注循环表达和计算单元及调度之间的关系。本文将对第二种data-centric的表达方式展开。
在MAESTRO的工作中,将data mapping和reuse作为一等公民,关注的是数据在时间和空间两个维度的复用。对于WS的计算架构,weight在时间维度上复用(相当于保持不变),中间计算结果是在空间维度上复用,其复用如图2所示。
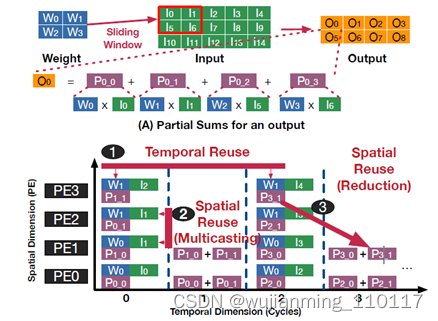
图2 2x2kernel的卷积在WS类型加速器数据复用的表示[4] 关于时间和空间数据复用的表达,文中提出了一种IR的表示方式,我们称之为时域映射(Temporal Map)和空域映射(Spatial Map)。时域映射表示特定的维度与单个PE之间的映射关系,空域映射表示的是特定的维度与多个PE之间的映射关系,具体的表示如下:1.T(size, offset)α:α表示的特定的维度,比如权重的weight,width及channel等,size表示单个时间步长(time step)下α所在维度的index映射到单个PE的尺寸,offset表示的是相邻的时间步长的index偏移。对应的for循环表达如图3所示。2.S(size, offset):α表示特定的维度,size表示维度α映射到每个PE的index的尺寸,offset表示映射到相邻PE的index偏移。

图3 时域和空域映射与循环表达之间的对应关系[4]
假设一个计算架构有3个PE,卷积的权重大小为6,输入元素个数为17,步进为1,计算过程可以通过图4表示。在图中,标签1表示for循环的表达,标签2表示在时域和空域的IR表达,标签3表示数据在PE的分布及时间上的计算过程,图中可以看出cycle1到cycle4复用S中的index(1),也就是weight保持静止。标签4表示空域映射、时域映射以及计算顺序,其中t表示按照所示的箭头方向依次计算。基于这样的IR表达及时间上的计算过程,就可以表示出一个WS架构的计算过程。
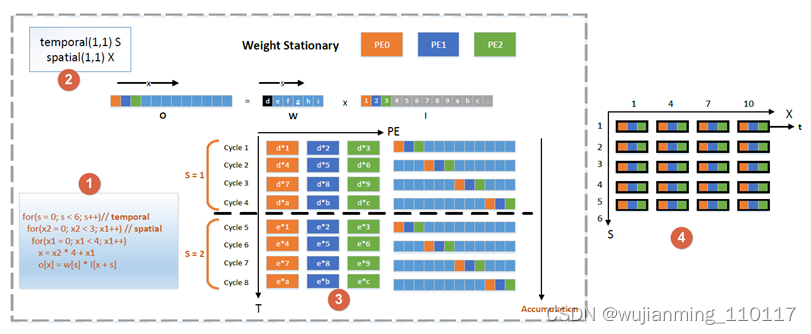
图4 1D卷积操作在时域和空域的表示演示图
基于IR的性能分析方法
Aladdin[6]是较早开展基于编译的方式进行硬件的性能分析,将性能分析提前到RTL代码之前,避免了RTL代码及C-model大量的开发工作,基本的思路是将计算任务lowering到动态数据依赖图(DDDG:Dynamic Data Dependence Graph)级别,DDDG是针对特定架构的中间表达(Intermediate Representation)的表示,如图5所示。针对特定的硬件架构,分析DDDG的动态执行过程,即可评估出性能和功耗的数据,他们基于ILDJIT compiler IR[7]。

图5 DDDG的计算表示[6]
基于GEM5的工作,他们将其扩展为GEM5-Aladdin,用于对加速器系统级的性能分析,涵盖了SoC的接口通信开销,从而实现加速器架构和通信的协同设计。GEM5负责CPU和内存系统的性能分析,Aladdin负责加速器的性能分析。DDDG的表示从ILDJIT IR迁移到LLVMIR。
Interstellar[8]是将Halide语言用于AI架构的性能分析,数据流表达的方式属于computation-centric,核心工作是将和计算及数据流相关的for-loop转换到Halide的scheduling language,同时显性表达存储和计算。其中,关于架构和数据流是在Halide编译过程中的IR表达中引入,同时和Halide语言中的hardware primitive对应起来,将整个计算过程拆解到IR级别,然后映射到硬件结构,最后根据数据流的计算过程评估硬件的性能,整体过程如图6所示。最终采用调用硬件语言代码库的方式生成硬件设计。

图6 标签1为Halide语言描述conv操作;标签2表示Halide Lowering过程中对in, compute_at, split及reorder调度原语(scheduling primitives)的IR表示;标签3表示调度原语和硬件架构的对应关系[8]
