【导读】
本篇博客讲解的是2020年由清华大学李国良教授团队发表在ICDE上的论文,介绍它所提出的算法与实验结果,并结合实际情况给出一些思考。
原文链接:
http://dbgroup.cs.tsinghua.edu.cn/ligl/papers/icde2020-learnedjoinorder.pdf

Part 1 - 背景
连接顺序选择(Join Order Selection, JOS)是一个为SQL查询寻找最佳连接顺序的问题。作为数据库查询优化器的主要关注点已经被广泛研究了几十年。这个问题很难,因为它的解空间很大,彻底遍历解空间来寻找最佳连接顺序的代价是非常昂贵的。传统的方法通常基于基数估计和代价模型,与启发式剪枝相结合,通过一些剪枝技术来缩小搜索可能的连接顺序的解空间。
尽管经过几十年的努力,传统的优化器在处理复杂的SQL查询时仍然存在低可扩展性或低准确性的问题。基于动态规划(DP)的算法通常会选择最优方案,但代价非常昂贵。启发式方法,如GEQO、QuickPick-1000和GOO,可以更快地计算计划,但往往产生糟糕的计划。
近年来,基于机器学习(ML)和深度学习(DL)的基于学习的优化器(Learned Optimizer)方法在数据库界越来越受欢迎。特别是基于深度强化学习(Deep Reinforcement Learning, DRL)的方法,如ReJOIN和DQ,已经显示出了令人满意的结果——它们可以生成与原生查询优化器一样好的计划,但在学习后执行的速度相比原生查询优化器更快。但是,现有的基于DRL的学习优化器将连接树编码为固定长度的向量,其中向量的长度由数据库中的表和列决定。这将导致两个问题:
1. 这些向量不能捕获连接树的结构信息,可能会导致连接顺序选择到一个糟糕的计划;
2. 当数据库模式发生变化,如添加列/表或多别名表名时,这个基于学习的优化器将会失效,这需要一个新的不同长度的输入向量,然后再重新训练神经网络。
在本文中,作者提出了一种新的基于学习的优化器RTOS,它使用强化学习和树状结构长短期记忆(tree-LSTM)来进行连接顺序选择。RTOS对现有的基于DRL的方法进行了两方面的改进:
(1) 采用图神经网络来捕获连接树的结构;
(2) 支持对数据库模式和多别名表名的修改。
在Join Order Benchmark (JOB)和TPC-H上的大量实验表明,RTOS优于传统优化器和现有的基于drl的学习优化器。
Part 2 - 相关工作
DRL,深度强化学习相关概念:
关于强化学习的概念性解释在早先的博客《Constraint-aware SQL Generation Using Reinforcement Learning》中也有提到,这里不再重复赘述Agent、Environment、State、Action、Reward等概念,感兴趣的读者也可查找相关资料加深了解。
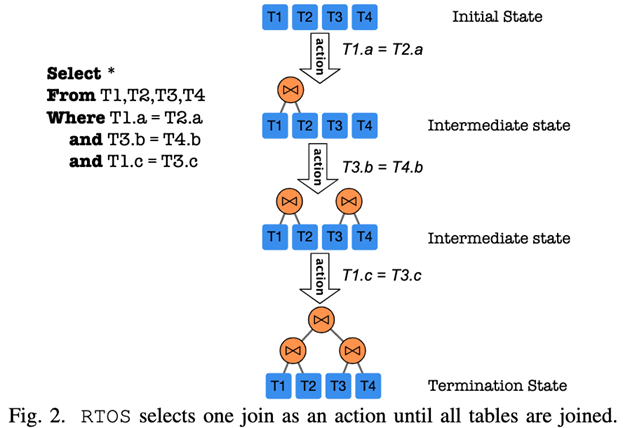
