为什么要用缓存?
- 在一个网页应用中,当访问请求非常多时,随之而来的也会有很多问题
- 如果全部增删改查都在数据库完成,由于数据库的数据是存储在磁盘上的,那么就会带来性能问题
- 使用缓存中间件,例如
Redis,就是为了解决数据的高速访问所带来的问题,来缓解数据访问的压力 - 使用缓存,可以
提升应用程序性能、提高读取吞吐量(IOPS)、消除数据库热点、可预测的性能、减少后端负载、降低数据库成本
Redis 概述
-
Redis是一个开源的Key-Value存储系统,其中Value支持String、list、set、hash、zset五种数据结构,这些数据都支持push/pop、add/remove、取交集并集、排序等丰富的操作,并且这些操作都是原子性的 -
与同为
NoSQL型缓存数据库的Memcached类似,Redis 的数据都存在内存中,数据的运算都在内存中进行,不会发生IO(这也是Redis为什么这么快的一个原因) -
区别是
Redis具备持久化方式,会周期性的把更新的数据写入磁盘(RDB)或者把修改操作追加写入记录文件中(AOF) -
一句话概括就是:Redis的数据存放在内存中,但Redis也支持持久化将数据存入磁盘或文件。
-
另外,Redis 是单线程的,但是多任务并发时可以开启多个 Redis,并且Redis支持主从同步,避免了宕机带来的影响,以及写时同步技术实现了
数据读写分离(主机负责写入、从机负责读取)
缓存的设计
- 插入
1、新增数据至数据库 - 更新
1、删除缓存中对应的数据
2、修改数据库中的数据 - 删除
1、删除缓存中对应的数据
2、删除数据库中的数据 - 查找
1、查询缓存中的数据,存在即返回查询的数据
2、缓存中不存在数据则查询数据库,数据库存在数据则返回数据库中的数据并同步更新到缓存
3、 缓存和数据库都不存在数据,返回null
这里在缓存中只有删除和增加的操作,这样就能避免缓存和数据库数据不一致的问题
什么是缓存穿透?
-
当加入了缓存后,数据请求和数据库之间就多了一个缓存层

-
缓存穿透,顾名思义,就是穿过缓存,直接去访问数据库。
-
那这样看上去,缓存穿透仿佛是个很正常的行为啊,为什么那么多公司企业会把缓存穿透当作一个问题去找寻解决方案呢?
-
思考一下,如果我查询的数据在缓存和数据库中都不存在,那么每一次查询都要查询一次缓存和数据库,这样就会带来额外的IO操作和开销。
-
那么如果有一个用户就是无限基于这个不存在的key来请求查询,那该怎么办呢?
扫描二维码关注公众号,回复: 11416813 查看本文章
-
这种情况下,你可以将在数据库查询不到的数据放在缓存中,并存入 NULL 值,这样就能减少数据库的性能消耗。
-
但是如果此时有恶意攻击者已经发现你系统的这个漏洞,频繁地用不存在的数据的Key来进行请求,这样你又该怎么去防范呢?
-
如果仍使用存入 NULL 值的方法,就会导致缓存中有大量的Key - NULL这样的无用键值对
-
如果我们能通过一个过滤器,来判断这个值是否存在,再去查询缓存或者数据库,这样,就能过滤掉很多没有意义的请求。

-
这样,我们只需要建造这样的一个Filter就行了,我们的需求也就转变成:如何在一个大量的、无序、无重复的数据集中快速地判断一个值是否存在
如何解决?
- 根据需求,我们需要解决的,一个是存放数据集的容器,一个是高效的算法
对于容器
- 对于容器,要求有两点,一个是占用空间小(在大量的数据中,空间占用会非常的大),一个是支持快速的查找(大量的数据,如果不支持快速查找,那么效率会非常的低下)
- 因为我们只需要判断数据是否存在,所以只需要
0和1来表示即可;对于快速查找,数组的查找速度是最快的,只需要给定一个下标,使用Bit-map 位图是最适合的 - 不懂的话可以参考《BitMap算法简介》

对于算法
-
对于算法,我们需要保证,第一,每次运算完后的结果都是始终保持一致的,第二,允许任意的输入且保证固定长度的输出

-
能满足这样两个条件的算法,就是 哈希算法
如何判断一个值是否存在呢?
