一、图像单应性概述
论文提出了一个深度卷积神经网络来估计一对图像之间的相对单应性。我们的前馈网络有 10 层,以两个堆叠的灰度图像作为输入,并产生一个 8 自由度的单应性,可用于映射从第一个图像到第二个图像的像素。我们为 HomographyNet 提出了两种卷积神经网络架构:一个直接估计实值单应性参数的回归网络,以及一个在量化单应性上产生分布的分类网络。我们使用 4 点单应性参数化,将一个图像的四个角映射到第二个图像。我们的网络使用扭曲的 MS-COCO 图像以端到端的方式进行训练。我们的方法无需单独的局部特征检测和转换估计阶段即可工作。我们的深度模型与基于 ORB 特征的传统单应性估计器进行了比较,我们强调了 HomographyNet 优于传统技术的场景。我们还描述了由深度单应性估计提供支持的各种应用,从而展示了深度学习方法的灵活性。
稀疏的 2D 特征点是大多数现代 Structure from Motion 和 SLAM 技术的基础。 这些稀疏的 2D 特征通常称为角点,在所有几何计算机视觉任务中,必须平衡角点检测方法中的误差与几何估计误差。 即使是最简单的几何方法,例如估计两个图像之间的单应性,也依赖于容易出错的角点检测方法。
从一对图像估计 2D 单应性(或投影变换)是计算机视觉中的一项基本任务。 在以下场景中,单应性是单目 SLAM 系统的重要组成部分:
仅旋转运动、平面场景、物体离观察者很远的场景。
众所周知,关于两个围绕相机中心旋转的图像的变换是单应性,单应性对于创建全景图是必不可少的也就不足为奇了。 为了处理平面和大部分平面场景,流行的 SLAM 算法 ORBSLAM 结合使用单应性估计和基本矩阵估计。 基于平面结构和单应性的增强现实应用已得到充分研究。 使用平面结构的相机校准技术也依赖于单应性。
传统的单应性估计流水线由两个阶段组成:角点估计和鲁棒单应性估计。通过返回大量且过完整的点集将鲁棒性引入角点检测阶段,而单应性估计步骤的鲁棒性表现为大量使用 RANSAC 或平方损失函数的鲁棒性。由于拐角不如人造线性结构可靠,因此研究界已投入大量精力将线特征和更复杂的几何图形添加到特征检测步骤中。我们真正想要的是一个强大的算法,给定一对图像,简单地返回与这对图像相关的单应性。 算法是否可以学习自己的一组原语,而不是手动设计角点特征、线特征等? 我们想更进一步,将变换估计步骤添加为深度学习管道的最后一部分,从而使我们能够以端到端的方式学习整个单应性估计管道。
最近对密集或直接无特征 SLAM 算法(如 LSD-SLAM)的研究表明,有望将完整图像用于几何计算机视觉任务。同时,深度卷积网络正在为图像分类、语义分割和人体姿态估计等语义任务设定最先进的基准。此外,最近的工作如 FlowNet、Deep Semantic Matching 和 Eigen 等人的多尺度深度网络为密集几何计算机视觉任务(如光流和深度估计)提供了有希望的结果。 甚至像视觉里程计这样的机器人任务也正在使用卷积神经网络来解决。
在论文中,展示了整个单应性估计问题可以通过深度卷积神经网络来解决(见下图)。

论文的贡献如下:为单应性估计任务提出了一个新的 VGG 风格的网络。展示了如何使用4点参数化来获得表现良好的深度估计问题。由于深度网络需要从头开始训练大量数据,因此我们分享了创建看似无限的 (,
,
) 数据集的秘诀。从现有的真实图像数据集(如 MS-COCO 数据集)训练三元组。我们提出了单应性估计问题的附加公式作为分类,它产生单应性分布,可用于确定估计单应性的置信度。
二、4点HOMOGRAPHY参数化
参数化单应性的最简单方法是使用 3x3 矩阵和固定比例。 单应映射 [u,v],左侧图像中的像素,到[,
],右侧图像中的像素,并按比例定义(参见公式 1)。

但是,如果我们将单应性的 8 个(或 9 个)参数展开到单个向量中,我们很快就会意识到我们正在混合旋转项和平移项。 例如,子矩阵 [;
],表示单应性中的旋转项,而向量 [
] 是平移偏移量。 作为优化问题的一部分,平衡旋转项和平移项是很困难的。
我们发现基于单一类型位置变量(即角点位置)的替代参数化更适合我们的深度单应性估计任务。 4 点参数化已用于传统的单应性估计方法中,我们将其用于现代的单应性估计问题的深度表现(见图 2)。 令 为第一个角的 u 偏移,4 点参数化表示非同应性如下:

等效于单应性的矩阵公式,4 点参数化使用八个数字。 一旦知道四个角的位移,就可以轻松地将 转换为
。 这可以通过多种方式实现,例如可以使用归一化直接线性变换 (DLT) 算法或 OpenCV 中的函数 getPerspectiveTransform()。
三、Homography 估计的数据生成
从头开始训练深度卷积网络需要大量数据。 为了满足这一要求,我们通过将随机投影变换应用于自然图像的大型数据集来生成几乎无限数量的标记训练示例。 该过程如图 3 所示,并在下文进行描述。
为了生成单个训练示例,我们首先在位置 p 处从较大的图像 I 中随机裁剪一个正方形补丁(我们避免边界以防止稍后在数据生成管道中出现边界伪影)。这个随机裁剪是 。然后,补丁 A 的四个角被 [-p, p] 范围内的值随机扰动。这四个对应关系定义了一个单应性
。 然后,将这个单应性的逆
应用于大图像以产生图像
。 第二个补丁
从位置 p 的
裁剪。然后将两个灰度补丁
和
逐通道堆叠以创建直接馈入我们的 ConvNet 的 2 通道图像。 然后将 HAB 的 4 点参数化用作相关的真实训练标签。
管理训练图像生成管道使我们能够完全控制我们想要建模的视觉效果的种类。例如,为了使我们的方法对运动模糊更加鲁棒,我们可以将这种模糊应用于训练集中的图像。如果我们想要 为了对遮挡具有鲁棒性,我们可以将随机遮挡形状插入到训练图像中。 我们尝试在训练图像中绘制随机遮挡矩形,作为模拟真实遮挡的简单机制。
在实验中,使用裁剪后的 MS-COCO 图像,尽管任何足够大的数据集都可以用于训练

四、卷积网络模型
我们的网络使用具有 Batch-Norm 和 ReLU 的 3x3 卷积块,并且在架构上类似于 Oxfords VGG Net。两个网络都将大小为 128x128x2 的双通道灰度图像作为输入。 换句话说,通过单应性关联的两个输入图像按通道堆叠并馈入网络。我们在每两个卷积之后使用 8 个卷积层和一个最大池化层(2x2,步长 2)。 8 个卷积层每层的滤波器数量如下:64、64、64、64、128、128、128、128。卷积层后面是两个全连接层。 第一个全连接层有 1024 个单元。 在最后一个卷积层和第一个全连接层之后应用概率为 0.5 的 Dropout。 我们的两个网络在最后一层共享相同的架构,其中第一个网络产生实值输出,第二个网络产生离散量(见图 4)。