架构级别的IR
Micro-IR[9]文章的核心思想是将加速器的架构表示为一个并发的结构图(Concurrent Structural Graph),每个组件就是一个架构级别的硬件单元,比如计算单元、网络或者存储器。结构图中显性地表达了加速器的构成组件,以及不同组件之间的数据流动,最终回归到数据流的表达和实现上。定义架构级别IR的好处在于1)将算法的表达和硬件架构解耦,2)将硬件的优化和RTL的代码实现解耦。这样一来,硬件架构IR层的优化工作可以单独展开。
整个编译的架构基于LLVM的实现,前端接入为AI framework,然后编译到LLVM IR,LLVM IR再对接到Micro-IR,在Micro-IR优化的PASS中聚焦就是前文提及到的关于数据流的映射、调度,tiling以及映射到硬件的intrinsic。最后对接到chisel的IR FIRTL,生成可综合的硬件语言。
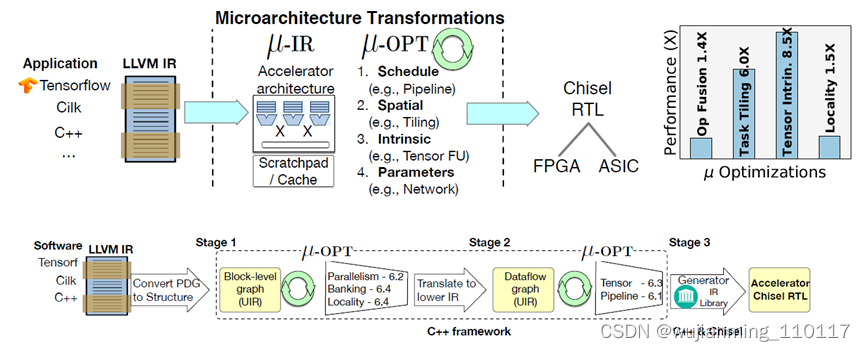
图7 Micro-IR的编译流程[9]
对于架构的表达,也是围绕数据流、存储和互联的展开,如图8所示,将一个简单的奇偶乘法翻译到IR图层,再翻译到IR的具体表达。
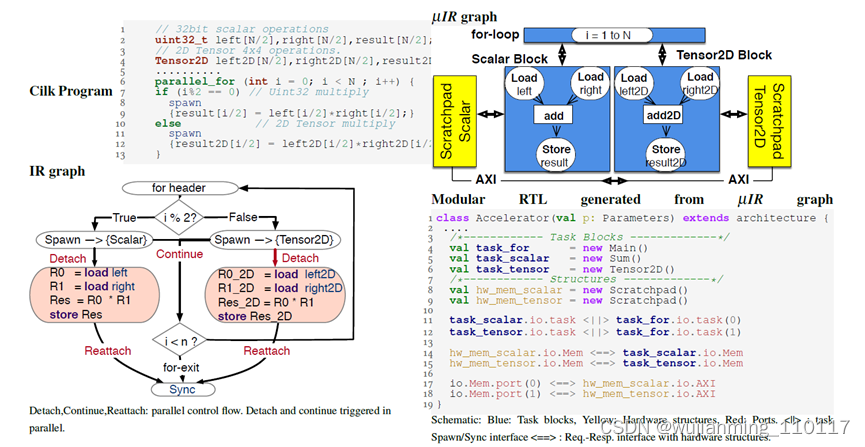
图8 Micro-IR的编译表示[9]
MLIR中引入架构探索的可能性和挑战
可能性:1.经过上述章节的分析发现现有的性能分析方法的研究工作都有IR表示的思想,而且基于数据流的表示思想具有较好的理论基础,从时域和空域两个维度展开,也有很好的IR具体实现。2.基于IR性能分析的方法也处于不断演进的过程中,从ILDJIT到LLVM再到Halide,都证实了基于IR进行架构探索的可行性。同时不同的表示方式具有不同的有点,比如Halide中突出调度的思想,可以将该思想引入到MLIR中,形成schedule IR。3.关于硬件架构IR表示的文章也较多,比如Spatial[10],文中举例的micro-IR 是比较典型的标准,与MLIR都基于LLVM的编译流程,将其引入到MLIR中作为硬件架构存在可能性。4.Union[11]是将MAESTRO性能分析的工作引入到MLIR的框架中,但是MAESTRO是作为架构探索的工具使用,没有接入到MLIR的编译流程中。
挑战:1.目前的架构探索都是基于相对规则的架构展开,没有涉及到复杂的工业界的芯片,存有一定的局限性,将其方法应用到工业界还有很大的隔阂。2.定义一个通用型的架构IR比较困难。架构是比较分散的,不同的任务需求有不同的架构设计,虽然架构设计从大的层面分为计算、存储和互联,但通过IR精准地刻画架构充满挑战,比如对于架构IR控制流的表示,Micro-IR中关于控制流的表达没有进行详细的阐述。3.在编译过程中,如何将软件任务能够自动翻译到架构IR上,同时能够对硬件架构进行自动调整和优化,这也是很大的挑战。目前是针对特定的已知架构,将计算任务映射到硬件。
GPU MLIR 设计
多级(IRs)层次结构,逐级降低程序,执行代码转换。根据自有设计原则,开发原型编译器,设计stencil和 GPU dialect。在 LLVM MLIR 编译器基础架构上实现的两个域特定优化(500 行代码)。从本质上讲,多层次重写有望开启由域和特定目标dialect组成的专业编译器的时代。
目标域特定方法正在彻底改变高性能设备的代码生成,激发了目标域特定语言 (DSL) 框架的发展,实现了通用编译器无法达到的性能。例如,Halide自动生成用于图像处理的高性能代码,XLA利用目标域特定的编译加速深度学习,Stella是将天气和气候模拟移植到 GPU 实现 2.9 × 加速。特定编译器的成功, 随着时间的推移也暴露了弱点:与通用编译器流程分离。Halide, XLA, Stella和其他专有方案,设计时没有考虑到重用性。可复用的编译器基础架构,如 ROSE 或 LLVM, 实现目标域特定功能,设计和维护成本很高。
因此, 如何设计一个目标域特定的编译器, 该编译器
(a) 与用户前端完全脱钩,
(b) 便于实施域转换,
© 明确分离通用组件?