-
如果我们基于一个运算方法,获得了这个值存放结果的索引,当数据一多,就会导致同一个位置需要表示两个值是否存在,这样就会导致误判

-
怎么解决呢?很简单,就是多次进行哈希运算,减少发生Hash碰撞的几率
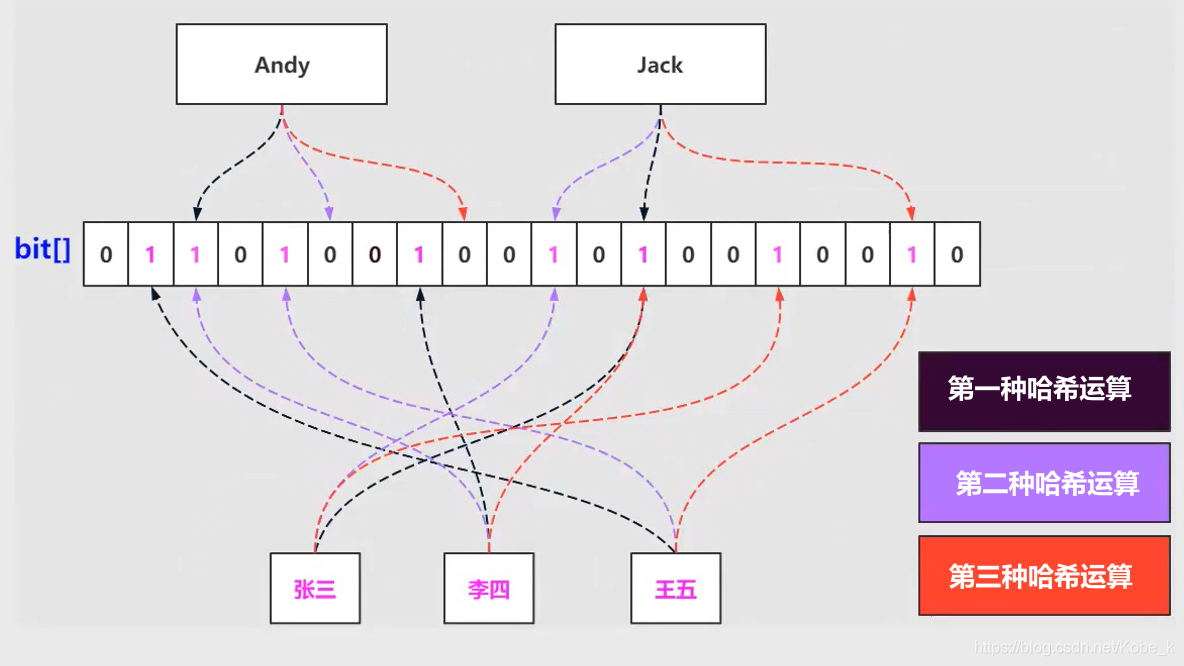
-
这样只要保证合理的位数组长度和合理的哈希函数的个数,就能尽可能地减少发生Hash碰撞的概率。但是,注意了,
只能降低,不能完全杜绝,因此也就是不存在漏报,存在误报,因为也还是有可能会发生同样的位置表示不同的数据,只是这个概率减小了。 -
这,也就是布隆过滤器的原理
布隆过滤器
-
布隆过滤器(Bloom Filter)是1970年由布隆提出的。
-
它实际上是一个很长的二进制向量和一系列随机映射函数。
-
布隆过滤器可以用于检索一个元素是否在一个集合中。
-
它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难。
-
布隆过滤器是一种比较巧妙的概率型数据结构(probabilistic data structure),可以用来告诉你 “
某样东西一定不存在或者可能存在” -
