浅谈HDFS读写数据过程内部原理
文章开始把我喜欢的这句话送个大家:这个世界上还有什么比自己写的代码运行在十万人的电脑上更酷的事情吗,如果有那就是让这个数字再扩大十倍。
本文将详细解释HDFS读写数据过程中系统底层究竟发生了什么以及其具体实现,希望可以帮助理解。
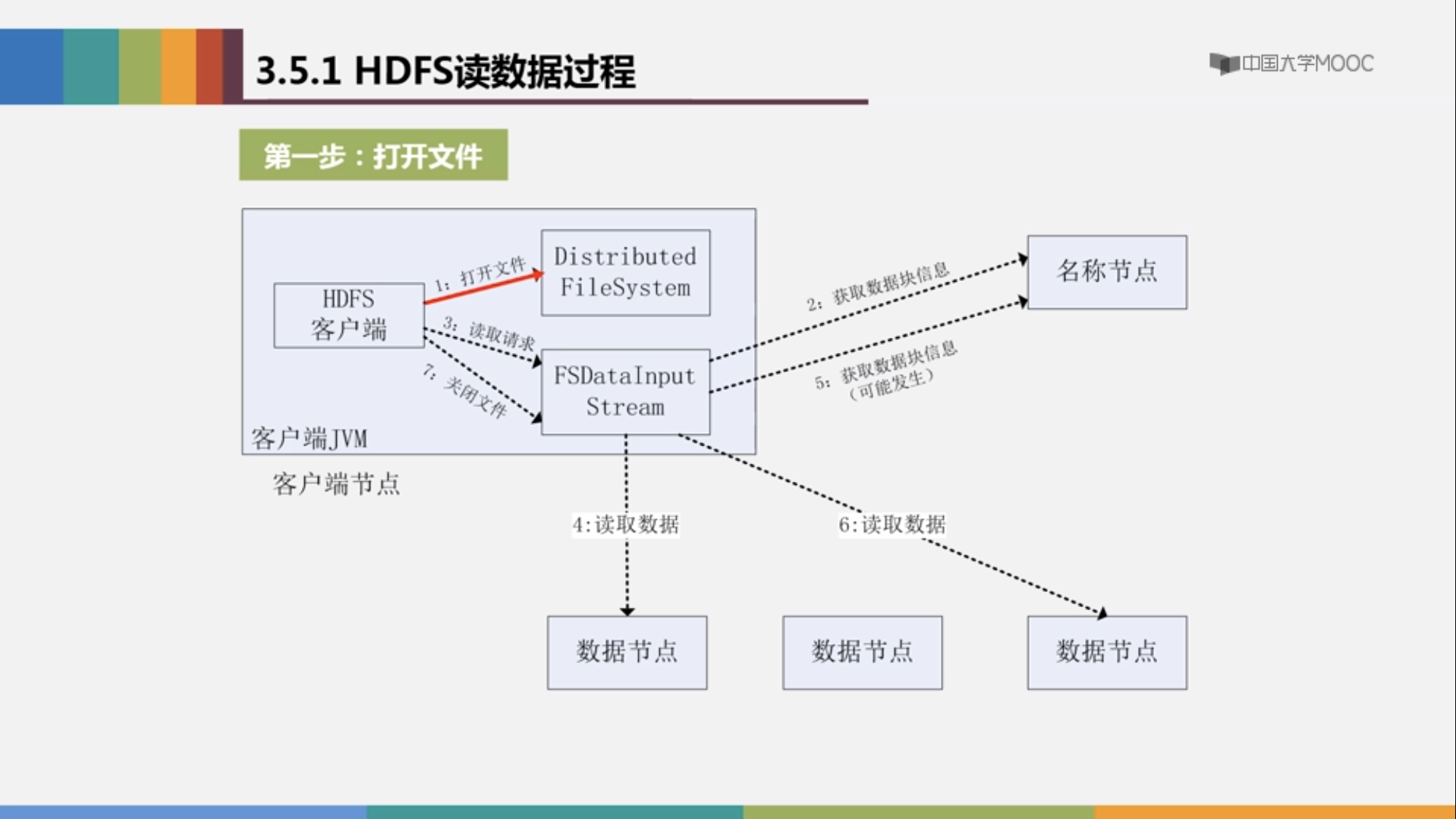
首先读数据过程:
HDFS客户端发出读数据命令之后
configuration conf =new Configration();//配置文件,加载core-site.xml hdfs-site.xml 得到读写的地址
FileSystem fs=FileSystem.get(conf);//这一过程在底层实际上完成了FileSystem抽象类生成子类Distributed Filesystem 并实例 化对象fs 的过程,真正对分布式文件进行操作的也是DistributedFileSystem的对象fs
path filename=new Path("url");
FSDataInputStream is=fs.open(filename);//此时会在内部创建一个输入流FSDateInputStream,输入流FSDateInputStream对 应着底层的DFSDateInputStream,由这个DFSInputStream 来对底层操作调用 ClientProtocal.getBlockLocation()方法得到NameNode的地址,进而得到 DataNode的地址,完成读的过程
而当读取的文件占用超过一个数据块时,会重复进行该过程读取剩下的文件所在的数据块。
以上便是读取数据的过程,我们可以发现操作数据的并不是我们程序员直接接触的FileSystem FSDataInputStream 等类,而是他们在底层对应的DistributedFileSystem以及DFSDataInputStream.