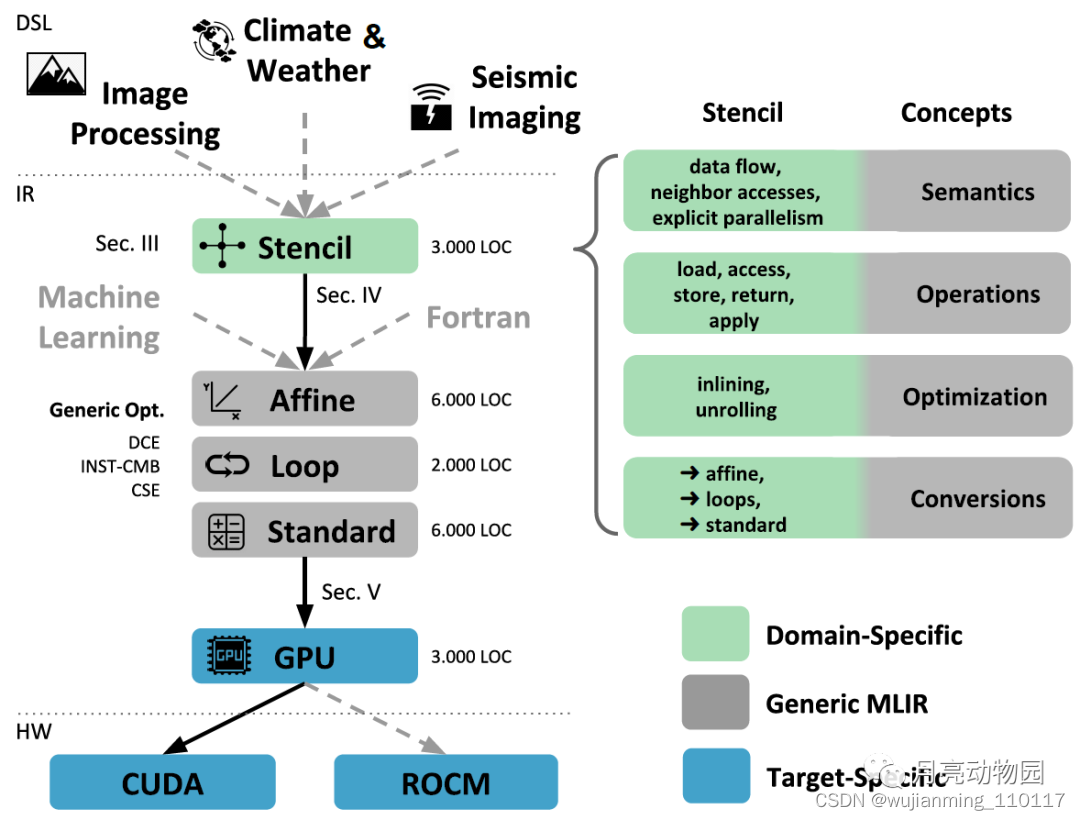
本方案设计和实现气象和气候建模编译器来构建多级IR结构。使用图像处理stencil计算模式, 但它需要完全不同的优化策略才能达到最优性能。地震成像是 3D 的, 实现了控制流的带宽限制的低阶stencil。相比之下, 图像处理流程在2D 数据结构上使用stencil, 地震成像stencil是高阶计算密集型。多维数组上的循环抽象, 算术优化 以及 生成 GPU 代码 这些方面大体相同, 但要重新实现。建议使用多层次 IR 重写来设计 DSL 编译器。
此方法是
(a) 基于SSA
(b)高级语义运算
© 渐进式IR的组合, 为可复用 高性能设备代码生成 提供了有效的框架。
基于 SSA IR , 可复用通用编译器的优化方法。高层运算主要编码目标领域属性, 使其可用,例如,SSA 数据流, 无需分析。渐进式层次下降保存目标领域信息、将转换表示为peephole优化 以及 引入可重用的低层级抽象。
a. 多级 IR 重写的编译器概述
MLIR 编译器, 使我们能够获取 LLVM在过去 15 年中实践验证的 IR 设计原则, 实现生产级编译器 IR。Open Earch 编译器(图 1) 是一个端到端的编译流, 利用多层 IR 重写来实现高性能代码生成。其核心是一组 MLIR dialects, 即运算和变换的集合, 以及它们之间的转换。Open Earch编译器使用 peephole-style重写模式, 逐步将程序从高级别的域特定dialect转换为较低级别的平台特定dialect来优化代码。每个dialect都定义了一个抽象, 使相关分析成本较低, 便于转换。编译过程从 stencil dialect 开始, 该dialect 用于面向用户的DSL,以及用于转换的数据结构 (如 stencil inlining)。Stencils进一步向更低层次下沉, 使用一系列IR表示的操作 (Affine), 结构控制流(SCF) 和算术运算 (Standard), 这些操作在 MLIR中都有了, 以及循环转换和数值层级的转换(如循环展开或通用子表达消除)。这些 IR 使我们专注于结构化循环抽象, 而不是编译器后端常见的低级别的基于"goto"的 SSA IR。使用此结构设计通用GPU kernel dialect, 基于stencil级别保留的并行信息, 使用简单模式实现loop-to-kernel转换, 避免成本较高的 GPU mapping algorithms。这完整的流程可以将高级别代码转变为可高速执行的二进制文件。
虽然stencil dialect是通用的, 足以涵盖一系列应用 (如图像处理或地震成像), 但本案例是要实现气候领域的高性能计算。基于Stencil operations的语义, 能够用通用指令转换(例如冗余消除)取代复杂的循环变换序列,仅需很少的分析以确保有效性。其他领域可以调整stencil dialect, 以适应需求变化, 或只重用中低层抽象。实践证明, 基于多级 IR 重写,开发具有可重用的组件的特定编译器非常简单。
多级 IR 重写设计模块化的编译器:
● stencil language可表示为 MLIR dialect,将stencil program高级数据流编码为 SSA
● 多次转换, 用简单的peephole优化, 而非传统高级别层次上的循环转换, 来调优 stencil program
● 平台无关 GPU dialect编译流程, 转换为特定 GPU 代码
b. 多级 IR 重写
多级IR 重写, 定义一系列可重用的抽象, 实现转换来简化特定编译器的开发。目标是降低每级的复杂度, 直接在 IR 中编码, 保留转换的有效性, 降低分析成本。识别特定领域的抽象对于多层次重写至关重要。每一个新的抽象都会增加复杂度, 相反, 如果抽象不完整, 某些工作负载无法表达。使用 MLIR 开发 OpenEarth编译器, 对它进行抽象, 必要时引入新的抽象。目的是确保性能: 并行和数据本地化, 这两个是需要平衡的转换, 会产生复杂的优化问题。提出这些问题, 使用以下原则从具体问题中提取并行和数据本地化信息。