回归网络直接产生 8 个实值数字,并在训练期间使用欧几里德 (L2) 损失作为最后一层。 这个公式的优点是简单; 然而,在不产生任何类型的预测置信度值的情况下,这种直接方法在某些应用中可能会令人望而却步。
模型核心参考代码如下:
from keras.models import Sequential
from keras.layers import Activation, Dense, Dropout, Conv2D, MaxPooling2D, Flatten, BatchNormalization, InputLayer
from keras.callbacks import ModelCheckpoint
from keras import backend as K
from keras import optimizers
import tensorflow as tf
# Dataset-specific
train_data_path = 'dataset/training'
test_data_path = 'dataset/test'
samples_per_archive = 9216
num_archives = 40
# 43 archives x 9,216 samples per archive, but use just 40 and save the 3 for testing
num_samples = num_archives * samples_per_archive
# From the paper
batch_size = 64
total_iterations = 90000
steps_per_epoch = num_samples / batch_size # As stated in Keras docs
epochs = int(total_iterations / steps_per_epoch)
input_shape = (128, 128, 2)
kernel_size = 3
pool_size = 2
filters = 64
dropout = 0.5
model = Sequential()
model.add(InputLayer(input_shape))
model.add(Conv2D(filters=filters,\
kernel_size=kernel_size, activation='relu', padding='same'))
model.add(BatchNormalization())
model.add(Conv2D(filters=filters,\
kernel_size=kernel_size, activation='relu', padding='same'))
model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size))
model.add(Conv2D(filters=filters,\
kernel_size=kernel_size, activation='relu', padding='same'))
model.add(BatchNormalization())
model.add(Conv2D(filters=filters,\
kernel_size=kernel_size, activation='relu', padding='same'))
model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size))
model.add(Conv2D(filters=filters*2,\
kernel_size=kernel_size, activation='relu', padding='same',))
model.add(BatchNormalization())
model.add(Conv2D(filters=filters*2,\
kernel_size=kernel_size, activation='relu', padding='same',))
model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size))
model.add(Conv2D(filters=filters*2,\
kernel_size=kernel_size, activation='relu', padding='same',))
model.add(BatchNormalization())
model.add(Conv2D(filters=filters*2,\
kernel_size=kernel_size, activation='relu', padding='same',))
model.add(BatchNormalization())
model.add(Flatten())
model.add(Dropout(dropout))
model.add(Dense(1024, activation='relu'))
model.add(Dropout(dropout))
#for regression model
model.add(Dense(8))
#model.add(Activation('softmax'))
model.summary()
#use optimizer Stochastic Gradient Methond with a Learning Rate of 0.005 and momentum of 0.9
#sgd = optimizers.SGD(lr=0.005, momentum=0.9, decay=0.001355)
sgd = optimizers.SGD(lr=0.005, momentum=0.9)
#compile model
model.compile(loss=euclidean_l2,\
optimizer=sgd, metrics=['mean_squared_error'])
#check point
filepath = "checkpoints/weights-{epoch:02d}-{loss:.2f}.hdf5"
checkpoint = ModelCheckpoint(filepath, monitor='loss', verbose=1)
callback_list = [checkpoint]
# Train
print('TRAINING...')
model.fit_generator(data_loader(train_data_path, batch_size),
steps_per_epoch=steps_per_epoch,
epochs=epochs, callbacks=callback_list)分类网络使用量化方案,在最后一层有一个 softmax,我们在训练时使用交叉熵损失函数。 虽然量化意味着存在一些固有的量化误差,但网络能够为该方法产生的每个角点产生置信度。 我们选择对 8 个输出维度中的每一个使用 21 个量化箱,这导致最终层具有 168 个输出神经元。下图是我们的方法产生的角点置信度的可视化 - 请注意所有角点的置信度是不相等的。

