前言
目前每当我们聊到当下热门的计算引擎的时候,无一例外地会聊到Apache Flink:当下非常火热的流处理计算框架。更是有人拿它和Spark做对比,到底哪个才是现今最好的计算引擎。当然这个已经不是本文所要阐述的主题啦。老实话,笔者本人做的比较多的还是存储领域,对计算领域的知识不敢说是内行。最近也是抽空学习了下Flink的一些概念体系,来分享分享笔者的一个学习心得吧。
Apache Flink到底是什么
Apache Flink是一个计算框架,更准确地来说,它是一个处理有界/无界数据流的计算处理框架。类似于Apache Spark框架,它的计算处理过程也是在内存中做加速计算的。
有界、无界数据流
在Flink的流处理过程中,我们会经常提到有界,无界的数据流概念。那么什么叫做有界/无界的数据流呢?
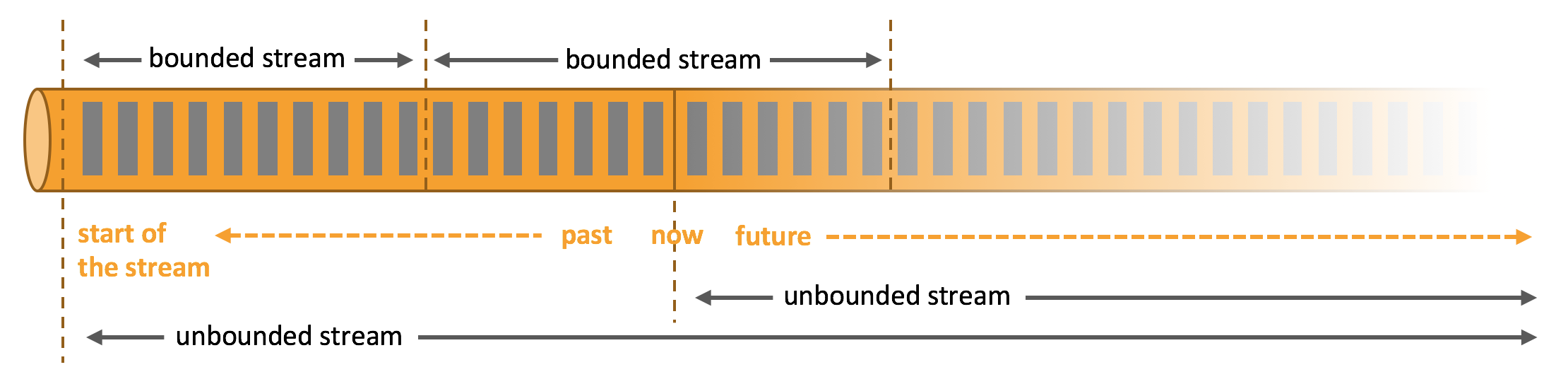
无界数据流(Bounded Stream):一个数据流,拥有开始而没有结尾的定义,我们称这种数据流为无界数据流。这种数据流一旦产生,就不会停止,而且需要被连续不断地被处理。
有界数据流(Unbounded Stream):一个“有头有尾”的数据流。在有界数据流中,有序并不是一个必须的要求。因为当我们接受到一批数据后,还是可以对其做排序的。作为一个有头有尾的数据流,我们可以把它理解为一段有固定大小的数据集合,那么对于有界数据流的处理来说,它完全可以类似于我们平常所说的批处理。
在一段流数据中,有界和无界数据流的概念如下图所示:
Flink内存加速处理优化
和Spark类似,Flink同样利用内存来进行计算过程的加速,进一步地保证数据计算的低延时性。另外,为了保证Flink错误恢复的一致性,Flink将一些状态数据进行了持久化外部存储的操作(定期checkpoint操作),如下图所示。