P1 转换驱动的语义
流程中的特定抽象,如 stencil 或 GPU kernels, 应该倾向于为转换准备而不需要程序员友好。主要是建立一堆中间表示, 使编译器能够对特定程序进行推理, 而无需多次重复分析, 如 循环提取 或 依赖分析。每个 IR 都侧重于处理一组特定的转换, 获取所有必要的信息。用户可用性可以直接放到 DSL 前端。
P2 渐进式转换
还要建立一个有效和简化的转换流程, 代码逐步从高层 IR 降低到低层目标 IR。应设计不同的 IR 抽象, 保持高级别语义信息, 避免对高层语义的恢复过于复杂。在较大的编译器中, 渐进式下降, 抽象应无缝组合, 共存于单模块中, 有选择地下降转换。
P3 显式分离
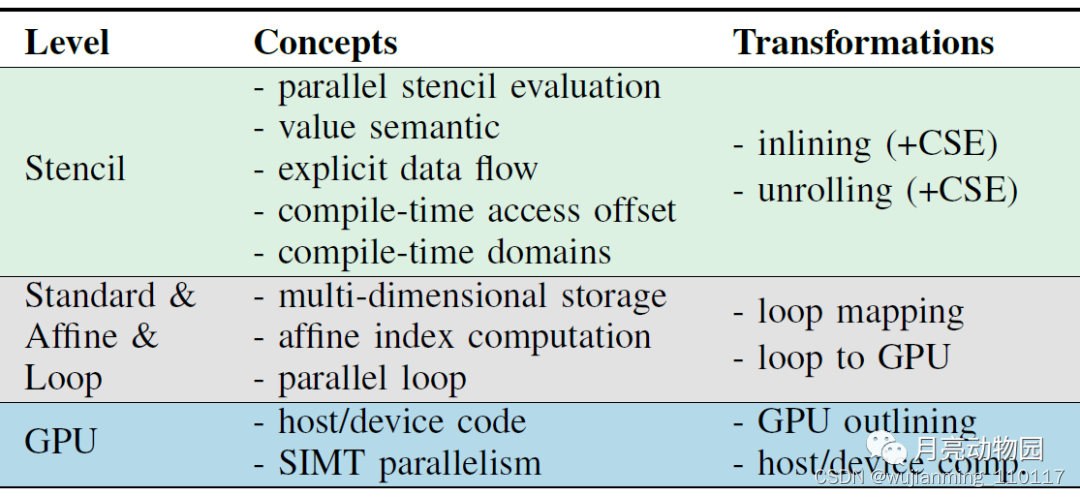
根据之前的原则的抽象组合性, 将各个抽象部分组合起来比解耦复杂的表示更容易。对IR分离的思路往往取决于特定的应用领域,这些区别要明确体现到IR中。特别是性能相关的抽象, 如并行度或内存分配, 应在 IR 中有所体现, 并彼此分离。同样, 编译和运行时抽象也应分开。从长远来看, 这种表示更适合现代搜索技术。渐进式降低的IR (P2), 各级之间清晰的分离(P3), 如表I所示, 每级的转换易于实现(P1)。这种多层次的表示有助于将优化转换与层级降低分开。
c. MLIR 基础架构
MLIR 编译器基础架构, 适合多层IR 重写, 它有dialect扩展以及对声明式重写模板的内置支持。因此,OpenEarth编译器可以作为一组 MLIR dialect实现, 并转换为重写模式。如果设计一些抽象, 重用 standard, Loop, Affine, 和 LLVM IR dialect, 以便它们能够组合在一起。
MLIR 核心概念包括operations,values, types, attributes, (basic)blocks 和 regions。operations是程序描述的原子单位。values表示运行时的数据, 始终与编译时已知的类型关联。operations使用values, 定义新 values。values只能定义一次, IR 需要遵守 SSA。types保留有关values编译时信息,而 attributes 将编译时信息添加到operations。block是一系列operations, 与其他block连在一起形成regions。region对应于含有语义operation。主要的控制流只处理 operation和对应的regions, 以及同一region 的 blocks 的出入口之间。特定 operation 定义了控制流的结构, 例如, block 的最后一个 operation 可以有条件或无条件地将控制流转移到另一个 block。

图2将 64x64x64元素的定义值 %def 设置为负值 %use 的MLIR运算示例。
图2 演示了stencil dialect 的一个 operation的语法。stencil.apply 操作用 %use使用值, 用 %def 定义值。types和 attributes 标记编译时运算。嵌套 region 由一个 block 组成, 用基本 block 参数 %arg 执行计算。这种分层组织分为 blocks 和 regions, 能够实现无限嵌套。没有一组固定的 operations, attributes, 或 types。相反, 每个 MLIR 用户可以定义自己的或重用其他人定义的。即使是 MLIR 内置功能很大程度依赖于这种扩展性。因此, stencil computation 可以通过提供自定义 types, attributes 和 operations, 构建stencil编译器。控制流操作, 比如循环或多维数组数据类型也是其构成部分。从架构角度来看, 自定义运算和类型与常见的数值运算和类型没有区别。dialect 是一组协同工作的operations,attributes 和 types。dialect的结构没有所谓正式或技术限制, 除非运算语义另有规定, 否则 region 可以包含不同dialect的运算, 运算可以引用不同 dialect 定义的 types 和 attributes。因此, 新的抽象可以作为新的dialect引入MLIR生态系统。