五、实验
使用动量为 0.9 的随机梯度下降 (SGD) 在单个 Titan X GPU 上训练我们的两个网络大约 8 小时。 使用 0.005 的基本学习率,并在每 30,000 次迭代后将学习率降低 10 倍。 使用 64 的批大小对网络进行了 90,000 次总迭代的训练。使用流行的开源深度学习包 Caffe 进行所有实验。
为了创建训练数据,我们使用 MS-COCO 训练集。 所有图像都调整为 320x240 并转换为灰度。 然后,我们使用第三节中描述的方法生成 500,000 对大小为 128x128 的图像块,这些块通过单应性相关联。 我们选择,这意味着128x128灰度图像的每个角落最多可以被图像总边缘尺寸的四分之一扰动。 我们避免较大的随机扰动以避免极端转变。 我们没有使用任何形式的预训练; 网络的权重被初始化为随机值并从头开始训练。 我们使用 MS-COCO 验证集来监控过度拟合,我们发现的很少。
据我们所知,没有大型的、公开可用的单应性估计测试集,因此我们在我们自己的 Warped MS-COCO 14 测试集上评估我们的单应性估计方法。 为了创建这个测试集,我们从测试集中随机选择了 5000 张图像,并将每个图像的大小调整为 640x480 灰度,并使用图 3 中描述的方法和生成一对大小为 256x256的图像块和相应的地面实况单应性 .
我们将 HomographyNet 的分类和回归变体与两个基线进行比较。 第一个基线是经典的 ORB 描述符 + RANSAC + getPerspectiveTransform() OpenCV Homography 计算。我们在传统的单应性估计器中使用默认的 OpenCV 参数。 这会在多个尺度上估计 ORB 特征,并使用前 25 个得分匹配作为 RANSAC 估计器的输入。在计算的 ORB 特征太少的情况下,ORB+RANSAC 方法会输出身份估计。 在 ORB+RANSAC 的估计过于极端的情况下,4 点单应性估计被裁剪为 [-64,64]。 第二个基线对测试集中的每对图像使用 3x3 单位矩阵。
由于 HomographyNets 需要固定大小的 128x128x2 输入,因此来自 Warped MS-COCO 14 测试集的图像对在通过网络之前从 256x256x2 调整为 128x128x2。 然后将网络输出的 4 点参数化单应性乘以 2 以解决此问题。 在评估分类 HomographyNet 时,选择置信度最高的角位移。
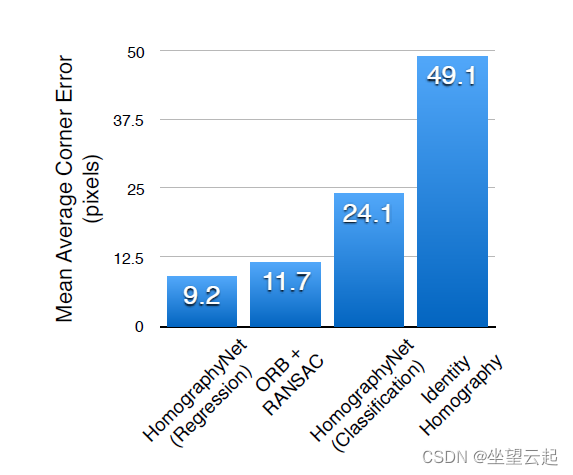
结果如图 5 所示。我们报告了每种方法的平均角误差。 为了测量这个度量,首先计算地面实况角位置和估计的角位置之间的 L2 距离。 误差在图像的四个角上进行平均,并在整个测试集上计算平均值。 虽然回归网络表现最好,但分类网络可以产生置信度,因此是可视化调试结果的一种有意义的方式。 在某些应用中,具有这种确定性度量可能是至关重要的。
我们在下图中可视化单应性估计。第 1 列中的蓝色方块通过第三节中描述的过程生成的随机单应性映射到第 2 列中的蓝色四边形。 绿色四边形是估计的单应性。 蓝色和绿色四边形排列得越紧密越好。 红线显示图像块中 ORB 特征的得分最高的匹配。 类似的可视化显示在第 3 列和第 4 列中,但使用了深度单应性估计器。
下面图片是传统单应性估计与深度图像单应性估计对比。 在 12 个示例中的每一个中,蓝色都描绘了ground truth 区域。 左列显示基于 ORB 的 Homography Estimation 的输出,红色显示匹配的特征,绿色显示裁剪的结果映射。 右列以绿色显示 HomographyNet(回归头)的输出。 第 1-2 行:ORB 特征要么集中在小区域,要么无法检测到足够的特征,并且相对于不受这些现象影响的 HomographyNet 表现不佳。 第 3 行:两种方法都给出了相当好的单应性估计。 第 4 行:在第 3 行的图像对中添加了少量高斯噪声,使传统方法产生的结果变差,而我们的方法不受失真的影响。 第 5-6 行:传统方法提取分布良好的 ORB 特征,并且优于深度方法。



六、应用
我们的深度单应性估计系统支持各种有趣的应用。 首先,我们的系统很快。 它在 NVIDIA Titan X GPU 上以超过 300 fps 的速度运行,批量大小为 1(即实时推理模式),这使得许多应用程序在更慢的系统中根本无法实现。 最近出现的用于深度网络的专用嵌入式硬件将使许多嵌入式系统或平台上的应用程序具有有限的计算能力,而这些计算能力无法负担昂贵且耗电的桌面 GPU。 这些嵌入式系统能够实时运行更大的网络,例如 AlexNet,并且运行相对轻量级的 HomographyNets 应该没有问题。
其次,通过将单应性估计公式化为机器学习问题,可以构建特定于应用程序的单应性估计引擎。 例如,使用平面 SLAM 通过单应性估计导航室内工厂车间的机器人可以仅使用从室内工厂的机器人图像传感器捕获的图像进行训练。虽然可以优化诸如 ORB 之类的特征检测器以在特定环境中工作,但它是 并不简单。环境和传感器特定的噪声、运动模糊和遮挡可能会限制单应性估计算法的能力,可以使用 ConvNet 以类似的方式解决。 其他经典的计算机视觉任务,例如用于增强现实的图像拼接和无标记相机跟踪系统,也可以从基于目标系统传感器和环境创建的图像对示例训练的 HomographyNets 中受益。
在论文中,提出了两种能够很好地完成单应性估计这项任务的卷积神经网络架构。 我们的端到端训练管道包含使用单应性的4点角参数化,这使得参数化坐标在相同的尺度上运行,以及使用大型真实图像数据集综合创建看似无限大小的训练集用于单应性估计。我们希望通过学习来解决视觉中的更多几何问题范式。