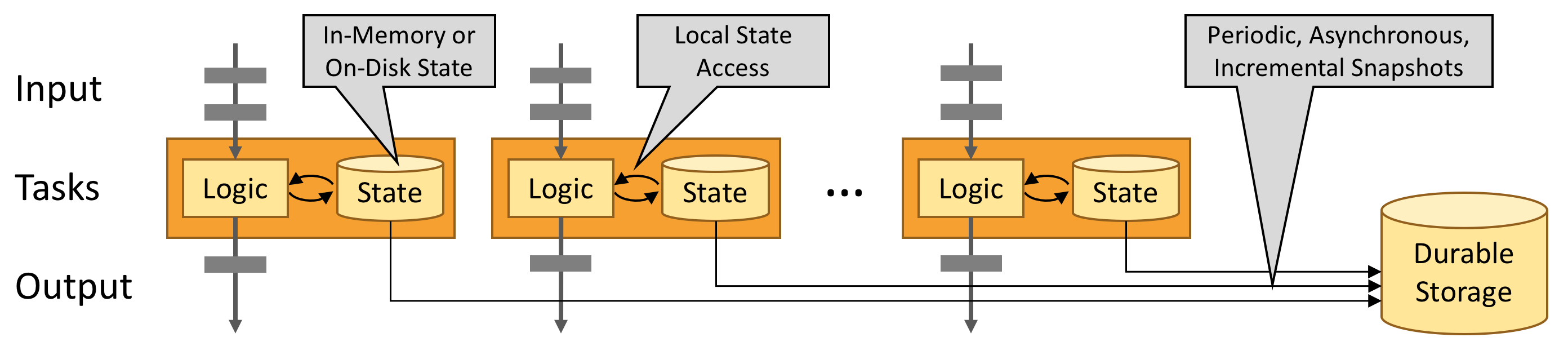
Flink的状态处理
为了保证流计算任务的失败恢复,Flink内部对这块做了很多的工作,包括可插拔的状态后端存储,Exactly-Once语义保证的checkpoint恢复,支持大规模量级的状态存储。
Flink的数据流模型
下面我们来深入Flink框架内部,对内部的数据流模型做进一步地了解。
在数据处理的抽象层面,Flink内部实现了4个层级的抽象,供用户使用选择,如下图所示:
不同层级对应的使用方法的操作抽象程度各为不同,比如越低层级的操作方法,使用粒度可以做到做精细,但是使用起来不是很方面,学习成本相应也会较高。由比如说最高级别的SQL级别,用户使用起来就会很简单,通过标准的SQL标准语句,也能轻松构建出Flink任务了。
Flink的流处理过程
在Flink的普通任务过程中,一般 分为3个模块:
- 数据源头,Source源。
- 数据处理,ProcessFunction,也可以理解为此为计算转换过程。
- 数据结果输出,Sink端。
图示结果如下:

Window在Flink流处理过程中的应用
在流处理的场景中,我们经常会碰到分段汇总统计的需求,比如说分小时的pv/uv统计。Flink提供了Window窗口的概念来做这样的处理。对于分时段的统计来说,我们可以用时间窗口来做这样的数据处理,当然还有一种是基于记录数的窗口。每当当前窗口过去,此窗口的计算结果值被记录了下来,然后程序开始进行下一个窗口结果的计算。通过Flink内部设计的窗口来做这样的运算后,就无须用户来做时间分段的复杂逻辑控制了。至于窗口的具体实现原理,可以阅读Flink官网对此的介绍。Flink的窗口处理效果如下所示,上面是基于时间的窗口划分,下面是基于fixed-size的窗口,整体是自左向右的不间断的流数据。
