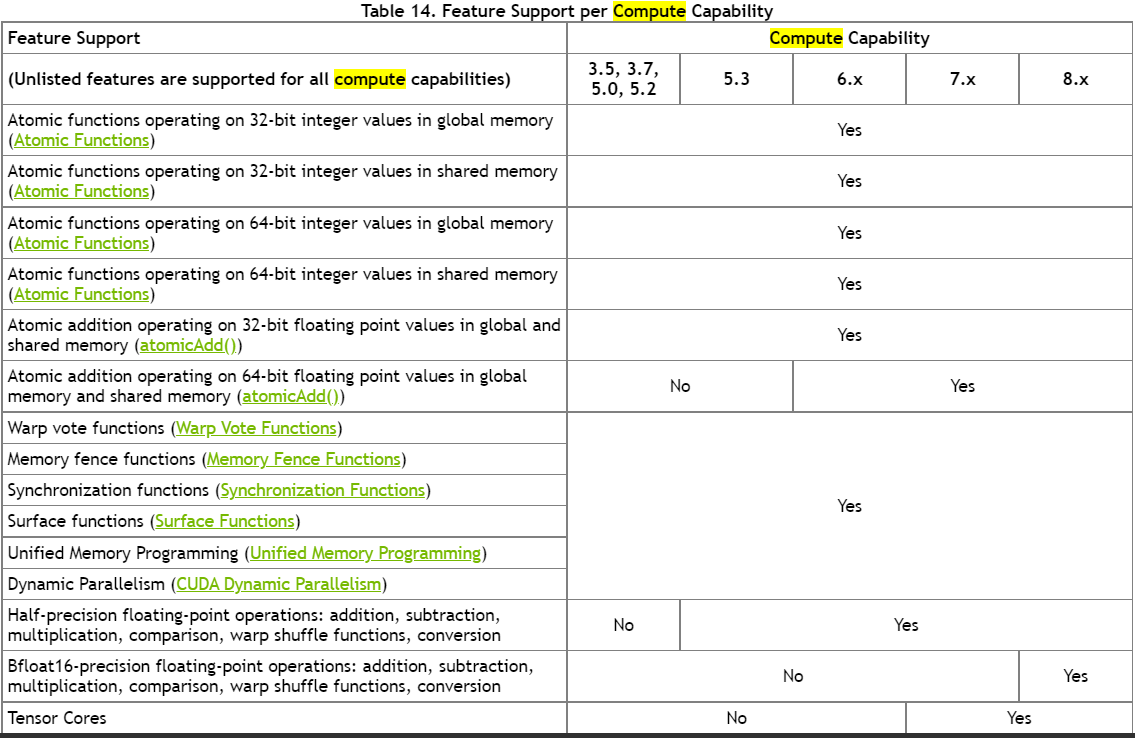
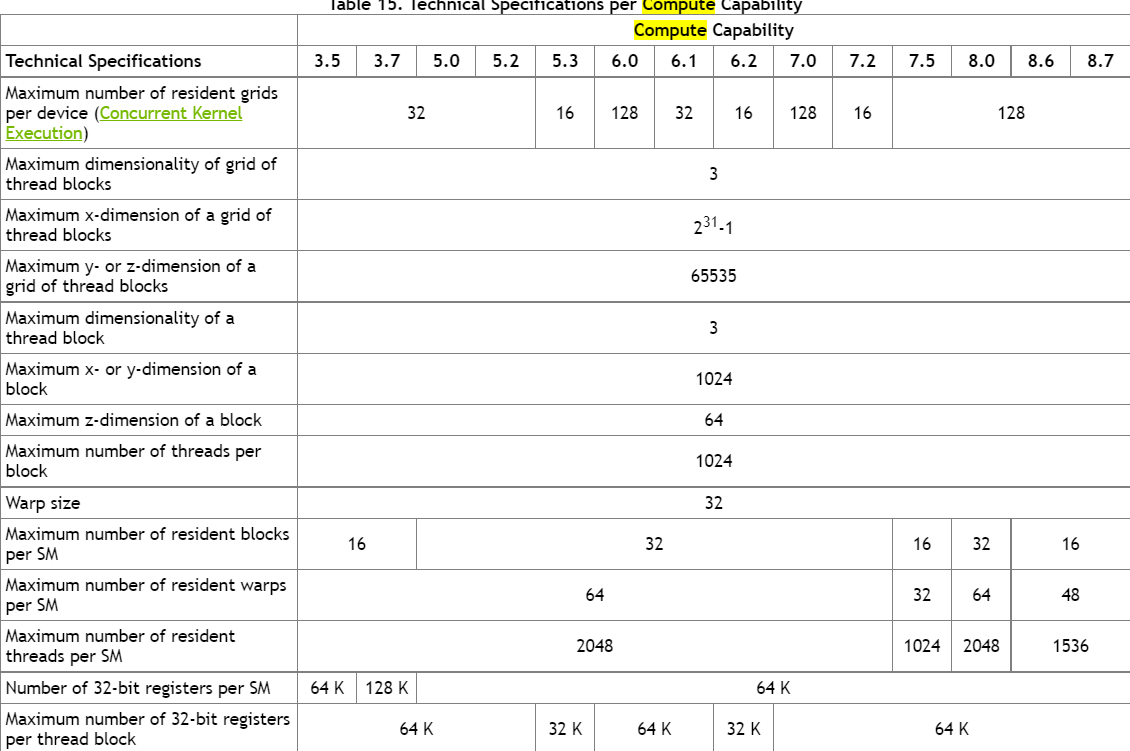
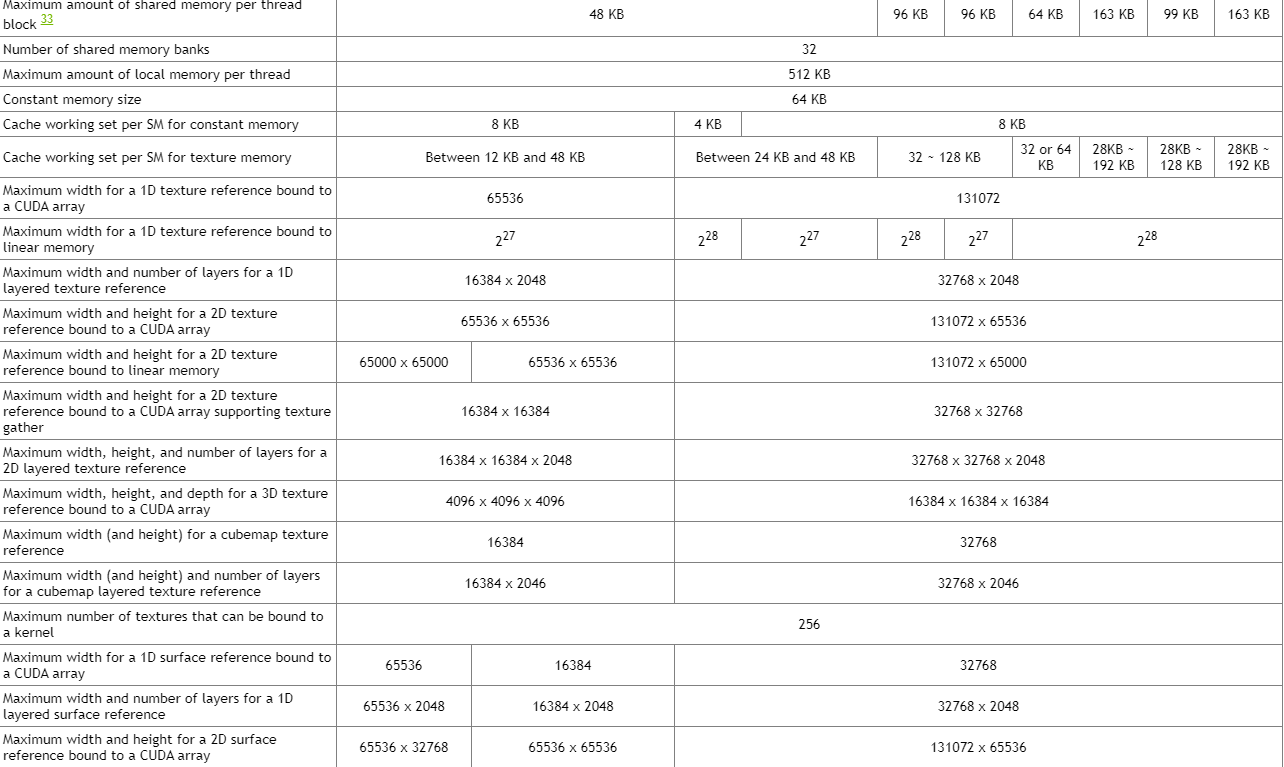
简要:
本文阐述了
1、Nvidia GPU 内存结构
2、计算能力(SM) 和架构的关系
GPU 硬件架构
GPU 可以理解为由 计算单元和内存的集合。
GPU 内存:GPU的内部存储分为片上存储和片下存储(相对于 SM);具体可细分为: 局部内存(local memory)、全局内存(global memory)、常量内存(constant memory)、图像/纹理(texture memory)、共享内存(shared memory)、寄存器(register)、L1/L2缓存、常量内存/纹理缓存(constant/texture cache)
计算单元(SM): 每一个SM都有自己的控制单元(Control Unit),寄存器(Register),缓存(Cache),指令流水线(execution pipelines)
Turing 架构实物图

下图 为 Turing 架构的 GPU 结构示意图:
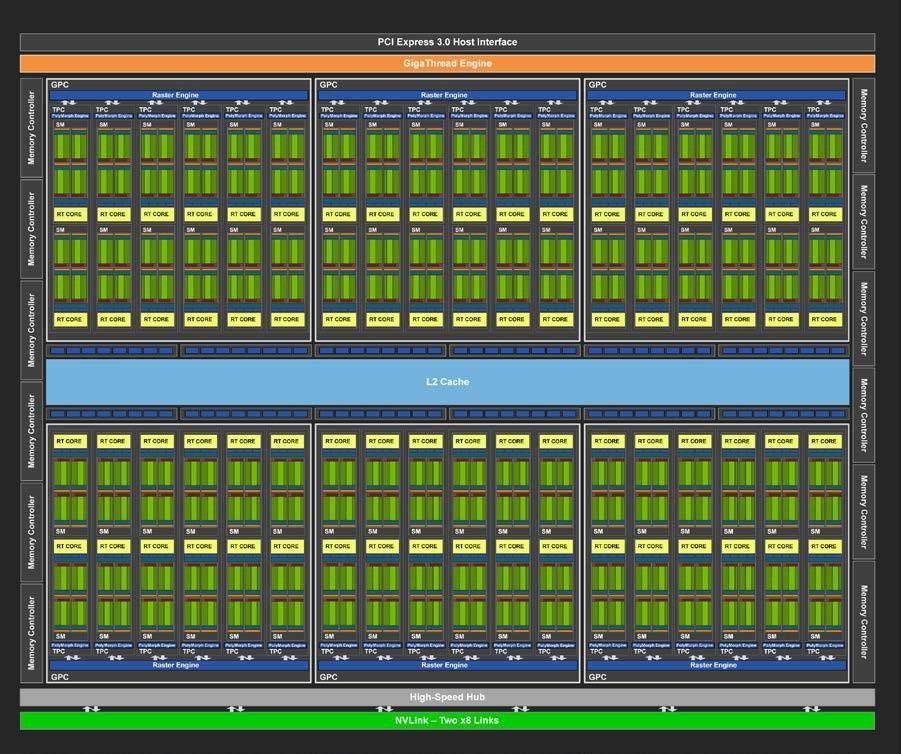
内存
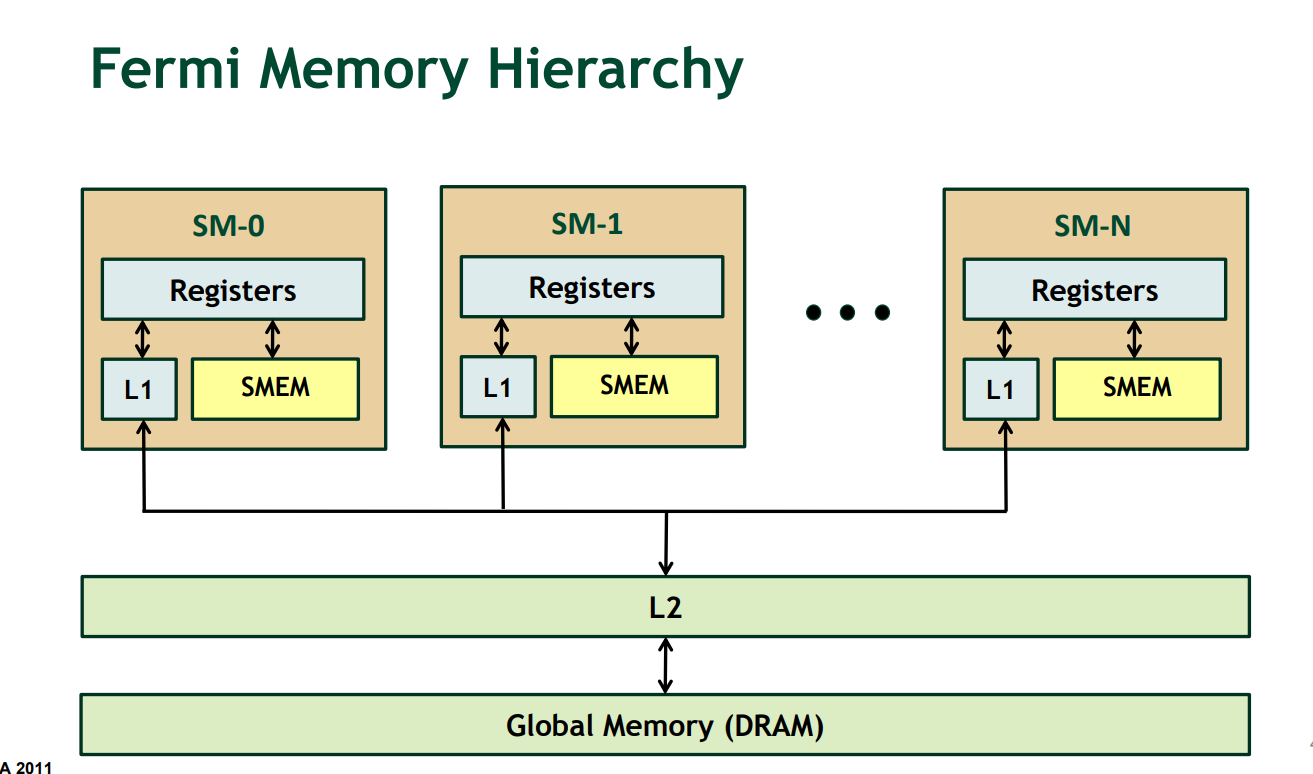
GPU 的内存机制
如下图所示,数据如果参与计算 ,那么它的流动如下:
Global memory ->L2->L1(或者其它缓存如:shared_memory 纹理等)->寄存储器(local memory)
SM (Turing 架构) 示意图
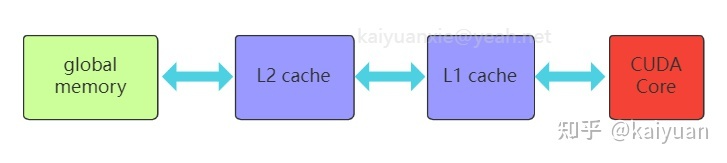
全局内存
全局内存(global memory)是数据通常用的内存,它能被设备内的所有线程访问、全局共享,为片下(off chip)内存,硬件HBM中的大部分都是用作全局内存。跟CPU架构一样,运算单元不能直接的使用全局内存的数据需要经过缓存,过程如下图所示:
cudaMalloc(&ptr, size);
cudaMallocAsync(&ptr, size,stream);
//cudaMallocAsync(&ptr, size, cudaStreamPerThread);
// do work using the allocation
//kernel<<<..., cudaStreamPerThread>>>(ptr, ...);
// An asynchronous free can be specified without synchronizing the cpu and GPU
//cudaFreeAsync(ptr, cudaStreamPerThread);
cudaMallocPitch(&devPtr, &pitch,
width * sizeof(float), height);
cudaMalloc3D(&devPitchedPtr, extent);