在RTOS中Agent对应优化器,通过与Environment(对应DBMS)的试错交互从反馈中学习。对于图中所示的一条SQL查询语句,随着强化学习过程的推进会进入不同的State(每个State对应着连接计划)。RTOS读取当前计划并利用Tree-LSTM来计算估计的长期Reward(例如,哪个表应该连接起来以使当前状态更完整)。然后它会选择具有最大Reward(对应最小Cost)的预期最佳Action。当所有的表都被连接(即,导出一个完整的连接计划)时,连接计划将被发送到DBMS执行。
DQ,《Learning to Optimize Join Queries With Deep Reinforcement Learning》中提出的基于DRL学习优化器方法:
DQ将连接顺序选择问题抽象为一个马尔可夫决策过程。DQ使用了DQN(Deep Q Network)作为强化学习模型来指导连接顺序的选择,由于DQN中的代价估计函数Q-function计算代价过高,因此使用一个两层的MLP(Multilayer Perceptron)来学习Q-function。神经网络的输入是当前的State,包括了SQL语句中的查询信息以及通过连接左侧右侧状态表示的连接操作信息。
REJOIN,《Deep Reinforcement Learning for Join Order Enumeration》中提出的基于DRL学习优化器方法:
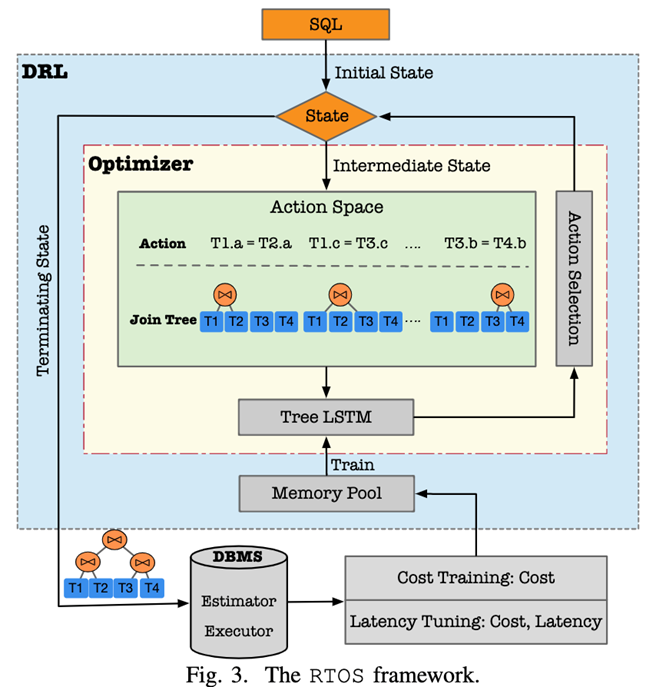
ReJOIN主要使用了邻近策略优化算法(Proximal Policy Optimization)来指导连接顺序的选择。其中的关键组成是一个用于策略选取的神经网络。这个神经网络通过输入向量化的状态信息进行训练,这些信息包含:由深度信息组成的树结构向量、连接谓词向量和选择性谓词向量。对于不同的SQL语句而言,存在不同的神经网络参数和Reward,ReJOIN会根据这条SQL语句之前的参数和Reward,来估算以后的Reward,从而达到对测试集中的SQL语句进行连接顺序选择的目的。
现有基于DRL方法的不足:
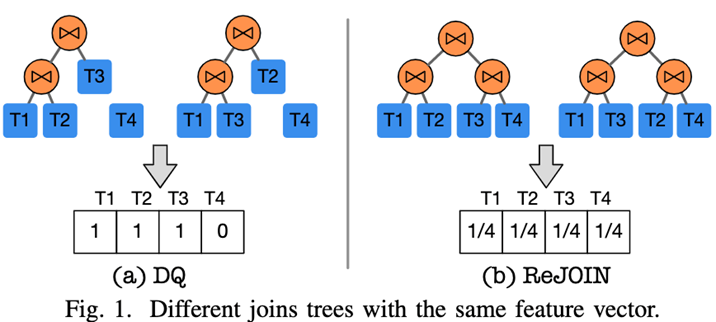
假设一个数据库有4个表T1、T2、T3、T4。DQ使用独热编码(1表示表在树中,否则为0)来编码连接树:图中可以发现((T1,T2), T3)和((T1,T3),T2)具有相同的特征向量[1,1,1,0]。ReJOIN使用连接表的深度构造特征向量:图(b)中可以发现,每个表的深度是d = 2,((T1,T2),(T3 T4))和((T1, T3), (T2,T4))具有相同的特征向量[1/4,1/4,1/4,1/4]。
Part 3 - RTOS框架
对于上述提到的基于DRL的学习优化器方法, 由于它们无法捕获连接树的结构特征,进而导致无法总是获得代价低、执行时间短的方案。此外这些方法无法够适应一些改变数据库模式的操作,如添加列/表或多别名表名后,需要重新对神经网络进行训练。因此本文作者提出了RTOS,致力于捕捉连接树的结构特征,对计划进行更好的估计得到执行时间低的计划,同时能够更快的适应一些会改动数据库有的操作。
