神经网络理论和应用
神经网络学习预备知识
AI机器学习深度学习的关系
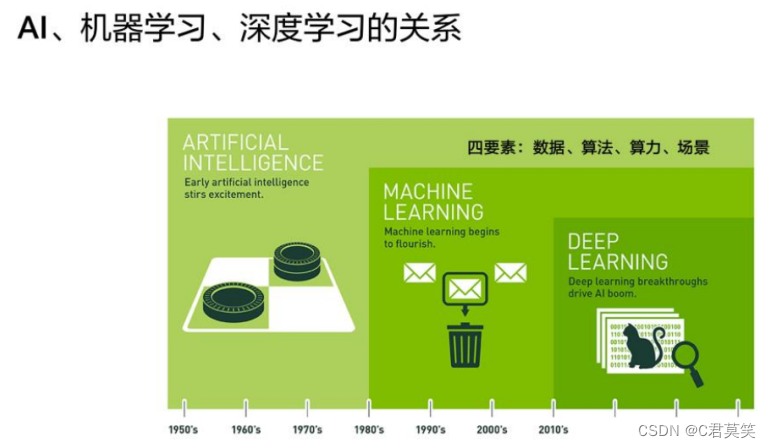
- 人工智能是个长久以来我们希望实现的目标
- 机器学习是达成人工智能目标的一种手段
- 深度学习是机器学习其中的一种方法
详见:Python人工智能概念之机器学习基础入门思维导图,果断收藏
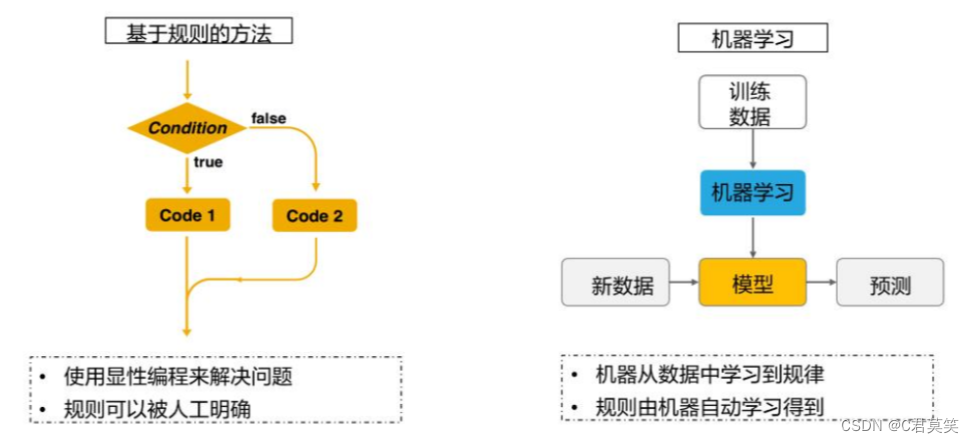
机器学习算法与传统基于规则的区别
训练集和测试集
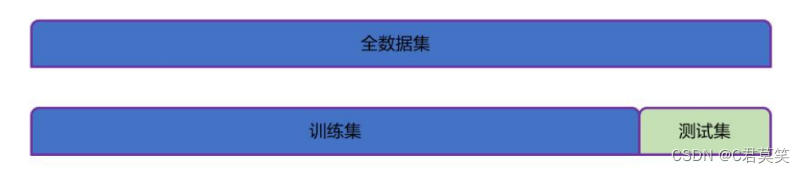
- 训练集:训练过程中使用的数据集,其中每个训练样本称为训练样本。从数据中学得模型的过程称为学习(训练)。
- 测试集:学得模型后,使用其进行预测的过程称为测试,使用的数据集称为测试集,每个样本称为测试样本。
欠拟合和过拟合
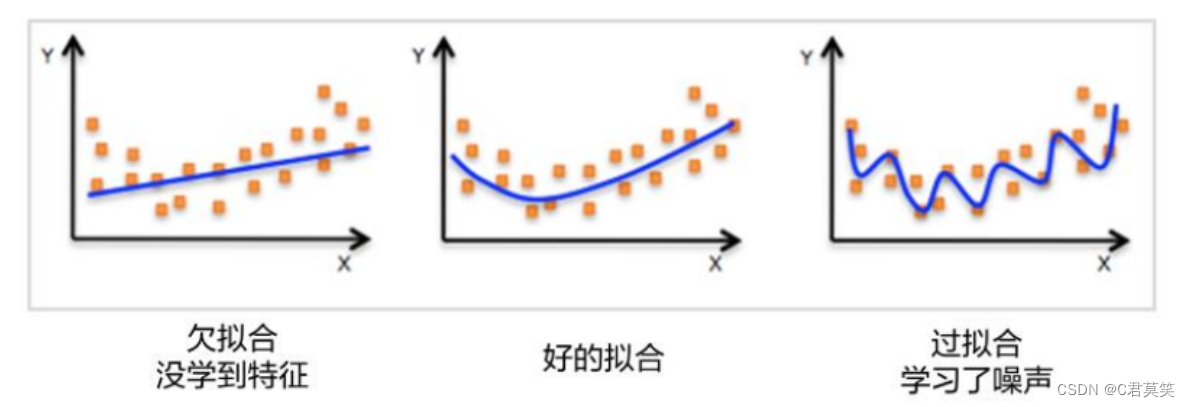
- 欠拟合:模型过于简单导致训练误差泛化误差大。
- 过拟合:训练得到的模型的训练误差很小,而泛化能力较弱即泛化误差较大。
机器学习的应用场景
四大常见任务:分类,回归,聚类,生成
分类和回归是预测问题的两种主要类型,分类的输出是离散的类别值,而回归的输出是连续数值。
详见:机器学习之KNN最邻近分类算法入门思维导图,果断收藏
详见:机器学习之逻辑回归(Logistic Regression)原理讲解和实例应用,果断收藏