// Nvidia 一致致力于易用性 向 C++ STL 看齐
cudaMallocArray(&cuArray, &channelDesc, width, height);
L1/L2缓存
L2为所有SM都能访问到,速度比全局内存块,所以为了提高速度有些小的数据可以缓存到L2上面;L1为SM内的数据,SM内的运算单元能够共享,但跨SM之间的L1不能相互访问。
L2 可以被显式的使用(cuda 11 ),去优化性能
Nvida示例: Cuda 11 L2 示例
共享内存(shared memory)
共享内存是片内内存,被 SM 独享,SM 内的块所共享。
共享内存是片内存储, 和 L1的速度相当
共享内存与L1的位置、速度极其类似,区别在于共享内存的控制与生命周期管理与L1不同,共享内存的使用受用户控制,L1受系统控制,shared memory更利于block之间数据交互。
Kernel <<< * , 线程, 共享内存>>>>,kernel 执行第三个分配资源
__global__ void staticReverse(int *d, int n)
{
__shared__ int s[64]; // 分配的共享内存
int t = threadIdx.x;
int tr = n-t-1;
s[t] = d[t];
__syncthreads();
d[t] = s[tr];
}
局部内存(local memory)
局部内存(local memory) 是线程独享的内存资源,线程之间不可以相互访问,硬件位置是off chip状态,所以访问速度跟全局内存一样。局部内存主要是用来解决当寄存器不足时的场景,即在线程申请的变量超过可用的寄存器大小时,会将变量存储在局部内存中。
寄存器(register)
寄存器(register)是线程能独立访问的资源,它所在的位置与局部内存不一样,是在片上(on chip)的存储,用来存储一些线程的暂存数据。寄存器的速度是访问中最快的,但是它的容量较小。以目前最新的Ampere架构的GA102为例,每个SM上的寄存器总量256KB,使用时被均分为了4块,且该寄存器块的64KB空间需要被warp中线程平均分配,所以在线程多的情况下,每个线程拿到的寄存器空间相当小。寄存器的分配对SM的占用率(occupancy)存在影响,可以通过CUDA Occupancy Calculator 计算比较,举例:如图当registers从32增加到128时,occupancy从100%降低到了33.0。 一般 Occupancy 越高,kernel 优化的越好。
Kernel <<< * , 线程>>>>,kernel 执行第二个分配资源
常量内存(constant memory)
常量内存(constant memory) 是指存储在片下存储的设备内存上,但是通过特殊的常量内存缓存(constant cache)进行缓存读取,常量内存为只读内存。为什么需要设立单独的常量内存?直接用global memory或者shared memory不行吗?