附上流程图:

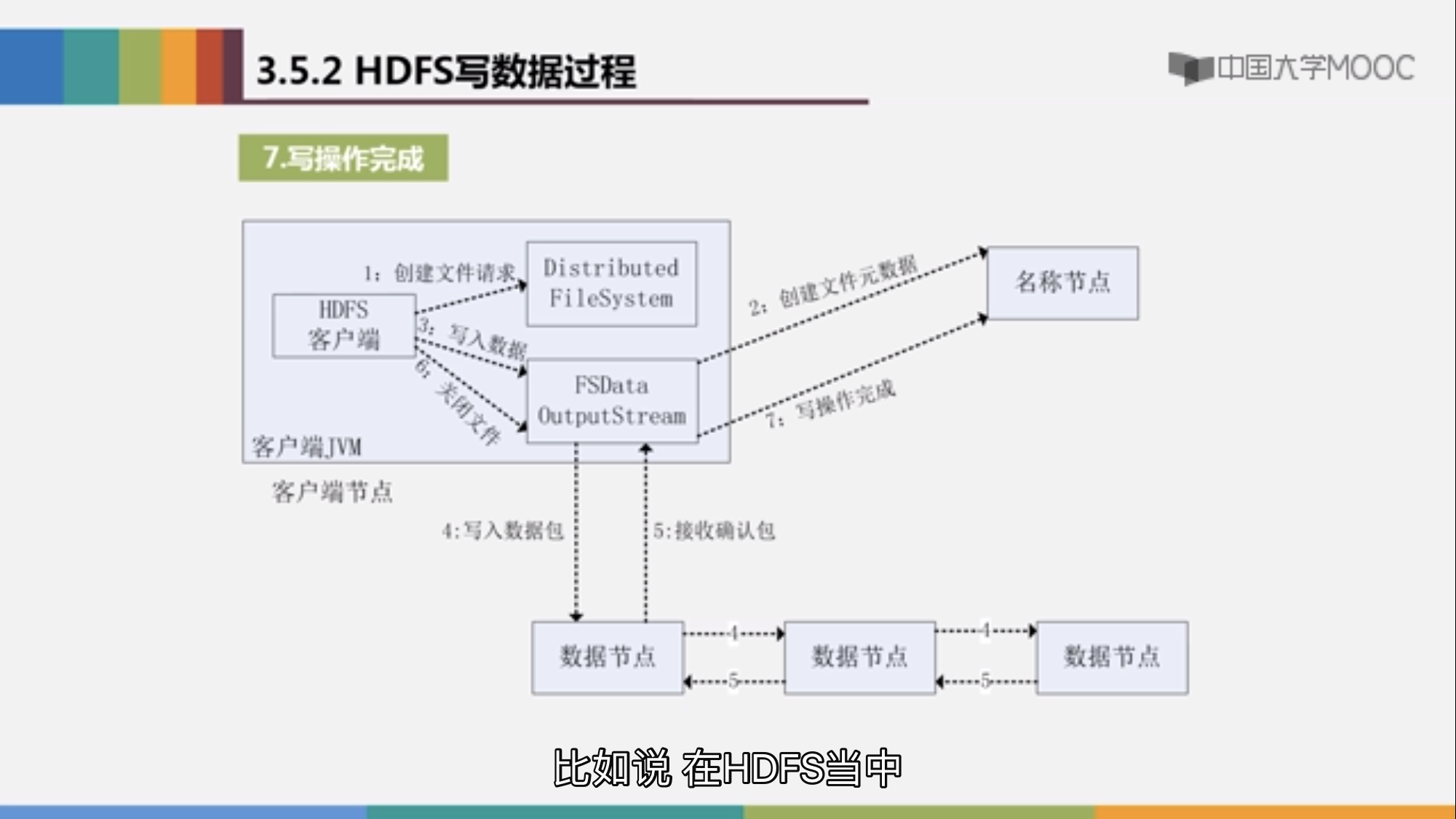
写入的过程与读的过程类似,不在附加说明,唯一不同的是写入数据时HDFS采取流水线方法,当FSDataOutputStream 将数据写入第一个节点之后,会由第一个节点向第二个节点写入数据,一次向后达到备份的目的。
附上流程图:
加油吧,程序员!!!