文章目录
到底怎么使用机器学习?
机器学习在实际操作层面一共分为7步:
- 收集数据
- 数据准备
- 选择一个模型
- 训练
- 评估
- 参数调整
- 预测(开始使用)
机器学习的7个步骤

假设我们的任务是通过酒精度和颜色来区分红酒和啤酒,下面详细介绍一下机器学习中每一个步骤是如何工作的。

案例目标:区分红酒和啤酒
步骤1:收集数据
我们在超市买来一堆不同种类的啤酒和红酒,然后再买来测量颜色的光谱仪和用于测量酒精度的设备。
这个时候,我们把买来的所有酒都标记出他的颜色和酒精度,会形成下面这张表格。

这一步非常重要,因为数据的数量和质量直接决定了预测模型的好坏。
步骤2:数据准备
在这个例子中,我们的数据是很工整的,但是在实际情况中,我们收集到的数据会有很多问题,所以会涉及到数据清洗等工作。
当数据本身没有什么问题后,我们将数据分成3个部分:训练集(60%)、验证集(20%)、测试集(20%),用于后面的验证和评估工作。

步骤3:选择一个模型
研究人员和数据科学家多年来创造了许多模型。有些非常适合图像数据,有些非常适合于序列(如文本或音乐),有些用于数字数据,有些用于基于文本的数据。
在我们的例子中,由于我们只有2个特征,颜色和酒精度,我们可以使用一个小的线性模型,这是一个相当简单的模型。
步骤4:训练
大部分人都认为这个是最重要的部分,其实并非如此~ 数据数量和质量、还有模型的选择比训练本身重要更多(训练知识台上的3分钟,更重要的是台下的10年功)。
这个过程就不需要人来参与的,机器独立就可以完成,整个过程就好像是在做算术题。因为机器学习的本质就是将问题转化为数学问题,然后解答数学题的过程。
步骤5:评估
一旦训练完成,就可以评估模型是否有用。这是我们之前预留的验证集和测试集发挥作用的地方。评估的指标主要有 准确率、召回率、F值。
这个过程可以让我们看到模型如何对尚未看到的数是如何做预测的。这意味着代表模型在现实世界中的表现。
步骤6:参数调整
完成评估后,您可能希望了解是否可以以任何方式进一步改进训练。我们可以通过调整参数来做到这一点。当我们进行训练时,我们隐含地假设了一些参数,我们可以通过认为的调整这些参数让模型表现的更出色。
步骤7:预测
我们上面的6个步骤都是为了这一步来服务的。这也是机器学习的价值。这个时候,当我们买来一瓶新的酒,只要告诉机器他的颜色和酒精度,他就会告诉你,这时啤酒还是红酒了。
实验案例
随机森林分类器(红酒数据集案例)
#导包
import matplotlib.pyplot as plt
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
#导数据集,切分数据集
wine = load_wine()
wine.data
wine.target
wine.feature_names
Xtrain, Xtest, Ytrain, Ytest = train_test_split(wine.data,wine.target,test_size=0.3)
Xtrain.shape
#对比随机森林分类器vs决策树
clf = DecisionTreeClassifier(random_state = 0)
rfc = RandomForestClassifier(random_state = 0)
clf = clf.fit(Xtrain,Ytrain)
rfc = rfc.fit(Xtrain,Ytrain)
score_c = clf.score(Xtest,Ytest)
score_r = rfc.score(Xtest,Ytest)
print(score_c)
print(score_r)