主要是解决一个warp内多线程的访问相同数据的速度太慢的问题,如下图所示:
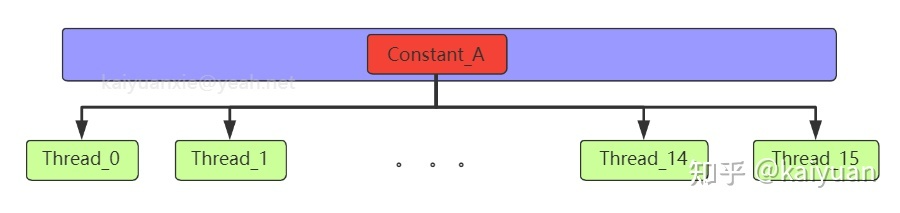
所有的运算的thread都需要访问一个constant_A的常量,在存储介质上面constant_A的数据只保存了一份,内存的物理读取方式决定了这么多thread不能在同一时刻读取到该变量,所以会出现先后访问的问题,这样使得并行计算的thread出现了运算时差。常量内存正是解决这样的问题而设置的,它有对应的cache位置产生多个副本,让thread访问时不存在冲突,从而提高并行度。
图像/纹理内存(texture memory)
图像/纹理(texture memory)是一种针对图形化数据的专用内存,其中texture直接翻译是纹理的意思,但根据实际的使用来看texture应该是指通常理解的1D/2D/3D结构数据,相邻数据之间存在一定关系,或者相邻数据之间需要进行相同的运算。 texture内存的构成包含 global + cache + 处理单元,texture为只读内存。
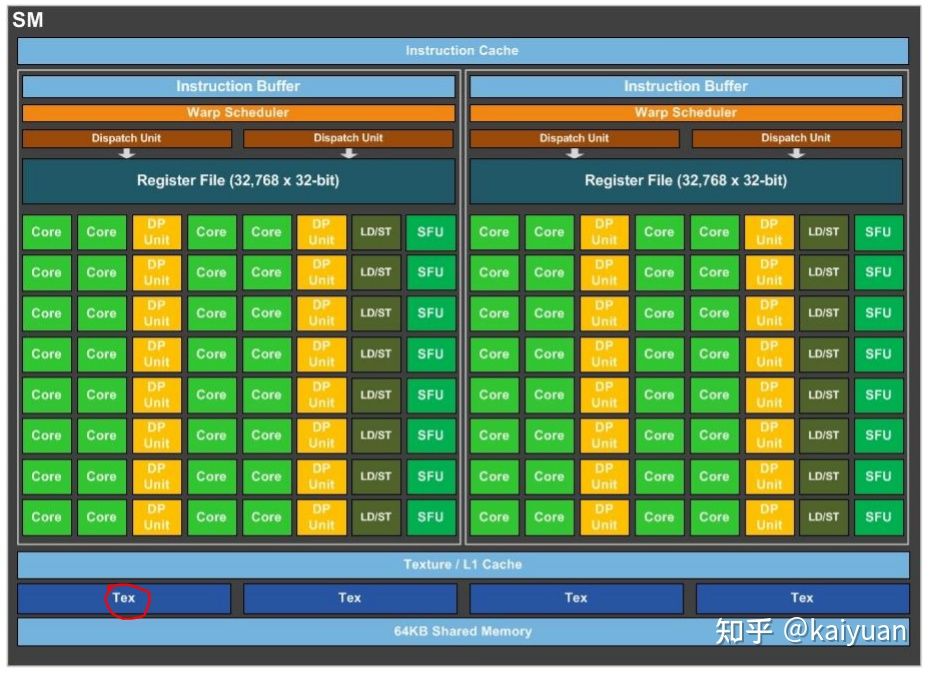
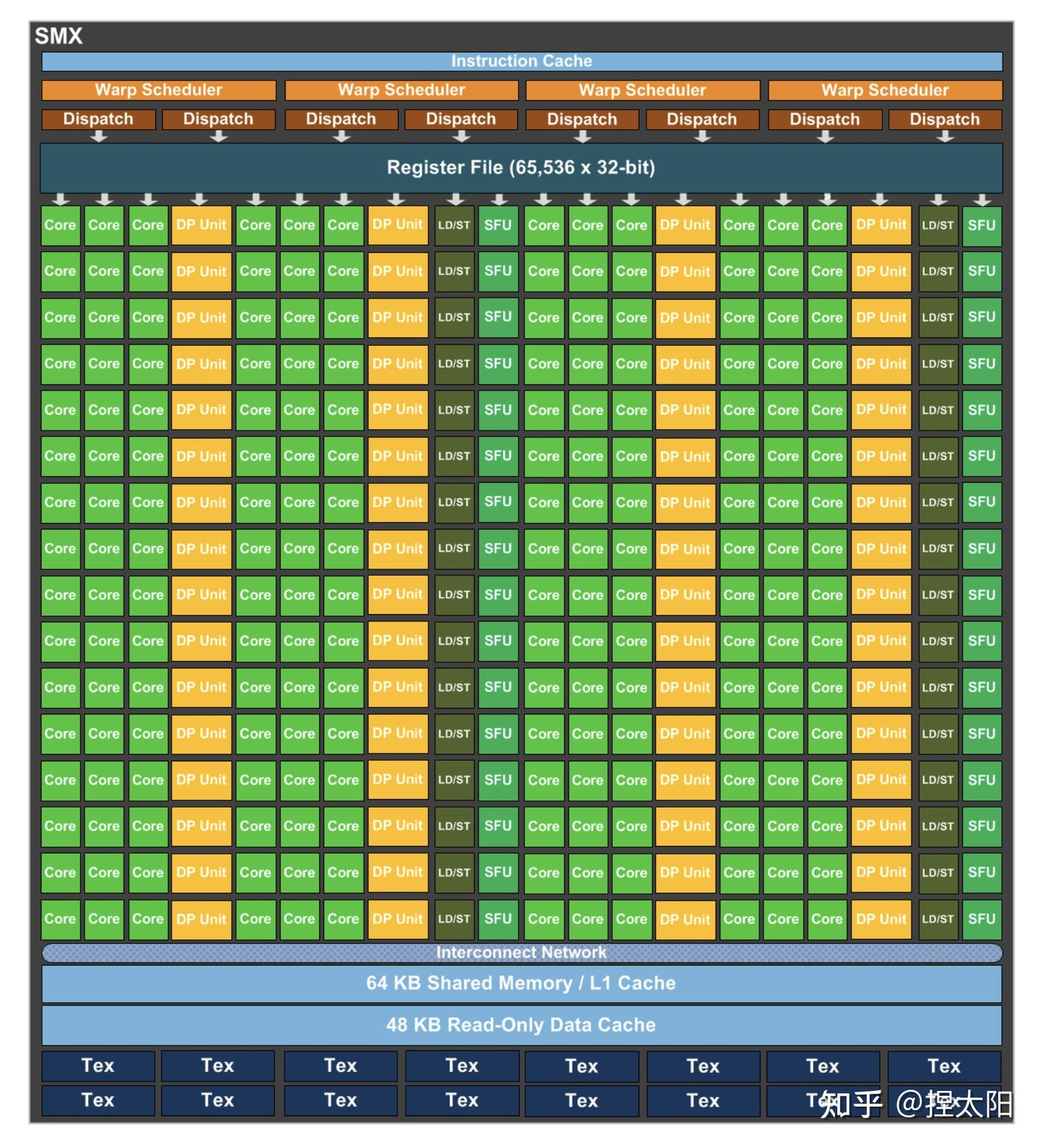
SM架构
如图所示,是一个P100显卡的SM架构,包含了四个Tex。Tex是专门用来处理texture的单元,进行数据拿取(fetch)的时候,能够在一个clock时钟内完成对数据的一些预处理。texture的优势:
- texture memory 进行图像类数据加载时, warp内的thread访问的数据地址相邻,从而减少带宽的浪费。
- texture 在运算之前能进行一些处理(或者说它本身就是运算),比如聚合、映射等。
最后放一张各个存储的对比图:
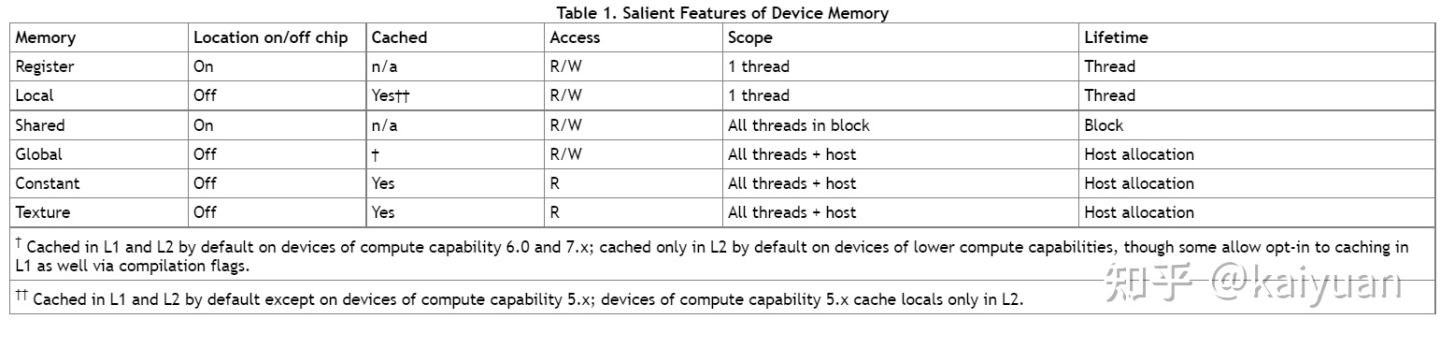
数据来源CUDA best practices
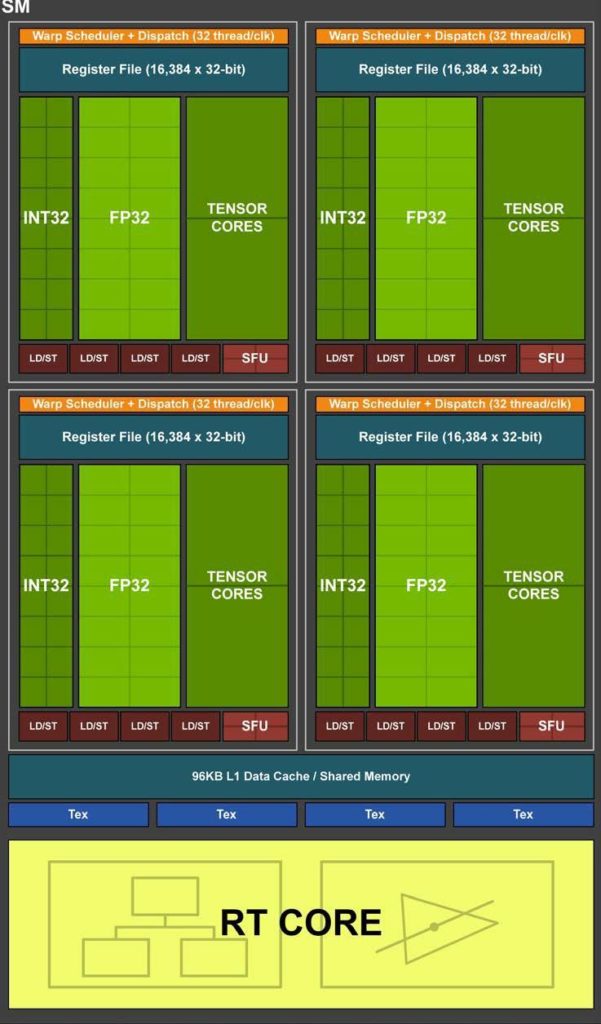