Flink的适用场景
相比于传统的数据分析应用来说,采用的方式往往式批处理的,周期性的执行分析任务。而对于Flink来说,它的实时数据流的处理,能够做到更低的延时和高的吞吐量,再加上它的checkpoint的容错恢复机制。Flink方式的任务具有很好的稳定性。
一个典型的数据分析的使用场景,传统方式和以Flink的计算处理方式
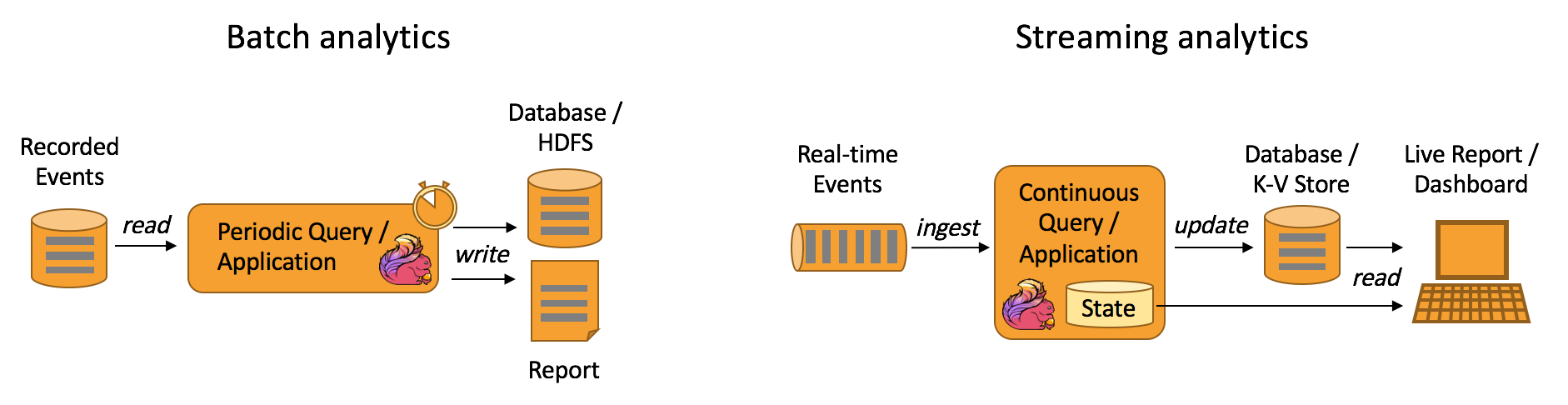
又或者,我们可以利用Flink框架低延时,高吞吐量的特点,来做一些ETL(数据抽取转换)任务。Flink在新版本中已经能够多类型Source源的connect,这样的话,我们完全也利用Flink来做这样的工作。下面是传统方式ETL和Flink方式下的比较。
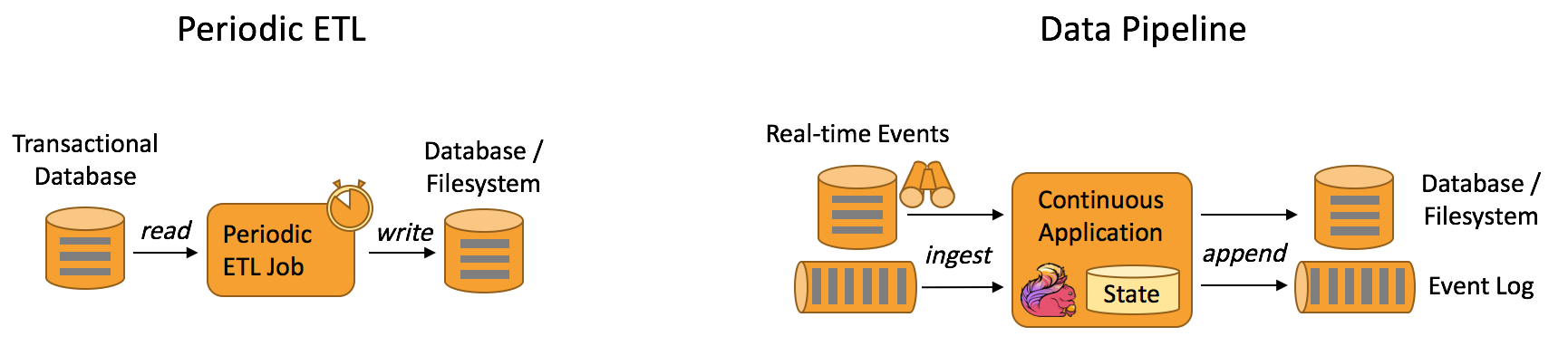
说了这么多,笔者并不是鼓吹说Flink都是万能的,传统批处理任务也有它自己的合适使用的地方。只是说,Flink的出现,将会使得我们能够更加灵活地进行技术的选型,来匹配实际的生产环境。
引用
[1].https://flink.apache.org/flink-architecture.html
[2].https://flink.apache.org/usecases.html
[3].https://ci.apache.org/projects/flink/flink-docs-release-1.7/concepts/programming-model.html