机器学习方法(数据是否带标记)
监督学习(带标记)
无监督学习(不带标记)
半监督学习(部分带标记,部分不带标记)
自监督学习
- 自监督学习在19年提出,常用于自然语言处理的模型训练,例如,Word2Vec,BERT等。而图像和语音也逐渐提出一些方法来进行自监督学习。由于不需要人为手动标签,因此自监督学习会逐渐成为未来的主流训练方法。
机器学习的整体流程

详解:机器学习实操的7个步骤
人工神经网络
神经网络简介
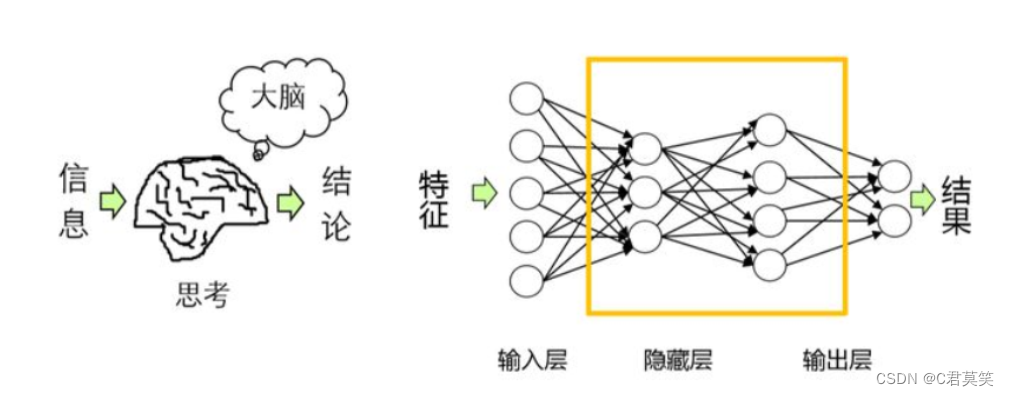
人工神经网络是用数字化技术模拟人类大脑神经元的连接和信息传递,是人工智能的重要研究方向。现代神经网络是一种非线性统计性数据建模工具。
感知机
感知机概念
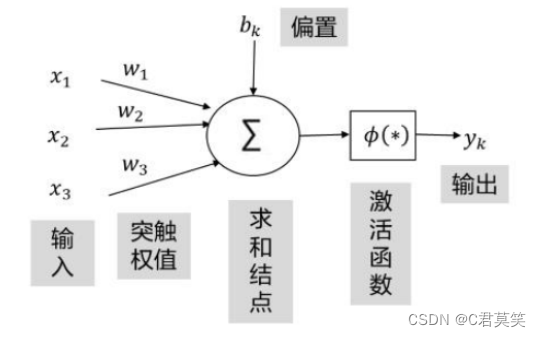
感知器用来接收多个信号,输出一个信号(由多个神经元组成)。每个输入信号具有一定的权重,计算多个输入信号的值与权重的乘积和,根据该结果(和)与指定的阈值进行比较,来决定该神经元是否被激活。
感知机分类
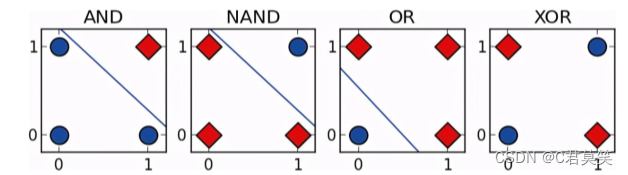
单层感知器
-
输入端与输出端之间无隐含层
-
线性不可分,只能分类简单线性可分的模型(二分类) 只能画出一条直线

非线性决策边界无法使用单层感知机

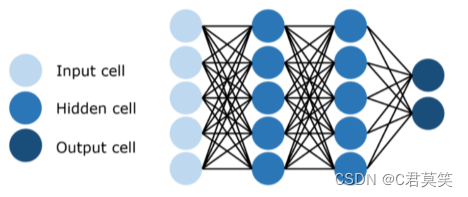