Streaming Multiprocessor (SM)
图灵 SM 被划分为四个处理块(block ),每个处理块有 16 个 FP32 核、 16 个 INT32 核、两个张量核、一个 warp 调度器和一个调度单元。每个块包括一个新的 L0 指令缓存和一个 64kb 的寄存器文件。四个处理块共享一个组合的 96kbl1 数据缓存/共享内存。传统图形工作负载将 96 KB L1 /共享内存划分为 64 KB 的专用图形着色器 RAM 和 32 KB 的纹理缓存和寄存器文件溢出区域。计算工作负载可以将 96 KB 划分为 32 KB 共享内存和 64 KB L1 缓存,或 64 KB 共享内存和 32 KB L1 缓存。
CudaCore (streaming processors)
CudaCore 又叫 SP , CudaCore 是GPU的计算单元。可以分为 FP32 、INT32 、TensorCore(这个划分不适合老版本架构的 cuda core)
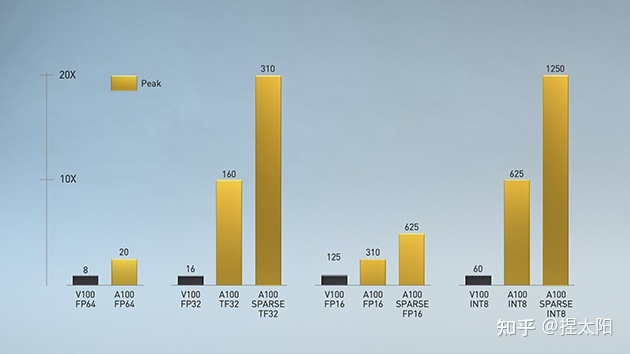
TensorCore
TensorCore 是 Nvidia 提供的特殊的计算单元,如下图所示,一个指令完成一个矩阵乘法(是硬件的加速单元)
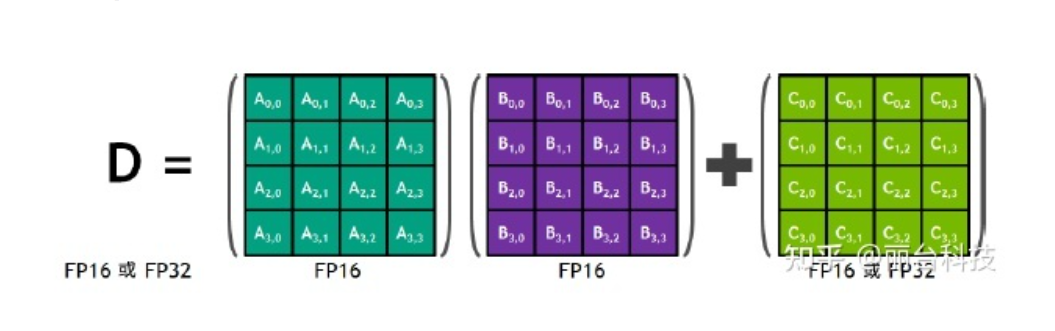
TensorCore支持的精度如下:
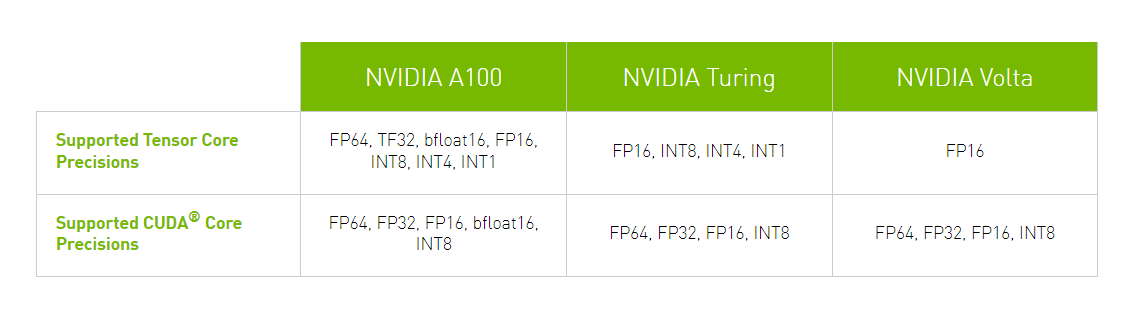
TensorCore 对不同架构的支持:
NVIDIA Ampere GPU Architecture Tuning Guide :: CUDA Toolkit Documentation
warp
wrap 是 Nvidia 线程调度的基本单位,32 个线程为一个 wrap, 每个 SM 有一个 Wrap 调度器。一个 SP(cuda core) 在同一时间只能执行一个wrap。
在同一时刻运行的 wrap 称作 active wrap, Occupancy就是每个SM的active warp占最大warp数目的比例。Occupancy 是衡量计算资源利用率的最重要的指标。