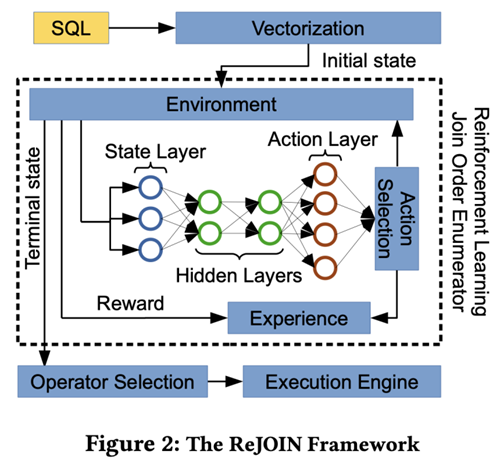
整个RTOS框架由两部分组成:DRL Optimizer和 DBMS。
1. DRL Optimizer中包含State、Optimizer和Memory Pool。State维护连接进程的当前状态信息,具体内容在Part4部分解释;Optimizer对应于RL中的Agent,它是整个系统的核心部分。对于给定的状态,可以将每个候选连接条件视为一个Action;Memory Pool记录RTOS生成的计划的状态和来自DBMS的反馈。
2. DBMS用于为RTOS生成的连接计划进行开销估算。RTOS为给定的查询生成一个连接计划,然后将其传递给DBMS,例如PostgreSQL。我们使用DBMS中的两个组件,Estimator和Executor。Estimator可以给出计划的Cost,使用统计数据来估算开销,而不需要执行。而Executor用户获得计划实际执行的Latency。
另外,在模型训练方面,RTOS使用了两阶段训练的方法。具体来说,先用Cost作为反馈来训练得到开销较低的模型;再用真实执行的Latency作为反馈来调整模型参数。
Part 4 - States表示
State的表示由三部分组成:
1.输入SQL查询的表示:用于描述查询的全剧信息,通过神经网络进行表示,包含了查询需要连接的表以及查询中的谓词信息等。
2.表和列的表示:通过神经网络表示查询中的表和列信息,依据谓词计算特征,对参与计算的列进行表示,然后通过池化得到表的表示。
3.连接数和连接的表示:通过多种Tree-LSTM的组合表示的连接树和连接状态信息。
前两种信息包含了之前方法:DQ,ReJOIN中提到的特征向量信息,最后一种表示保留了连接顺序以及完整的连接树的结构信息。通过神经网络来表示的状态信息可以实现在需要修改数据库模式,例如新增加一列或者一个表时,可以通过申请新的参数来实现,而不需要重新训练模型。
RTOS强化学习策略:

本文使用了DQN的深度强化学习方法,通过设计一个Q-network来估计每个状态的Q值。在对训练的反馈进行收集时,由于Latency需要实际执行SQL查询来获取,收集的代价较高。而Cost作为Latency的近似的估计,不需要实际执行SQL查询,收集的代价较低,并且可以实现和Latency一样为指导连接顺序选择。因在RTOS的强化学习的反馈和训练的过程分为两个阶段:
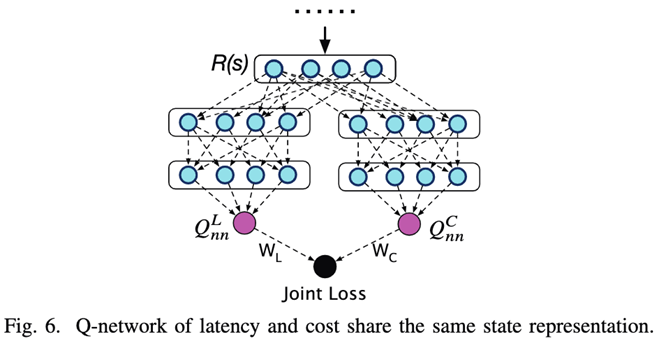
第一阶段,使用SQL语句的Cost作为反馈,生成大量的训练数据,使得RTOS的基于DRL的学习优化器能够达到传统方法,例如动态规划相同的效果,选择出Cost较低的连接顺序的计划。
第二阶段,使用实际执行SQL语句得到的Latency作为反馈微调RTOS的模型。通过实际的Latency微调可以矫正RTOS中对Cost估计错误的连接顺序的计划。即表现为估算的Cost值很高而实际执行的Latency较低的计划,反之亦然。