布隆过滤器的数学依据
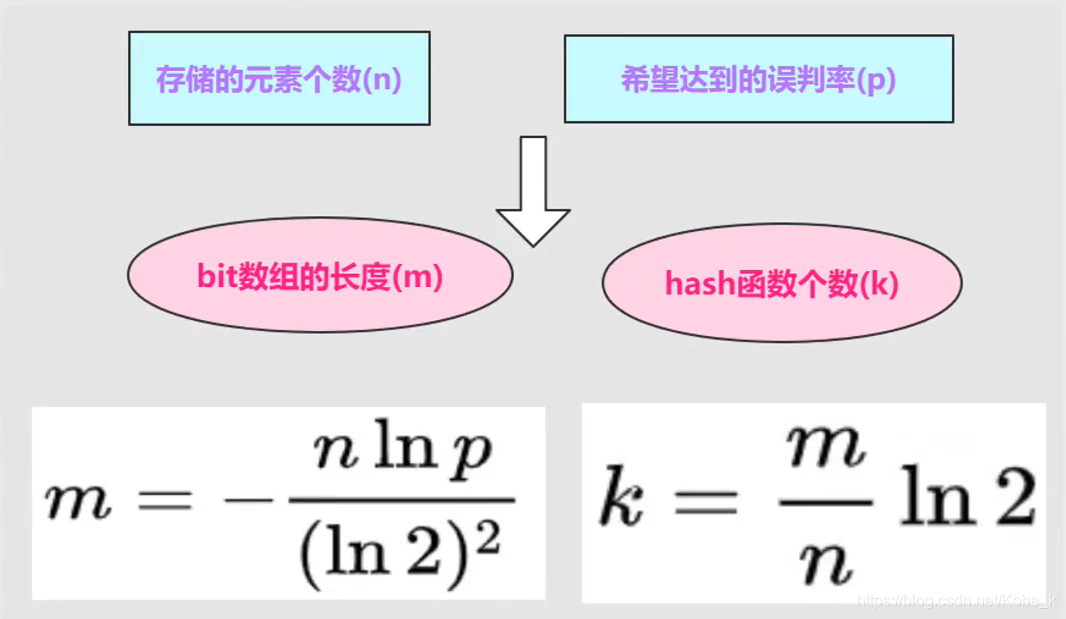
-
所以,当一个请求经过布隆过滤器的时候,当返回的结果说没有该值的时候,就表示一定没有该值,那么直接返回空结果即可;如果返回的结果说存在该值的时候,就可以继续去向缓存和数据库发送请求,但是也不一定能获得该值,因为存在误判。
手写布隆过滤器(基于Java)
- 首先需要解决第一个问题,Java的八大基本数据类型中,没有 bit 数组,那该怎么去表示呢?
- 既然没有位数组,那我们可以使用字节数组,众所周知,
1byte = 8bit,那么就可以通过byte表示位数组,当然也可以使用其他的数据类型来模拟,例如 long类型占8个字节,int类型占4个字节等
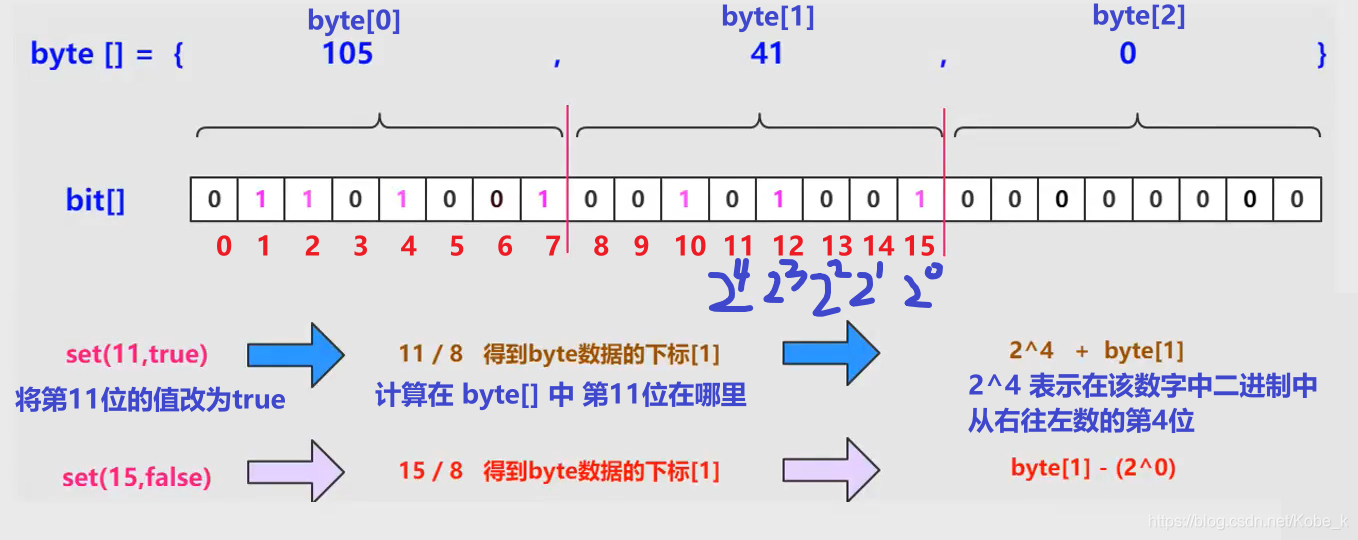
在Java中,可以使用
java.util.BitSet工具类来完成模拟位数组的操作
// BitSet 中是使用 long 类型来模拟 位数组
/**
* The internal field corresponding to the serialField "bits".