其它
SFU (special Function uint)特殊数学计算单元: 如 sin cos ;LD/ST(Load/Store Unit)存储单元
GPU 架构的变化
GPU 架构总览
| 版本号(计算能力) |
|
| Tesla 古董 |
1* |
| Fermi 古董 |
2* |
| Kepler |
35 37 |
| Maxwell |
50 52 53 |
| Pascal |
60 61 62 |
| Volta |
70 72 |
| Turing |
75 |
| Ampere |
80 86 87 |
cuda 和 架构关系
Cuda 7 开始不支持 Tesla,Cuda 9 开始不支持 Fermi。
Cuda 11 不支持 3.5 以下的。
Cuda 和 设备没有严格对应的关系, 和驱动、cudnn 版本严格对应关系
Nvcc
Nvcc sm 就是架构

TensorRT 和架构关系
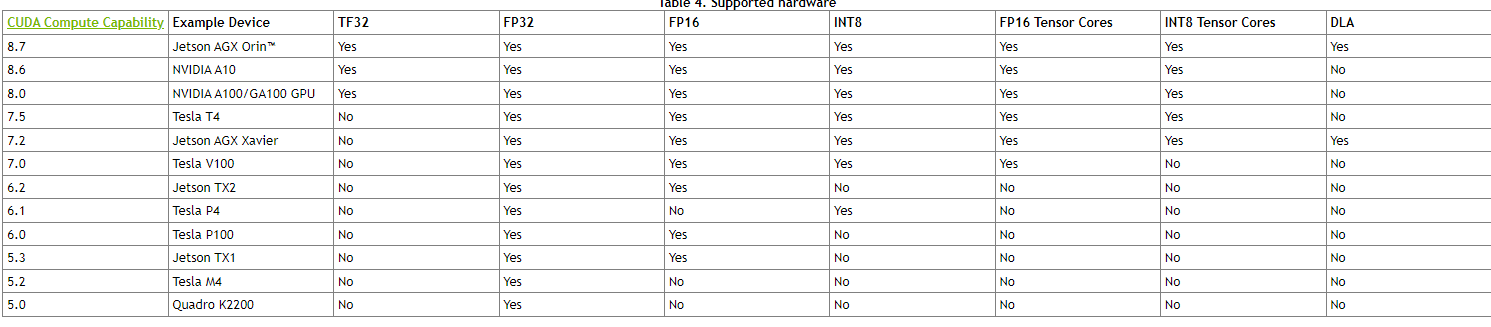
架构区别总览
总览如下图所示:
特殊类型解释说明:
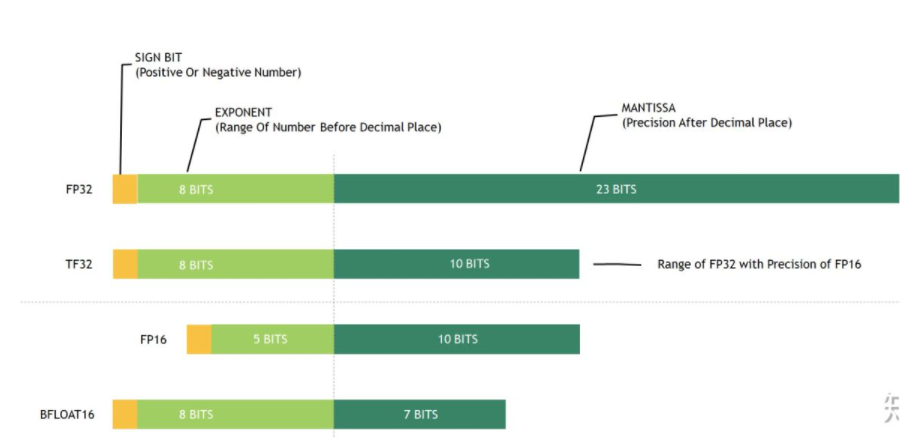
16 精度 float 类型

wrap matrix 混合精度计算

Kepler 架构
Kepler架构的思路是:减少SM单元数(在这一代中叫SMX单元),增加每组SM单元中的CUDA内核数。在Kepler架构中,每个SM单元的CUDA内核数由Fermi架构的32个激增至192个。
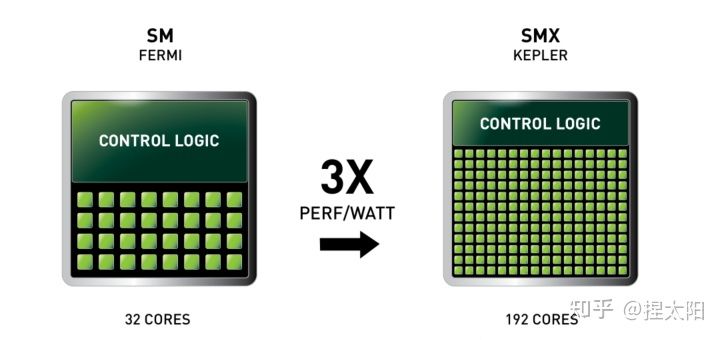
在每个SMX中:
- 4 个 Warp Scheduler,8 个 Dispatch Unit
- 绿色:192个 CUDA 内核,分在12条 lane 上,每条分别是 16 个
- 黄色:64 个DP双精度运算单元,分在4条 lane 上,每条 lane 上 16 个
