(本文给出基础神经网络的工作流程解释以及相应的代码,方便小伙伴们理解,这里需要的仅仅是高等代数/线性代数的基础知识。)
为了方便,这里使用tensorflow自带的mnist数据集,我们知道图像识别一般用卷积神经网络,但这里我们将图片reshape为一个长条向量,就可以用基础神经网络来操作。
(关于卷积神经网络分类mnist数据,后续还会更新相应的博客)
为了更方便理解,我们用keras导入数据:
import numpy as np
import tensorflow as tf
from tensorflow import keras
(x_train,y_train),(x_test,y_test) = keras.datasets.mnist.load_data()
我们来看一下导入的数据样子:

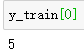
可以看出训练集x中,一个样本是一个矩阵(28乘28),对应label值y为一个数字。
(即x是图片转化成的数字矩阵,y是图片中的数字类型)
为了更方便小伙伴们理解神经网络的工作原理,我们先将label进行编码,将数字值映射成一个十维向量,数字值对应的位置为1,其余九个位置为0.
定义编码函数并编码label值:
def dense_to_one_hot(labels_dense,num_classes):
num_labels = labels_dense.shape[0]
index_offset = np.arange(num_labels) * num_classes
labels_one_hot = np.zeros((num_labels,num_classes))
labels_one_hot.flat[index_offset + labels_dense.ravel()] = 1
return labels_one_hot
y_train = dense_to_one_hot(y_train,10)
y_test = dense_to_one_hot(y_test,10)
编码后的label值:

可以看出原本的5,变成了这样一个向量,其中第6个值为1,其余为0。(从0开始计算,5是第6个)
至于为什么要这么做,后面会讲到。
由于我们今天聊的最基础的神经网络适用于一维向量的输入,所以我们把28乘28的数字矩阵拉长为1乘784维,变成一个向量:
x_train = x_train.reshape([-1,784])
x_test = x_test.reshape([-1,784])
拉长后的x形式:

此时x为一组784维的向量,这样我们的数据预处理部分就完成了。
下面来看我们今天聊的神经网络模型:
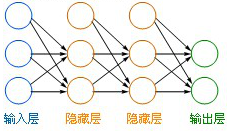
其中输入层就是我们要输入的一组一维向量,这就是我们要将x拉直的原因。每个隐藏层所做的是将输入的数据进行映射,其中包含两步:
第一步是线性映射,通过WX+b的形式,将输入数据进行线性变换,这里我们选用784乘128的W矩阵进行第一个隐藏层的操作,b为偏置项,可以用128维的零向量来初始化。
先查看一下我们的x_train数据集的shape:
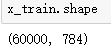
是60000个784维向量组合成的矩阵,那么我们用784乘128的W进行变换,会将其映射成60000乘128的矩阵。(其中60000表示有60000个样本,128表示将每个样本最初的784个特征映射成128个,相当于做了一次特征提取,所以神经网络是不需要特征提取的)
这里要注意的是,定义W的shape的时候,一定要保证W和输入的X可以做矩阵乘法,即在这个例子中,W是784行,刚好和输入x_train的784列相等。映射完之后,为60000乘128,所以偏置项b为128维向量。
计算完第一步之后,得到了WX+b,这是一个线性映射,而我们知道线性分类器对很多复杂的分类任务效果往往不是很好,于是有了隐藏层的第二步操作。
第二步是激活操作,将第一步得到的结果进行激活,这里我们选用ReLu激活函数,即max(x,0)。将所有小于0的值映射成0,这是一步非线性变换,可以大大增加神经网络的分类灵活度。
(关于激活函数部分,可以查看我之前的博客,《闲谈神经网络softmax激活函数》,里面详细介绍了激活操作与各种激活函数的作用和推导)
这两步结合起来就是一个隐藏层所做的工作,可以通过多个隐藏层来继续提高神经网络的灵活性,每一个隐藏层都按上述步骤处理前一个隐藏层传递的数据。
而在最后一个隐藏层结束后,我们通过softmax激活函数,将隐藏层输入的数据映射成概率向量,维度就是分类数目。其中概率向量中的每个数值是输入样本属于某个类别的概率。(这个例子中,是0,1,2,3,4,5,6,7,8,9的十分类任务,因此为十维的概率向量),最后将得到的概率向量做如下操作:
将向量中概率值最大的位置映射成1,其余映射成0。这就变成了我们之前编码后的label值。这样更加方便计算损失函数,而且也非常直观。
下面是具体代码:
#固定shape
n_hidden_1 = 128 #第一隐层输出维度
n_hidden_2 = 64 #第二隐层输出维度
n_hidden_3 = 32 #第三隐层输出维度
n_input = 784 #输入样本维度
n_class = 10 #输出分类维度
#固定x,y
x = tf.placeholder('float',[None,n_input])
y = tf.placeholder('float',[None,n_class])
#固定W,b的shape
stddev = 0.1
weights = {
'w1' : tf.Variable(tf.random_normal([n_input,n_hidden_1],stddev=stddev)), #定义w1为n_input * n_hidden_1的矩阵,即784*128