d. stencil dialect
OpenEarth编译器运行天气和气候模型。这些模型主要包括偏微分方程。包括数十个stencil 代码, 由多个 stencil operator 组成作用在不同的3D网格上。本案例将空间划分成三维网格, 每个网格与其他六个相邻。这样就可以通过索引处理单元格问题。在stencil 代码中, 不是优化单个stencil, 必须优化stencil chain 或整个程序链, 例如, 利用生产者-消费者融合来获得最优性能。设计stencil dialect来表示stencil 代码, 包括连接它们之间的stencil 运算, 以及数据流上的输入/输出数据结构, 可选控制流, 按照之前定义的多级 IR 重写原则实现。dialect分解为高级IR(P3), 构建运算和低层IR之间的数据流, 低层IR构建了单个运算的并行执行。其中我们模拟了单个操作员的并行执行。高层IR支持控制流路由转换, 它的stencil operator可被视为一个单位(与低级别IR算术指令集合相反), 低层IR支持并行(P1)。层级分离也包含在渐进式下降中(P2)。
dialect不是为用户设计的 DSL, 是支持变换(P1和P3)的编译器 IR, 通过:
(a) 保持 stencil 概念的高层语义, 以便它们可以变成一个单元进行处理,
(b)不强加特定执行顺序以便平行,
© 用值语义而不是分配存储对象, 避免缓存分析。
Dialect Overview

图3:stencil 示例代码, 计算简单的stencil数组 %in, 将结果存储到数组 %out。
stencil dialect 主要考虑特有的概念, 用MLIR标准dialect来表达具体计算(P2)。图 3 stencil 代码, 处理 64x64x64的每一个元素, 添加输入array% 左右邻, 结果存储到 %out中。"stencil"前缀从dialect中识别 operations 和 types。Dialect 定义了两种 type: A !stencil.field 是一个多维数组, 存储网格中所有点。stencil 代码的输入和输出都是这个类型。A !stencil.temp 是网格矩形子域上的多维元素集合。临时变量有值语义, 但不存储。这种类型的值要么指向输入数组的子域, 要么保留stencil operation的计算结果。这两种类型都存储1到3维数组上的单精度或双精度浮点元素(f32 或 f64)。stencil dialect 还定义了六种操作。stencil.assert操作判断数组的静态形状。stencil.load操作输入数组, 返回指向stencil的输入元素的临时变量。stencil.apply操作执行 stencil, 定义了保存计算结果的变量。循环迭代部分, 对某一点执行 stencil operator。stencil.access 操作以特定偏移读取输入临时变量, 而 stencil.return操作将输出设置为当前位置。在这两者之间, 使用标准 dialect 计算左右邻元素的和。stencil.store操作最终将计算结果存储到输出数组。那么, 其范围属性指定了stencil 代码编写的具体领域。编译器利用输出范围自动推导整个stencil 代码的访问范围和迭代域。
Shape & Domains
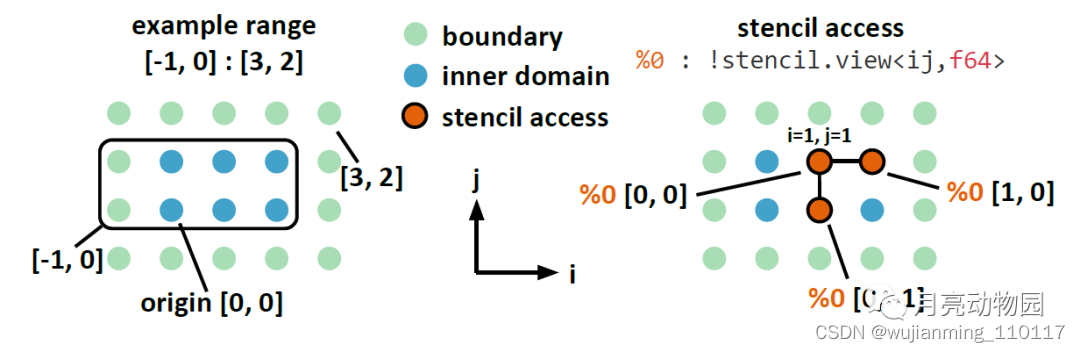
图4:示例range表示为: (左)下界,上界,stencil accesses(右)
range对指定 stenciliteration 域和访问范围至关重要, 特别是考虑到stencil可能会访问其计算域之外的输入下标, 比如边界。图4显示二维range(左图)。原点表示计算域的下限, 所有坐标设置为零。包含下界和由冒号间隔的上界的绝对坐标, 以确定范围。GPU 中, 整型索引计算是一个重要的性能瓶颈。实际操作中, stencil 经常针对相同的问题反复执行stencil,stencil dialect 支持特定的JIT编译。内存大小和迭代域定义为数字类型编译时属性(P3)来实现这个功能。
