
1 PNASNet模型简介
PNASNet模型是Google公司的AutoML架构自动搜索所产生的模型,它使用渐进式网络架构搜索技术,并通过迭代自学习的方式,来寻找最优网络结构。即用机器来设计机器学习算法,使得它能够更好地服务于用户提供的数据。该模型在ImageNet数据集上Top-1准确率达到82.9%,Top-5准确率达到96。2%,是目前最好的图片分类模型之一。
PNASNet模型最主要的结构是Normal Cell和Reduction Cell(参见arXⅳ网站上编号为1712.00559的论文),NASNet模型的主要结构使用残差结构和多分支卷积技术,还添加深度可分离卷积(组卷积的一种特殊形式)和空洞卷积的处理。
2 组卷积
组卷积是指对原有的输入数据先分组,再做卷积操作。不但能够增强卷积核之间的对角相关性且减少训练参数,不易过拟合,类似于正则效果。AlexNet模型使用了组卷积技术。
2.1 组卷积的操作规则
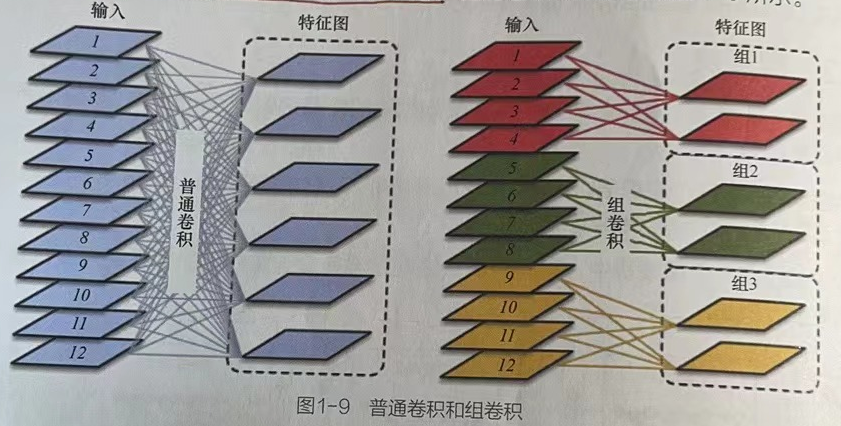
2.1.1 普通卷积和组卷积的不同
普通卷积和组卷积最大的不同就是卷积核在不同通道上卷积后的操作。
普通卷积是用卷积核在各个通道上进行卷积求和,所得的每一个特征图都会包含之前各个通道上的特征信息。
组卷积是按照分组来进行卷积融合操作,在各个分组之间进行普通卷积后融合,融合生成的特征图仅包含其对应分组中所有通道的特征信息。
2.2 代码实现组卷积
2.2.1 代码实现
import torch
input1 = torch.ones([1,12,5,5])
groupsconv = torch.nn.Conv2d(in_channels=12,out_channels=6,kernel_size=3,groups=3) # 定义组卷积,输入输出通道必须是groups的整数倍
Group_convolution = groupsconv(input1)
print("查看组卷积的卷积核的形状",groupsconv.weight.size()) # torch.Size([6, 4, 3, 3])
print("查看组卷卷积的结果形状:",Group_convolution.size()) # torch.Size([1, 6, 3, 3])
conv = torch.nn.Conv2d(in_channels=12,out_channels=6,kernel_size=3,groups=1) # 定义普通卷积
Ordinary_convolution = conv(input1)
print("查看普通卷积的卷积核的形状",conv.weight.size()) # torch.Size([6, 12, 3, 3])
print("查看普通卷积的结果形状:",Ordinary_convolution.size()) # torch.Size([1, 6, 3, 3])2.2.2 代码讲解
组卷积使用了6个4通道卷积核,处理过程如下
1、将输入数据的12个通道分成3组,每组4个通道。
2、将输入数据中第1组的4个通道分别与第1个4通道卷积核进行卷积操作,将4个通道的卷积结果加和,得到第1个通道的特征图。
3、将输入数据中第1组的4个通道分别与第2个4通道卷积核进行卷积操作,将第(3)步的结果按照第(2)步的方式加和,得到第2个通道的特征图。
4、将输入数据中第2组的4个通道分别与第3、4个4通道卷积核按照第(2)~(3)步操作,得到第3、4个通道的特征图。
5、将输入数据中第3组的4个通道分别与第5、6个4通道卷积核按照第(2)~(3)步操作,得到第5、6个通道的特征图。
6、最终得到6个通道的组卷积结果。
普通卷积则直接将12个通道的卷积核与12个通道的输入数据做卷积操作,并对其结果进行加和,得到第1个通道的特征图。重复5次这种操作,完成整个卷积过程。