多层感知器
- 输入端和输出端之间多了隐含层
- 实现了非线性分类画多条直线
感知机的优缺点
- 优点:模型简单,易于实现。
- 缺点:无法完美地处理线性不可分地训练数据,最终迭代代数受结果超平面以及训练集的数据影响很大
激活函数
激活函数作用
-
实现神经元输入和输出之间关系的非线性化,加入非线性因素
-
画曲线
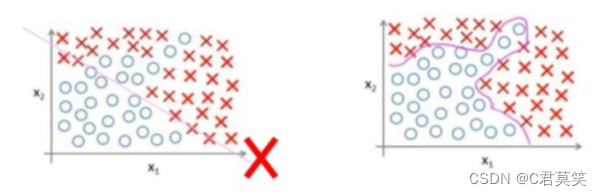
若采用线性模型进行拟合无法得到一个满意的结果,所以选择更复杂的非线性化模型,得到了复杂的分类线。
几种常见激活函数
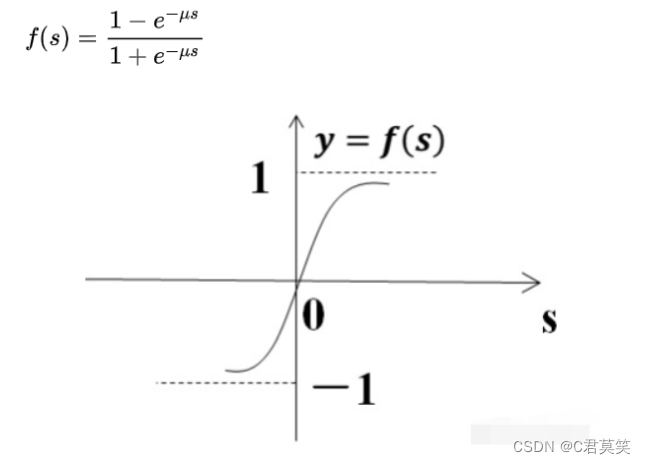
Sigmoid函数(S型函数)(最常作为激活函数)
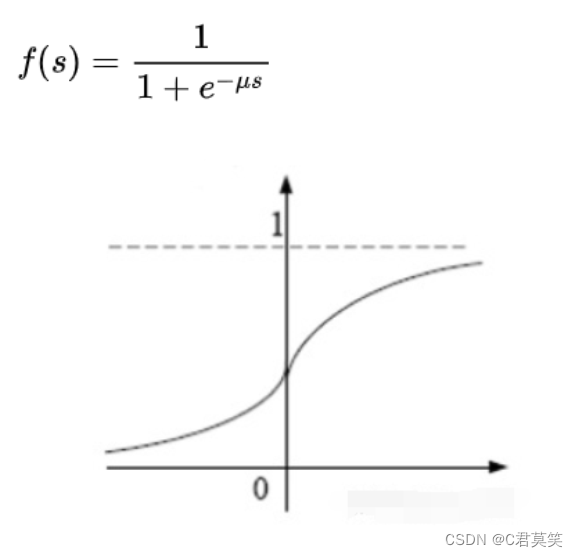
饱和函数
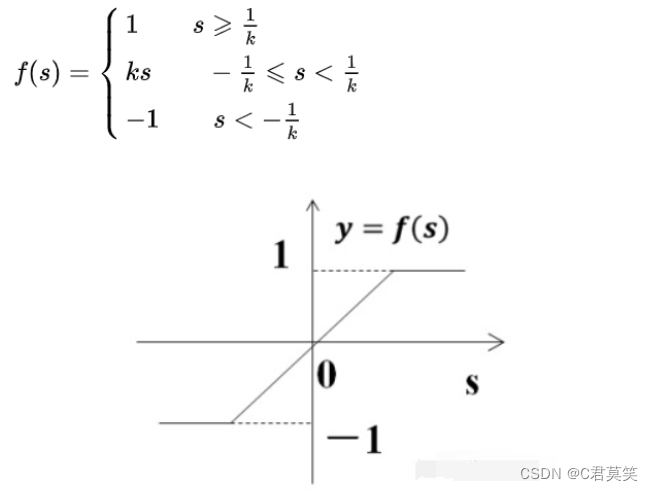
阶跃函数
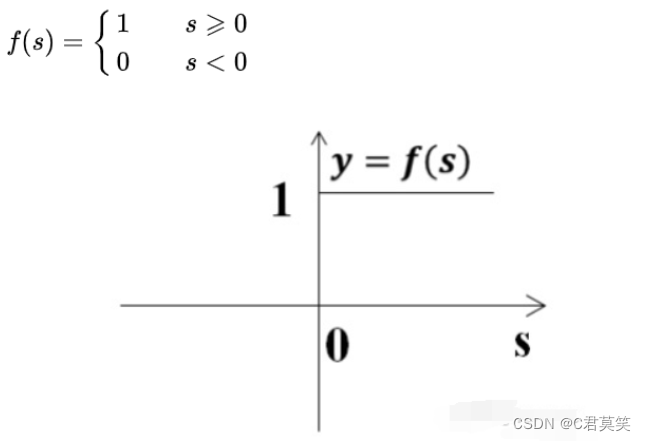
双曲函数(tanh函数)
训练神经网络
如何训练神经网络
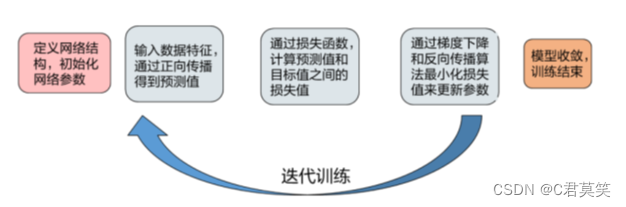
- 第一步:先随机地给参数赋值
- 第二步:优化:计算网络在训练数据集上的损失函数值,并不断地调整参数,使得损失函数值最小。
损失函数
损失函数定义
- 损失函数衡量了预测与真实样本标签的距离。