Stencil Operators
stencil operator 对网格的所有元素进行元素计算, 除了某些常量宽度边界。相对于输出元素的坐标, 它以常量偏移访问输入数组的元素。stencil.apply操作实现了标量运算的stencil operator。标量运算在循环嵌套中作用到所有元素。stencil operator输入和输出, 与这个操作使用和定义的值相对应。Stencil.access 可以访问输入的各个元素, 以恒定偏移读取元素。然后, stencil dialect lowering 添加指针偏移到当前迭代。图4显示了二维stencil迭代的偏移计算(右图)。stenciloperator 的区域必须由某个stencil.return 终止, 输出元素值作为参数返回。Stencil.access 和 stencil.return一起指定了stencil operator的访存模式。两者都仅作为 stencil operator的一部分。实际的stencil gragrams通常会实现数十个stenciloperators。因此, stencil program 需要一些方法来编排它们。
Stencil Programs
stencil program 执行一系列相互依赖的 stencil operators。它从输入数组中加载数据, 添加stencil operators, 将结果存入输出数组。程序的 SSA 定义使用图指定了stencil operators(P2)之间的高层级数据流。将高级数据流和函数中的stencil operators, 进行代码转换, 消除复杂的程序分析(P1)。另外三个操作也是程序的一部分。stencil.assert指定输入或输出数组范围。需要定义所有输入和输出数组的索引范围。stencil.load 返回一个临时变量, 所有输入数组元素。stencil.store 存储输出数组。
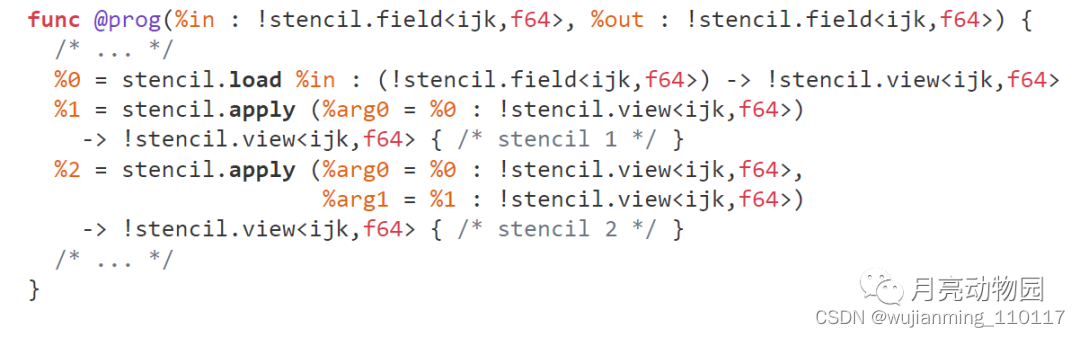
图5:是两个相互依赖stencil program。Stencil.load返回临时变量, 保存 %in 数组元素。第二个stenciloperator使用第一个的结果。最后, stencil.store 保存第二个stencil计算结果到数组 %out。所有stencilprogram 参数没有别名, 从unit加载或存储到unit。中间结果保存在 !stencil.temp, 不存储, 不命名。根据!stencil.temp的数值语义, def-use图对stencil operators之间的数据依赖关系进行编码(P1 和 P3)。
Control Flow
实践中的stencil application 不只是纯数据流语义。可以 eagerexecution 和 JIT编译处理大部分程序级别的控制流, 采用 MLIR 内置的结构控制流(SCF) dialect, 在 stenciloperators 内部实现动态控制流。

图6:SCF dialect使 stencil operator内部控制流得以实现。
图 6显示了一个 stencil根据判断条件访问其中一个参数。scf.if执行"then"或"else"。与if-else相比, 操作返回 scf.yield 设置的结果。这个表示使数据流变得清晰, 每个stencil维护一个stencil.return。除了scf.if之外, select也可以基于条件选择计算值。要支持scf.if 不需要调整编译器(P2)。选择内置 MLIR SCF dialect可以渐进式逐层下降, 显式分离和可组合抽象, 使编译器组件在多级 IR 重写方案可以重用。
e. Stencil Transformations
stencil dialect 有3类转换:
1)性能优化,
2)准备降低,
3)实际降低.
