1.数据读取过程

一般的文件读取操作包括:open 、read、close等
客户端读取数据过程,其中1、3、6步由客户端发起:
客户端首先获取FileSystem的一个实例,这里就是HDFS对应的实例:
①客户端调用FileSystem实例的open方法,获得这个文件对应的输入流,在HDFS中就是DFSInputStream
②构造第一步中的输入流DFSInputStream时,通过RPC远程调用NameNode可以获得NameNode中此文件对应的数据块的保存位置,包括这个文件的副本的保存位置(主要是各DataNode的地址)。注意,在输入流中会按照网络拓扑结构,根据与客户端距离对DataNode进行简单排序
③④获得此输入流之后,客户端调用read方法读取数据。输入流DFSInputStream会根据前面的排序结果,选择最近的DataNode建立连接并读取数据。如果客户端和其中一个DataNode位于一个机器中(比如MapReduce过程中的mapper和reducer),那么就会直接从本地读取数据。
⑤如果已达到数据块末端,那么关闭与这个DataNode的连接,然后重新查找下一个数据块。
不断执行②-⑤直到数据全部读完,然后调用close
⑥客户端调用close,关闭输入流DFSInputStream
另外如果DFSInputStream和DataNode通信时出现错误,或者是数据校验出错,那么DFSInputStream就会重新选择DataNode传输数据。

2.数据写入过程
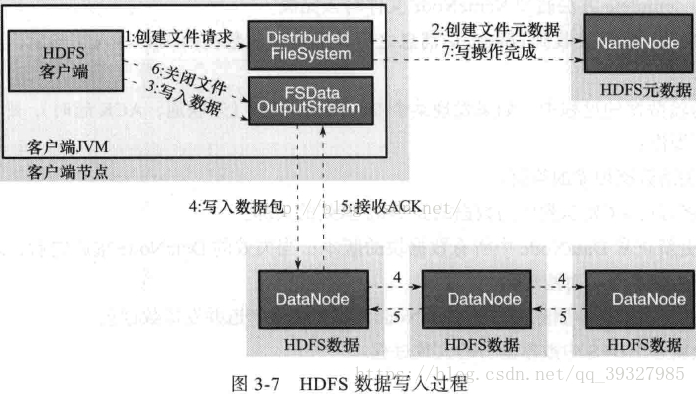
客户端写入数据过程,其中1、3、6由客户端发起
客户端首先要获取FileStream的一个实例,这里就是HDFS的实例,
①②客户端调用FileSystem实例的create方法,创建文件。NameNode通过检查,比如文件是否存在,客户端是否拥有创建权限等;通过检查之后,在NameNode添加文件信息。注意,因为此时文件没有数据,所以NameNode上也没有文件数据块信息。创建结束后,HDFS会返回一个输出流DFSDataOutputStream给客户端。
③客户端调用输出流DFSDataOutputStream的write方法向HDFS中对应的文件写入数据。数据首先会被分包,这些分包会写入一个输入流内部队列Data队列中,接收完整数据分包,输出流DFSDataOutputStream会向nameNode申请保存文件和副本数据块的若干个DataNode,这若个个DataNode会形成一个数据传输管道。
④DFSDataOutputStream会(根据网络拓扑结构排序)将数据传输给距离上最短的DataNode,这个DataNode接收到数据包之后会传递给下一个DataNode,数据在各DataNode之间通过管道流动,而不是全部由输出流分发,这样可以减少传输开销。
⑤因为DataNode位于不同机器上,数据需要通过网络发送,所以,为了保证所有的DataNode的数据都是准确的,接收到数据的DataNode要向发送者发送确认包(ACKPacket)。对于某个数据块,只有当DFSDataOutputStream收到了所有DataNode的正确ACK,才能确认传输结束。DFSDataOutputStream内部专门维护了一个等待ACK队列,这一队列保存已经进入管道传输数据、但是并未被完全确认的数据包。
不断③-⑤直到数据全部写完,客户端调用close关闭文件。
⑥客户端调用close方法,DFSDataOutputStream继续等待直到所有数据写入完毕并被确认,调用complete方法通知NameNode文件写入完成。
⑦NameNode接收到complete消息之后,等待相应数量的副本写入完毕后,告知客户端即可。
3、在传输过程中,如果发现某个DataNode失效(未联通,ACK超时),那么HDFS执行如下操作:
①关闭数据传输的管道
②将等待ACK队列中的数据放到Data队列的头部
③更新正常DataNode中所有数据块的版本;当失效的DataNode重启之后,之前的数据块会因为版本不对而被清除。
④在传输管道中删除失效DataNode,重新建立管道并发送数据包。
3.HDFS基本操作常用API
1.创建文件
public FSDataOutputStream create(Path f) throws IOException;
这里会返回一个FSDataOutputStream对象,通过这个对象来调入write方法
2.打开文件
public FSDataInputStream open(Path f) throws IOException ;
这里会返回 FSDataInputStream对象,通过这个对象调用read方法
3.获取文件信息
public FileStatus getFileStatus(Path f) throws IOException;
这里返回 FileStatus对象,其中保存了文件很多信息
4.获取目录信息
public FileStatus[] listStatus(Path f) throws IOException;
5.读取
public int read(long position, byte[] buffer, int offset, int length) throws IOException;
6.写入
public void write(byte[] b, int off, int len) throws IOException
7.关闭
public void close() throws IOException;
8.删除
public boolean delete(Path f, boolean recursive) throws IOException;
参考 :《深入理解大数据 大数据处理与编程实践》