#导包
import matplotlib.pyplot as plt
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
#导数据集,切分数据集
wine = load_wine()
wine.data
wine.target
wine.feature_names
Xtrain, Xtest, Ytrain, Ytest = train_test_split(wine.data,wine.target,test_size=0.3)
Xtrain.shape
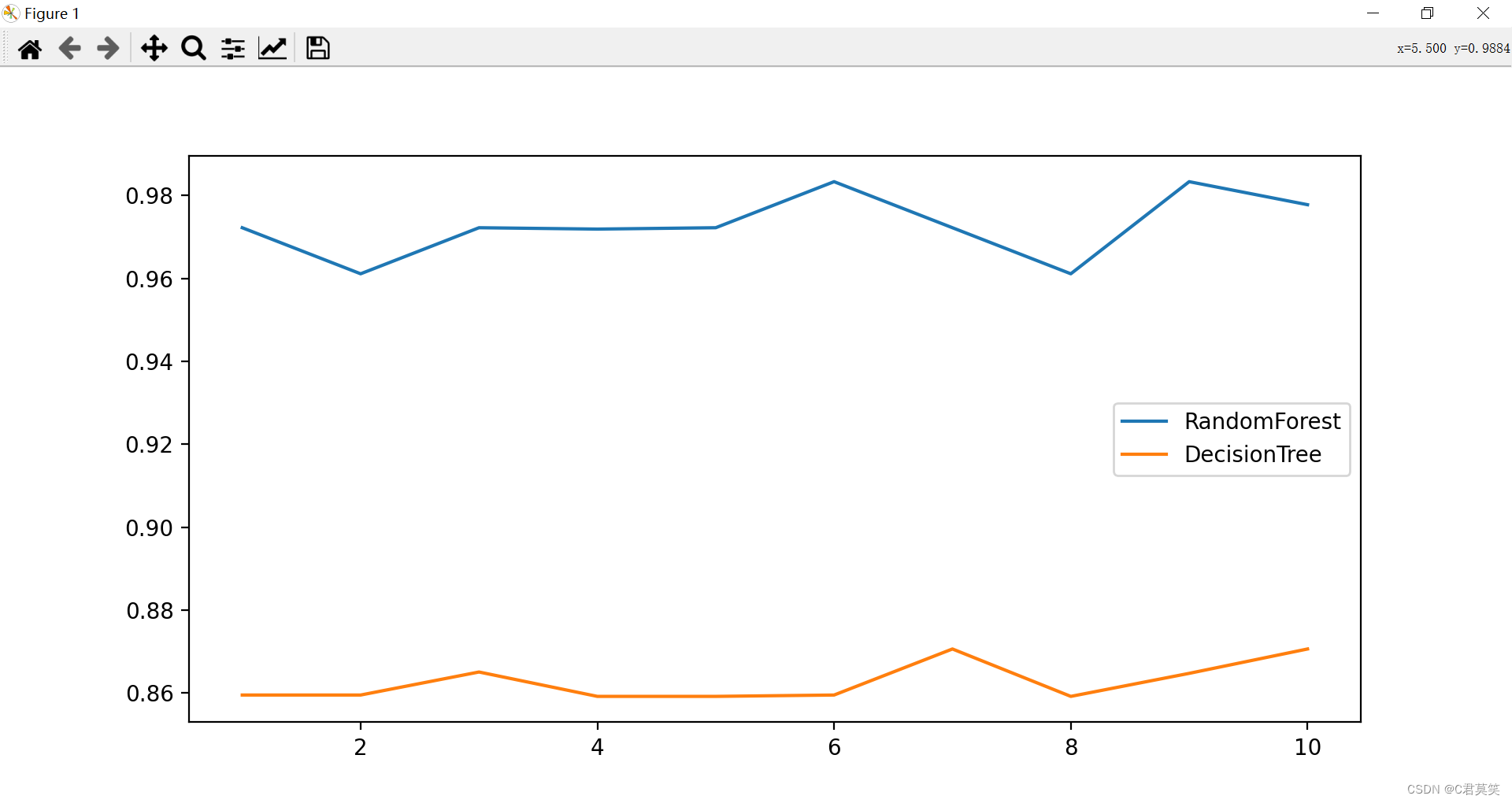
一组样本可能说服力不大,下面看看交叉验证的结果
#交叉验证
from sklearn.model_selection import cross_val_score
label = "RandomForest"
for model in [RandomForestClassifier(n_estimators=25),DecisionTreeClassifier()]:
score = cross_val_score(model,wine.data,wine.target,cv=10)
# print("{}:".format(label)),print(score.mean())
print(f"{label}"),print(score.mean())
plt.plot(range(1,11),score,label = label)
plt.legend()
label = "DecisionTree"
plt.show()
