1.BlockCanary
造成app卡顿的直接原因通常是,主线程执行繁重的UI绘制、大量的计算或IO等耗时操作。常用的解决卡顿的方法有BlockCanary、ArgusAPM、LogMonitor等。
从监控主线程哦哦实现原理上,主要分为两种:
①依赖主线程Looper,监控每次dispatchMessage的执行耗时。(BlockCanary)
②依赖Choreographer模块,监控相邻两次Vsync事件通知的时间差。(ArgusAPM、LogMonitor)
BlockCanary是Android平台的一个非侵入式的性能监控组件,应用只需要实现一个抽象类,提供一些该组件需要的上下文环境,就可以在平时使用应用的时候检测主线程上的各种卡慢问题,并通过组件提供的各种信息分析出原因并进行修复。
BlockCanary对主线程操作进行了完全透明的监控,并能输出有效的信息,帮助开发分析、定位到问题所在,迅速优化应用。其特点有:
①非侵入式,简单的两行就打开监控,不需要到处打点,破坏代码优雅性。
②精准,输出的信息可以帮助定位到问题所在(精确到行),不需要像Logcat一样,慢慢去找。
2.BlockCanary使用
①添加依赖
dependencies {
compile 'com.github.markzhai:blockcanary-android:1.5.0'
// 仅在debug包启用BlockCanary进行卡顿监控和提示的话,可以这么用
debugCompile 'com.github.markzhai:blockcanary-android:1.5.0'
releaseCompile 'com.github.markzhai:blockcanary-no-op:1.5.0'
}
②在Application里进行初始化和start
BlockCanary.install(this, new BlockCanaryContext()).start();
3.BlockCanary原理
首先看install方法:
public static BlockCanary install(Context context, BlockCanaryContext blockCanarayContext) {
BlockCanaryContext.init(context, blockCanaryContext);
setEnabled(context, DisplayActivity.class, BlockCanaryContext.get().displayNotification());
return get();
}
其中BlockCanaryContext表示监测的某些参数,包括卡顿的阈值、输出文件的路径等等。
public class BlockCanaryContext implements BlockInterceptor {
public int provideBlockThreshold() {
return 1000; //默认卡顿阈值为1000ms
}
public String providePath() {
return "/blockcanary/";//输出的log
}
//支持文件上传
public void upload(File zippedFile) {
throw new UnsupportedOperationException();
}
//可以在卡顿提供自定义操作
@Override
public void onBlock(Context context, BlockInfo blockInfo) {
}
}
install只是创建出BlockCanary实例,主要是start方法的操作:
BlockCanary.java:
//Start monitoring.
public void start() {
if (!mMonitorStarted) {
mMonitorStarted = true;
Looper.getMainLooper().setMessageLog ging(mBlockCanaryCore.monitor);
}
}
start方法其实就是给主线程的Looper设置一个monitor。
熟悉Message/Looper/Handler系列的一定知道Looper.java中这么一段:
private static Looper sMainLooper;
public static void prepareMainLooper() {
prepare(false);
synchronized (Looper.class) {
if (sMainLooper != null) {
throw new IllegalStateException("The main Looper has already been prepared.");
}
sMainLooper = myLooper();
}
}
public static Looper getMainLooper() {
synchronized (Looper.class) {
return sMainLooper;
}
}
即整个应用的主线程,只有这一个looper,不管有多少handler,最后都会回到这里。
在Looper的loop方法中,看看主线程的looper实现:
public static void loop() {
...
for (;;) {
...
Printer logging = me.mLogging;
if (logging != null) {
logging.println(">>>>> Dispatching to " + msg.target + " " + msg.callback + ": " + msg.what);
}
msg.target.dispatchMessage(msg);
if (logging != null) {
logging.println("<<<<< Finished to " + msg.target + " " + msg.callback);
}
...
}
}
主线程所有执行的任务都在dispatchMessage方法中派发执行完成,通过setMessageLogging的方式给主线程的Looper设置一个Printer,因为dispatchMessage执行前后都会打印对应信息,在执行前利用另外一条线程,通过Thread#getStackTrace接口,以轮询的方式获取主线程执行堆栈信息并记录起来,同时统计每次dispatchMessage方法执行耗时,当超出阈值时,将该次获取的堆栈进行分析上报,从而捕捉卡顿信息,否则丢弃此次记录的堆栈信息。
这个Printer - mLogging在每个message处理的前后被调用,而如果主线程卡住了,不就是在dispatchMessage里卡住了吗?