- Loss的值都会设置为和吻合程度负相关。
损失函数选择
- 回归问题的损失函数为均方误差损失函数
- 分类问题会选择交叉嫡损失函数
梯度下降法
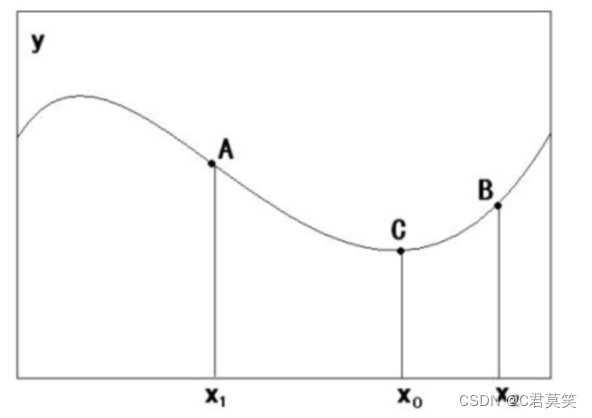
梯度下降法是一种求解函数局部极小值的迭代优化算法。
计算步骤
-
给定一个点,计算当前导数,沿着导数正负反向取 步得到新的点
-
反馈:然后重复之前的步骤,不断重复,知道满足最终条件
学习率(步长)
-
学习率(步长) 越小,则前进速度缓慢,但是更加精细
-
学习率(步长) 越大,则前进速度较快,但是比较粗糙
一般随着迭代次数增加,会逐渐减小 学习率 。即先快速,后慢速
梯度下降方法
-
批量梯度下降(BGD )
每次更新使用所有的训练数据,最小化损失函数,如果只有一个极小值,那么批量梯度下降是考虑了训练集所有数据,但如果样本数量过多,更新速度会很慢。
-
随机梯度下降(SGD )
每次更新的时候只考虑了一个样本点,这样会大大加快训练速度,但是函数不一定是朝着极小值方向更新,且SGD对噪声也更加敏感。
-
小批量梯度下降((MBGD )
MBGD每次更新的时候会考虑一定数量(batchsize)的样本,解决了批量梯度下降法的训练速度慢问题,以及随机梯度下降对噪声敏感的问题。
反向传播
反向传播原理
通过检查输出与期望之间的偏差,反馈回输入,并修正各单元之间的连接权值
梯度消失与梯度爆炸
-
