今天碰到个业务,他的 Redis 集群有个大 Value 用途是作为布隆过滤器,但沟通的时候被小怼了一下,意思大概是 “布隆过滤器原理都不懂,还要我优化?”。技术菜被人怼认了、怪不得别人,自己之前确实只是听说过这个,但是没深入了解过,趁这个机会补充一下知识。
在进入正文之前,之前看到的有句话我觉得说得很好:
Data structures are nothing different. They are like the bookshelves of your application where you can organize your data. Different data structures will give you different facility and benefits. To properly use the power and accessibility of the data structures you need to know the trade-offs of using one.
大意是不同的数据结构有不同的适用场景和优缺点,你需要仔细权衡自己的需求之后妥善适用它们,布隆过滤器就是践行这句话的代表。
什么是布隆过滤器
本质上布隆过滤器是一种数据结构,比较巧妙的概率型数据结构(probabilistic data structure),特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”。
相比于传统的 List、Set、Map 等数据结构,它更高效、占用空间更少,但是缺点是其返回的结果是概率性的,而不是确切的。
实现原理
HashMap 的问题
讲述布隆过滤器的原理之前,我们先思考一下,通常你判断某个元素是否存在用的是什么?应该蛮多人回答 HashMap 吧,确实可以将值映射到 HashMap 的 Key,然后可以在 O(1) 的时间复杂度内返回结果,效率奇高。但是 HashMap 的实现也有缺点,例如存储容量占比高,考虑到负载因子的存在,通常空间是不能被用满的,而一旦你的值很多例如上亿的时候,那 HashMap 占据的内存大小就变得很可观了。
还比如说你的数据集存储在远程服务器上,本地服务接受输入,而数据集非常大不可能一次性读进内存构建 HashMap 的时候,也会存在问题。
布隆过滤器数据结构
布隆过滤器是一个 bit 向量或者说 bit 数组,长这样:
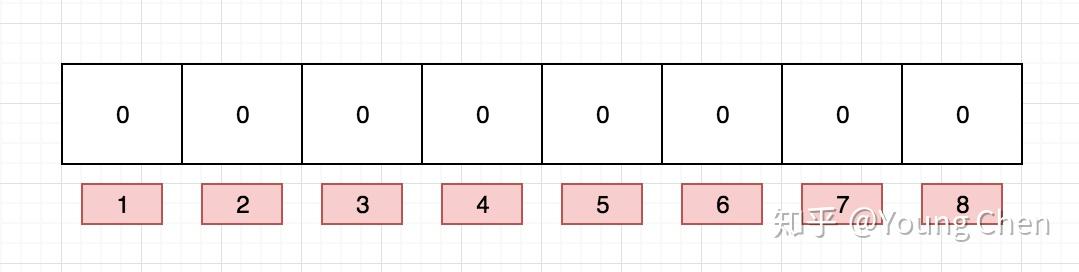
如果我们要映射一个值到布隆过滤器中,我们需要使用多个不同的哈希函数生成多个哈希值,并对每个生成的哈希值指向的 bit 位置 1,例如针对值 “baidu” 和三个不同的哈希函数分别生成了哈希值 1、4、7,则上图转变为:
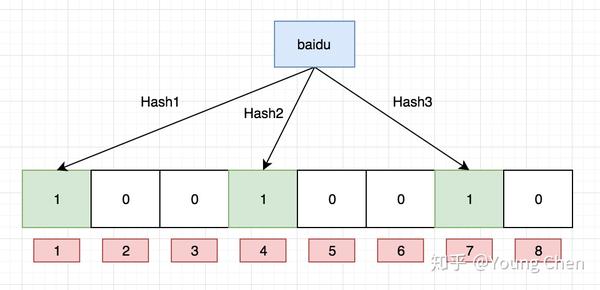
Ok,我们现在再存一个值 “tencent”,如果哈希函数返回 3、4、8 的话,图继续变为:
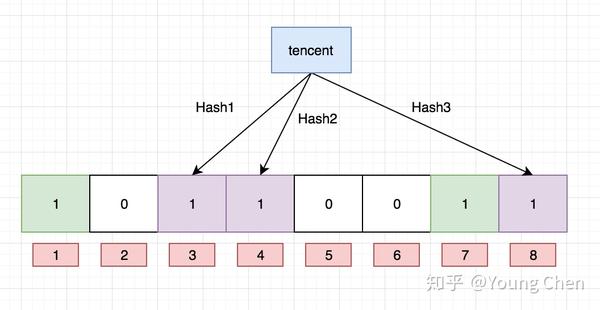