Part 5 - 实验结果
论文基于PostgreSQL构建了RTOS,实验采用的benchmark是JOB(Join Order Benchmark)和TPC-H。JOB是一个基于IMDB的真实数据集,提供真实的工作负载,它有来自33个模板的113个查询,包含了3.6GB的数据(计算索引时为11GB)和21张表。TPC-H是一个标准的行业数据库基准测试,有8张表。论文使用了22个模板生成了4GB数据和110个查询。除了上述提到的baseline(例如DQ,ReJOIN,DP)以外,论文还比较了SkinnerDB(一种基于强化学习策略的方法)和QuickPick(一种贪心算法)。实验结果如下:
COST结果:

LATENCY结果:
JOB数据集上结果:

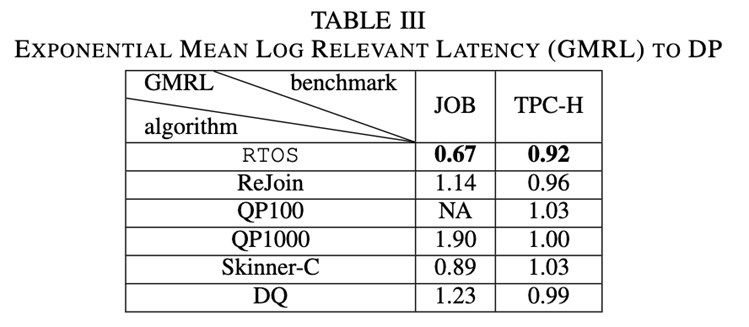
第一个指标:论文以DP作为基线,并按照之前的工作报告其他方法的MRC(mean relative cost,平均相对成本 ),其中MRC = 1表示与DP性能相同。观察Cost和Latency的结果可以发现,RTOS在Cost上要优于其他四种方法,且几乎与DP相等,在Latency更佳,是所有方法中延迟最低的。
第二个指标:论文把数据集中的查询按照模板进行分类,计算GMRL( Geometric Mean Relevant Latency,几何平均相关延迟),从图9中可以发现,大多数情况下RTOS的性能都不弱于DP,且优于其他方法。对于T20,T26,T28,T29等RTOS的性能要远远好于DP,是因为实验数据中的测试模板多数是比较长或者是带有多别名的查询,传统的开销模型往往会出现估算不准确的问题,导致基于Cost选择出的计划可能不是最优,而RTOS可以解决这一问题,通过从查询执行的latency中进行学习,可以修正选择出的计划,实现更高性能。
TPC-H数据集上结果:
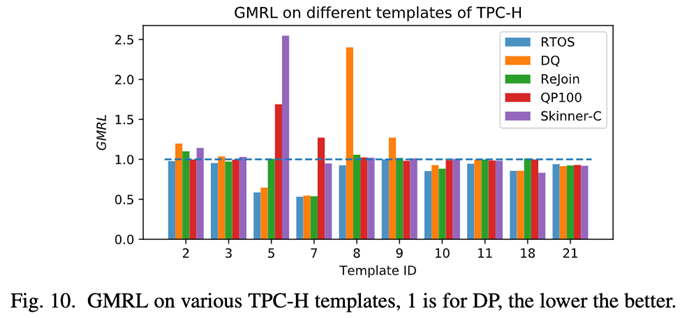
图10显示了TPC-H不同模板上的,图中没有展示DRL方法与DP方法执行相同的模板,以获得更好的视图。可以发现对于所有模板,RTOS生成的规划并不比DP差(在GMRL= 1处的水平线),也比其他方法好。
Part 6 - 总结与思考
本文介绍了将机器学习应用在连接顺序选择问题上的方法:使用Tree-LSTM学习连接计划的树形结构的RTOS。首先,RTOS使用了深度强化学习技术解决JOS问题,在此基础之上,采用了Tree-LSTM模型为连接状态进行编码。基于前两个工作设计了基于DRL的学习优化器,利用SQL解析的知识、DRL的连接顺序选择、DNN的计划代价估算,可以在成本和延迟两个基准上生成良好的计划;并通过证明了该方法能够很好地学习连接树的结构,获取连接操作的信息。论文还证明,该代价可以预先训练神经网络,减少延迟调优时间。然而,论文中有提到,在实际使用场景下还存在一些问题,例如:训练时间过长、不能根据不同数据库状态适应性的选择连接顺序等问题。