Optimizing Transformations
stencil dialect 的所有优化转换均在高层运行, 既不引入循环, 也不引入存储分配(P1)。
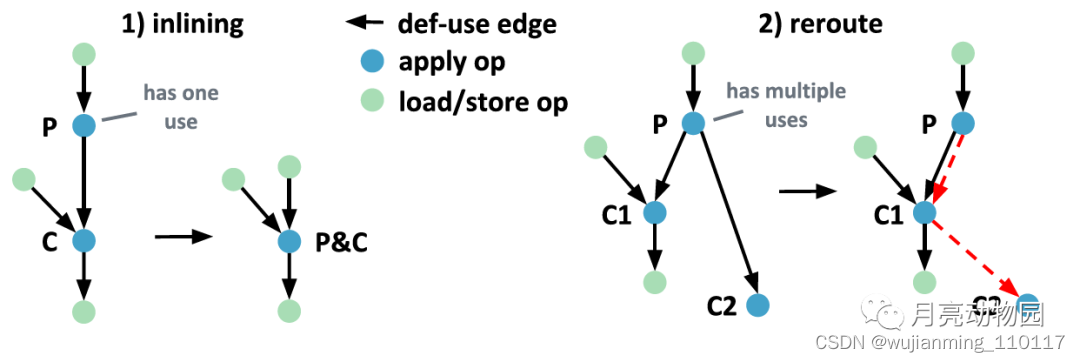
图7: stencil program两种模式迭行生产者-消费者融合。def-use edges表示stenciloperations 之间的是数据流。
stencil inlining pass 在 def-use graph进行融合。反复使用生产者-消费者融合的stencil变体, 内联计算取代所有对生产者结果访存。如果消费者访问多个生产者, 需要对迭代域中的每一个点重计算。任意顺序inlining stencil可能会引入循环依赖。例如, 消费者的输入可能依赖于另一种stencil, 这种stencil会暂时依赖 producer stencil的输出。不需要开发一种算法将stencil按特定顺序融合, 而是匹配和重写小子图, 并使用 MLIR 一步步重写stencils。图7显示了inlining patterns。如果producer只有一个consumer, 则inlining pattern将生产者 P 和消费者 C 匹配。如果模式匹配成功, 删除producer stencil, 将计算内联到consumer。另外还要更新fused stencils的参数和结果列表。重定向的模式将生产者 P 及它的消费者 C1 与 CN 匹配。如果模式匹配成功, 将生产者的所有输出通过要执行的下一个消费者进行路由。红色箭头标记了重路由的数据依赖。前一种模式是真正的inlining, 后一种模式是准备一个inlining step。inlining实现引入重计算, 即使消费者多次访问相同的偏移, 始终 inline 整个producer, 即使只访问其中一个输出。死代码消除 dead code elimination 和子表达消除 common subexpression elimination 稍后会清理代码。这些转换依赖于stencil accesses 并无其他作用(stencil输入不可变, 不给输出起别名)。这个编译器目前不实现启发式融合和连续内联, 不管使用哪种模式。

图8:沿着j维度展开stencil的两次迭代。
stencil unrolling pass 多次复制stencil operator, 一次更新多个网格。图 8显示了示例程序的unroll版本。Unrolling 是高层dialect实施循环转换的又一例证。这个实现不是改变循环, 而是标注高级stencil dialect, 直接降低到unrolled loops。只修改 stencil.apply 上的嵌套区域, 但不处理接口。刚开始的时候, 每次展开循环迭代只计算stencil一次, 调整访问偏移。使用stencil.return 返回所有展开循环迭代的结果, 用可选属性attribute标记展开因子和维度。unrolling pass支持所有展开维度和展开因子。但lowering目前仅限于域大小均匀划分的展开因子。
Inlining 和 unrolling 可提高stencil程序的性能。inlining 引入冗余计算, 减少了芯片外的数据移动。Unrolling 消除一部分冗余计算, 因为unrolled stencil operator 通常在同一偏移多次使用生产者。使用现有的通用子表达式消除pass,不是自动删除冗余计算。
Preparing the lowering
优化stencil程序后, 推断出所有访问范围和迭代域, 以准备lowering(P2)。
shape inference pass 获得输入数组和 stencil operators。stencil程序只定义了代码编写的输出范围, 需要做shape inference。pass从输出范围开始, 根据stencil程序依赖的use-def链, 扩展访问范围。算法反向遍历代码的所有运算, 用range attributes标记可计算范围。这些计算范围是最小边界框, 包含了这个当前运算需要用到的所有变量或值。如果消费者是stencil.load操作, 它的访问就和输出范围的属性是一样的。如果消费者是stencil.apply 操作, 它的访问范围就是所有要处理的变量或值的最小边界框的迭代区间。一旦stencil.load操作的访问范围确定了, 就可以知道输入数组是否足够大。
虽然这些访问区间分析看上去和渐进式lowering的思路相矛盾, 但它的目的不是恢复之前的高层信息, 它主要是自动化地对手动访问的地方做错误验证。形状推理使能lowering, 且不会有性能影响。
Lowering to Explicit Loops
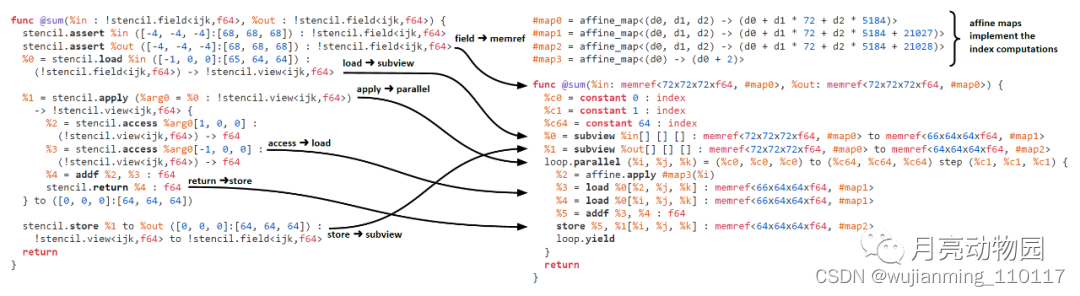
图9: 将stencil dialect 转换为MLIR SCF + Affine+ Standard dialect 进一步降低到GPU abstractions。