梯度消失:在神经网络中,当前面隐藏层的学习速率低于后面隐藏层的学习速率,即随着隐藏层数目的增加,分类准确率反而下降了。这种现象叫梯度消失。
-
梯度爆炸:在神经网络中,当前面隐藏层的学习速率低于后面隐藏层的学习速率,即随着隐藏层数目的增加,分类准确率反而下降了。这种现象叫梯度爆炸。
梯度消失与梯度爆炸的产生原因
-
梯度消失
隐藏层的层数过多
采用了不合适的激活函数(更容易产生梯度消失 -
梯度爆炸
隐藏层的层数过多
权重的初始化值过大
详见:TensorFlow实战–使用神经网络来实现对鸢尾花数据集的分类
神经网络架构设计
深度前馈网络(前馈神经网络,多层感知机)
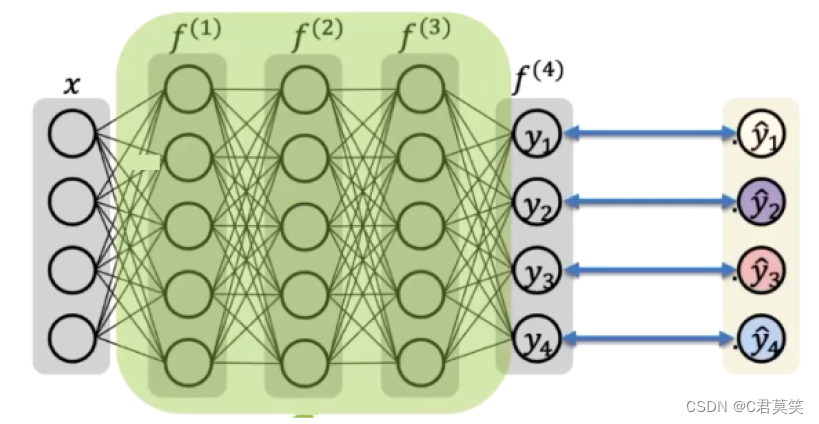
我们有三个函数 f(1), f(2) 和 f(3) 连接在一个链上以形成f3(f2(f1)),f1为网络第一层,叫输入层。f2为第二层,依次类推,中间层叫做隐藏层。最后一层为输出层。链的全长称为模型的深度。每个隐藏层都有张量值,这些隐藏层的维数为模型的宽度。
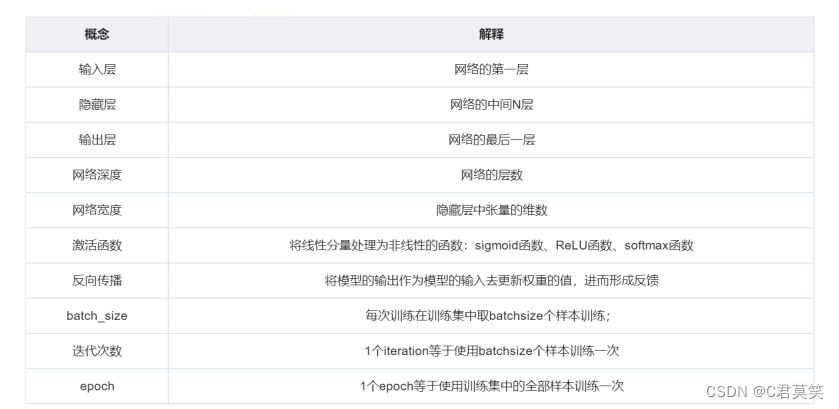
神经网络的层数是否越多越好?
- 神经网络的层数并非越多越好,随着神经网络层数的增加,会导致训练时间过长以及梯度消失的问题(增加神经元数量并不会产生梯度消失),使得网络训练不好。
- ResNet提出当网络层数过深时,网络的性能反而会下降,这是由于梯度消失造成的。而ResNet提出可以用残差结构来缓解梯度消失的问题。