*/
private long[] words;
// 实例化时传入长度
/**
* Creates a bit set whose initial size is large enough to explicitly
* represent bits with indices in the range {@code 0} through
* {@code nbits-1}. All bits are initially {@code false}.
*
* @param nbits the initial size of the bit set
* @throws NegativeArraySizeException if the specified initial size
* is negative
*/
public BitSet(int nbits) {
// nbits can't be negative; size 0 is OK
if (nbits < 0)
throw new NegativeArraySizeException("nbits < 0: " + nbits);
initWords(nbits);
sizeIsSticky = true;
}
// 初始化长度
private void initWords(int nbits) {
// 将 位数组长度 转换成 long类型数组的长度
// 就是找出 位数组中最后一位 所在的 long数组下标,然后 +1 表示长度
words = new long[wordIndex(nbits-1) + 1];
}
// 计算 给定的位数组索引下标 在 long类型数组中的下标
/**
* Given a bit index, return word index containing it.
*/
private static int wordIndex(int bitIndex) {
// 右移一位等于除以2^1
// 1个long类型有64位,所以将位下标除以64,即可得到long数组的下标
// 2^6 = 64
return bitIndex >> ADDRESS_BITS_PER_WORD;
}
private final static int ADDRESS_BITS_PER_WORD = 6;
/* --------------- 再来看看BitSet中的set方法 ----------------- */
// 将某个位下标的值改为 true
/**
* Sets the bit at the specified index to {@code true}.
*
* @param bitIndex a bit index
* @throws IndexOutOfBoundsException if the specified index is negative
* @since JDK1.0
*/
public void set(int bitIndex) {
if (bitIndex < 0)
throw new IndexOutOfBoundsException("bitIndex < 0: " + bitIndex);
// 获得 long数组下标
int wordIndex = wordIndex(bitIndex);
// 确保 long数组 足够长可以容纳下该 位下标 ,如果不够长就扩大 long数组
expandTo(wordIndex);
// 将获得的值做 或运算
// 将 1 左移 bitIndex位 假设要修改第4位,那么就是将 1 左移 4 位,得到 10000
// 然后 或上 10000 ,就能将第4位改成 1
words[wordIndex] |= (1L << bitIndex); // Restores invariants
// 检查不变量
checkInvariants();
}
/**
* Sets the bit specified by the index to {@code false}.
* 将索引指定的位设置为 false
* @param bitIndex the index of the bit to be cleared
* @throws IndexOutOfBoundsException if the specified index is negative
* @since JDK1.0
*/
public void clear(int bitIndex) {
if (bitIndex < 0)
throw new IndexOutOfBoundsException("bitIndex < 0: " + bitIndex);
// 获得 long数组下标
int wordIndex = wordIndex(bitIndex);
// 如果要设置成false,就需要保证这个下标在 long数组表示的范围之内
if (wordIndex >= wordsInUse)
return;
// 改成 false 操作
// 将 1 左移 bitIndex位 例如 10000
// 然后取反 变成 01111
// 再做与操作 即可将指定位置设置位 false
words[wordIndex] &= ~(1L << bitIndex);
recalculateWordsInUse();
checkInvariants();
}
/**
* Ensures that the BitSet can accommodate a given wordIndex,
* temporarily violating the invariants. The caller must
* restore the invariants before returning to the user,
* possibly using recalculateWordsInUse().
* 确保BitSet可以容纳给定的wordIndex,
* 暂时违反不变式。 调用者必须
* 在返回给用户之前恢复不变式,
* 可能使用recalculateWordsInUse()。
* @param wordIndex the index to be accommodated.
*/
private void expandTo(int wordIndex) {
int wordsRequired = wordIndex+1;
if (wordsInUse < wordsRequired) {
ensureCapacity(wordsRequired);
wordsInUse = wordsRequired;
}
}
/**
* Every public method must preserve these invariants.