- 32 个 LD/ST Unit
- 32 个 SFU
Maxwell 架构
Maxwell架构的SM单元和Kepler架构相比,又有很大变化,这一代的SM单元更像是把4个Fermi 架构的SM单元,按照2x2的方式排列在一起,这一代称为SMM单元:
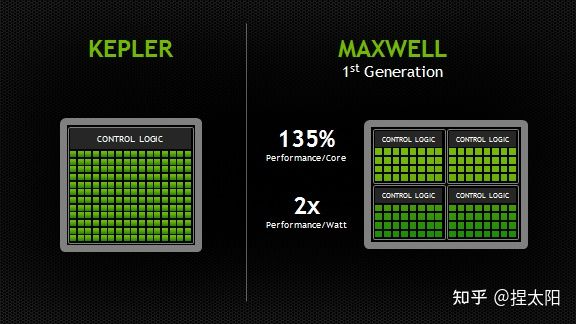

SMM 使用基于象限的设计,具有四个 32 核处理块(processing blocks),每个处理块都有一个专用的 warp 调度程序,能够在每个时钟分派两条指令。
每个 SMM 单元提供
- 八个纹理单元(texture units)
- 一个多态引擎(polymorph engine-图形的几何处理)
- 专用寄存器文件和共享内存。
每个处理块中:
- 1个 Warp Scheduler,2 个 Dispatch Unit
- 绿色:32个 CUDA 内核
- 8个 LD/ST Unit
- 8个 SFU
CUDA内核总数 从Kpler时代的每组SM单元192个减少到了每组128个,但是每个SMM单元将拥有更多的逻辑控制电路,便于精确控制。
参考:
Maxwell: The Most Advanced CUDA GPU Ever Made | NVIDIA Developer Blog
Pascal 架构(10卡)
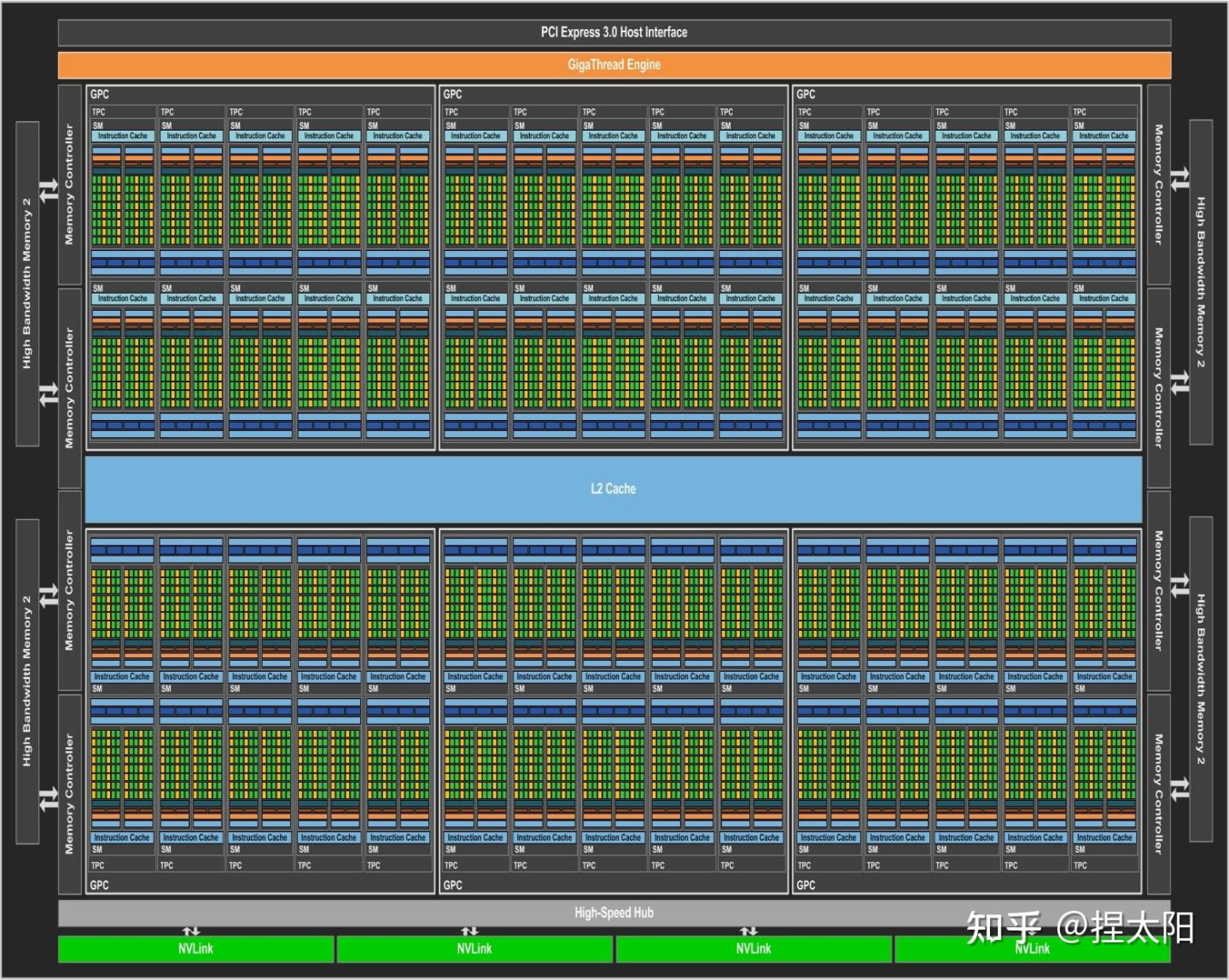
pascal架构的GP100核心
这里有一个新概念:核心
NVIDIA不同的架构会有几种不同的核心,Pascal架构有GP100、GP102两种大核心:
- GP100:3840个CUDA核心,60组SM单元;
- GP102:3584个CUDA核心,28组SM单元;
核心是一个完整的GPU模组,上图展示了一个pascal架构的GP100核心,带有 60 个 SM 单元。
不同的显卡产品可以使用不同的 GP100 配置,一般是满配或者减配,比如Tesla P100 使用了 56 个 SM 单元。

GP100核心的SM单元