'w2' : tf.Variable(tf.random_normal([n_hidden_1,n_hidden_2],stddev=stddev)),
'w3' : tf.Variable(tf.random_normal([n_hidden_2,n_hidden_3],stddev=stddev)),
'out' : tf.Variable(tf.random_normal([n_hidden_3,n_class],stddev=stddev))
}
biases = {
'b1' : tf.Variable(tf.random_normal([n_hidden_1])),
'b2' : tf.Variable(tf.random_normal([n_hidden_2])),
'b3' : tf.Variable(tf.random_normal([n_hidden_3])),
'out' : tf.Variable(tf.random_normal([n_class]))
}
这段代码所做的神经网络包含了三个隐藏层。其中w1,w2,w3分别代表三个隐藏层的W,b1,b2,b3分别代表三个隐藏层的偏置。(再次提醒隐藏层做的第一步是线性映射,即将输入X映射成WX+b)

#隐藏层操作:
def multilayer_perceptron(_X,_weights,_biases):
layer_1 = tf.nn.relu(tf.add(tf.matmul(_X,_weights['w1']),_biases['b1'])) # W1 * X + b1 之后进行relu操作
layer_2 = tf.nn.relu(tf.add(tf.matmul(layer_1,_weights['w2']),_biases['b2']))
layer_3 = tf.nn.relu(tf.add(tf.matmul(layer_2,_weights['w3']),_biases['b3']))
return (tf.matmul(layer_3,_weights['out']) + _biases['out'])
其中,tf.matmul是矩阵乘法运算,tf.add是向量加法,tf.nn.relu是表示用ReLu激活函数进行激活操作。
这样神经网络的前向传播就定义好了,接下来我们处理损失函数部分。
损失函数是神经网络要优化的指标,整个前向传播是为了输出预测值,而整个反向传播则是优化各个隐层的W和b,让这些参数能够更适应分类这个数据集,其优化方向就是损失函数梯度方向,优化步长就是定义的学习率。
(神经网络反向传播优化理论部分参考https://blog.csdn.net/softdiamonds/article/details/80101440)
在这个例子中,我们用tf.nn.softmax_cross_entropy_with_logits操作去定义损失函数(loss)。
首先明确,loss也就是损失函数,是我们要最小化的目标函数。
tf.nn.softmax_cross_entropy_with_logits(logits, labels, name=None)
除去name参数用以指定该操作的name,与方法有关的一共两个参数:
第一个参数logits:就是神经网络最后一层的输出,如果有batch的话,它的大小就是[batchsize,num_classes],单样本的话,大小就是num_classes
第二个参数labels:实际的标签,大小同上
具体的执行流程大概分为两步:
第一步是先对网络最后一层的输出做一个softmax,这一步通常是求取输出属于某一类的概率,对于单样本而言,输出就是一个num_classes大小的向量([Y1,Y2,Y3…]其中Y1,Y2,Y3…分别代表了是属于该类的概率)
softmax的公式是:
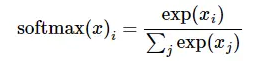
至于为什么是用的这个公式?可以参考我之前的博客,《闲谈神经网络softmax激活函数》
第二步是softmax的输出向量[Y1,Y2,Y3…]和样本的实际标签做一个交叉熵,公式如下:
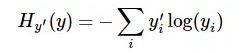
其中
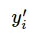
指代实际的标签中第i个的值(在这个例子中,如果是3,那么标签是[0,0,0,1,0,0,0,0,0,0],除了第4个值为1,其他全为0)
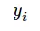
就是softmax的输出向量[Y1,Y2,Y3…]中,第i个元素的值
显而易见,预测越准确,结果的值越小(别忘了前面还有负号),最后求一个平均,得到我们想要的loss。
注意!!!这个函数的返回值并不是一个数,而是一个向量(反复指出之前对label进行编码是为了这一步),如果要求交叉熵,我们要再做一步tf.reduce_sum操作,就是对向量里面所有元素求和,最后才得到。如果求loss,则要做一步tf.reduce_mean操作,对向量求均值。
上面这些综合起来,用一行代码完成就是tf.nn.softmax_cross_entropy_with_logits
这就有了下面的代码:
#predict
pred = multilayer_perceptron(x,weights,biases)
#loss
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=pred,labels=y))
optm = tf.train.GradientDescentOptimizer(learning_rate=0.001).minimize(cost)
#accuracy
corr = tf.equal(tf.argmax(pred,1),tf.argmax(y,1))
accr = tf.reduce_mean(tf.cast(corr,'float'))