在上面的loop循环的代码中,msg.target.dispatchMessage就是UI线程收到每一个消息需要执行的操作,都在其内部执行。系统在其执行的前后都会执行logging类的print方法,这个方法是可以自定义的。所以只要在运行的前后都添加一个时间戳,用运行后的时间减去运行前的时间,一旦这个时间超过了设定的阈值,就可以说这个操作卡顿,阻塞了UI线程,最后通过dump出此时的各种信息,来分析各种性能瓶颈。
核心流程图:
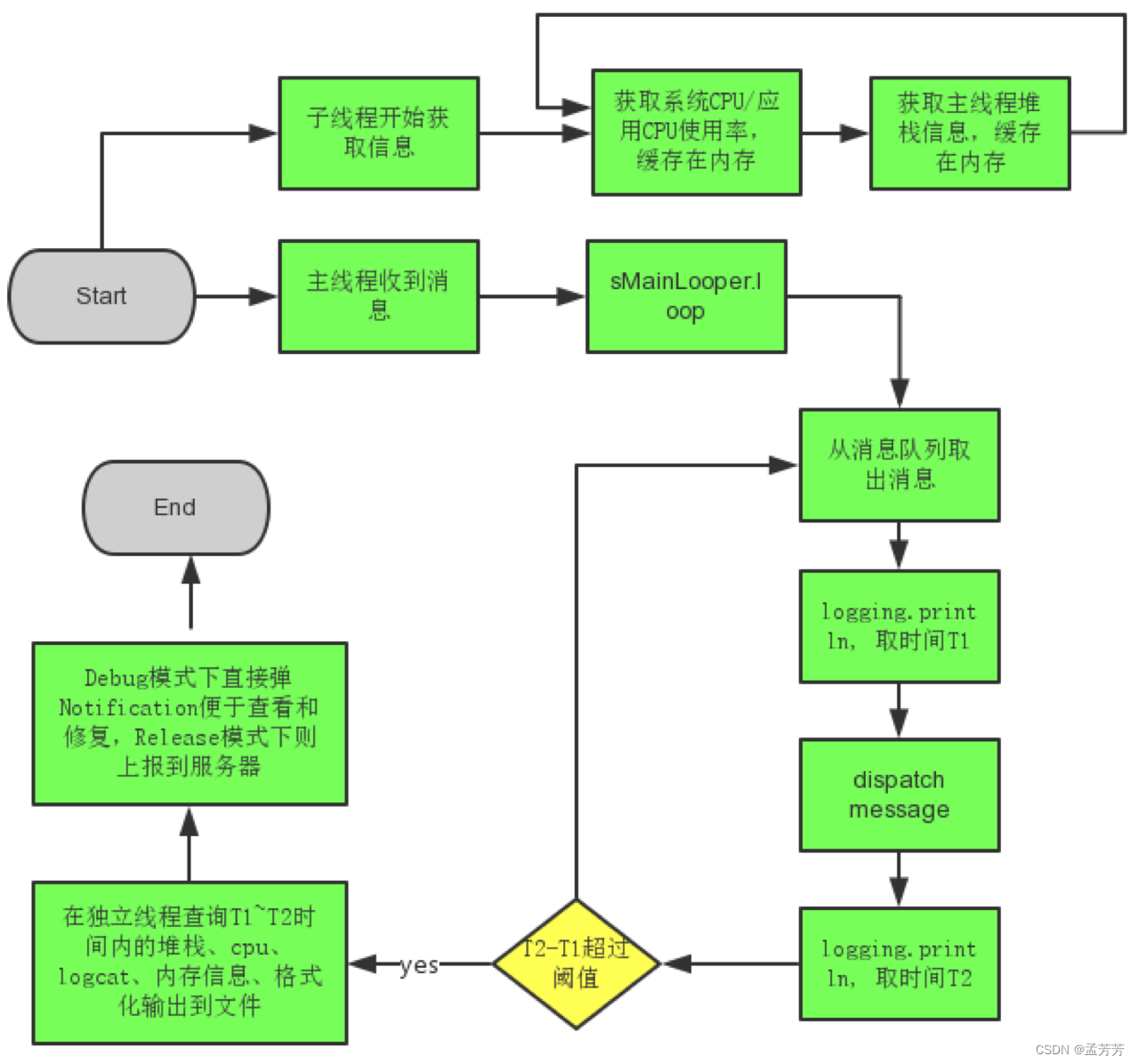
该组件利用了主线程的消息队列处理机制,通过Looper.getMainLooper().setMessageLogging(mainLooperPrinter);并在mainLooperPrinter中判断start和end,来获取主线程dispatch该message的开始和结束时间,并判定该时间超过阈值(如2000毫秒)为主线程卡慢发生,并dump出各种信息,提供开发者分析性能瓶颈。
接下来看看这个monitor的println方法:
LooperMonitor.java:
@Override
public void println(String x) {
//如果当前在调试中,那么直接返回,不做处理
if (mStopWhenDebugging && Debug.isDebuggerConnected()) {
return;
}
if (!mPrintingStarted) {
//执行操作前
mStartTimestamp = System.currentTimeMillis();
mStartThreadTimestamp = SystemClock.currentThreadTimeMillis();
mPrintingStarted = true;
startDump();
} else {
//执行操作后
final long endTime = System.currentTimeMillis();
mPrintingStarted = false;
//是否卡顿
if (isBlock(endTime)) {
notifyBlockEvent(endTime);
}
stopDump();
}
}
private boolean isBlock(long endTime) {
return endTime - mStartTimeMillis > mBlockThresholdMillis;
}
在ui操作执行前,将会记录当前的时间戳,同时会startDump。
在ui操作执行后,将会计算当前是否卡顿了,如果卡顿了,将会回调到onBlock的onBlock方法。同时将会停止dump。
为什么操作之前就开启了startDump,而操作执行之后就stopDump呢?