每个SM单元中,分为2个Process Block,每个Process Block中:
- 1个 Warp Scheduler,2 个 Dispatch Unit
- 绿色:32个 CUDA 内核
- 黄色:16 个DP双精度运算单元,分在2条 lane 上,每条 lane 上 8个
- 8个 LD/ST Unit
- 8个 SFU
CUDA内核总数从Maxwell时代的每组SM单元128个减少到了每组64个,这一代最大的特点是又把DP双精度运算单元加回来了。
制程工艺升级到了16nm,性能大幅提升,功耗却不增加。
Volta 架构
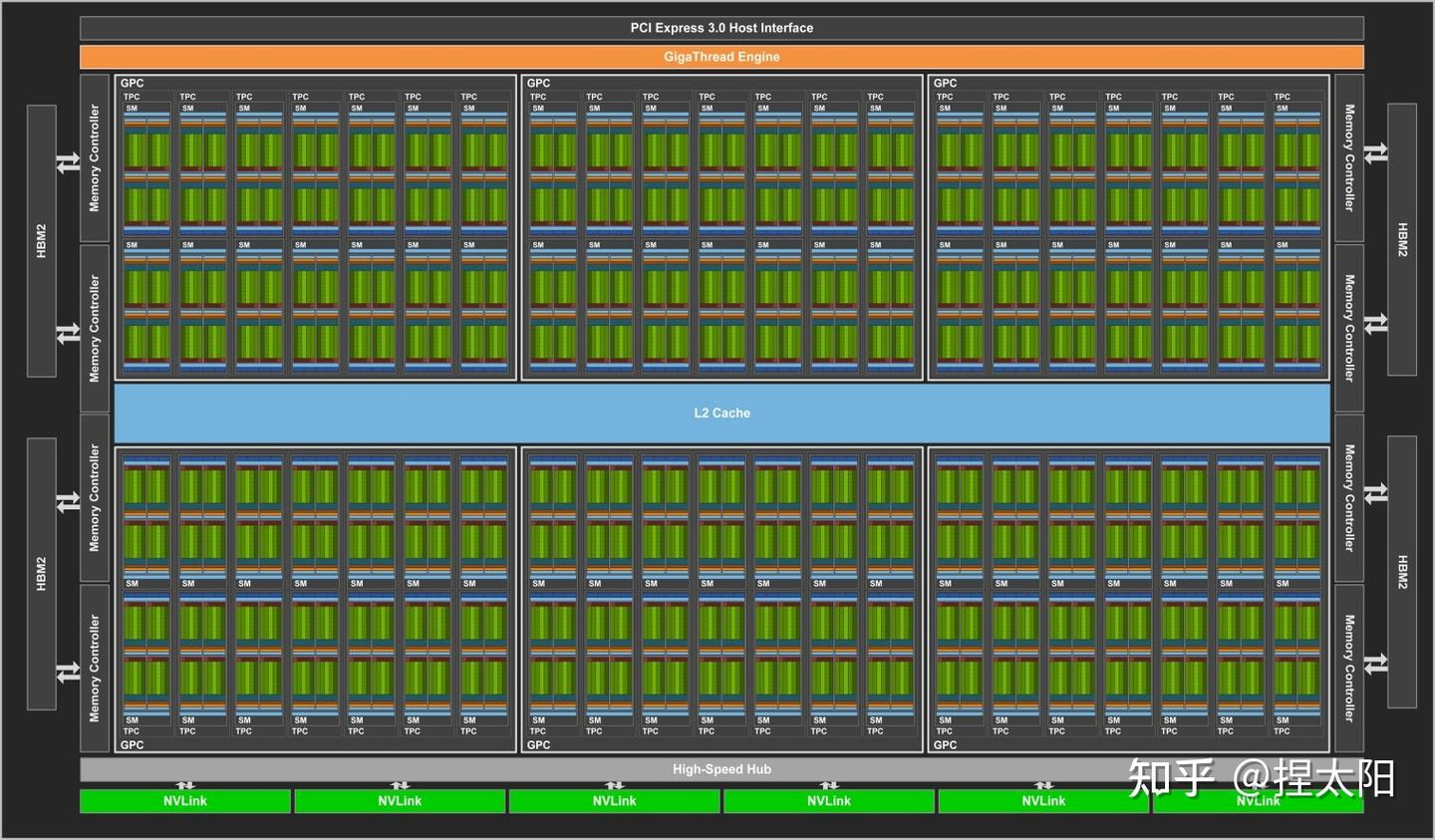
Volta架构的GV100核心
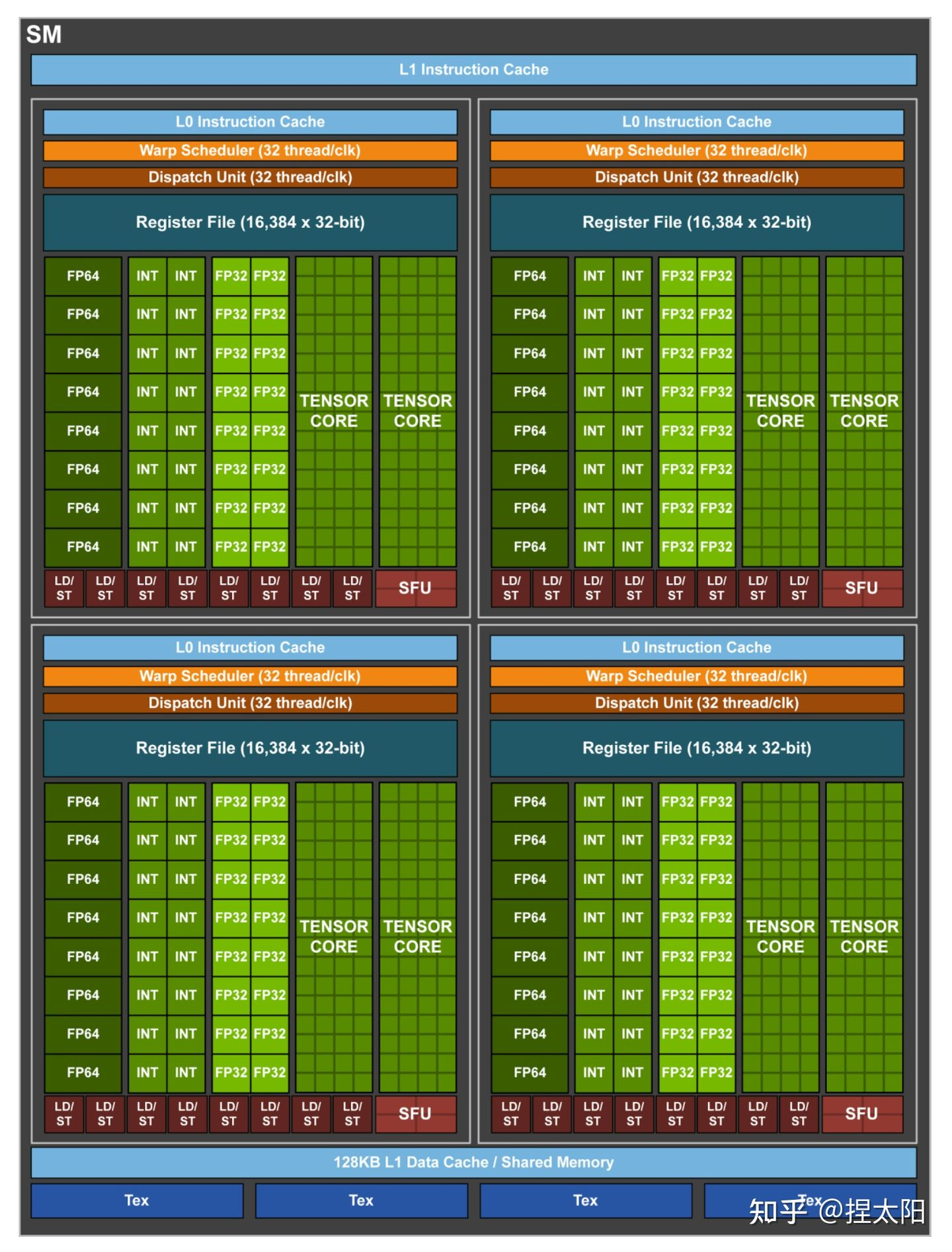
GV100核心的SM单元
每个SM单元中,分为4个Process Block,每个Process Block中:
- 1个 Warp Scheduler,1个 Dispatch Unit
- 8 个 FP64 Core
- 16 个 INT32 Core
- 16 个 FP32 Core
- 2 个 Tensor Core
- 8个 LD/ST Unit
- 4个 SFU
在前几代架构中:
一个CUDA 内核在每个时钟周期里只能为一个线程执行一条浮点或整数指令。
但是从Volta架构开始,将一个CUDA 内核拆分为两部分:FP32 和 INT32,好处是在同一个时钟周期里,可以同时执行浮点和整数指令,提高计算速度。
Volta架构在传统的单双精度计算之外还增加了专用的Tensor Core张量单元,用于深度学习、AI运算等。
Turing 架构(20卡)

Turing架构的TU102核心
Turing架构目前一共有三种核心:
- TU102核心
- TU104核心
- TU106核心
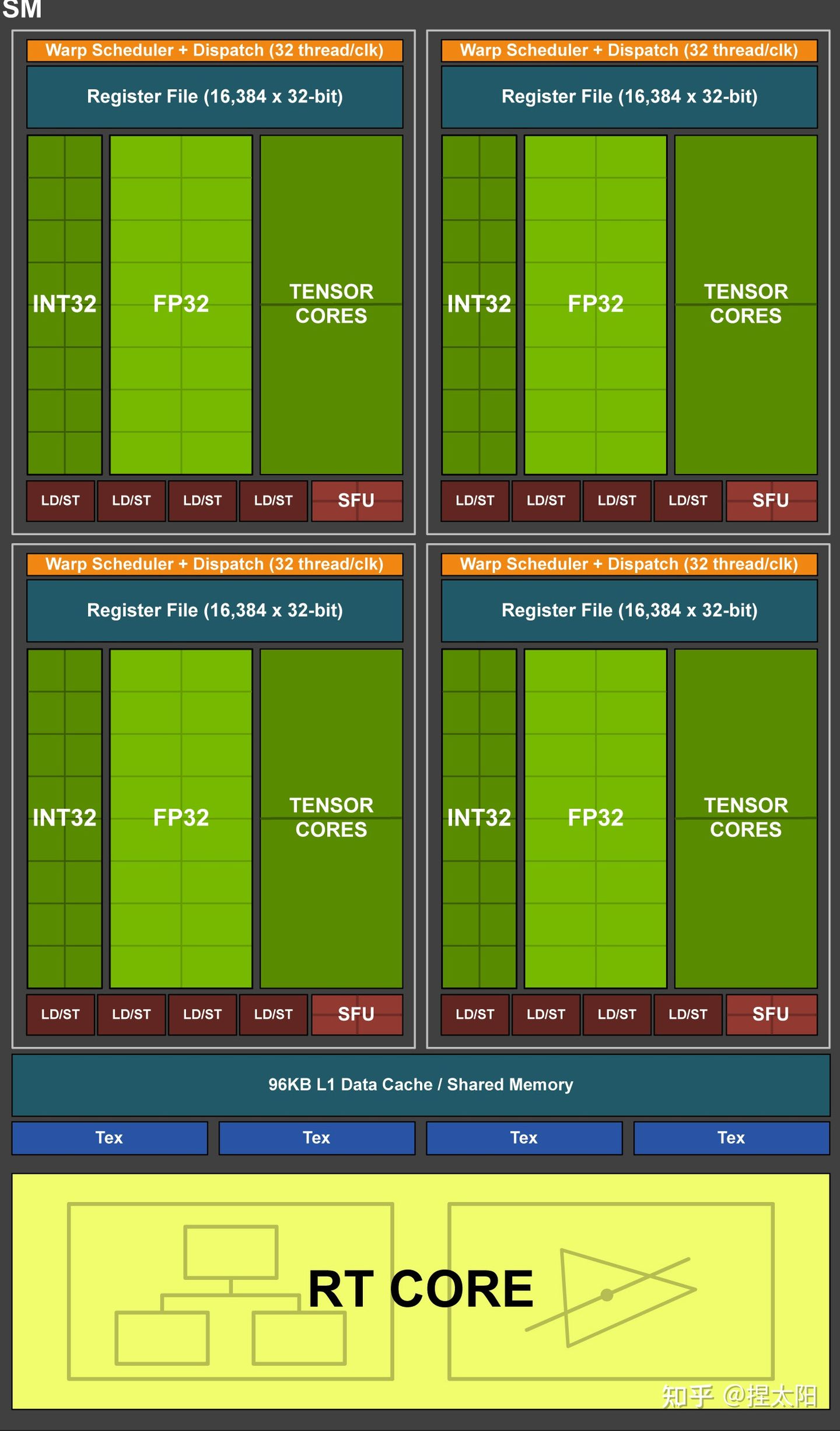
TU102核心的SM单元
每个SM单元有4个处理块,每个处理块中:
- 1 个 Warp Scheduler,1 个 Dispath Unit
- 16 个 INT32 Core
- 16 个 FP32 Core
- 2 个 Tensor Core
- 4 个 LD/ST Unit
- 4 个 SFU
这一代架构去掉了对FP64的支持。
Ampere 架构(30卡)
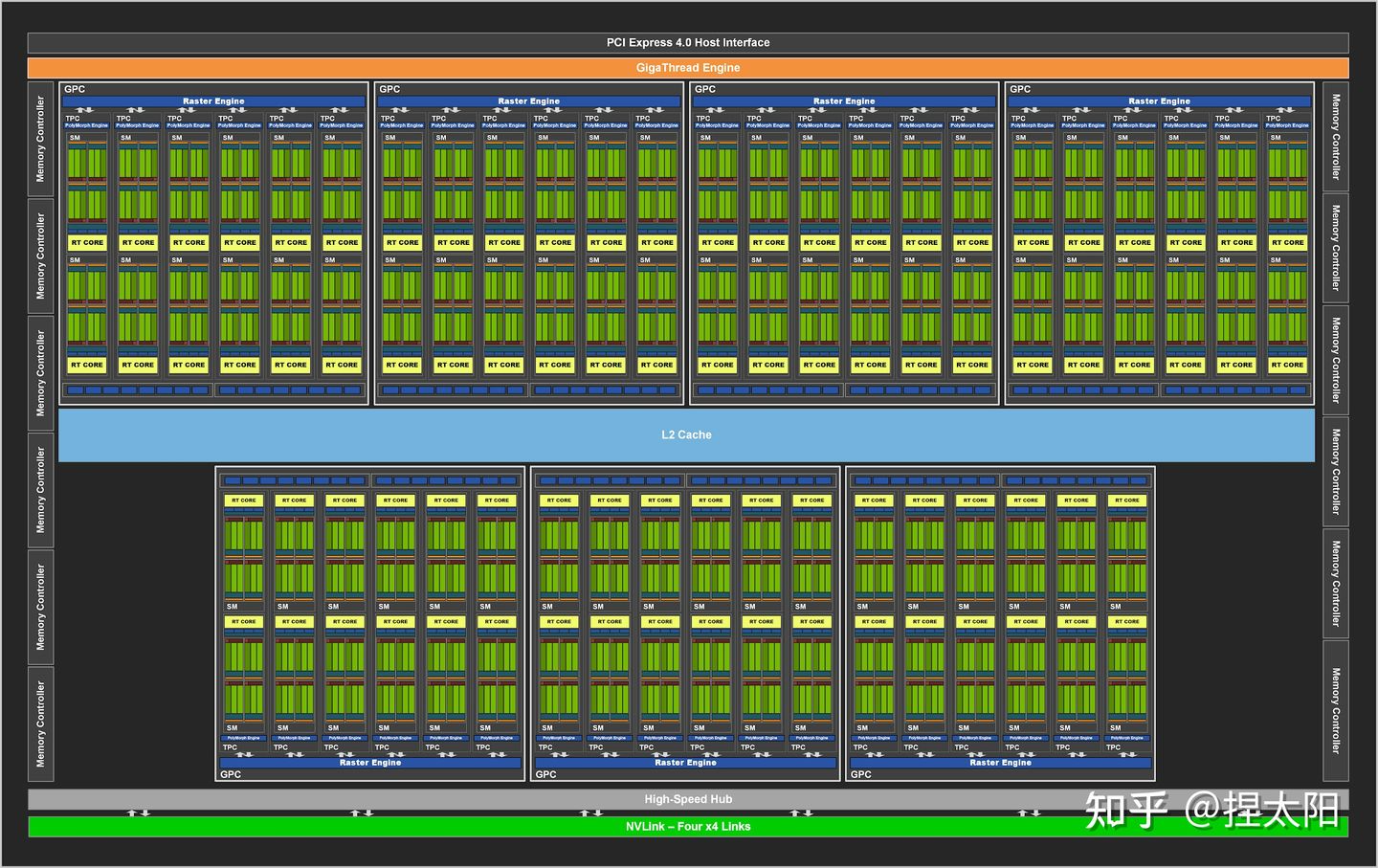
Ampere架构的GA102核心
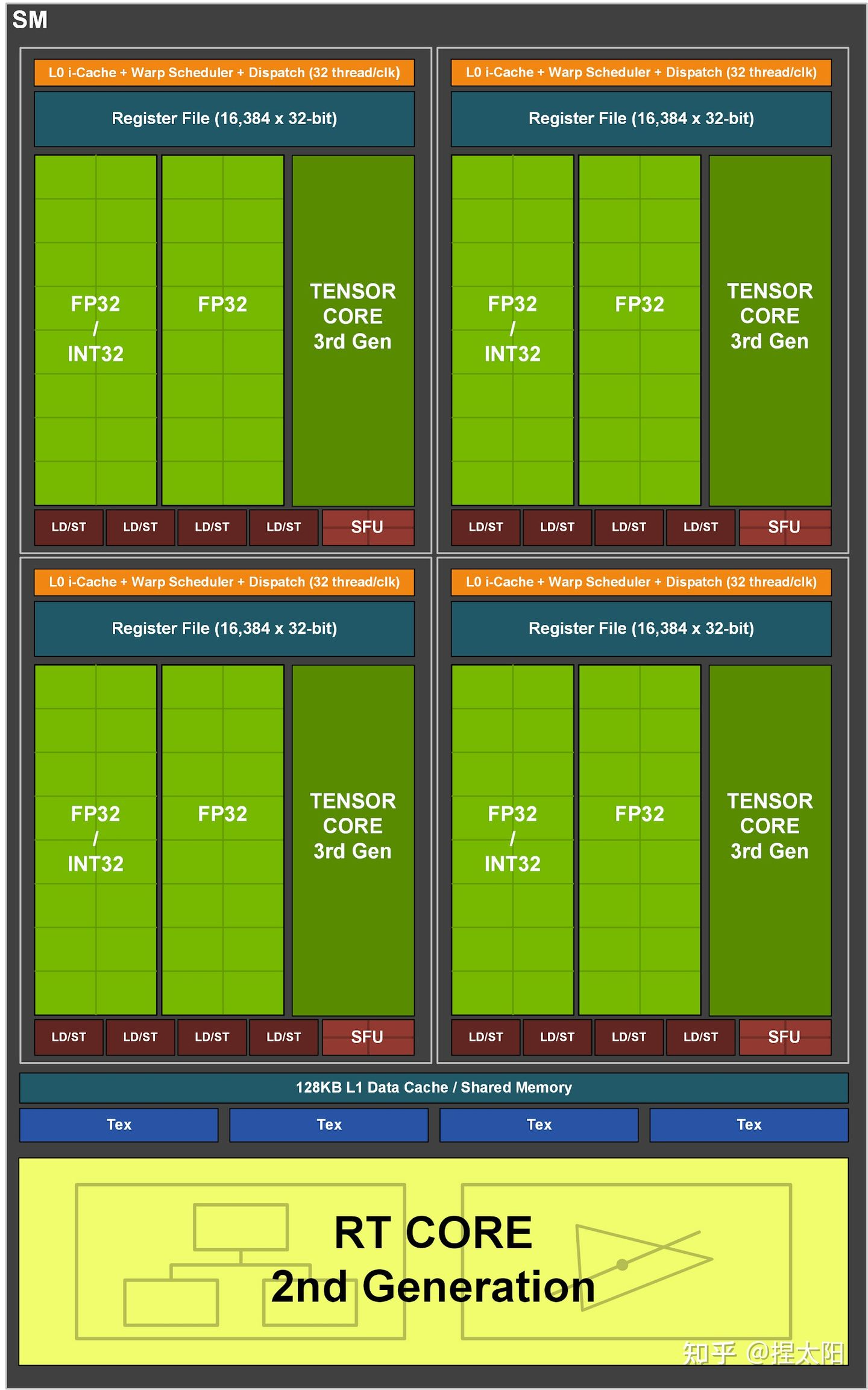
GA102核心的SM单元
每个SM单元分成4个处理块,每个处理块中:
- 1 个 Warp Scheduler,1 个 Dispatch Unit
- 8 个 FP64 Core
- 16 个 FP32 Core
- 16 个 INT32 Core
- 1 个 Tensor Core
- 8 个 LD/ST Unit
- 4 个 SFU
这一代架构又把FP64 Core加回来了,同时也是自Volta架构以来的,NVIDIA第三代Tensor技术,保持一代架构更新一次Tensor。
架构数字表示(Compute Capabilities)
设备的计算能力由版本号表示,有时也称其“SM版本”。该版本号标识GPU硬件支持的特性,并由应用程序在运行时使用,以确定当前GPU上可用的硬件特性和/或指令。
计算能力包括一个主要版本号X和一个次要版本号Y,用X.Y表示
主版本号相同的设备具有相同的核心架构。设备的主要修订号是8安培NVIDIA GPU的体系结构的基础上,7基于沃尔塔设备架构,6设备基于帕斯卡架构,5设备基于麦克斯韦架构,3基于开普勒架构的设备,2设备基于费米架构,1是基于特斯拉架构的设备。
次要修订号对应于对核心架构的增量改进,可能包括新特性。
图灵是用于具有计算能力7.5的设备的体系结构,是基于Volta体系结构的增量更新。
阿丘科技, 工业视觉的领导者,薪资 ok, 如 高级算法 30-60k , 内推码: NTAHmCz
微信号 :i_scream_andicecream
内推的话,欢迎加好友