hdfs写数据原理图
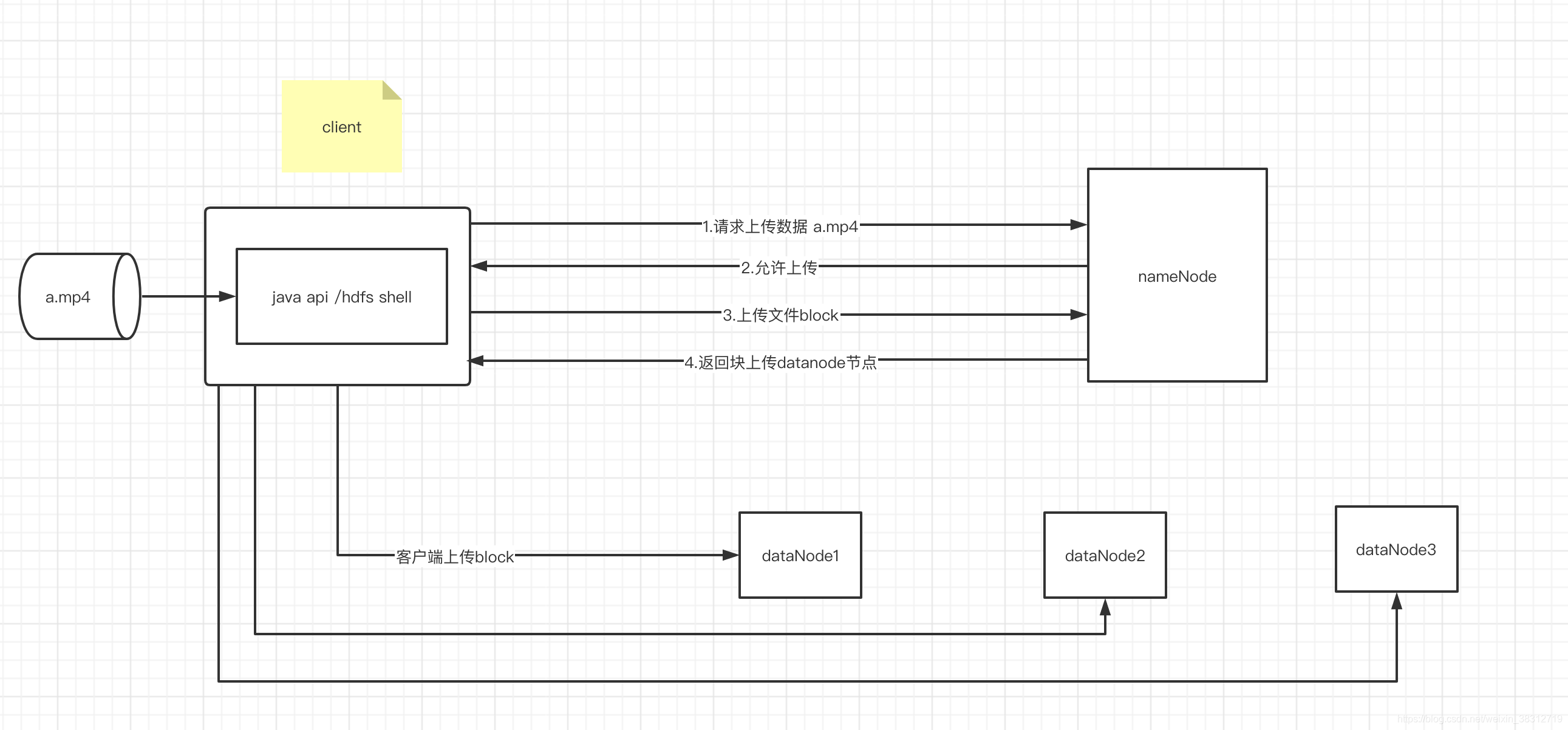
hdfs写数据原理图说明
1.客户端发起请求,namenode需要检测是否可以上传(磁盘大小,节点检查等)
2.namenode检查完毕,觉得可以上传,那么会返回hdfs系统的一些配置,客户端需要根据这些要求(文件块大小之类的)进行上传
3.客户端根据namenode要求,对a.mp4进行切块,比如namenode返回block.size=128M,
客户端上传文件大小是300M, 那么需要切分为(128,128,44),分别上传.
4.接收到客户端上传分片请求,namenode根据自己管理的datanode节点情况(节点距离,副本数量),
返回对应的数据节点,返回数据节点的数量取决于客户端配置的副本数量,如果客户端只要将上传文件有两个副本,那么namenode会返回三个datanode地址.
5.客户端上传block,客户端根据拿到的namenode返回的nodenode地址发起上传文件的io请求,
开始上传数据块.