值得注意的是,4 这个 bit 位由于两个值的哈希函数都返回了这个 bit 位,因此它被覆盖了。现在我们如果想查询 “dianping” 这个值是否存在,哈希函数返回了 1、5、8三个值,结果我们发现 5 这个 bit 位上的值为 0,说明没有任何一个值映射到这个 bit 位上,因此我们可以很确定地说 “dianping” 这个值不存在。而当我们需要查询 “baidu” 这个值是否存在的话,那么哈希函数必然会返回 1、4、7,然后我们检查发现这三个 bit 位上的值均为 1,那么我们可以说 “baidu” 存在了么?答案是不可以,只能是 “baidu” 这个值可能存在。
这是为什么呢?答案跟简单,因为随着增加的值越来越多,被置为 1 的 bit 位也会越来越多,这样某个值 “taobao” 即使没有被存储过,但是万一哈希函数返回的三个 bit 位都被其他值置位了 1 ,那么程序还是会判断 “taobao” 这个值存在。
支持删除么
目前我们知道布隆过滤器可以支持 add 和 isExist 操作,那么 delete 操作可以么,答案是不可以,例如上图中的 bit 位 4 被两个值共同覆盖的话,一旦你删除其中一个值例如 “tencent” 而将其置位 0,那么下次判断另一个值例如 “baidu” 是否存在的话,会直接返回 false,而实际上你并没有删除它。
如何解决这个问题,答案是计数删除。但是计数删除需要存储一个数值,而不是原先的 bit 位,会增大占用的内存大小。这样的话,增加一个值就是将对应索引槽上存储的值加一,删除则是减一,判断是否存在则是看值是否大于0。
如何选择哈希函数个数和布隆过滤器长度
很显然,过小的布隆过滤器很快所有的 bit 位均为 1,那么查询任何值都会返回“可能存在”,起不到过滤的目的了。布隆过滤器的长度会直接影响误报率,布隆过滤器越长其误报率越小。
另外,哈希函数的个数也需要权衡,个数越多则布隆过滤器 bit 位置位 1 的速度越快,且布隆过滤器的效率越低;但是如果太少的话,那我们的误报率会变高。
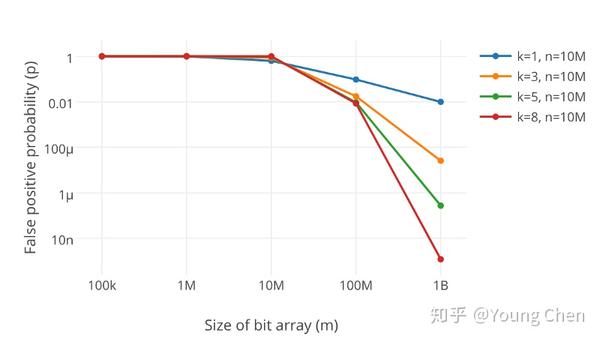
k 为哈希函数个数,m 为布隆过滤器长度,n 为插入的元素个数,p 为误报率。
如何选择适合业务的 k 和 m 值呢,这里直接贴一个公式:

至于如何推导这个公式,我在知乎发布的文章有涉及,感兴趣可以看看,不感兴趣的话记住上面这个公式就行了。
最佳实践
常见的适用常见有,利用布隆过滤器减少磁盘 IO 或者网络请求,因为一旦一个值必定不存在的话,我们可以不用进行后续昂贵的查询请求。
另外,既然你使用布隆过滤器来加速查找和判断是否存在,那么性能很低的哈希函数不是个好选择,推荐 MurmurHash、Fnv 这些。
大Value拆分
Redis 因其支持 setbit 和 getbit 操作,且纯内存性能高等特点,因此天然就可以作为布隆过滤器来使用。但是布隆过滤器的不当使用极易产生大 Value,增加 Redis 阻塞风险,因此生成环境中建议对体积庞大的布隆过滤器进行拆分。
拆分的形式方法多种多样,但是本质是不要将 Hash(Key) 之后的请求分散在多个节点的多个小 bitmap 上,而是应该拆分成多个小 bitmap 之后,对一个 Key 的所有哈希函数都落在这一个小 bitmap 上。