* 每个公共方法都必须保留这些不变式。
*/
private void checkInvariants() {
assert(wordsInUse == 0 || words[wordsInUse - 1] != 0);
assert(wordsInUse >= 0 && wordsInUse <= words.length);
assert(wordsInUse == words.length || words[wordsInUse] == 0);
}
/**
* The number of words in the logical size of this BitSet.
* 此BitSet的逻辑大小中的单词数,即 long数组的单词数
*/
private transient int wordsInUse = 0;
/**
* Sets the field wordsInUse to the logical size in words of the bit set.
* 将字段wordsInUse设置为以位设置的字的逻辑大小
* WARNING:This method assumes that the number of words actually in use is
* less than or equal to the current value of wordsInUse!
* 警告:此方法假定实际使用的单词数为小于或等于wordInUse的当前值!
*/
private void recalculateWordsInUse() {
// Traverse the bitset until a used word is found
int i;
for (i = wordsInUse-1; i >= 0; i--)
if (words[i] != 0)
break;
wordsInUse = i+1; // The new logical size
}
- 详情参考《BitSet源码分析》
- 当设置为
true时,是或1操作;当设置为false时,就是与0操作;通过左移
解决完存储容器的问题之后,就可以着手算法的问题
package bloomfilter;
import java.math.BigInteger;
import java.security.MessageDigest;
import java.security.NoSuchAlgorithmException;
import java.util.BitSet;
/**
* 手写布隆过滤器
* @author Long
*/
public class Filter {
// 预期存储的数据量
private int n;
// 误判率
private double p;
// bit[] length
private int m;
// hash函数个数
private int k;
// bit[]
private BitSet bitMap;
public Filter(int n, double p){
this.n = n;
this.p = p;
}
/**
* 添加元素
* @param element 元素
*/
public void addElement(String element){
// 懒加载
if (bitMap == null){
init();
}
int[] posArr = getIndexes(element);
for (int tempos: posArr) {
bitMap.set(tempos, true);
}
}
/**
* 初始化过程
*/
private synchronized void init(){
if (this.m == 0) {
this.m = (int) ((-n * Math.log(this.p)) / (Math.log(2) * Math.log(2)));
}
if (this.k == 0) {
this.k = Math.max(1, (int) Math.round(this.m / this.n * Math.log(2)));
}
if (bitMap == null) {
bitMap = new BitSet(this.m);
}
System.out.println("this.m : " + this.m);
System.out.println("this.k : " + this.k);
}
private int[] getIndexes(String element){
int[] retArr = new int[this.k];
for (int i = 0; i < this.k; i++) {
retArr[i] = MD5Hash(element + i) % this.m;
}
return retArr;
}
private int MD5Hash(String key) {
MessageDigest md5 = null;
try {
md5 = MessageDigest.getInstance("md5");
byte[] bytes = key.getBytes();
md5.update(bytes);
BigInteger bigInteger = new BigInteger(md5.digest());
return Math.abs(bigInteger.intValue());
} catch (NoSuchAlgorithmException e) {
e.printStackTrace();
}
return -1;
}
private boolean isExist(String element) {
int[] posArr = getIndexes(element);
boolean flag = true;
for (int temPos : posArr) {
flag = flag && bitMap.get(temPos);
}
return flag;
}
public static void main(String[] args) {
Filter filter = new Filter(1000000, 0.0003);
for (int i = 0; i < 1000000; i++) {
filter.addElement("abc"+i);
}
int count = 0;
for (int i = 0; i < 2000000; i++) {
if (filter.isExist("abc"+i)){
count ++;
}
}
System.out.println("count: "+count);
}
}
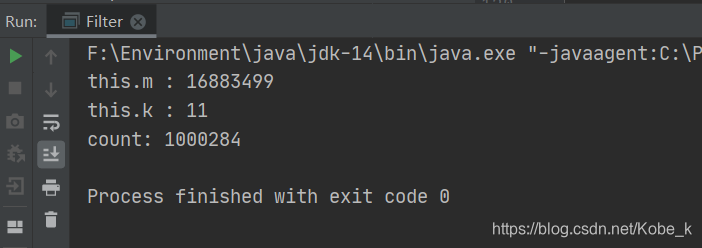
-
输出结果:可以看出误判率在 0.0003 之内
-
Google 提供了 Guava 工具类库,也是类似的思想 《Guava的布隆过滤器》