stencil lowering 使用转换模板将单一stencil 运算转换成对应的MLIR。这是编译流程中最后一个与特定领域相关的部分, 如图1中所示, 将high-level stencil程序向可执行代码的下降。即使是标准dialect层次上, MLIR 也提供了相当高层次的抽象。memref 是结构化的多维buffer抽象, 可以具有静态或动态大小, 如果layout不是行主格式, optional layout attribute 就可以定义索引计算。layoutattribute还可以将strided hyper-rectangular定义为memory buffer,例如, 每个维度都有偏移和非单位steps。另一个例子是scf.parallel, 可以并行多维循环。
图9演示了从stencil dialect 到MLIR standarddialect level 的lowering的过程。本例定义六种转换模板, 引入loops, index computations, memory accesses, temporarystorage 。lowering 之后, 通过分析检测 stencil operators或读取偏移。实现特定于域的转换变得更加困难。反过来, 通过引入循环loops 和临时存储 temporary storage, 实现了程序顺序执行, 但仍需为后续 GPU lowering 保留并行语义。
f. GPU Dialect
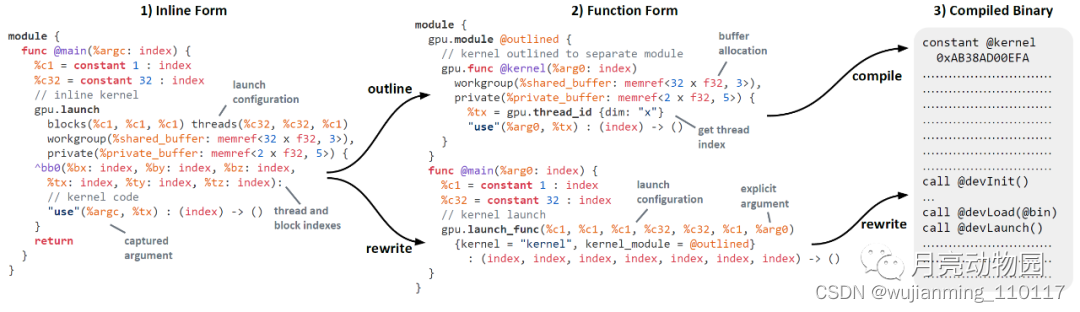
图10: lowering of a kernel: 1) inline form支持主机设备代码和其他转换, 2) function form 将设备代码隔离在一个可实现设备特定优化和单独主机/设备代码编译的独立模块中, 3) 二进制文件将kernel嵌入为常量数据。
GPU是实现高性能的首选平台, 可以构建了针对这些设备的多层级编译器。按照之前的原则进行设计, 实现 MLIR GPU dialect, 不依赖供应商库抽象 GPU 执行模型。泛化了 MLIR’s NVVM, ROCm 和 SPIR-V 表示, 将统一的平台独立设备映射(P1)与平台相关的代码生成(P3)code generation区分开来。GPU dialect 不是通用的 SIMT 执行模型(P3), 也不是较低级别抽象(P2)的高层表示。
Dialect提供了一组GPU 的特定概念: 分层线程结构 (blocks, threads, warp); synchronizationthrough barriers; 内存等级memory hierarchy (global, shared, private, constant memory);标准计算原语, 如 parallel reductions。单个模块(P3)中支持主机/设备单独编译。设备端编译由 MLIR 模块实现, 这些模块递归包含以不同方式处理的其他模块。
图10是 GPU lowering 期间, kernellaunch的两种形式。Inline form 使用gpu.launch 定义kernel inline。嵌套实现kernel, block 参数提供 thread 和 block 标识符。不需要处理参数, 嵌套之外定义的值可以处理。function form 使用 gpu.func 实现 kernel , 在单独的模块中实现, 通过 gpu.launch_func 激活 kernel。专有操作可访问线程和块标识符。所有非常量内核参数均可传递, 而常数则传递到内核函数中。inline 和 function form 均接受 GPU grid配置, 支持 GPU 内存等级的不同级别缓存的声明分配。Kernel code 按照 SIMT 模型进行单线程计算, 有专门的机制访问线程和块标识符。特定的GPU原语(barrier synchronization, shuffles, and ballots)只能存在于kernel内部。图10 演示了 GPU lowering 的主要步骤, 从内联形式(左)开始, 通过函数形式(中间), 到编译好的二进制(右)。并行循环嵌套可以就地转换为内联形式, 使用循环边界作为 GPU grid 配置。转换之后, 使用通用子表达式和死码消除、规范化和 GPU kernel内常量传播, 最大限度地减少主机/设备内存流量。Kernel inline 无可见性限制, 基于 SSA 的转换可无缝地作用于主机/设备边界。Kernel 在专用 GPU 模块中实现独立的功能。内核调用的函数复制到模块中, 内核外定义的值作为函数参数传递进去。kernel位于单独的模块中, 实现独立的主机/设备优化和编译。Host code 程序内优化无法作用到kernel。GPU 模块最终通过专用dialect转换为平台特定表示(PTX), 并使用供应商编译器(ptxas)将进一步编译为二进制文件。生成的二进制文件以全局常量嵌入到原有模块中。这种方法支持多种版本, 支持不同大小的工作负载的多个架构或特定 kernel。然后, 用二进制扩展的原始模块变成了host模块, 可以优化,编译,执行。Kernel 调用降低到对设备驱动程序库或运行时的调用。
参考文献链接
https://mp.weixin.qq.com/s/4pD00N9HnPiIYUOGSnSuIw
https://mp.weixin.qq.com/s/s5_tA28L94arLdm5UijkZg
https://mp.weixin.qq.com/s/sgZCbWnCQEO8C8gXv7wV6Q