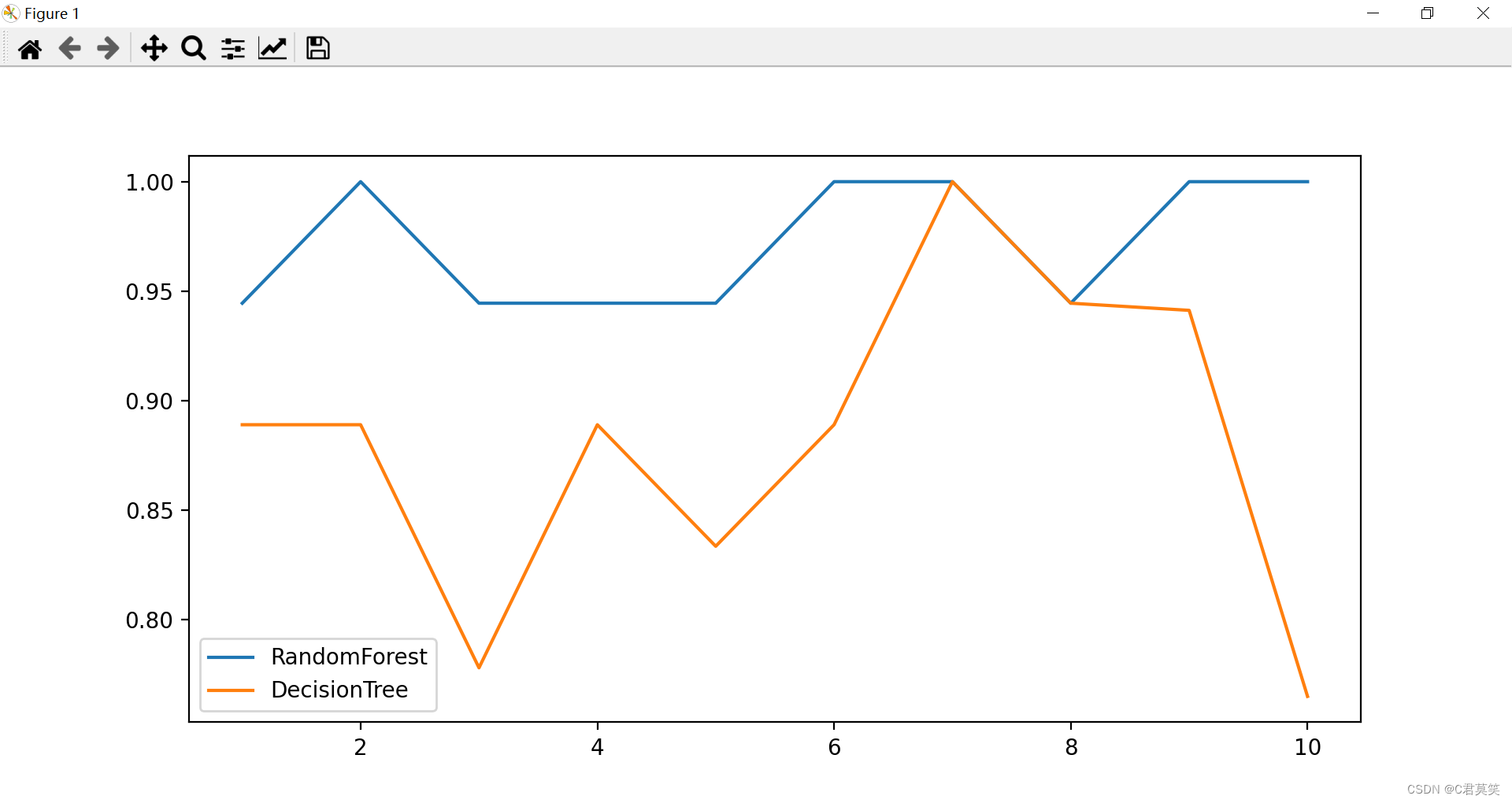
为了观察更稳定的结果,下面进行十组交叉验证
#导包
import matplotlib.pyplot as plt
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
#导数据集,切分数据集
wine = load_wine()
wine.data
wine.target
wine.feature_names
Xtrain, Xtest, Ytrain, Ytest = train_test_split(wine.data,wine.target,test_size=0.3)
Xtrain.shape
# 十组交叉验证
rfc_l = []
clf_l = []
for i in range(10):
rfc = RandomForestClassifier(n_estimators=25)
rfc_s = cross_val_score(rfc, wine.data, wine.target, cv=10).mean()
rfc_l.append(rfc_s)
clf = DecisionTreeClassifier()
clf_s = cross_val_score(clf, wine.data, wine.target, cv=10).mean()
clf_l.append(clf_s)
# 绘制结果曲线
plt.plot(range(1, 11), rfc_l, label="RandomForest")
plt.plot(range(1, 11), clf_l, label="DecisionTree")
plt.legend()
plt.show()