其中pred是预测值,cost是损失函数,optm表示我们要最小化损失函数,学习率为0.001
accr是分类准确率。
到现在我们已经将神经网络的前向传播和反向传播定义好了。可以进行迭代了。
在开始迭代之前,要先说明一些事项。
给初次接触tensorflow编程的小伙伴们解释一下batch,batch_size,epoch的概念。
比如有10000个图片,计算机无法一次计算这么大的数据,我们一般选择128,或64个数据为一个batch,128或64就是一个batchsize。我们将10000个数据分成几个batch进行迭代,每个batch迭代完优化一次参数,所有样本迭代一遍为一个epoch(这个例子中,若选择64为batchsize,那么一个epoch就是(10000/64)取整+1 个batch,权重参数在一个epoch期间也是更新了这些次,对于剩余样本不足一个batch的情况,我们在所有样本中随机抽取补满这个batch。如果将epoch值设成10次,意味着所有样本基本上都要迭代10遍(被抽到补位的样本被迭代的次数要多一些)。
这里给大家提供一个逐个batch迭代的模板。(也正是因为这个原因,再加上解释之前的编码操作,我才没有用input_data进行mnist数据下载,因为这样做直接什么都做好了,也就不需要这些代码的操作,不利于小伙伴们理解。)
x_train = np.asmatrix(x_train) #将x_train转变成矩阵的形式
# serve data by batches
epochs_completed = 0
index_in_epoch = 0
num_examples = x_train.shape[0]
def next_batch(batch_size):
global x_train
global y_train
global index_in_epoch
global epochs_completed
start = index_in_epoch
index_in_epoch += batch_size
# when all trainig data have been already used, it is reorder randomly
if index_in_epoch > num_examples:
# finished epoch
epochs_completed += 1
# shuffle the data
perm = np.arange(num_examples)
np.random.shuffle(perm)
x_train = x_train[perm]
y_train = y_train[perm]
# start next epoch
start = 0
index_in_epoch = batch_size
assert batch_size <= num_examples
end = index_in_epoch
return x_train[start:end], y_train[start:end]
有了这个next_batch模板,就可以直接调用进行迭代了。
下面进行tensorflow的初始化操作(这个没什么可说的,用了tensorflow这个框架就得按照人家的规定来):
#初始化
init = tf.global_variables_initializer()
#迭代
training_epochs = 100
batch_size = 100
display_step = 10
sess = tf.Session()
sess.run(init)
之后进行迭代操作,同时规定一个间隔来打印一些值(损失,训练集,测试集准确度)
for epoch in range(training_epochs):
avg_cost = 0
total_batch = int(len(x_train)/batch_size)
for i in range(total_batch):
batch_xs, batch_ys = next_batch(batch_size)
feeds = {x:batch_xs, y:batch_ys}
sess.run(optm, feed_dict=feeds)
avg_cost += sess.run(cost, feed_dict=feeds)
avg_cost = avg_cost / total_batch
if (epoch+1) % display_step ==0:
print('epoch:%d,avg_cost:%.4f'%(epoch,avg_cost))
train_acc = sess.run(accr,feed_dict=feeds)
print('train_acc:%.4f'%train_acc)
feeds = {x:x_test, y:y_test}
test_acc = sess.run(accr,feed_dict = feeds)
print('test_acc:%.4f'%test_acc)
这里我们进行了100个epoch的迭代,看一下效果:
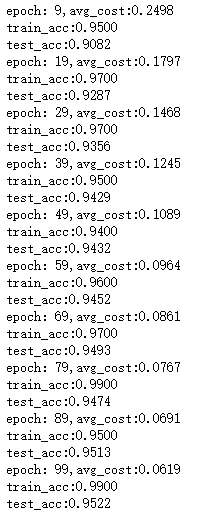
可以看出起初精度并不高,当迭代完20个epoch之后,分类精度就会有一个很大的提升,之后也没有很大的变化,可以知道这类神经网络对mnist数据集的分类效果就是95%左右。
这是将图片拉直后运用基础神经网络的效果,这并不是处理图片数据最好的网络。我们选用这个数据集主要目的是为了和之后的精度进行对比。
在之后的博客中,我们会介绍专门用于图像分类的另一种神经网络——卷积神经网络
(先给个数字吧,用这种网络训练出的模型,分类精度能达到1.0)
(说明一下我只是个大四在读学生,在自学深度学习,期间遇到很多问题,通过各种资料解开了疑问。写这篇博客的目的是加深对理论的理解,同时也希望能给和我一样存在疑问的初学者一些参考。所以请各位大佬在看到错误的时候指出来,不胜感激!)