2.3 组卷积的优缺点
2.3.1 组卷积的优势
组卷积的优势是可以减少参数数量和计算量,可以选择组卷积中的组大小来提高DNN的分类精度。
2.3.2 组卷积的劣势
在组卷积中,随意地选择组大小会导致计算复杂性和数据重用程度之间的不平衡,影响计算的效率。

3 深度可分离卷积
深度可分离卷积是指对每一个输入的通道分别用不同的卷积核卷积。
3.1 深度可分离卷积文章来源
Xception模型是Inception系列模型的统称,其使用深度可分离卷积的主要目的是将通道相关性和平面空间维度相关性进行解耦,使得在通道关系和平面空间关系上的卷积操作相互独立,以达到更好的效果。(参见arXⅳ网站上编号1610.02357的论文)。
3.2 代码实现:深度可分离卷积
3.2.1 代码简述
在深度可分离卷积中,使用参数k来定义每个输入通道对应的卷积核个数,其输出通道数为(k×输入通道数)。
3.2.2 代码实现:深度可分离卷积
# 案例:实现了k为2的深度可分离卷积,在对输入通道为4的数据进行深度可分离卷积操作时,为其每个通道匹配2个1通道卷积核进行卷积操作。
# 深度可分离卷积在实现时,直接将组卷积中的groups参数设为与输入通道in_channels相同即可。
import torch
input1 = torch.ones([1,4,5,5])
conv = torch.nn.Conv2d(in_channels=4,out_channels=8,kernel_size=3) # 定义普通卷积
depthwise_conv = torch.nn.Conv2d(in_channels=4,out_channels=8,kernel_size=3,groups=4) # 定义一个k为2的深度可分离卷积,out_channels/in_channels
Ordinary_convolution = conv(input1) # 普通卷积
print("查看普通卷积的卷积核的形状",conv.weight.size()) # torch.Size([8, 4, 3, 3])
print("查看普通卷积的结果形状:",Ordinary_convolution.size()) # torch.Size([1, 8, 3, 3])
Depthwise_convolution = depthwise_conv(input1) # 可分离深度卷积
print("查看深度可分离卷积的卷积核的形状",depthwise_conv.weight.size()) # torch.Size([8, 1, 3, 3])
print("查看深度可分离卷积的结果形状:",Depthwise_convolution.size()) # torch.Size([1, 8, 3, 3])4 空洞卷积
4.1 空洞卷积的含义
空洞卷积是针对图像语义分割问题中下采样会降低图像分辨率、丢失信息而提出的一种卷积思路。利用添加空洞扩大感受野,让原本3x3的卷积核,在相同参数量和计算量下拥有5x5或者更大的感受野,从而无需下采样。
4.2 空洞卷积的图解



4.3 空洞卷积的代码实现
4.3.1空洞卷积代码概述
空洞卷积也可以直接通过卷积类的diation参数来实现。diiation参数代表卷积核中每个元素之间的间隔,默认是1代表普通类。
4.3.2 空洞卷积的代码实现
import torch
# 1.0 准备数据
arr = torch.tensor(range(1,26),dtype=torch.float32) # 生成5×5的模拟数据
arr = arr.reshape([1,1,5,5]) # 对模拟数据进行变形
print("模拟数据:",arr)