//3.4.5是一个循环,根据切块数量,不断执行3-5步骤
hdfs读数据原理图
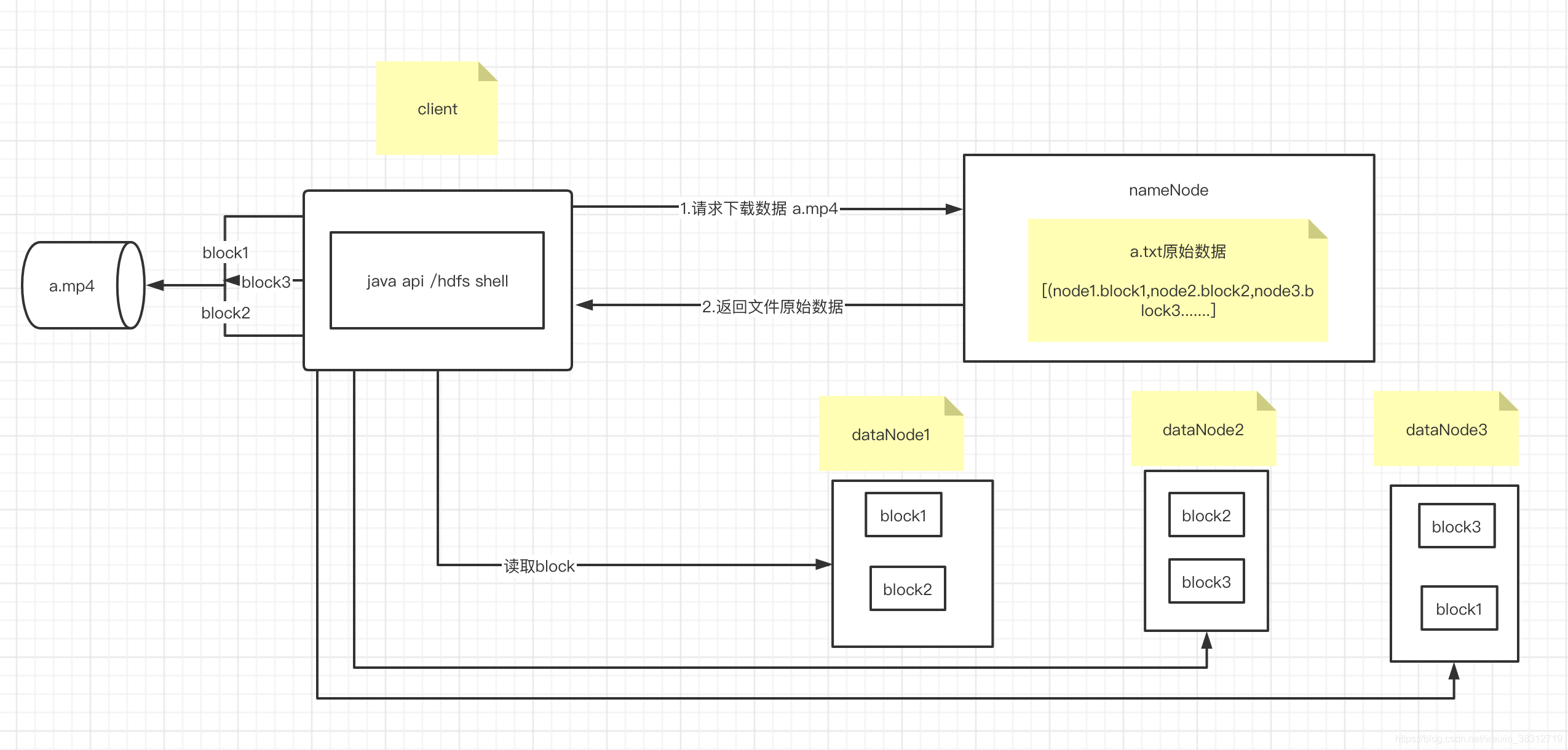
hdfs读数据原理图说明
1.客户端请求下载a.mp4,namenode进行校验文件是否存在等检查
2.namenod检查完毕,返回要读取文件的原始数据,主要包括数据分块信息和节点分布信息
3.客户端使用文件元数据向datanode发起读取文件块的请求,所有块读取完毕后,合并为一个完整
的可用文件
总结
1.hdfs文件读写都是分块处理,多副本的形式进行分布式存储, 体现了分布式文件系统高可用
2.hdfs文件读写客户端可以并发访问datanode, 读写速度是所有datanode之和,体现了分布式文件系统速度快
3.hdfs文件数据都是存储在多台datanode的,这些datanode原始数据由namenode统一管理,并且可以无限扩展,体现了分布式文件系统可以存储任意大小文件