LooperMonitor.java:
private void startDump() {
if (null != BlockCanaryInternals.getInstance( ).stackSampler) {
BlockCanaryInternals.getInstance( ).stackSampler.start();
}
if (null != BlockCanaryInternals.getInstance( ).cpuSampler) {
BlockCanaryInternals.getInstance( ).cpuSampler.start();
}
}
其中start方法:
AbstractSampler.java:
public void start() {
if (mShouldSample.get()) {
return;
}
mShouldSample.set(true);
HandlerThreadFactory.getTimerThreadHandl er().removeCallbacks(mRunnable);
HandlerThreadFactory.getTimerThreadHandl er().postDelayed(mRunnable, BlockCanaryInternals.getInstance().getSampleDelay());
}
可以看到,startDump的时候并没有马上start,而是会postDelay一个runnable,这个runnable就是执行dump的真正的操作,delay的时间是设置的阈值的0.8倍,也就是,一旦stop在设置的延迟时间之前执行,就不会真正的执行dump操作。
AbstractSampler.java:
public void stop() {
if (!mShouldSample.get()) {
return;
}
mShouldSample.set(false);
HandlerThreadFactory.getTimerThreadHandl er().removeCallbacks(mRunnable);
}
只有当stop操作在设置的延迟时间之后执行,才会执行dump操作。
AbstractSampler.java:
private Runnable mRunnable = new Runnable() {
@Override
public void run() {
doSample();
if (mShouldSample.get()) {
HandlerThreadFactory.getTimerThreadHa ndler().postDelayed(mRunnable,mSampleInterval);
}
}
};
这个doSameple分别会dump出stack信息和cpu信息。
CpuSampler.java:
protected void doSample() {
cpuReader = new BufferedReader(new InputStreamReader(new FileInputStream( "/proc/stat")), BUFFER_SIZE);
String cpuRate = cpuReader.readLine();
if (cpuRate == null) {
cpuRate = "";
}
if (mPid == 0) {
mPid = android.os.Process.myPid();
}
pidReader = new BufferedReader(new InputStreamReader(new FileInputStream( "/proc/" + mPid + "/stat")), BUFFER_SIZE);
String pidCpuRate = pidReader.readLine();
if (pidCpuRate == null) {
pidCpuRate = "";
}
parse(cpuRate, pidCpuRate);
}
StackSampler.java:
protected void doSample() {
StringBuilder stringBuilder = new StringBuilder();
for (StackTraceElement stackTraceElement : mCurrentThread.getStackTrace()) {
stringBuilder.append( stackTraceElement.toString()).append(BlockInfo.SEPARATOR);
}
synchronized (sStackMap) {
if (sStackMap.size() == mMaxEntryCount && mMaxEntryCount > 0) {
sStackMap.remove( sStackMap.keySet().iterator().next());
}
sStackMap.put(System.currentTimeMillis(), stringBuilder.toString());
}
}
这样,整个blockCanary的执行过程就完毕了。
4.总结
BlockCanary会在发生卡顿(通过MonitorEnv的getConfigBlockThreshold设置)的时候记录各种信息,输出到配置目录下的文件,并弹出消息栏通知(可关闭)。
简单的使用如在开发、测试、Monkey的时候,Debug包启用。
BlockCanary提供了一个友好的展示界面,供开发测试直接查看卡慢信息(基于LeakCanary的界面修改)。
dump的信息包括:
①基本信息:安装包标示、机型、api等级、uid、CPU内核数、进程名、内存、版本号等
②耗时信息:实际耗时、主线程时钟耗时、卡顿开始时间和结束时间
③CPU信息:时间段内CPU是否忙,时间段内的系统CPU/应用CPU占比,I/O占CPU使用率
④堆栈信息:发生卡慢前的最近堆栈,可以用来帮助定位卡慢发生的地方和重现路径
sample如下图,可以精确定位到代码中哪一个类的哪一行造成了卡慢。