当我们在说性能的时候,我们在谈些什么?
衡量性能有两个指标:
在保持服务器资源配置不变的情况下,增加额定的访问量,会给系统带来多大的影响,比如影响了读取时间,写入时间等等。
在增加额定的访问量的情况下,要增加多少服务器资源,才能使其保持平日里的性能
这两个指标是基于服务架构来衡量的,要么在现有技术服务架构下,提出的衡量标准,要么基于未来的访问量,提出的架构设计。所以暂时这两个都不谈,也没有水平来谈。我们先看看性能中,能拿出来谈论的概念。
Latency VS Response Time
Latency 延迟,与 Reponse Time 响应时间,并不是同一个概念。Latency 是等待处理的时间,越小越好;Reponse Time 除了 Latency 时间,还有网络传输时间,有前后台进程切换的等待时间,有排队等待处理的时间, 它的范围更广。
衡量 Response Time 最好的技术指标 - Percentile
为什么说平均数不是个好的衡量指标?而想要更好的描述性能问题,就需要percentile.
比如我们有 7 次访问,每次的响应时间是 1,2,3,4,5,5,6
平均数是 (1 + 2 + 3 + 4 + 5 +5 +6)/7 是3.7. 中位数是 4.
那么按照平均数的算法为基准,会有 4 条记录不符合条件,也就是4个用户收到了影响,而按照中位数的算法,那么只有 3 条记录是不符合记录,也就是 3 个用户的访问收到了影响。
以下这张图就能说明问题:
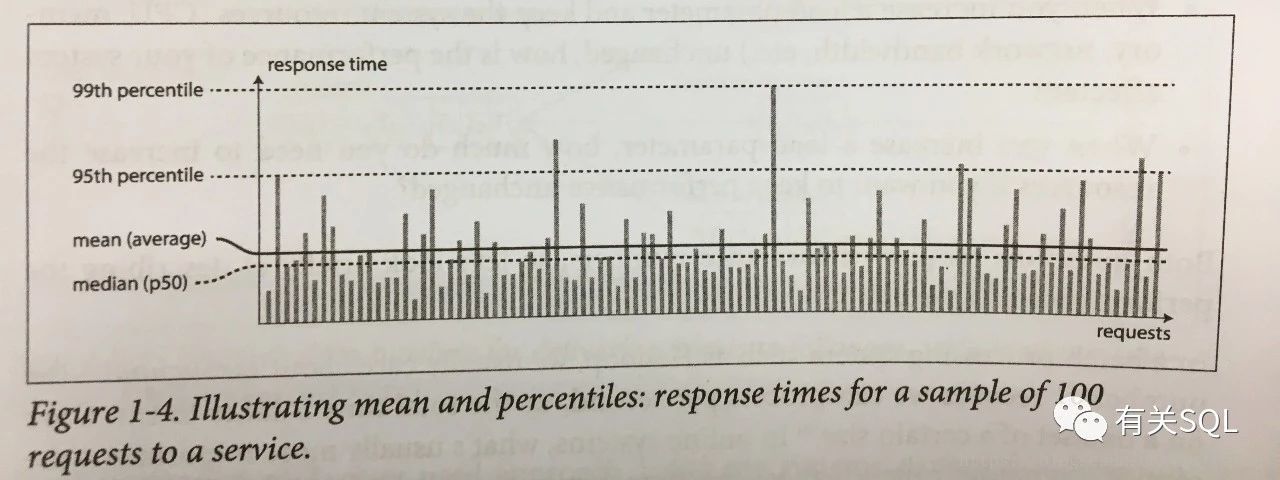
横轴是代表一个个请求,纵轴代表的是请求响应的时间,其长度越长,响应时间也就越长。median 是按照响应时间从短到长排序之后,得到的中位数。也就是50%的请求响应时间都是在这个中位数一下的,也记做 50 percentile (p50). 如果响应时间是 2s, 那么有 50% 的请求,响应时间都在 2s 以下。再看一个 99th percentile 的纵轴线,如果它的响应时间是 5s, 那么说明有 99% 的请求,响应时间都是在 5s 以下,有1% 的请求,响应在5s以上。
计算出这些统计值之后,我们可以对外做出 SLA (Service Level Agreement), SLO(Service Level Object) 的承诺, 比如 全年请求响应时间达到 2s 的比例大于 99.99%,即服务请求的时间在99%的情况下,都是2s内给到客户端反映。
影响 Response Time 的两个异常方面 - 头部阻塞与长尾效应
头部阻塞 Head-of-line blocking:
明明有时候我们的请求并不是十分耗资源,需要的数据也不多,为什么还是那么慢?CPU 就那么多核,一旦被处理慢的请求先占了,那么其他无论都快的请求过来,都会被阻塞或者排队。所以理论上很快的请求,偶尔情况下,也变得非常慢。
长尾效应 The tail at scale :
有时候一个请求会分成多个后台服务来处理,那么基于多个后台服务也会有各自处理的时间差,整个请求的响应时间就取决于处理最慢的后台服务。