# 模拟数据:tensor([[[[ 1., 2., 3., 4., 5.],
# [ 6., 7., 8., 9., 10.],
# [11., 12., 13., 14., 15.],
# [16., 17., 18., 19., 20.],
# [21., 22., 23., 24., 25.]]]])
# 1.1 普通卷积部分
Ordinary_Convolution = torch.nn.Conv2d(1,1,3,stride=1,bias=False,dilation=1) # 普通卷积
torch.nn.init.constant_(Ordinary_Convolution.weight,1) # 对Ordinary_Convolution的卷积核初始化
print("Ordinary_Convolution的卷积核:",Ordinary_Convolution.weight.size())
# 输出 Ordinary_Convolution的卷积核:torch.Size([1, 1, 3, 3])
ret_Ordinary = Ordinary_Convolution(arr)
print("普通卷积的结果:",ret_Ordinary)
# 输出 普通卷积的结果:tensor([[[[ 63., 72., 81.], [108., 117., 126.],[153., 162., 171.]]]], grad_fn=<ThnnConv2DBackward0>)
# 1.2 空洞卷积部分
Atrous_Convolution = torch.nn.Conv2d(1,1,3,stride=1,bias=False,dilation=2) # 空洞卷积
torch.nn.init.constant_(Atrous_Convolution.weight,1) # 对Atrous_Convolution的卷积核初始化
print("Atrous_Convolution的卷积核:",Atrous_Convolution.weight.size())
# 输出 Atrous_Convolution的卷积核:torch.Size([1, 1, 3, 3])
ret_Atrous = Atrous_Convolution(arr)
print("空洞卷积的结果:",ret_Atrous)
# 输出 空洞卷积的结果:tensor([[[[117.]]]], grad_fn=<SlowConvDilated2DBackward0>)4.4 空洞卷积的理论实现
扩张卷积/空洞卷积向卷积层引入了一个称为 “扩张率(dilation rate)”的新参数,该参数定义了卷积核处理数据时各值的间距。
换句话说,相比原来的标准卷积,扩张卷积 多了一个扩张率dilatation rate的参数,指的是kernel各点之前的间隔数量。
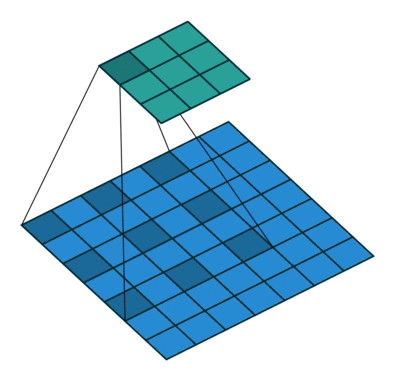
4.5 空洞卷积与普通卷积的对比
4.5.1 普通3×3卷积

4.5.2 空洞卷积(dilation rate=2的3×3卷积)
下图是一个扩张率为2的3×3卷积核,感受野与5×5的卷积核相同,而且仅需要9个参数。你可以把它想象成一个5×5的卷积核,每隔一行或一列删除一行或一列。
在相同的计算条件下,空洞卷积提供了更大的感受野。空洞卷积经常用在实时图像分割中。当网络层需要较大的感受野,但计算资源有限而无法提高卷积核数量或大小时,可以考虑空洞卷积。
4.6 空洞卷积的两大优势:
4.6.1 扩大感受野
在deep net中为了增加感受野且降低计算量,总要进行降采样,这样虽然可以增加感受野,但导致降低空间分辨率。为了不丢失分辨率,且仍然扩大感受野,可以使用空洞卷积。这在检测分割任务中空洞卷积十分有用。一方面扩大感受野可以检测分割大目标,另一方面分辨率高可以精确定位目标.
4.6.2 捕获多尺度上下文信息
空洞卷积有一个参数可以设置dilation rate,具体含义就是在卷积核中填充dilation rate个0。因此,当设置不同dilation rate时,感受野就会不一样,也即获取了多尺度信息.多尺度信息在视觉任务中相当重要。
使用空洞卷积代替下采样/上采样可以很好的保留图像的空间特征,也不会损失图像信息。当网络层需要更大的感受野,但是由于计算资源有限无法提高卷积核数量或大小时,可以考虑使用空洞卷积。
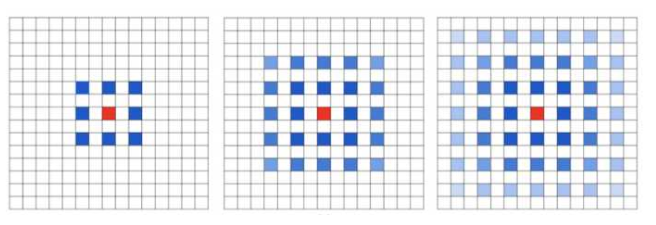
4.7 空洞卷积存在的问题:
4.7.1 网格效应
当多次叠加扩张率为2的3*3 kernel时,会产生如下问题:
4.7.2 远距离信息可能不相关
如果光采用大的扩张率的卷积可能只对一些大物体分割有效果。设计空洞卷积层的关键在于如何同时处理不同大小物体的关系。